
Apache Mahout: A Concise Tutorial Just An Hour – FREE
Last updated on 08th Jul 2020, Blog, Tutorials
This tutorial gives you an overview and talks about the fundamentals of Apache Mahout.
- Mahout is an open source machine learning library from Apache. The algorithms it implements fall under the broad umbrella of “machine learning,” or “collective intelligence.” This can mean many things, but at the moment for Mahout it means primarily collaborative filtering / recommender engines, clustering, and classification.
- Also scalable, mahout aims to be the machine learning tool of choice when the data to be processed is very large, perhaps far too large for a single machine. In its current incarnation, these scalable implementations are written in Java, and some portions are built upon Apache’s Hadoop distributed computation project.
- While Mahout is, in theory, a project open to implementations of all kinds of machine learning techniques, it is in practice a project that focuses on three key areas of machine learning at the moment. These are recommender engines (collaborative filtering), clustering, and classification.
- Recommender engines are the most immediately recognizable machine learning technique in use today. You will have seen services or sites that attempt to recommend books or movies or articles based on our past actions. They try to infer tastes and preferences and identify unknown items that are of interest.
- Clustering turns up in less apparent but equally well-known contexts. As its name implies, clustering techniques attempt to group a large number of things together into clusters that share some similarity. It is a way to discover hierarchy and order in a large or hard-to-understand data set, and in that way reveal interesting patterns or make the data set easier to comprehend.
- Classification techniques decide how much a thing is or isn’t part of some type or category, or, does or doesn’t have some attribute. Classification is likewise ubiquitous, though even more behind-the-scenes. Often these systems “learn” by reviewing many instances of items of the categories in question in order to deduce classification rules.
Why should you learn Apache Mahout?
- Turns big data into useful information in a faster and easier way leveraging your business capabilities
- Runs on Hadoop, making it easier to work on for those who know Hadoop
- Being integrated with Hadoop/HDFS, Mahout implements distributed memory algorithms that can be applied to data sets much larger than any other technique can handle.
- One of the hot machine learning projects that are being widely used by organizations worldwide
Classification techniques decide how much a thing is or isn’t part of some type or category, or how much it does or doesn’t have some attribute. Classification, like clustering, is ubiquitous, but it’s even more behind the scenes. Often these systems learn by reviewing many instances of items in the categories in order to deduce classification rules. This general idea has many applications: Yahoo! Mail decides whether or not incoming messages are spam based on prior emails and spam reports from users, as well as on characteristics of the email itself. A few messages classified as spam are shown in figure 1.4. Google’s Picasa and other photo-management applications can decide when a region of an image contains a human face. Optical character recognition software classifies small regions of scanned text into individual characters. Apple’s Genius feature in iTunes reportedly uses classification to classify songs into potential playlists for users. Classification helps decide whether a new input or thing matches a previously observed pattern or not, and it’s often used to classify behavior or patterns as unusual. It could be used to detect suspicious network activity or fraud. It might be used to figure out when a user’s message indicates frustration or satisfaction.
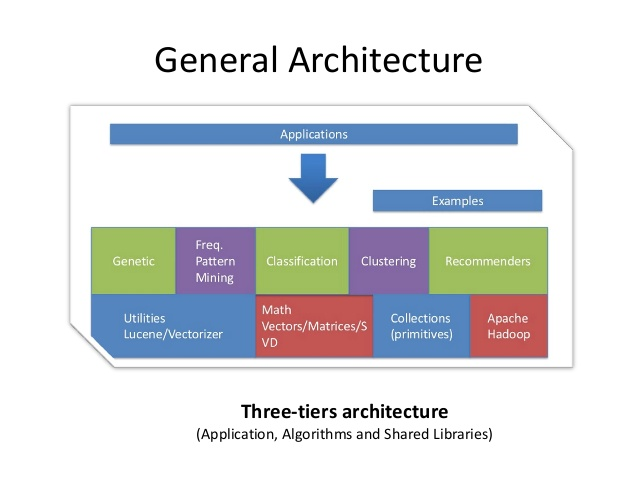
Features of the Mahout framework
- The Mahout framework is tightly coupled with Hadoop. So, it is very useful for distributed environments where Mahout uses the Apache Hadoop library to scale in the cloud.
- Developers can use Mahout for mining large volumes of data as it is a ready-to-use framework.
- Through Mahout, applications can analyse data faster and more effectively.
- MapReduce enabled clustering implementations are supported by Mahout—for example, clustering algorithms like K-Means, Fuzzy K-Means, Canopy, Dirichlet and Mean-Shift.
- It also supports distributed and complementary Naive Bayes classification implementations.
- Distributed fitness function capabilities are an inbuilt part of Apache Mahout for evolutionary programming.
- It includes vector and matrix libraries.
- It also has examples of all the above-mentioned algorithms.
- Mahout has great community support, which cannot be found for any other open source ML library.
Applications of the Mahout framework
- IT giants like Facebook, LinkedIn, Adobe, Twitter and Yahoo! use Mahout.
- Foursquare uses the Mahout recommender engine to serve you by finding the places, entertainment options and food to your liking, in a specific area.
- User interest can be modelled, and Twitter uses Mahout for that.
- The pattern mining of the Mahout framework is used by Yahoo!
Mahout Uses
- Collaborative filtering: mines user behavior and makes product recommendations (e.g. Amazon recommendations)
- Clustering: takes items in a particular class (such as web pages or newspaper articles) and organizes them into naturally occurring groups, such that items belonging to the same group are similar to each other
- Classification: learns from existing categorizations and then assigns unclassified items to the best category
- Frequent itemset mining: analyzes items in a group (e.g. items in a shopping cart or terms in a query session) and then identifies which items typically appear together.
Some examples of applied machine learning algorithms include:
- Recommendation engines: Numerous web sites today are able to make recommendations to users based on past behavior, and the behavior of others. Netflix for example is able to recommend movie to a user based on its similarity to other movies that user has enjoyed.
- Spam filtering: Nearly every modern email provider is able to automatically detect the difference between a spam message and a legitimate one, only presenting the latter ones to the user. These filtering engines use machine-learning algorithms such as clustering and classification.
- Natural Language Processing: Many of us have smartphones that understand what we mean when we ask “When are the niners playing next?”. Making a computer understand this phrase is no simple task – it has to know that “niners” is slang for the San Francisco 49ers, which is an American football team, so it needs to consult with the National Football League’s schedule to provide the answer. All of this was made possible by applying machine-learning algorithms to vast sets of language data to make these connections.
Until recently, data scientists had to implement and customize machine-learning algorithms manually to the computing framework that they were using, resulting in a significant amount of work. Now, with Hadoop and Mahout, data scientists can write MapReduce jobs that reference a number of predefined algorithms to build these kinds of applications easily.
Below is a current list of machine learning algorithms exposed by Mahout.
- Collaborative Filtering
- Item-based Collaborative Filtering
- Matrix Factorization with Alternating Least Squares
- Matrix Factorization with Alternating Least Squares on Implicit Feedback
- Classification
- Naive Bayes
- Complementary Naive Bayes
- Random Forest
- Clustering
- Canopy Clustering
- k-Means Clustering
- Fuzzy k-Means
- Streaming k-Means
- Spectral Clustering
- Dimensionality Reduction
- Lanczos Algorithm
- Stochastic SVD
- Principal Component Analysis
- Topic Models
- Latent Dirichlet Allocation
- Miscellaneous
- Frequent Pattern Matching
- RowSimilarityJob
- ConcatMatrices
- Colocations
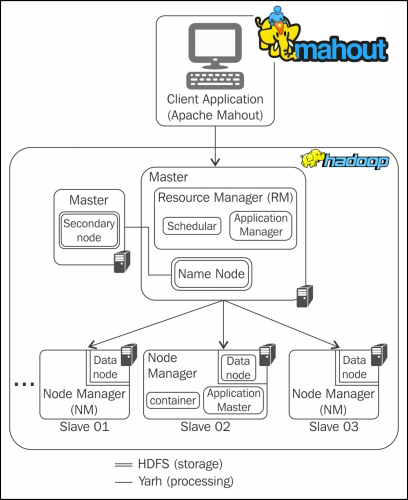
INSTALLATION
Setting up Mahout in Eclipse
1. Download Mahout source from http://apache.techartifact.com/mirror/mahout/0.7/
direct link for the source zip file: http://apache.techartifact.com/mirror/mahout/0.7/mahout-distribution-0.7-src.zip
2. Extract from archive it.
3. Convert the project into an eclipse project.
- $ cd mahout-distribution-0.7
- $ mvn eclipse:eclipse
Wait for a long time till it builds the eclipse project.
4. Now set the classpath variable M2_REPO of Eclipse to Maven 2 local repository
- mvn -Declipse.workspace= eclipse:add-maven-repo
(Adding the path of the maven jars in eclipse)

Get Experts Curated Apache Mahout Training with Industry Trends Concepts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
5. Finally import the converted Eclipse project of Mahout.
Open File > Import > General > Existing Projects into Workspace from Eclipse menu.
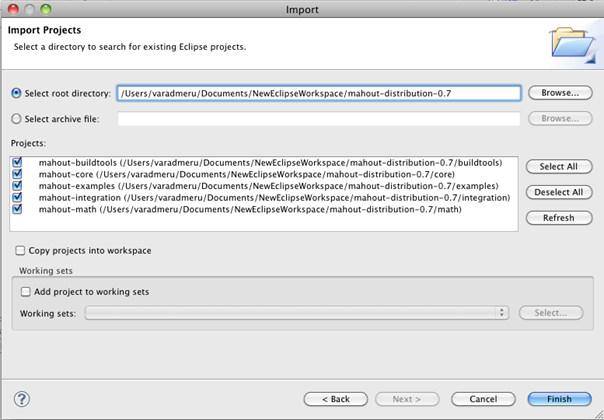
Mahout Setup Figure 1

Mahout Setup Figure2.
5. At first, generate a Maven project for sample codes on the Eclipse workspace directory.
- $ mvn archetype:create -DgroupId=com.orzota.mahout.recommender -DartifactId=recommender
The name of the project created is “recommender” in the workspace directory
6. Convert the newly created java project into eclipse project
- $ cd recommender
- $ mvn eclipse:eclipse
7. Import the project into eclipse
Open File > Import > General > Existing Projects into Workspace from Eclipse menu and select the ‘recommender’ project.
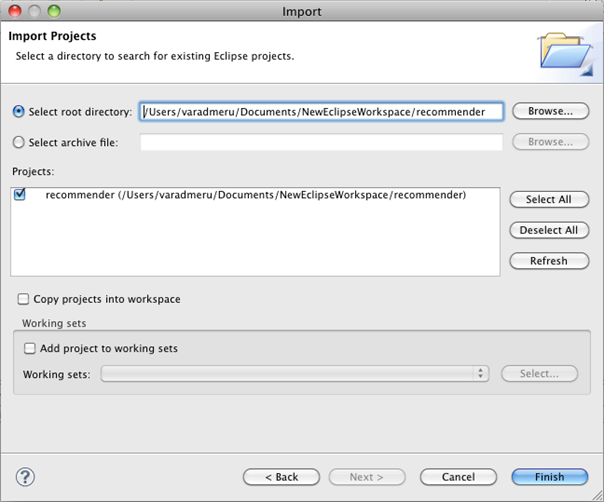
Mahout Setup Figure3
The Folder structure looks like the below. Now we can build apps using the Mahout
8. Right click the ‘recommender’ project, select Properties > Java Build Path > Projects from pop-up menu and click ‘Add’ and select the below Mahout projects.
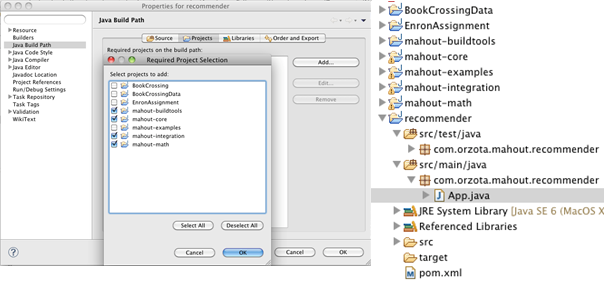
Mahout Setup Figure4.
Conclusion
We were able to configure Mahout Source Code for directly accessing and debugging our program programmatically from eclipse and help us to run mahout programs from eclipse itself.