
Last updated on 10th Nov 2021| 5106
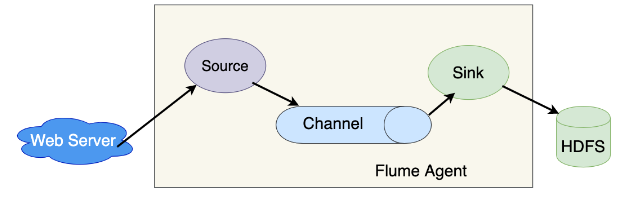
Apache Flume is an open-source and distributed data collection system designed to streamline the ingestion and transportation of large volumes of log data in diverse computing environments. As part of the Apache Hadoop ecosystem, Flume employs a modular architecture with three main components: sources, channels, and sinks. Sources capture data from various origins, channels act as temporary storage, and sinks deliver the data to its final destination. Commonly utilized for log aggregation, Flume excels in collecting and forwarding data from sources such as web servers to storage systems like Hadoop Distributed File System (HDFS).
1. What does Apache Flume stand for?
Ans:
Apache Flume is the open source platform for collecting, aggregating, and transferring huge amounts of data from one or more sources to a centralised data source effectively and reliably. Flume’s data sources can be customized, so it can injest any type of data, like log data, event data, network data, social media produced data, email messages, message queues, and so on.
2. Does Apache Flume provide support for third-party plug-ins?
Ans:
Yes, Apache Flume provides support for third-party plug-ins. You can extend the functionality of Flume by creating custom sources, channels, and sinks, or by using existing third-party plugins. This extensibility makes Flume adaptable to different use cases and data sources.
3. What is Agent?
Ans:
In Apache Flume, an independent daemon process (JVM) is what can be called an agent. At first, it receives the events from clients or other agents. Afterwards, it forwards it to its next destination that is sink or agent. It is possible that Flume can have more than one agent.
4. How can Flume be used with HBase?
Ans:
There are two types of HBase sinks. So, we can use Flume with HBase using one of two HBase sinks.
HBaseSink: Supports the secure HBase clusters and also the novel HBase IPC that was introduced in version HBase 0.96.
AsyncHBaseSink: It can easily make non-blocking calls to HBase, which means it has a better performance than HBase sink.
5. What is a channel?
Ans:
A transient store that receives events from a source and buffers them till they are consumed by the sinks is what is called a Flume channel. To be very specific it acts as a bridge between sources and sinks in Flume. Basically, these channels can work with any number of sources and sinks are fully transactional.
6. Explain replication and multiplexing selectors in Flume.
Ans:
Channel selectors are used to handle the multiple channels. Moreover, events can be written just to a single channel or to multiple channels, on the basis of Flume header value. By default, it is a Replicating selector, if channel selector is not specified to source.
Although, the same event is written to all channels in the source’s channels list, by using a replicating selector. However, when the application has to send different events to the different channels, use the Multiplexing channel selector.
7. Explain different channel types in Flume.
Ans:
MEMORY Channel: Through this MEMORY channel events are read from a source into the memory and passed to the sink.
JDBC Channel: It stores events in the embedded derby database.
FILE Channel: It writes contents to a file on file system after reading the event from source. The file is deleted only after contents are successfully delivered to a sink.
8. What is FlumeNG?
Ans:
FlumeNG is nothing but the real-time loader for streaming data into Hadoop. Basically, it stores data in HDFS and HBase. Thus, if you want to get started with FlumeNG, it improves on the original flume.
9. What is Interceptor?
Ans:
- In Apache Flume, an interceptor is a component that allows you to modify or process events as they flow through the Flume pipeline.
- Interceptors are used to customize the behavior of Flume agents by adding, modifying, or dropping events based on specified conditions.
10. Explain the core components of Flume.
Ans:
Event: Event is a single log entry or unit of data which can transport further.
Source: Source is a component by which data enters the Flume workflows.
Sink: For transporting data to a desired destination sink is responsible.
Channel: Channel is nothing but duct between Sink and Source.
Agent: Agent is what is known as any JVM that runs Flume.
Client: Client transmits events to a source that operates with the agent.
11. Why are we using Flume?
Ans:
Apache Flume is commonly used in big data environments for log aggregation and data ingestion. Some reasons for using Flume include its scalability, fault tolerance, extensibility through plugins, and ease of integration with various data storage systems. It provides a reliable and efficient way to collect and transport large volumes of data from multiple sources to centralized storage or processing systems.
12. Can Flume distribute data to multiple destinations?
Ans:
- Yes, Apache Flume can disseminate data to many locations. Flume supports many sinks, and events may be copied or routed to other destinations depending on your settings.
- This functionality comes in handy when you need to store data in many storage systems or analyze it in various ways.
13. Differentiate between FileSink and FileRollSink?
Ans:
| Feature | FileSink | FileRollSink | |
| Rolling Policy |
No automatic rolling |
Supports time or size-based rolling | |
| Use Case | Basic file writing | Periodic or size-based file rolling | |
| Configuration | Minimal | Additional rolling policy configuration | |
| File Naming |
Single file |
Timestamped or indexed new files |
14. What are sink processors?
Ans:
A sink processor in Flume is a component of the sink that processes events before delivering them to their final destination. Sink processors can be set to execute operations such as event filtering, event modification, or custom processing depending on certain parameters. Sink processors enable you to customise the sink’s behaviour and execute extra actions on events before they reach their destination.
15. Can flume provide 100% reliability to data flow?
Ans:
Flume provides mechanisms for reliable data flow. It achieves reliability through features such as fault tolerance, event acknowledgment, and durable channel storage.
However, achieving 100% reliability in distributed systems is challenging, and the level of reliability depends on various factors such as configuration, network stability, and the underlying infrastructure.
16. List the tools used in Big Data.
Ans:
- Hadoop
- Hive
- Pig
- Flume
- Mahout
- Sqoop
17. What are complicated steps in Flume configurations?
Ans:
You can process streaming data, by using the Flume. Hence, if started once, there is no stop/end of the process. Asynchronously it can flow the data from source to HDFS via the agent. First of all, agents should know the individual components and how they are connected to load data.
Thus, to load streaming data configuration is a trigger. For example, consumerkey, consumersecret accessToken, and accessTokenSecret are the key factors to download data from Twitter.
18. What are important steps in configuration?
Ans:
Configuration file is the heart of Apache Flume’s agents.
- Each Source must have at least one channel.
- Moreover, every Sink must have the only one channel.
- Every component must have a specific type.
19. What are Flume’s core components?
Ans:
Sources: Ingest data into the Flume pipeline.
Channels: Temporarily store data in the pipeline.
Sinks: Deliver data to the final destination.
20. Which is a reliable channel in Flume to ensure there is no data loss?
Ans:
In Apache Flume, the File Channel is a dependable choice for guaranteeing little data loss. It offers resilience and recoverability in the event of failures by storing events on the local file system. In situations when data integrity is critical, this persistence method is a good option since it helps avoid data loss throughout the data transfer process. In the case of system outages or failures, its capacity to save event state on disc improves dependability.
21. What are Data extraction tools in Hadoop?
Ans:
Sqoop: Efficiently transfer bulk data between Hadoop and relational databases.
Flume: Collect and transport log data from various sources.
Nifi: Web-based tool for designing data flows and automating ETL processes.
Kafka: Distributed streaming platform for buffering streaming data.
Chukwa: Monitoring tool with log data collection and analysis capabilities.
22. What is Apache Spark?
Ans:
Apache Spark is the general-purpose & lightning fast cluster computing system. It provides a high-level API. For example, Java, Scala, Python and R. Apache Spark is the tool for Running Spark Applications. Spark is 100 times faster than the Big Data Hadoop and 10 times faster than accessing data from disk.
23. What are the types of Data Flow in Flume?
Ans:
- Multi-hop Flow
- Fan-out Flow
- Replicating
- Multiplexing
- Fan-in Flow
24. What is a Flume event?
Ans:
The basic unit of data which is transported inside the Flume is what call a Flume Events. Generally, it contains the payload of a byte array. Basically, can transport it from a source to the destination accompanied by the optional headers.
25. Differences between Apache Flume and Apache Kafka?
Ans:
Flume:
- Designed for log data ingestion and simple event processing.
- Follows a master-agent architecture, emphasizing simplicity in data movement, commonly used in Hadoop environments.
Kafka:
- Functions as a distributed streaming platform for high-throughput, fault-tolerant, and real-time data streaming.
- Utilizes a publish-subscribe model with partitions, suitable for building real-time data pipelines and event-driven architectures.
26. Explain data flow in Flume.
Ans:
In Apache Flume, data flow involves three main components: sources, channels, and sinks. Sources ingest data from external origins, channels temporarily store the data, and sinks deliver it to the final destination. Events move seamlessly from source to channel to sink, allowing for efficient and reliable data collection and transport in diverse computing environments.
27. What are the Limitations of Flume?
Ans:
- Limited complex event processing (CEP).
- Scaling can be complex.
- Centralized configuration might be challenging in large deployments.
- Not as suited for real-time streaming use cases.
28. Explain Reliability and Failure Handling in Apache Flume.
Ans:
- Flume ensures reliability through transactional mechanisms.
- Channels like the File Channel provide durability with local file system storage.
- Event acknowledgment and fault tolerance mechanisms prevent data loss.
- Flume’s recovery features, including event replay, maintain data integrity in case of failures.
29. What is Flume Client?
Ans:
Flume client refers to the program or component that produces or consumes events and interacts with Flume agents. Flume clients are responsible for generating or receiving data and forwarding it to Flume agents for further processing. There are the two main types of Flume clients: producers and collectors.
30. What are possible types of Channel Selectors?
Ans:
Channel Selectors are generally two types:
Default channel selectors: Replicating channel selectors which replicate all events in each channel are what call Default channel selectors.
Multiplexing channel selectors: The Channel selectors which decide which channel to send an event based on the address in the header of that event are the Multiplexing channel selectors.
31. What are Channel Selectors?
Ans:
The Channel selector is that component of a Flume that determines which channel particular Flume event should go into when a group of channels exists. The target channel can be a one or multiple.
The mechanism used is an internal mechanism. As discussed earlier, in two ways multiple channels can be handled. Channel selectors are of the two types- Default and multiplexing.
32. What is Event Serializer in Flume?
Ans:
In Apache Flume, an Event Serializer is a component responsible for converting events into a specific format before they are persisted or transmitted. It allows users to customize the way event data is serialized for storage or further processing. By defining a custom Event Serializer, users can tailor the representation of events to suit the requirements of the destination storage or system.
33. What are Tools available to send streaming data to HDFS?
Ans:
Flume: Flume itself is often used for streaming data ingestion into HDFS.
Kafka Connect: Kafka Connect is a framework for streaming data between Apache Kafka and other data systems.
Apache NiFi: Apache NiFi is a data integration tool that supports the flow-based programming model.
Storm: Apache Storm is a real-time stream processing system.
34. What are Apache Flume Applications?
Ans:
- Apache Flume has a wide range of demand in e-commerce Companies to analyze customer behavior of different regions.
- The main design goal of flume is to ingest huge log data generated by the application servers into HDFS at higher speed.
- The main application of flume is online analytics.
- It is the backbone for real-time event processing.
35. Can we run two instances of flume node on same unix machine?
Ans:
Yes, it is possible to run two instances of Flume nodes on the same Unix machine. Each instance can have its own configuration and ports to avoid conflicts. It is essential to ensure that the configurations (including source, channel, and sink configurations) and ports are appropriately specified for each Flume instance to prevent interference between the two instances.

Learn Advanced Apache Storm Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details36. What is Streaming / Log Data?
Ans:
Streaming / Log Data is data produced by various data sources and usually required to be analyzed. Data Sources are applications servers, social networking sites, cloud servers and enterprise servers. So, that data is generally in the form of log files or events.
37. What are use cases of Apache Flume?
Ans:
- It helps in the Reliable delivery of data to a destination.
- When velocity and volume of data increases, Flume becomes a scalable solution that can run quite easily just by adding a machine to it.
- Without incurring any downtime Flume dynamically configures various components of architecture.
38. What is the use of Interceptors?
Ans:
- The interceptors used to modify/drop events are in-flight. Flume has capability as it uses the interceptors.
- The interceptor also decides what sort of data should pass through to the Channel.
- An interceptor can modify/drop events based on any criteria chosen by a developer of the interceptor. Flume supports the binding of interceptors.
- Interceptors are stated as the whitespace separated list in a source configuration.
39. How do you deal with agent errors?
Ans:
If a Flume agent fails, all the flows hosted on that agent are terminated. Flow will resume once agent is restarted. All events stored in a channel when the agent went down are lost if the channel is set up as an in-memory channel. Channels configured as a file or other stable channels, on other hand, will continue to handle the events where they left off.
40. What is the use of Sink Processors?
Ans:
Sink Processors in Apache Flume enable customization of event processing before reaching the final destination (sink). They facilitate event filtering, transformation, and conditional processing, allowing users to apply specific actions based on criteria, enhancing the flexibility and adaptability of the data flow pipeline.
41. In Flume, how is recoverability ensured?
Ans:
Flume organizes events and data into channels. Flume sources populate Flume channels with the events. Flume sinks consume the channel events and publish them to a terminal data storage. Failure recovery is handled by the channels. Flume supports a variety of channels. In-memory channels save events in an in-memory queue for a speedier processing. The local file system backs up the file channels, making them durable.
42. What is topology design in Apache Flume?
Ans:
- The initial step in the Apache Flume is to verify all the data sources and sinks, after which may determine whether event aggregation or rerouting.
- When gathering data from multiple sources, aggregation and rerouting are required to redirect those events to a different place.
43. What are complicated steps in Flume configuration?
Ans:
Flume can process the streaming data, so if started once, there is a no stop/end to the process. asynchronously it can flow data from source to HDFS via Agent. First of all, agents should know the individual components that are connected to load data. So configuration is triggered to load streaming data. For example, consumerKey, consumerSecret, accessToken and accessTokenSecret are the key factors to download data from Twitter.
44. Explain Consolidation in Flume.
Ans:
The beauty of Flume is Consolidation, it collects data from the different sources even its different Flume Agents. Flume source can collect all the data flow from different sources and flows through the channel and sink. Finally, send this data to the HDFS or target destination.
45. What are Flume’s Basic Characteristics?
Ans:
- Distributed Data Collection
- Modular Architecture
- Reliability and Fault Tolerance
- Extensibility
- Ease of Integration
46. Difference between Flume and Sqoop?
Ans:
Flume is designed for the collecting, aggregating, and transporting log data, while Sqoop is designed for efficiently transferring bulk data between the Apache Hadoop and structured datastores such as relational databases.
47. How does Flume handle fault tolerance?
Ans:
- Flume ensures fault tolerance through use of reliable channels. Channels store events persistently and can recover data in case of a failure.
- Additionally, Flume supports the use of the multiple agents and failover configurations for the increased reliability.
48. How can you configure Flume to handle large volumes of data efficiently?
Ans:
To efficiently handle large data volumes in Apache Flume, strategic configuration choices and optimizations are essential. Begin by selecting appropriate channel types, such as Memory or File Channels, and fine-tune their capacities to match the anticipated data flow. Embrace horizontal scaling by increasing the instances of channels, sources, and sinks, enabling parallel processing and enhancing scalability.
49. List all of the accessible interceptors.
Ans:
- Timestamp Interceptor
- Host Interceptor
- Static Interceptor
- UUID Interceptor
- Search and Replace Interceptor
50. Difference between durable and transient channels in Flume?
Ans:
A durable channel is one that persists data on the disk and survives agent restarts, providing fault tolerance. In contrast, a transient channel only stores data in memory and does not survive agent restarts. Durable channels are suitable for scenarios where data persistence is critical.
51. Explain Avro source in Flume.
Ans:
The Avro source in Flume allows ingestion of data through the Avro protocol. It enables data to be sent to the Flume in a structured format, making it suitable for scenarios where schema evolution is more important.
52. How can you secure data transmission in Flume?
Ans:
- Data transmission in Flume can be secured by enabling encryption and authentication.
- Flume supports the SSL/TLS for securing communication between agents.
- Additionally, can use authentication mechanisms like Kerberos to ensure secure data transfer.
53. Explain Spooling Directory source in Flume.
Ans:
The Spooling Directory source is used to ingest data from files in a specified directory. It monitors the directory for new files and reads their contents, sending the data to the configured channel. This source is useful for the scenarios where data is generated by an external application and saved to files.
54. What is MorphlineInterceptor in Flume?
Ans:
The MorphlineInterceptor in Flume integrates with Cloudera’s Morphlines framework, allowing it to define flexible and dynamic transformations on the event data. It is useful for tasks such as data enrichment, extraction, and transformation before a data reaches the sink.
55. How can configure load balancing in Flume for better performance?
Ans:
- Load balancing in Flume can be achieved by configuring multiple agents with the same source.
- The load will be distributed among agents, enhancing performance.
- Load balancing can be further improved by adjusting batch sizes and channel capacities.
56. Explain Fan-out and Fan-in patterns in Flume.
Ans:
Fan-out: This pattern involves the distributing data from a single source to multiple channels or agents. It helps in parallelizing processing of data.
Fan-in: This pattern involves the consolidating data from the multiple sources into a single channel or agent. It is useful for aggregating data from different streams.
57. What is the Memory Channel in Flume?
Ans:
The Memory Channel is the in-memory channel in Flume that stores events in the RAM. It is suitable for the scenarios where low-latency and high-throughput event processing is required. However, it is not persistent and may lose data in case of agent restart.
58. How does Flume handle data delivery guarantees?
Ans:
Flume provides the three types of data delivery guarantees:
At most once: Data may be lost but will not be duplicated.
At least once: Data may be duplicated but will not be lost.
Exactly once: Ensures data is neither lost nor duplicated.
59. What is the significance of the Interceptor chain in Flume?
Ans:
The Interceptor chain in Flume is the sequence of interceptors that process events before reaching the sink. Interceptors can modify, filter, or enhance events, providing flexibility in the customizing data flow.
60. How does Flume handle backpressure?
Ans:
Flume employs mechanisms such as channel capacities and transactional boundaries to handle back pressure. If the channel reaches its capacity, the source may slow down or stop until the channel can accept more events. This helps to prevent overwhelming downstream components.
61. Explain the use case for Exec source in Flume.
Ans:
The Exec source in Flume is used to execute the command and ingest its output as events. It allows Flume to capture data generated by external processes, making it suitable for the scenarios where data is produced outside the Flume ecosystem.
62. What is Null Sink in Flume?
Ans:
- The Null Sink in Flume is the sink that discards events without persisting them.
- It is often used for testing or scenarios where certain events are not required to be stored.

Get JOB Oriented Apache Storm Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
63. Explain Timestamp Interceptor in Flume.
Ans:
The Timestamp Interceptor in the Flume adds a timestamp to the event header, indicating when the event was processed by the source. This can be useful for tracking the time at which events enter the Flume pipeline.
64. How can monitor and manage performance of Flume agents?
Ans:
- Flume provides the tools and interfaces for monitoring and managing agent performance.
- The Flume web UI, metrics, and log files are the valuable resources for understanding agent behavior.
- Additionally, tools like Apache Ambari can be used for centralized management.
65. Explain TailDir source in Flume.
Ans:
The TailDir source in Flume is used to continuously monitor directory for new log files and tail their contents. It is particularly useful for the scenarios where log data is generated and appended to files in real-time.
66. What is JMS (Java Message Service) source in Flume?
Ans:
- The JMS source in Flume allows ingestion of messages from a JMS provider.
- It facilitates integration of Flume with messaging systems that adhere to a JMS standard.
67. What is RpcSink in Flume?
Ans:
The RpcSink in Flume allows events to be sent to the remote Flume agent using the Avro protocol. It enables distributed data processing by forwarding events to another Flume agent for further processing or storage.
68. Explain use case for Thrift source in Flume.
Ans:
- The Thrift source in Flume allows ingestion of events through the Apache Thrift protocol.
- It is useful for the scenarios where cross-language support and efficient serialization are important.
69. What is Ganglia Sink in Flume?
Ans:
The Ganglia Sink in Flume is used for the monitoring and reporting of Flume metrics to the Ganglia server. It enables integration with Ganglia monitoring systems for real-time performance tracking.
70. How can you configure Flume for secure data transmission using SSL/TLS?
Ans:
- To enable secure data transmission in Flume, can configure SSL/TLS properties in a source, channel, and sink components.
- This involves specifying keystore and truststore locations, setting an encryption algorithm, and enabling the SSL/TLS communication.
71. Explain use case for Twitter Source in Flume.
Ans:
- The Twitter Source in Flume is used to ingest real-time data from Twitter.
- It allows users to track specific keywords, hashtags, or user streams and capture relevant tweets for the analysis or storage.
72. What is Enrichment Interceptor in Flume?
Ans:
The Enrichment Interceptor in Flume is used to add additional metadata or context to events as they pass through the pipeline. This metadata can be derived from the external data sources and helps in enhancing information associated with events.
73. How can you configure Flume to handle data compression?
Ans:
Flume supports the data compression for events. You can configure compression settings in a source, channel, or sink components to reduce the amount of data transferred and stored.
74. Explain Regex Extractor Interceptor in Flume.
Ans:
- The Regex Extractor Interceptor in Flume allows to extract data from event bodies using regular expressions.
- It is useful for parsing and extracting specific information from an event payload for further processing.
75. How can configure Flume to use third-party interceptors?
Ans:
To use third-party interceptors or serializers in Flume, you need to place the external JAR files containing the custom classes in a Flume classpath. Afterward, can configure Flume components to use these custom classes by specifying fully qualified class names.
76. Explain Custom Sink in Flume.
Ans:
The Custom Sink in Flume allows the users to implement their own custom sinks by extending the AbstractSink class. This provides the way to integrate Flume with the specific data storage systems or processing logic not covered by built-in sinks.
77. What is Spooling Directory Source in Flume?
Ans:
The Spooling Directory Source in Flume is used to ingest data from files in a specified directory. It continuously monitors directory for new files and reads their contents, making it suitable for the scenarios where data is generated by the external applications and saved to files.
78. What is Backoff configuration in Flume?
Ans:
- The Backoff configuration in Flume is used to handle the scenarios where a sink or source encounters errors.
- It introduces the delays between retries, preventing continuous retries and allowing the system to recover from transient failures.
79. Explain Syslog Sink in Flume.
Ans:
The Syslog Sink in Flume is used to forward the events to a syslog server. It converts the Flume events into syslog messages and sends them to the specified syslog server, making it suitable for integrating Flume with the systems that support syslog.
80. How can you configure Flume for high-throughput data ingestion?
Ans:
To configure Flume for a high-throughput data ingestion, consider using high-throughput sources, like Avro or Thrift sources, optimizing buffer sizes, increasing batch sizes, and tuning channel capacities. Load balancing across the multiple agents can also enhance throughput.
81. What is Metrics Sink in Flume?
Ans:
- The Metrics Sink in Flume is used to collect and report the internal metrics about the Flume agent’s performance.
- It allows the users to monitor and analyze various metrics, like event throughput, channel sizes, and sink processing times.
82. What is Hive Sink in Flume?
Ans:
The Hive Sink in Flume is used to write the events to Apache Hive, which is a data warehouse system for Hadoop. It facilitates a storage of event data in Hive tables, making it suitable for the scenarios where structured storage and querying are essential.
83. Explain use case for HTTP Sink in Flume.
Ans:
The HTTP Sink in Flume is used to send events to the HTTP endpoint. It allows Flume to communicate with external systems, such as web services or databases, by posting events to the specified URLs.
84. How handle data encryption in Flume for secure transmission?
Ans:
- To handle data encryption in Flume, can configure SSL/TLS settings in a source, channel, and sink components.
- This ensures that data is encrypted during transmission, providing a secure communication channel.
85. What is BlobDeserializer in Flume?
Ans:
The BlobDeserializer in Flume is the deserializer that treats the entire event body as a binary blob. It is useful when dealing with the non-textual data formats or scenarios where the event payload is a binary.
86. Explain Thrift Rpc Source in Flume.
Ans:
- The Thrift Rpc Source in Flume is used to ingest the events through the Thrift RPC (Remote Procedure Call) protocol.
- It allows for remote communication between different components in a Flume system or with an external system supporting Thrift.
87. How does Flume handle transactional semantics in channel?
Ans:
Flume handles the transactional semantics in the channel by using transactions to ensure atomicity of event processing. This ensures that either all events in the transaction are successfully processed or none of them are, preventing partial data inconsistencies.
88. What is GrokInterceptor in Flume?
Ans:
- The GrokInterceptor in Flume is used for pattern matching and extraction of structured data from the unstructured log events.
- It allows the users to define patterns using Grok syntax to parse log events and extract meaningful information.
89. Explain Load Balancer Source Selector in Flume.
Ans:
The Load Balancer Source Selector in the Flume is used to evenly distribute events among the multiple sources. It ensures that each source in configuration receives a fair share of events, facilitating load balancing in the Flume setup.
90. What is Elasticsearch Sink in Flume?
Ans:
The Elasticsearch Sink in the Flume is used to index events into the Elasticsearch cluster. It allows for a real-time indexing of event data, making it searchable and analyzable through the Elasticsearch.




