
Last updated on 03rd Jul 2020| 1968
In our cassandra interview questions, we cover a broad spectrum of topics related to this distributed NoSQL database, assessing candidates’ comprehension of Cassandra architecture, data modeling, and operational elements. Candidates might encounter questions delving into concepts such as eventual consistency, the CAP theorem, and the significance of the partition key in Cassandra data modeling. Proficiency in CQL (Cassandra Query Language) is frequently evaluated, encompassing knowledge of primary keys, clustering columns, and composite keys. Interrogations may also address Cassandra’s fault tolerance mechanisms, anti-entropy repair, and strategies for enhancing read and write performance. Additionally, we explore candidate’s familiarity with the nodetool utility, the function of the commit log, and the utilization of compaction in data storage. Demonstrating robust problem-solving abilities, a grasp of distributed systems, and hands-on experience in deploying and maintaining Cassandra clusters are pivotal for success in interviews related to Cassandra.
1. What is Apache Cassandra?
Ans:
Apache Cassandra is an open-source, distributed NoSQL database management system designed to handle large amounts of data across many commodity servers, providing high availability and fault tolerance. It was initially developed at Facebook and later open-sourced as an Apache project. Cassandra is designed to handle massive amounts of data and transactions across a distributed network of nodes without a single point of failure.
2. Explain the key features of Cassandra.
Ans:
- Distributed and Decentralised: Cassandra distributes data across multiple nodes, eliminating single points of failure.
- High Availability: It ensures data availability even in the face of node failures.
- Linear Scalability: Cassandra can scale horizontally by adding more nodes to the cluster to handle increased load.
- Fault Tolerance: Data is replicated across nodes, ensuring data availability in case of node failures.
- Tunable Consistency: Cassandra allows users to choose between consistency and availability based on their application requirements.
- No Single Point of Failure: Cassandra has a peer-to-peer architecture with no single point of failure.
3. What are the main components of Cassandra?
Ans:
- Node: A single machine in the Cassandra cluster.
- Data Center: A collection of related nodes.
- Cluster: The complete Cassandra database that spans all nodes and data centres.
- Commit Log: A crash-recovery mechanism for storing write operations before they are written to the actual data files.
- Memtable: An in-memory data structure used for write operations.
- SSTable (Sorted String Table): An on-disk, persistent data structure used for read operations.
4. How does Cassandra achieve high availability?
Ans:
Cassandra achieves high availability through replication. Data is replicated across multiple nodes in a cluster, and each node can serve as a replica for another. In case of a node failure, data can be retrieved from other replicas, ensuring that the system remains available even if some nodes go down.
5. Describe the architecture of Cassandra.
Ans:
Cassandra has a decentralised, peer-to-peer architecture. Each node in the cluster is equal, and there is no single point of failure. Data is partitioned and distributed across nodes using a consistent hashing algorithm. Read and write operations are coordinated through a combination of gossip protocol and partitioning.
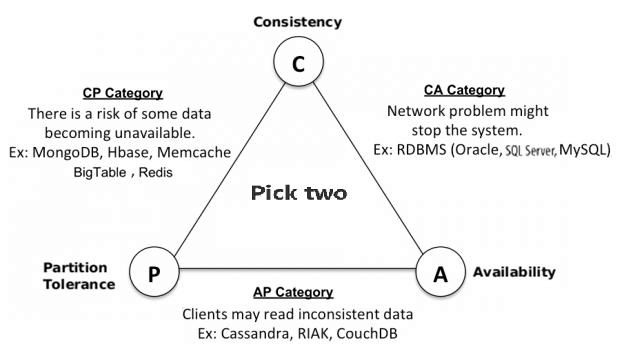
6. What is the CAP theorem, and how does Cassandra adhere to it?
Ans:
The CAP theorem states that a distributed system cannot simultaneously provide all three guarantees: Consistency, Availability, and Partition tolerance. Cassandra is designed to provide both Availability and Partition tolerance (AP), allowing for high availability and fault tolerance even in the presence of network partitions. It sacrifices strong consistency in certain situations to achieve this.
7. Explain the concept of eventual consistency in Cassandra.
Ans:
Cassandra follows the principle of eventual consistency, meaning that given enough time, all replicas of a piece of data will converge to the same value. During network partitions or failures, Cassandra may allow inconsistent reads, but it ensures that consistency is eventually reached.
8. What is the use of the Cassandra Query Language (CQL)?
Ans:
CQL is a query language for interacting with Cassandra databases. It is similar to SQL but adapted to fit the NoSQL nature of Cassandra. CQL allows users to create, update, and query data using a syntax that is familiar to those accustomed to working with relational databases.
9. Differentiate between NoSQL and traditional relational databases.
Ans:
- NoSQL databases like Cassandra are designed for horizontal scalability, handling large amounts of unstructured or semi-structured data, and providing high availability. They often sacrifice strong consistency for performance.
- Traditional relational databases follow a structured, tabular data model and provide ACID properties (Atomicity, Consistency, Isolation, Durability). They are suitable for applications with complex relationships and transactions.
10. How does Cassandra handle write and read operations?
Ans:
- Write Operations: Writes in Cassandra are first stored in a commit log for crash recovery and then written to an in-memory data structure called the memtable. Periodically, the memtable is flushed to disk as an SSTable. Data is also replicated to other nodes based on the configured replication factor.
- Read Operations: Cassandra uses a partition key to determine the node responsible for a particular piece of data. Read operations are performed by querying the appropriate node or nodes based on the partition key, and data is retrieved from the SSTables on disk. Replicas can be used if the primary node is unavailable.
11. What is a keyspace in Cassandra?
Ans:
In Cassandra, a keyspace is the outermost container for data. It is a namespace that defines how data is replicated on nodes in a cluster. A keyspace holds one or more column families, which are the basic unit of organisation for data storage in Cassandra. Keyspaces also define replication strategies and various configuration options for the data they contain.
12. Explain the role of a column family in Cassandra.
Ans:
A column family in Cassandra is a container for rows of data that share the same schema. It is roughly equivalent to a table in a relational database. Each row in a column family is identified by a unique primary key, and the columns within a row are organised into column families. Column families in Cassandra provide flexibility in terms of the data they can hold, as different rows within the same column family can have different columns.
13. Describe the purpose of a primary key in Cassandra.
Ans:
The primary key in Cassandra uniquely identifies a row in a column family. It consists of one or more columns that serve as identifiers for the data. The primary key is crucial for efficient data retrieval and distribution across the nodes in a cluster. It is also used to determine the partitioning of data and plays a role in the distribution and replication of data in a Cassandra cluster.
14. What are the types of primary keys in Cassandra?
Ans:
- Simple Primary Key: Consists of a single column, which uniquely identifies each row.
- Composite Primary Key: Consists of multiple columns, where the combination of values uniquely identifies each row. This is particularly useful for cases where a single column is not sufficient for uniqueness.
15. Explain the difference between a partition key and a clustering key.
Ans:
| Criteria | Partition Key | Clustering Key | |
| Definition |
Determines how data is spread across partitions. |
Specifies the order of data within a partition. | |
| Usage in Partitioning | Essential for every table; defines the partitioning scheme. | Optional; a table can exist without a clustering key. | |
| Uniqueness |
Requires unique values within the table’s partition. |
Requires unique values within a partition. | |
| Data Distribution | Facilitates horizontal data distribution across nodes or servers. | Organizes data within a partition in a sorted manner for optimized queries. | |
| Query Efficiency |
Used in the WHERE clause for filtering data and improving cross-partition query performance. |
Used in the ORDER BY clause for arranging data within a partition, enhancing range query efficiency. | |
| Example |
For a user data table, a suitable partition key might be “Country” for data distribution based on countries. |
In the same user data table, a clustering key like “Last Login Date” could order users within each country partition. |
16. How does data distribution work in Cassandra?
Ans:
- Data distribution in Cassandra is achieved through the use of a partition key. The partition key is responsible for determining the distribution of data across nodes in the cluster.
- Each row in a Cassandra table is identified by a unique primary key, which consists of the partition key and, optionally, clustering columns.
- The values of the partition key are hashed, and the hash determines which node in the cluster will be responsible for storing that particular piece of data.
- Even distribution of data across nodes is crucial for achieving load balancing and ensuring that no single node becomes a bottleneck.
17. What is denormalization, and why is it important in Cassandra?
Ans:
- Denormalization in the context of Cassandra involves storing redundant data or duplicating data across multiple tables or column families.
- This is done to optimize read performance and to avoid the need for complex joins, which are not natively supported in Cassandra.
- Denormalization is important in Cassandra because it allows for efficient querying and retrieval of data without the need for multiple complex operations to assemble the complete result.
18. Discuss the importance of choosing the right data types in Cassandra.
Ans:
- The choice of data types in Cassandra is important for both storage efficiency and application requirements.
- Cassandra supports various data types, including text, numeric, UUID, timestamp, and more.
- Choosing appropriate data types helps in minimizing storage space, improving query performance, and ensuring that data is represented accurately.
- Understanding the nature of the data and the requirements of the queries helps in selecting the most suitable data types.
19. What is a secondary index in Cassandra?
Ans:
- In Cassandra, a secondary index allows for querying data based on a column that is not the primary key or a clustering column.
- While primary keys and clustering columns are optimized for efficient data retrieval, secondary indexes provide additional flexibility for querying.
- However, the use of secondary indexes should be done judiciously, as they may impact performance and add overhead, especially in large datasets. Reliance on secondary indexes can lead to performance issues and is generally discouraged for high-throughput systems.
20. How is CQL different from SQL?
Ans:
CQL (Cassandra Query Language):
- CQL is specific to Cassandra and is used to interact with Cassandra databases.
- It shares similarities with SQL, making it more accessible to users familiar with relational databases.
- CQL supports the definition of keyspaces, column families, and querying using a syntax similar to SQL.
- It is designed to work with the distributed and decentralised architecture of Cassandra.
SQL (Structured Query Language):
- SQL is a standard language for relational databases used in systems like MySQL, PostgreSQL, and Oracle.
- SQL is more expressive and supports complex queries, joins, and transactions, which are not natively supported in Cassandra.
- Unlike CQL, SQL assumes a centralised, tabular data structure, which is different from the decentralised, distributed nature of Cassandra.
21. Explain the syntax of basic CQL commands.
Ans:
Syntax of Basic CQL Commands:
Creating a Keyspace:
- CREATE KEYSPACE
- WITH REPLICATION = {‘class’: ‘
‘, ‘replication_factor’: };
Using a Keyspace:
- USE
;
Creating a Table:
- CREATE TABLE
( , , - PRIMARY KEY (
) - );
Inserting Data:
- INSERT INTO
( , , …) - VALUES (
, , …);
Querying Data:
- SELECT
, , … - FROM
- WHERE
;
22. What is a batch statement in CQL?
Ans:
- A batch statement in CQL allows you to group multiple DML (Data Manipulation Language) statements (INSERT, UPDATE, DELETE) into a single atomic operation.
- This ensures that either all or none of the statements in the batch are executed.
Example:
BEGIN BATCH
- INSERT INTO
( , ) VALUES ( , ); - UPDATE
SET = WHERE ; - APPLY BATCH;
23. How does CQL support conditional updates?
Ans:
CQL supports conditional updates, allowing you to specify conditions that must be met for an update to be applied.
Example:
- UPDATE
- SET
= - WHERE
- IF
;
24. Discuss the purpose of the ALLOW FILTERING option in CQL queries.
Ans:
- The ALLOW FILTERING option is used in queries where filtering is performed on a non-indexed column.
- It allows the retrieval of data even if the filtering condition involves non-indexed columns.
- However, using ALLOW FILTERING can lead to performance issues, and its use should be minimised.
25. What is the role of the CONSISTENCY level in CQL?
Ans:
- The CONSISTENCY level in CQL defines the level of consistency required for a read or write operation.
- Examples of consistency levels include ONE, QUORUM, ALL, etc.
- The choice of consistency level balances data consistency and availability, allowing developers to tailor it based on the application’s requirements.

Learn Hands-on Experience from Cassandra Certification Training Course
Weekday / Weekend BatchesSee Batch Details26. Explain the use of the TOKEN function in CQL.
Ans:
- The TOKEN function in CQL is used for calculating the token of a partition key.
- It is often used in advanced queries and data modelling to understand and manipulate the distribution of data across nodes in a Cassandra cluster.
27. What is the purpose of the WRITETIME and TTL options in CQL?
Ans:
- The WRITETIME option in CQL allows you to retrieve the timestamp of the last modification to a column.
- The TTL (Time-To-Live) option is used to set an expiration time for data. Data with TTL will be automatically deleted after the specified time.
28. What is data partitioning in Cassandra?
Ans:
- Data partitioning in Cassandra involves distributing data across nodes based on a partition key.
- The partition key determines the node responsible for storing a particular piece of data.
- Well-chosen partition keys are crucial for even data distribution, efficient querying, and preventing hotspots in the cluster.
29. How does Cassandra ensure fault tolerance?
Ans:
- Cassandra achieves fault tolerance through data replication. Each piece of data is replicated across multiple nodes in the cluster.
- If a node fails, data can be retrieved from replicas on other nodes.
- The number of replicas and their placement in the cluster are configurable, allowing developers to balance fault tolerance, performance, and storage requirements.
30. Explain the concept of replication in Cassandra.
Ans:
- Replication in Cassandra involves copying data to multiple nodes to ensure availability and fault tolerance.
- The replication strategy is defined at the keyspace level and can be configured based on factors like the replication factor and placement strategy.
- Cassandra supports strategies like SimpleStrategy and NetworkTopologyStrategy for replication. The choice depends on the cluster architecture and requirements.
31. What is a replication factor, and how does it affect data consistency?
Ans:
- The replication factor in Cassandra determines the number of replicas (copies) of each piece of data stored across the cluster.
- A higher replication factor improves fault tolerance but can affect write performance and storage requirements.
- The replication factor influences Data consistency. In a write operation, Cassandra must write the data to the specified number of replicas before considering the write successful. The consistency level (e.g., ONE, QUORUM) further dictates how many replicas must acknowledge the writer for it to be considered consistent.
32. Describe the snitch in Cassandra and its role in data centre awareness.
Ans:
- The snitch in Cassandra is responsible for determining the network topology of the nodes in the cluster, helping Cassandra be aware of the physical location of nodes.
- It assists in data centre awareness, ensuring that data is distributed intelligently based on the network topology.
- Different snitches are available, such as SimpleSnitch, GossipingPropertyFileSnitch, and NetworkTopologyStrategy, allowing users to configure how nodes are organised and how data is replicated across data centres.
33. What is the role of a seed node in Cassandra?
Ans:
- A seed node is a configuration option in Cassandra that acts as a reference point for other nodes to join the cluster.
- Seed nodes help new nodes discover the cluster and establish communication.
- Seed nodes are important for the initial bootstrap process of a node joining the cluster.
34. How can you optimise read performance in Cassandra?
Ans:
- Use appropriate data modelling with efficient partition keys to distribute data evenly.
- Consider denormalization to reduce the need for complex joins.
- Adjust the read consistency level based on the application’s requirements.
- Utilise caching mechanisms, like Cassandra’s built-in row cache or external caching solutions.
- Use secondary indexes judiciously, as they may impact read performance.
35. Explain the factors that influence write performance in Cassandra.
Ans:
- Choose an optimal partition key to ensure even data distribution.
- Batch small, frequent writes into larger batches for efficiency.
- Adjust the write consistency level based on the desired level of durability. Use asynchronous writes when appropriate to improve write throughput.
- Optimise the disk I/O subsystem for write operations.
36. What is compaction, and why is it important in Cassandra?
Ans:
- Compaction is the process of merging and compacting SSTables to reclaim disk space and improve read performance.
- It helps eliminate obsolete or overwritten data and reduces the number of SSTables.
- There are different compaction strategies in Cassandra, such as SizeTieredCompactionStrategy and LeveledCompactionStrategy, each with its characteristics.
37. How can you monitor and tune the garbage collection in Cassandra?
Ans:
- Monitoring garbage collection (GC) is crucial to ensuring system stability and performance.
- Configure JVM options for garbage collection according to Cassandra’s recommendations.
- Use tools like JVisualVM or GC logs to analyse and tune garbage collection settings.
- Adjust heap sizes based on workload and available system resources.
38. Discuss the importance of the Bloom filter in Cassandra.
Ans:
- A Bloom filter is a probabilistic data structure used to test whether a particular element is a member of a set.
- In Cassandra, Bloom filters are used to reduce the number of disk reads during read operations.
- Bloom filters help quickly determine if data may be present in an SSTable, reducing the need to access the actual data on disk unnecessarily.
39. What is the purpose of the memtable in Cassandra?
Ans:
- The memtable is an in-memory data structure used to temporarily store write operations before they are written to disk.
- Write operations are first stored in the memtable for efficiency.
- Once the memtable reaches a threshold, it is flushed to disk as an SSTable.
40. How do you install and configure Cassandra?
Ans:
- Download the Cassandra distribution from the official website.
- Extract the downloaded archive to a suitable location on your system.
- Configure Cassandra. yaml file to set options such as cluster name, seeds, snitch, and data directory.
- Start Cassandra using the appropriate command (bin/Cassandra).
- Optionally, configure and start the CQL shell (bin/cqlsh) for interacting with Cassandra using CQL.
- Monitor logs and use tools like node tools to verify the status of the cluster.

Enroll in Cassandra Training with Industry Oriented Modules from Expert Instructors
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. Explain the role of the commit log in Cassandra.
Ans:
The commit log in Cassandra serves as a crash recovery mechanism for write operations.
- Before data is written to the actual data files (SSTables), it is first written to the commit log.
- In the event of a node failure or crash, the commit log is used to recover any write operations that were in progress at the time of the failure.
42. What is the purpose of the system keyspace in Cassandra?
Ans:
- The system keyspace in Cassandra contains internal tables that store metadata and configuration information.
- It includes information about keyspaces, tables, column families, and other system-related data.
- Users typically do not interact directly with the system keyspace, but it is crucial for the proper functioning and management of the Cassandra cluster.
43. How can you back up and restore data in Cassandra?
Ans:
- To back up data in Cassandra, you can use tools like the node tool to create snapshots of keyspaces.
- Snapshots are stored in the snapshots directory in each node’s data directory. To restore data, you can copy the snapshot files back to the original data.
- directory and use the node tool to restore the data.
44. Discuss the node tool utility in Cassandra.
Ans:
- Nodetool is a command-line utility that provides various operations for managing and monitoring a Cassandra cluster.
- It can be used for tasks such as viewing cluster information, managing nodes, taking snapshots, running repairs, and more.
- Examples of node tool commands include node tool status, node tool snapshot, and nodetool repair.
45. What is the purpose of the gossip protocol in Cassandra?
Ans:
- The gossip protocol is used by nodes in a Cassandra cluster to exchange information about the cluster’s state and topology.
- Nodes gossip with each other to share details about their status, load, and other relevant information.
- Gossip helps maintain an eventually consistent view of the cluster across all nodes.
46. Explain how repair operations work in Cassandra.
Ans:
- Repair operations in Cassandra are used to synchronise data between replicas and ensure consistency across nodes.
- The repair process identifies and corrects inconsistencies in data by comparing data between replicas and bringing them into alignment.
- Repair operations can be scheduled and initiated using nodetool repair.
47. How does authentication work in Cassandra?
Ans:
- Cassandra supports various authentication mechanisms, including PasswordAuthenticator, LDAP, and more.
- Authentication is configured in the Cassandra. yaml file.
- Users and their credentials are defined in the system_auth keyspace.
- Authentication mechanisms can be customised to integrate with external authentication systems.
48. What is the role of the Cassandra role manager?
Ans:
- The role manager in Cassandra is responsible for managing user roles and their associated permissions.
- Role-based access control (RBAC) is implemented through the role manager.
- Users are assigned roles, and roles are granted specific permissions on keyspaces, tables, and other resources.
49) Discuss the importance of SSL in securing Cassandra clusters.
Ans:
- SSL (Secure Sockets Layer) is essential for securing communication between nodes in a Cassandra cluster.
- SSL can be used to encrypt data transmitted between nodes, preventing eavesdropping and unauthorised access.
- It is especially important in production environments and when dealing with sensitive data.
- SSL can be configured in Cassandra. yaml files and certificates can be generated and managed for each node.
50. Cassandra supports encryption in transit and at rest.
Ans:
- To enable encryption in transit, SSL/TLS can be configured in the Cassandra—yaml file.
- For encryption at rest, Cassandra can be integrated with third-party tools or filesystem-level encryption.
- Full-disk encryption or filesystem-level encryption options can be utilised for encrypting the data stored on disk.
51. How can you implement data encryption in Cassandra?
Ans:
- Common issues include performance bottlenecks, nodetool errors, and data consistency problems.
- Troubleshoot using nodetool commands for status, repair, and compaction.
- Analyse the system, and Cassandra logs for error messages.
- Monitor system resources (CPU, memory, disk) using tools like top and iostat.
52. What are some common issues in Cassandra, and how would you troubleshoot them?
Ans:
- Use nodetool for real-time monitoring and diagnostics.
- Utilise tools like Prometheus and Grafana for comprehensive cluster monitoring.
- Set up alerts based on key metrics such as latency, compaction, and disk usage.
- Monitor and analyse system and Cassandra logs for warnings and errors.
53. How can you monitor the performance of a Cassandra cluster?
Ans:
- JMX (Java Management Extensions) is used for monitoring and managing Java applications.
- Cassandra exposes JMX metrics that can be monitored using tools like JConsole or third-party monitoring solutions.
- JMX metrics provide insights into various aspects of Cassandra, including node status, heap usage, compaction, and more.
54. Explain the role of JMX in monitoring Cassandra.
Ans:
- Hinted handoff is a mechanism in Cassandra that temporarily stores writes on a coordinator node when a replica is unavailable.
- Once the replica becomes available, a hinted handoff delivers the writes to the replica.
- This mechanism ensures that writes are not lost during temporary node unavailability.
55. What is a hinted handoff, and how does it work in Cassandra?
Ans:
- Cassandra integrates seamlessly with Apache Spark for advanced analytics and processing.
- The Spark Cassandra Connector enables reading and writing data between Cassandra and Spark.
- This integration allows Spark to leverage the distributed nature of Cassandra for data processing tasks.
56. How does Cassandra integrate with Apache Spark?
Ans:
- Cassandra can be integrated with Hadoop through tools like Apache Hadoop MapReduce and Apache Hive.
- The integration allows for running analytics and processing on data stored in Cassandra using Hadoop’s distributed computing capabilities.
57. Discuss the integration of Cassandra with Hadoop.
Ans:
- Cassandra can be integrated with Hadoop through tools like Apache Hadoop MapReduce and Apache Hive.
- The integration allows for running analytics and processing on data stored in Cassandra using Hadoop’s distributed computing capabilities.
58. Explain the role of Cassandra in a microservices architecture.
Ans:
- Cassandra is well-suited for microservices architectures due to its scalability, high availability, and flexible data model.
- Microservices can independently interact with Cassandra clusters for data storage and retrieval.
- Cassandra’s decentralised architecture aligns with the distributed nature of microservices.
59. What is the purpose of the Cassandra Connector for Apache Kafka?
Ans:
- The Cassandra Connector for Apache Kafka allows for the integration of Cassandra and Kafka.
- It enables the movement of data between Kafka topics and Cassandra tables.
- This integration supports real-time data streaming from Kafka to Cassandra, facilitating data synchronisation.
60. What is the purpose of the Cassandra Tombstones?
Ans:
- Tombstones in Cassandra represent deleted data.
- When data is deleted, a tombstone is written to indicate the deletion.
- Tombstones ensure that deleted data is propagated across replicas during compaction and prevent data resurrection.
61. Explain the lightweight transactions in Cassandra.
Ans:
- Lightweight transactions in Cassandra provide support for atomic and isolated operations.
- IF clauses in CQL statements enable conditional updates based on the existing value of a column.
- These transactions help maintain consistency in scenarios where strong consistency is required without sacrificing overall system performance.
62. How does Cassandra handle multi-data centre deployments?
Ans:
- Cassandra is designed to support multi-data centre deployments.
- The NetworkTopologyStrategy allows you to define replication strategies across different data centres.
- Replication can be configured to ensure high availability and fault tolerance across geographically distributed clusters.
- Use of data centre-aware snitches helps optimise data distribution and routing.
63. What is the role of the virtual nodes (vnodes) feature in Cassandra?
Ans:
- Virtual nodes (vnodes) simplify the assignment of tokens to nodes, making it easier to add or remove nodes from the cluster.
- Vnodes improve the distribution of data across the cluster, reducing hotspots.
- They also simplify the process of scaling the cluster horizontally by evenly distributing tokens among nodes.
64. Discuss the use of materialised views in Cassandra.
Ans:
- Materialised views in Cassandra provide a way to create and query secondary indexes on columns other than the primary key.
- Materialised views are automatically updated when the base table is modified, ensuring consistency.
- They are useful for supporting different query patterns and improving read performance.
65. Explain the role of compaction strategies in Cassandra.
Ans:
- Compaction is the process of merging SSTables to reclaim disk space and improve read performance.
- Cassandra supports various compaction strategies, including SizeTieredCompactionStrategy and LeveledCompactionStrategy.
- The choice of compaction strategy depends on factors such as write and read patterns, disk I/O characteristics, and intended query performance.
66. What are the best practices for designing an effective data model in Cassandra?
Ans:
- Understand the queries your application will perform and model data accordingly.
- Choose appropriate primary keys, partition keys, and clustering columns.
- Avoid over-reliance on secondary indexes, as they can impact performance.
- Denormalize data when necessary to optimise read performance.
- Optimise data modelling for the specific requirements of your application.
67. How do you handle time-series data in Cassandra?
Ans:
- Use time stamped data as the primary key to support time-based queries.
- Leverage time-window compaction strategies for optimal storage and retrieval of time-series data.
- Consider using a combination of partition key and clustering columns to organise data effectively.
68. Discuss the concept of wide rows in Cassandra.
Ans:
- Wide rows in Cassandra refer to rows with a large number of columns.
- This model is suitable for scenarios where data is sparse or when there are many columns associated with a particular partition key.
- Wide rows can be used for time-series data or scenarios where data varies over time.
69. How can you implement counters in Cassandra?
Ans:
- Cassandra supports counter data types for incrementing and decrementing numeric values.
- Counters are designed for scenarios where atomic updates are essential, such as tracking page views or likes.
- Counter values are stored as a distributed and eventually consistent counter across nodes.
70. Explain when to use composite keys in Cassandra.
Ans:
- Composite keys in Cassandra involve combining multiple columns to create a composite primary key.
- Use composite keys when the application requires queries with multiple conditions.
- They are suitable for modelling relationships or representing complex queries.
71. How can you automate the deployment of Cassandra clusters?
Ans:
- Tools like Apache Cassandra’s cassandra-docker and Docker Compose can be used for deploying Cassandra clusters in containers.
- Automation tools like Ansible, Chef, or Puppet can be employed for configuring and managing Cassandra clusters across nodes.
72. Discuss the use of containers (e.g., Docker) with Cassandra.
Ans:
- Containers, such as Docker, are useful for packaging and deploying Cassandra instances consistently across environments.
- Docker Compose can be employed for orchestrating multi-container Cassandra deployments.
- Containers provide isolation, flexibility, and ease of deployment.
73. Explain the role of configuration management tools in Cassandra.
Ans:
- Configuration management tools like Ansible, Chef, and Puppet help automate the deployment and configuration of Cassandra clusters.
- They ensure consistent configuration across nodes in the cluster, simplifying management and reducing errors.
74. Describe a scenario where you would choose Cassandra over other databases.
Ans:
- Choose Cassandra for scenarios that require high write and read throughput, horizontal scalability, and fault tolerance.
- Well-suited for time-series data, event logging, and scenarios with large amounts of data.
- Appropriate for applications demanding high availability and low-latency data access.
75. How would you design a schema to handle a high-volume write-intensive workload?
Ans:
- Opt for a schema that minimises contention on the same partition key.
- Use appropriate compaction strategies based on write patterns.
- Leverage time-series data modelling for efficient storage and retrieval.
- Tune consistency levels based on the required balance between consistency and performance.
- Consider using counters for scenarios requiring atomic increment/decrement operations.
76. Discuss strategies for handling data migrations in Cassandra.
Ans:
Add a New Column:
- Introduce a new column to the existing schema, ensuring that new data adheres to the updated schema.
- Migrate existing data gradually as it’s accessed or through a batch process.
Batch Migration:
- Use batch scripts to transform and migrate data in chunks.
- This minimises the impact on system resources during migration.
Shadow Tables:
- Create shadow tables with the new schema alongside existing tables.
- Gradually migrate data from old to new tables, maintaining consistency.
Cutover:
- Plan a cutover where the application starts using the new schema.
- Implement mechanisms to handle both old and new schema during the transition.
77. Have you worked with the latest version of Cassandra? What are the new features in the recent release?
Ans:
As of my last update in January 2022, I don’t have information on the latest Cassandra releases. It’s recommended to check the official Cassandra website or release notes for the most recent features and improvements.
78. How does Cassandra support JSON data?
Ans:
- Cassandra supports JSON data through the use of the JSON data type.
- JSON data can be stored and queried, allowing flexibility in handling semi-structured data.
- Queries can be performed using the CONTAINS clause to search within JSON objects.
79. How do you stay updated on the latest developments in the Cassandra community?
Ans:
- Regularly check the official Cassandra website for announcements and release notes.
- Participate in the Cassandra community forums, mailing lists, and social media.
- Follow blogs, webinars, and conferences related to Apache Cassandra.
- Engage with relevant GitHub repositories to track changes and discussions.
80. What online resources and forums do you find most helpful for Cassandra-related questions?
Ans:
- Contributing involves submitting issues, participating in discussions, or providing code/documentation enhancements.
- Useful resources include the Cassandra documentation and community forums like Stack Overflow.
81. Where do you see the future of distributed databases like Cassandra?
Ans:
- Continued growth due to increasing demand for scalable and distributed solutions.
- Enhancements in security, ease of use, and integration with other technologies.
- Ongoing exploration of cloud-native architectures and serverless paradigms.
82. How would you approach scaling a Cassandra cluster to handle increasing load?
Ans:
- Scale horizontally by adding more nodes to distribute the workload.
- Monitor and adjust the partitioning strategy based on data distribution.
- Implement load balancing and ensure optimal performance through appropriate hardware.
83. Discuss the challenges of managing and scaling large Cassandra clusters.
Ans:
Managing and scaling large Cassandra clusters pose challenges such as increased maintenance overhead, complex monitoring, difficulties in even data distribution, coordination complexities, higher risk of node failures, resource utilisation concerns, communication overhead, scaling challenges, schema change impact, and intricate security considerations. Efficiently handling these challenges is crucial for ensuring the performance, availability, and reliability of the distributed database system.
84. Can you share a specific project or use case where you implemented Cassandra successfully?
Ans:
- Maintenance overhead increases with cluster size.
- Monitoring and diagnosing issues become more complex.
- Data distribution challenges may arise, requiring careful planning.
85. What challenges did you face, and how did you overcome them?
Ans:
- Scenario: Implementing a time-series data storage solution for IoT devices.
- Challenges: Managing high write loads and efficiently querying time-based data.
- Solutions: Optimised data modelling with time-series strategies, use of appropriate compaction strategies, and scaling horizontally for increased write throughput.
86. How does Cassandra compare to other NoSQL databases like MongoDB and Couchbase?
Ans:
- Cassandra offers high write throughput, scalability, and fault tolerance.
- MongoDB and Couchbase might excel in scenarios requiring flexible querying or complex data relationships.
- Cassandra is optimised for write-intensive, distributed, and highly available environments.
87. What are the advantages of using Cassandra over traditional relational databases?
Ans:
- Scales horizontally for seamless expansion.
- Optimised for write-heavy workloads.
- Provides fault tolerance through distributed architecture.
- Supports flexible data models, allowing for schema evolution
88. Explain your approach to disaster recovery planning for a Cassandra cluster.
Ans:
- Regularly back up data using snapshot or incremental strategies.
- Store backups in multiple locations for redundancy.
- Establish clear recovery procedures, including node replacement and data restoration.
- Implement monitoring to detect and respond to issues promptly.
89. How do you handle data consistency in the event of a node failure in Cassandra?
Ans:
- Cassandra uses replication to ensure data availability and consistency.
- Read and write consistency levels can be configured based on application requirements.
- Hinted handoff mechanisms help in recovering data from temporarily unavailable nodes.
90. Have you worked with any client libraries for Cassandra (e.g., DataStax Java Driver)? Share your experience.
Ans:
- DataStax Java Driver is commonly used for Java applications.
- Provides features like load balancing, connection pooling, and query execution.
- Choosing the right client library depends on language, application requirements, and compatibility.
91. How does the choice of client library impact the performance of Cassandra’s operations?
Ans:
- Different client libraries may have varying levels of support and optimization.
- Some libraries may provide additional features or better integration with specific programming languages.
- Consider the community support and documentation of the chosen library.
92. Discuss the various backup strategies in Cassandra.
Ans:
- Snapshot Backups: Regularly take snapshots of data directories.
- Incremental Backups: Capture changes since the last backup.
- Nodetool Commands: Use nodetool commands for backups and restores.
93. How do you restore data in Cassandra from a backup?
Ans:
- Stop the Cassandra node.
- Copy the backup files to the appropriate location.
- Start the node and use nodetool refresh or other commands to restore data
94. How do you handle schema changes in a production Cassandra environment?
Ans:
- Plan schema changes during maintenance windows to minimise impact.
- Use tools like nodetool or cqlsh to alter the schema.
- Gradual rollout or A/B testing may be considered for large changes.
95. Explain the impact of schema changes on data consistency.
Ans:
- Schema changes may require updates to existing data.
- During schema changes, it’s crucial to ensure compatibility and minimise downtime.
- Considerations include the use of batches and avoiding simultaneous schema changes across multiple nodes.
96. What are the best practices for securing a Cassandra cluster in a production environment?
Ans:
- Implement network security measures like firewalls.
- Enable SSL/TLS encryption for communication between nodes and clients.
- Properly configure authentication and authorization mechanisms.
- Regularly update and patch both Cassandra and the underlying operating system.
97. How do you manage user roles and permissions in Cassandra?
Ans:
- Use the Cassandra role manager to define roles and assign permissions.
- Roles can be assigned specific privileges on keyspaces, tables, and other resources.
- Regularly audit and review user roles to ensure security.
98. Discuss strategies for protecting sensitive data stored in Cassandra.
Ans:
- Apply encryption mechanisms, both in transit and at rest.
- Implement proper access controls and authentication.
- Regularly audit and monitor access patterns for unusual activities.
99. How does Cassandra handle the global distribution of data in a multi-region setup?
Ans:
- Use the NetworkTopologyStrategy to configure replication across multiple data centres.
- Adjust consistency levels based on the desired balance between consistency and latency.
- Leverage Cassandra’s multi-data centre architecture for fault tolerance and data locality.
100. Discuss the challenges and considerations for deploying a globally distributed Cassandra cluster.
Ans:
- Network latency may impact performance.
- Careful planning is required to optimise data distribution and replication.
- Consistent monitoring and adjustments are necessary to maintain performance across regions.




