
40+ [REAL-TIME] Kibana Interview Questions and Answers
Last updated on 15th Apr 2024, Popular Course
Kibana serves as a robust tool for visualizing and exploring data in conjunction with Elasticsearch. It provides an intuitive interface for analyzing extensive datasets through dynamic dashboards, charts, and graphs. With Kibana, users can swiftly generate visual representations, uncover insights, and monitor real-time metrics. Supporting diverse data sources, it facilitates advanced querying, filtering, and aggregation, empowering users to derive actionable insights. Whether for log analysis, infrastructure monitoring, or business analytics, Kibana proves invaluable in leveraging data for informed decision-making and problem-solving.
1. What’s Kibana, and how does it integrate with Elasticsearch?
Ans:
Kibana is an important open-source analytics and visualization platform designed to work with Elasticsearch. It provides a user-friendly interface for searching, viewing, and interacting with data stored in Elasticsearch indicators. Kibana enables users to perform advanced data analysis and visualize data in colorful maps, tables, and charts. It integrates with Elasticsearch through HTTP requests, exercising Elasticsearch’s peaceful API to execute hunt queries and recoup data. Thus, it is a vital part of the Elastic Stack for logging, covering, and functional intelligence.
2. Explain how an indicator pattern in Kibana is conceptualized.
Ans:
The way that Kibana should pierce the data in Elasticsearch indications is explained by the indicator pattern. An indicator pattern corresponds to one or more Elasticsearch indicators, enabling users to aggregate and analyze data from several sources simultaneously. Index patterns are essential for building dashboards and visualizations in Kibana since they indicate which data should be queried for perceptivity. Users can generate indicator patterns to match a single indicator, or they can match more indications by using wildcard characters.
3. How can you produce a visualization in Kibana?
Ans:
- To produce a visualization in Kibana, first navigate to the “fantasize” tab from the Kibana main menu.
- Also, click on “produce a visualization” and select the type of visualization you want to produce(e.g., bar map, line map, pie map, etc.).
- Choose the indicator pattern that contains the data you want to fantasize. Next, configure the visualization by opting the fields and setting the parameters( similar to criteria and pails for aggregation).
- Eventually, click “Save” to save the visualization, which can also be added to a dashboard.
4. What are Kibana dashboards, and how do you partake in them?
Ans:
Kibana dashboards are collections of visualizations and saved quests that give perceptivity to the data from colorful perspectives. They allow users to combine multiple visualizations into a single, interactive interface, easing comprehensive data analysis and reporting. To partake in a Kibana dashboard, you can induce a shareable URL or import it as a PDF or CSV train, depending on the data and visualization types. This functionality is penetrated through the” Share” button in the dashboard interface, enabling users to partake in perceptivity with others fluently.
5. Describe the part of Elasticsearch aggregations in Kibana visualizations.
Ans:
Elasticsearch aggregations play a pivotal part in Kibana visualizations by recapitulating and assaying large datasets to prize meaningful patterns and perceptivity. They allow for complex data analysis and aggregation operations similar to counting, comprising, min/ maximum computations, and histogram generation. When creating visualizations in Kibana, users define aggregations to specify how data should be grouped and what criteria should be calculated. Elasticsearch also executes these aggregations, and the results are displayed in Kibana visualizations, enabling detailed data disquisition and analysis.
6. How can you import and export Kibana dashboards or visualizations?
Ans:
- Kibana allows users to export and import dashboards or visualizations for provisory purposes or to partake with others.
- To export, go to the” operation” section, select” Saved Objects,” select the dashboards or visualizations you want to export, and click the” Export” button.
- This will download a JSON train containing the named objects.
- To import, navigate to the same” Saved Objects” runner, click on” Import,” and select the JSON train you wish to import. Kibana will also upload and apply the dashboards or visualizations.
7. Explain how to use Kibana for log analysis.
Ans:
To use Kibana for log analysis, first ensure your logs are ingested into Elasticsearch. Then, produce an indicator pattern in Kibana that matches your log data indicators. Use the Discover tab to explore and search through your logs in real time, applying pollutants and queries to pinpoint specific events or anomalies. You can produce visualizations to dissect log data trends, frequency, and distributions over time. Eventually, collect these visualizations into a dashboard for an accrued view of your log data, enabling comprehensive log analysis and monitoring.
8. What are some common use cases for Kibana?
Ans:
Kibana is used for various purposes, including log and event data analysis, real-time operation monitoring, security analytics, functional intelligence, and user geste analytics. It’s extensively used in IT operations for troubleshooting and understanding system performance issues, by security brigades for incident response and analysis, and by business judges for understanding client geste and trends. Kibana’s inflexibility and important visualization tools make it suitable for a wide range of data analysis tasks across different diligence.
9. What are the differences between a date histogram and a histogram map in Kibana?
Ans:
| Feature | Date Histogram | Histogram Map |
|---|---|---|
| Data Type | Time-series data | Geospatial data |
| Aggregation | Groups data based on time intervals | Groups data based on geographic coordinates |
| Use Cases | Analyzing trends, patterns, and fluctuations over time | Visualizing spatial patterns and distributions |
| Field | Date or timestamp field | Geographic coordinates (latitude and longitude) |
| Example | Analyzing website traffic over time | Mapping customer locations or sensor readings |
10. What’s the ELK Stack, and how does Kibana fit into it?
Ans:
The ELK Stack stands for Elasticsearch Logstash Kibana. It’s a set of important tools that work together for searching, assaying, and imaging log data and time-series data. Elasticsearch acts as a hunt and analytics machine, Logstash is used for data collection and processing, and Kibana is the visualization subcaste that provides the user’s interface for interacting with the data. Kibana enables users to produce dashboards and visualizations to explore and make sense of the data stored in Elasticsearch, making it an essential element of the ELK Stack for data analysis and functional intelligence.
11. How can Kibana’s Lens feature improve data visualization?
Ans:
By letting users drag and drop fields into the screen and automatically recommending fashionable visualization options, Kibana Lens is a valuable and intuitive tool that makes creating visualizations easier. It allows users to fluidly transition between many visualization formats to find the best method to present their data, improving data dissection and visualization. Lens is an invaluable tool for users of all skill levels who want to create complex analyses quickly and painlessly. It supports a wide range of visualization formats and enables quick comparisons and perceptivity.
12. Can you describe the Time Series Visual Builder( TSVB) in Kibana and its uses?
Ans:
- The Time Series Visual Builder( TSVB) in Kibana is a point-rich tool for the detailed analysis and visualization of time series data.
- It allows users to produce visualizations that include maps, data tables, and criteria, with the capability to apply advanced fine computations and metamorphoses to the data.
- TSVB is particularly useful for monitoring, assaying trends over time, and creating complex visualizations that involve multiple data sources or indicators.
- It offers a high degree of customization, making it ideal for users who demand to perform in-depth time series analysis.
13. How do you optimize Kibana’s performance for large datasets?
Ans:
Optimizing Kibana’s performance for large datasets originally involves several strategies, such as acclimating the Elasticsearch indicator settings to ameliorate hunt performance, similar to adding the refresh interval. Use Kibana’s” Data rollups” point to total and epitomize data, reducing the volume of data to be queried. Apply shard optimization in Elasticsearch to distribute data efficiently. Limit the time range of queries to avoid overfilling the system with large data reclamations. Eventually, ensure that the tackle and Elasticsearch cluster are meetly gauged to handle the data volume and query complexity.
14. What’s part of Kibana Spaces, and how do they profit from multi-user surroundings?
Ans:
Kibana Spaces is a point that allows users to organize dashboards, visualizations, and other saved objects into separate spaces within a single Kibana case. This association system is salutary in multi-user surroundings because it enables fine-granulated access control, allowing directors to limit users’ access to only the applicable spaces. Spaces help in managing content and collaborations across different brigades or systems, ensuring that users only see the data and objects material to their work, therefore enhancing security and usability in surroundings with different users’ places and conditions.
15. Explain the process of creating a machine literacy job in Kibana for anomaly discovery.
Ans:
- Creating a machine literacy job in Kibana for anomaly discovery involves several ways. First, navigate to the Machine Learning section in Kibana and elect” produce a job”. Choose the indicator pattern that contains the data you want to dissect.
- Select the type of analysis similar to outlier discovery, and configure the specific parameters for your analysis, including the field( s) to be anatomized.
- Review the job settings, and if satisfied, start the job to begin assaying the data for anomalies. Kibana will also use Elasticsearch’s machine literacy capabilities to describe and punctuate unusual patterns or outliers in your data.
16. Discuss the significance of Kibana query language( KQL) and its advantages.
Ans:
Kibana Query Language( KQL) is a flexible and intuitive language designed for data disquisition and querying within Kibana. It enhances the user experience by supporting autocomplete to fluently find fields and drivers and allows for the quick filtering of dashboard and visualization data. KQL’s syntax enables users to perform complex quests by combining conditions and using functions, making it important for rooting precise perceptivity from data. Its ease of use and effectiveness in filtering and searching data make KQL an essential tool for judges working within the Kibana terrain.
17. How can cautions and conduct be configured in Kibana for functional oversight?
Ans:
Cautions and conduct in Kibana can be configured to automate functional oversight and response. Users can produce cautions grounded on specific conditions or thresholds in the data covered by Kibana. Once an alert is defined, conduct can be set up to detect responses similar to transferring announcements via dispatch, Slack, or other supported integrations. This process involves navigating to the” cautions and conduct” section in Kibana, creating a new alert by specifying the conditions, defining the conduct to be taken when those conditions are met, and ensuring timely responses to critical events or data trends.
18. What challenges might you face when integrating Kibana with other systems?
Ans:
Integrating Kibana with other systems can present challenges similar to data format mismatches, authentication and authorization issues, and network connectivity problems. To address these challenges, ensure data is rightly formatted or converted before ingestion into Elasticsearch. Use the erected-in features of the Elastic Stack, similar to Logstash or Beats, for data metamorphosis. Address authentication and authorization issues by configuring applicable security settings in Elasticsearch and Kibana and use API keys or access commemoratives for secure communication. Eventually, troubleshoot network issues by ensuring proper firewall and network configurations.
19. How do shot and restore functionalities work in Kibana, and why are they important?
Ans:
- Shot and restore functionalities in Kibana allow users to take backups( shots) of their Kibana indicators and also restore them when demanded.
- This is pivotal for disaster recovery, as it ensures that Kibana configurations, dashboards, visualizations, and other saved objects can be recovered in case of data loss or corruption.
- The process involves using Elasticsearch’s shot and restore capabilities, where shots are stored in a depository, which can be a train system or a pall-grounded storehouse service.
- To perform a shot or restore, users generally use the Elasticsearch API or operation tools that affiliate with Elasticsearch.
20. Describe the process of setting up a geo-point field in Kibana for geographical data visualization.
Ans:
To set up a geo-point field in Kibana for geographical data visualization, first ensure that your Elasticsearch indicator contains a field counterplotted as a geo-point type, which is used to store latitude and longitude equals. Once your data is listed with the geo-point field, produce an indicator pattern in Kibana that includes this field. You can also use Kibana’s visualization tools, similar to Charts, to produce geographical data visualizations. In the visualization settings, elect your geo-point field to plot the geographical data. This enables you to fantasize and dissect data grounded on geographical locales, offering perceptivity into patterns and trends across different regions.
21. What differentiates Kibana’s Discover point from its Fantasize and Dashboard features?
Ans:
Kibana’s Discover point provides an important interface for searching and filtering the data stored in Elasticsearch indicators in real-time, allowing users to snappily explore their data without demanding to produce visual representations. It offers a detailed view of the raw data and supports querying with Kibana Query Language( KQL) or Lucene, enabling users to drill down into their data grounded on specific criteria. On the other hand, the fantasize point is used to produce a wide range of visual representations of the data, from simple line maps to complex heat charts and everything in between. Dashboards allow users to combine these visualizations into a single pane for comprehensive analysis, offering a holistic view of the data perceptivity through interactive and customizable visual factors. Discover focuses on data disquisition and hunts, fantasizes, and dashboards, emphasizing data donation and liars.
22. How does Kibana handle real-time data visualization, and what are the counteraccusations for performance?
Ans:
- Kibana excels at real-time data visualization by querying Elasticsearch indicators continuously to cost the rearmost data, which allows it to display updates as they occur.
- This capability is especially useful for covering logs, deals, and other time-sensitive data. Still, imaging real-time data can be resource-intensive, particularly with large datasets or complex aggregations, as each update requires a query to be transferred to Elasticsearch, reused, and returned to Kibana.
- To alleviate performance counteraccusations, Kibana and Elasticsearch offer features like shard optimizations, indicator rollovers, and data rollups to efficiently manage and query data.
- Also, users can control the refresh rate and time range of their visualizations to balance between real-time perceptivity and system performance.
23. Explain the significance of Elastic Common Schema( ECS) in Kibana.
Ans:
The Elastic Common Schema( ECS) is a standardized data model that facilitates invariant data representation across different sources in the Elastic Stack, including Kibana. By conforming to ECS, data ingested from colorful sources like logs, criteria, and network data can be fluently identified, anatomized, and imaged within Kibana since ECS ensures harmonious field names, data types, and formats. This standardization significantly enhances data interoperability and simplifies the process of creating comprehensive,cross-data visualizations and analyses, leading to further effective monitoring, security analysis, and functional troubleshooting. For users, ECS reduces the complexity of managing data from different sources, enabling quicker perceptivity and more effective data disquisition within Kibana.
24. Describe the process and benefits of using indicator Patterns in Kibana.
Ans:
Indicator Patterns in Kibana serve as a critical ground between the data stored in Elasticsearch and the colorful features within Kibana, similar to Discover, Fantasy, and Dashboard. By defining an indicator pattern, users instruct Kibana on which Elasticsearch indicators to pierce for data analysis and visualization. This process involves specifying an indicator pattern that matches the names of one or further Elasticsearch indicators, voluntarily including wildcards for broader matching. The benefits of using indicator patterns are multifaceted. They allow users to total and dissect data across multiple indicators, grease advanced quests and pollutants grounded on the fields available in the indicators, and enhance the user’s experience by furnishing field bus- -bus completion and type-ahead features. Index patterns are foundational for effectively working with large and different datasets within Kibana, enabling important data disquisition and visualization capabilities.
25. What are the crucial features of Kibana’s machine literacy capabilities, and how can they be applied?
Ans:
Kibana’s machine literacy features offer sophisticated tools to identify patterns, anomalies, and trends in data stored in Elasticsearch without requiring users to specify algorithms manually. These features include anomaly discovery jobs that automatically dissect literal and real-time data to identify unusual geste, vaticinations to prognosticate unborn circumstances grounded on literal data trends, and outlier discovery for relating data points that diverge significantly from the dataset norm. Machine literacy in Kibana can be applied across colorful disciplines, similar to IT operations for detecting system anomalies, fiscal services for fraudulent exertion discovery, and e-commerce for relating unusual client geste. By integrating these machine literacy capabilities, Kibana provides an important, user-friendly platform for advanced data analysis, enabling associations to uncover perceptivity and make data-driven opinions with lesser delicacy and effectiveness.
26. How do you manage large volumes of data in Kibana for effective analysis?
Ans:
- Managing large volumes of data in Kibana for effective analysis involves using colorful Elasticsearch and Kibana features to optimize performance and usability.
- One effective strategy is to use Elasticsearch’s data rollups and indicator lifecycle operation( ILM) to total, epitomize, and efficiently store data over time, which reduces the volume of data that needs to be queried and imaged.
- In Kibana, creating focused indicator patterns that target these optimized indicators can further ameliorate analysis performance.
- Also, wisely using Kibana’s saved objects( like dashboards and visualizations), such as limiting the number of visualizations on a single dashboard and narrowing the time range of data being anatomized, can significantly enhance responsiveness. Strategic use of pollutants and queries in Kibana also helps fasten the analysis of applicable data, minimizing cargo processing.
- Together, these practices grease smoother, more effective analysis of large datasets within Kibana, enabling users to gain perceptivity more snappily.
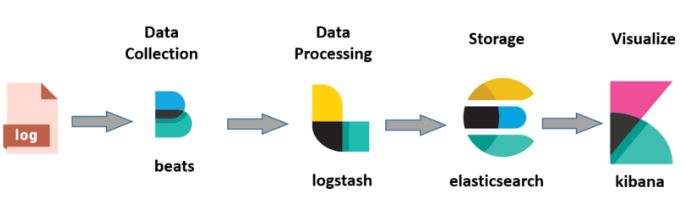
27. What’s the Elastic Stack, and how does Kibana fit into it?
Ans:
The Elastic Stack, formerly known as the ELK Stack, comprises several open-source tools designed to search, dissect, and fantasize data in real-time. The mound includes Elasticsearch, a hunt and analytics machine; Logstash, a garçon ‑ side data processing channel that ingests data from multiple sources contemporaneously, transforms it, and also sends it to a” store” like Elasticsearch; Beats, featherlight single-purpose data shippers; and Kibana, which provides the visualization and users interface for data stored in Elasticsearch. Kibana is the window into the Elastic Stack, enabling users to produce important visualizations of their data, manage and cover the mound, and explore Elasticsearch data. It’s the element that allows users to interact with the data stored in Elasticsearch through queries, visualizations, and dashboards, making it a necessary tool for data analysis and functional intelligence.
28. Explain the use of scripted fields in Kibana and their impact.
Ans:
Scripted fields in Kibana allow users to produce new fields that can be used in visualizations and dashboards, which are reckoned on the cover from the data in Elasticsearch indicators using effortless Lucene expressions or other scripting languages supported by Elasticsearch. These fields are basically dynamic computations that can transfigure, concatenate, or decide new values from being data without altering the source data. Scripted fields can be particularly useful for customizing how data is displayed in Kibana, performing on-the-cover computations, or creating tentative sense to punctuate specific conditions within the data. Still, they can have a significant impact on performance because the computations are done at query time. Thus, while scripted fields are important for enhancing data analysis and visualization, they should be used judiciously, with performance considerations in mind.
29. How can Kibana help in covering operation performance and logs?
Ans:
- Kibana is an essential tool for covering operation performance and logs, offering comprehensive capabilities for imaging and assaying log data in real time. By integrating with Elasticsearch, which stores log data, Kibana allows users to produce dashboards that can display crucial performance pointers( KPIs), criteria, and logs from operations and systems.
- Features like the Logs UI enable users to tail logs in real-time, while the Machine Learning capabilities can detect anomalies in log data, such as unanticipated drops in performance or harpoons in error rates. Also, Kibana’s waking features can notify brigades of implicit issues before they impact users.
- This visionary monitoring setup helps identify performance backups, debug issues snappily, and maintain system health, eventually perfecting operation trustability and user satisfaction.
30. Discuss the benefits and challenges of integrating Kibana with third-party tools.
Ans:
Integrating Kibana with third-party tools extends its functionality, enables more comprehensive analytics, and covers the ecosystem. The benefits of similar integrations include enhanced data ingestion from a variety of sources, bettered waking capabilities through external announcement systems, and the capability to incorporate Kibana visualizations into other platforms for broader business intelligence perceptivity. Still, challenges can arise, including comity issues between different performances of Kibana and third-party tools, implicit security vulnerabilities when exposing data to external systems, and the outflow of managing and maintaining integrations over time. To overcome these challenges, it’s important to completely test integrations in a controlled terrain, ensure robust security practices are in place, and keep both Kibana and third-party tools up to date. Effective integration planning and prosecution can significantly amplify Kibana’s value within an association’s data strategy.
31. What strategies would you employ to secure Kibana dashboards?
Ans:
Securing Kibana dashboards is pivotal to covering sensitive data and controlling access to data analytics coffers. Strategies for securing dashboards include enforcing part-grounded access control( RBAC) to ensure that users can only pierce the data and dashboards applicable to their places within the association. Using Elasticsearch security features, similar to SSL/ TLS encryption for data in conveyance and at rest, can protect data from unauthorized access and interception. Also, integrating with single sign-on ( SSO) systems can streamline the authentication process while maintaining high-security norms. It’s also judicious to regularly inspect dashboard access and operation to describe and alleviate unauthorized access or abnormal conditioning. By applying these strategies, associations can maintain the confidentiality, integrity, and vacuity of their data within Kibana.
32. Describe how Kibana’s Canvas Point can be employed for creating donations and reports.
Ans:
Kibana’s Canvas Point offers an important and interactive way to produce pixel-perfect donations and reports directly within Kibana. It allows users to pull live data from Elasticsearch and combine it with textbooks, images, and custom CSS to craft dynamic, data-driven stories. Oil is particularly useful for creating real-time functional dashboards, business reports, and custom visual summaries that go beyond traditional visualizations by including rich media rudiments. This capability enhances reporting by furnishing up-to-the-nanosecond data perceptivity in a visually charming format, suitable for both specialized and non-technical cult.
33. How do Kibana’s Timelion and TSVB features differ in handling time series data?
Ans:
- Kibana’s Timelion and Time Series Visual Builder( TSVB) are both important tools designed for handling time series data, but they feed to different use cases and offer unique functionalities. Timelion is a time series data visualizer that allows for the manipulation of time series using a query language.
- It excels in performing complex fine operations on multiple datasets and plotting them on a common timeline, making it ideal for relative analysis and trend identification over time.
- TSVB, on the other hand, provides a more intuitive interface with a wide range of visualization options beyond just line maps, including criteria, needles, and histograms. TSVB supports real-time data and reflections and offers further granularity when configuring how data is displayed.
- While Timelion requires users to be familiar with its query syntax, TSVB is more accessible for users who prefer a GUI-driven approach for creating detailed time series visualizations.
34. How does Kibana ensure data security, and what features does it offer to manage access control?
Ans:
Kibana ensures data security through a comprehensive set of features designed to manage access and cover sensitive information. It integrates with Elasticsearch’s security features to offer part-ground access control( RBAC), allowing directors to define places with specific warrants for penetrating data, features, and capabilities within Kibana. Users can be assigned one or more places, ensuring they only have access to the data and functions necessary for their tasks. Besides RBAC, Kibana supports features like encryption at rest and in conveyance, inspection logging to track users’ exertion, and integration with single sign-on ( SSO) results for authentication, including LDAP, Active Directory, SAML, and OpenID Connect.
35. Discuss the part of Vega and Vega-Lite in Kibana for creating custom visualizations.
Ans:
Vega and Vega-Lite play a critical part in Kibana by furnishing a frame for creating complex and custom-made visualizations that go beyond the erected-in map types. Vega is a declarative language for creating, saving, and participating in interactive visualization designs, allowing users to induce a wide range of graphical representations from introductory maps to complex interactive multi-view displays. Vega-Lite is a simpler, advanced-position language erected on top of Vega, offering a more compact syntax for common visualizations, making it easier to use while still being important. By using Vega and Vega-Lite in Kibana, users can draft bespoke visualizations acclimatized to their specific analysis requirements, similar to unique map types or interactive features not available in Kibana’s standard visualization options.
36. Explain the significance of Kibana’s Index Lifecycle Management( ILM) for managing data.
Ans:
Kibana’s Index Lifecycle Management( ILM) point plays a pivotal part in efficiently managing data within the Elastic Stack, particularly for time-series data like logs, criteria, and traces. ILM automates the process of managing indicators through their lifecycle, from creation to omission, grounded on programs defined by the users. These programs can specify conduct similar to rollover( moving to a new indicator grounded on size or age), allocation( transferring data to different tackle grounded on performance requirements), and ultimately omission, ensuring data is stored on the most cost-effective storehouse league. I optimize the storehouse and performance by managing data retention according to organizational requirements and nonsupervisory conditions, reducing homemade outflow, and ensuring that the Elasticsearch cluster remains performant and cost-effective.
37. Can you explain how to use Kibana for performing root cause analysis?
Ans:
- Using Kibana for root cause analysis involves using its comprehensive suite of visualization tools and dashboards to drill down into data and uncover the underpinning causes of observed anomalies or issues.
- Users can start by creating an overview dashboard that highlights crucial criteria and anomalies across their systems.
- When an issue is detected, they can also use Kibana’s detailed filtering and querying capabilities, including KQL, to insulate applicable logs, criteria, or traces that relate to the time and nature of the issue.
- Kibana’s integration with the Elastic Stack enables further disquisition by linking logs, criteria, and APM( operation Performance Monitoring) data, furnishing a holistic view of the system’s progress.
38. Discuss the significance of Elasticsearch mappings in the environment of Kibana visualizations.
Ans:
Elasticsearch mappings play a critical part in the effectiveness of Kibana visualizations by defining how data is stored and listed in Elasticsearch, which in turn affects how it can be queried and imaged in Kibana. Duly defined mappings ensure that the data types are rightly honoured, which is pivotal for performing accurate aggregations, quests, and analyses in Kibana. For illustration, date fields need to be rightly counterplotted to support time-grounded aggregations, and geo-point fields are necessary for geographical visualizations. Likewise, mappings can significantly impact performance; for example, enabling the right analyzers for textbook fields can grease more effective full-textbook hunt capabilities.
39. How do Spaces in Kibana enhance collaboration and association of dashboards and visualizations?
Ans:
Spaces in Kibana are designed to enhance collaboration and association by allowing users to insulate dashboards, visualizations, and other saved objects into logically grouped areas. This point is particularly useful in surroundings where multiple brigades or systems partake in a Kibana case but bear separate workspaces to manage their separate data visualizations and analyses. By creating distinct spaces for different brigades or systems, Kibana ensures that users can find and pierce applicable objects snappily without sifting through unconnected content, thereby enhancing productivity. Spaces also support access control, allowing directors to circumscribe users’ access to specific spaces, therefore ensuring that sensitive data is only accessible to authorized labour forces.
40. What are the Benefits of Kibana?
Ans:
Kibana offers an important and user-friendly interface for imaging Elasticsearch data, abetting in the analysis and understanding of complex datasets. Its real-time data visualization capabilities enable users to produce interactive dashboards that can display changes in data as they are, making it an invaluable tool for monitoring, troubleshooting, and gaining perceptivity into functional and business criteria. Kibana also supports a wide range of map types, charts, and graphs, allowing for the customization of visualizations to fit specific requirements. Likewise, its integration with the Elastic Stack enhances data analysis and hunt capabilities, making it easier to navigate and understand large volumes of data. Kibana facilitates collaboration among platoon members by participating in dashboards and visualizations and perfecting decision-making processes.

Get JOB Kibana Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. What’s the primary function of Kibana 5 dashboards?
Ans:
- The primary function of Kibana 5 dashboards is to give an important and interactive visualization subcaste that allows users to explore and dissect their data in real-time.
- Dashboards in Kibana 5 serve as a centralized platform for adding up multiple visualizations and contraptions, offering perceptivity into colorful datasets stored in Elasticsearch.
- These dashboards are largely customizable, enabling users to customize the layout and content to meet specific monitoring, analysis, or reporting requirements. Users can also produce, modify, and share dashboards, making it easier to integrate data analysis systems.
42. Why is it pivotal that calculating or non-computing bias remains healthy all of the time?
Ans:
Maintaining the health of computing and non-computing bias is pivotal to ensuring continued service and optimal performance. Healthy biases are essential for maintaining productivity, as they minimize time-out caused by malfunctions or failures, directly impacting business operations and effectiveness. In critical systems, similar to healthcare or fiscal services, device trustability can be consummate to safety and compliance with nonsupervisory norms. Likewise, healthy biases are more secure, reducing the threat of vulnerabilities that can lead to data breaches or cyber-attacks. Regular conservation and monitoring of device health help drag their lifetime, save costs related to repairs or reserves, and ensure that bias remains effective in meeting the demands of users and businesses.
43. What are the liabilities of the log store in the ELK mound?
Ans:
Logstash plays a critical part in the ELK( Elasticsearch, Logstash, Kibana) Stack as the data processing and ingestion element. Its primary responsibility is to collect, parse, and transfigure data from colourful sources before encouraging it to Elasticsearch for indexing. Logstash can ingest data from a multitude of sources, similar to logs, criteria, web operations, data stores, and all services. It provides a wide range of input, sludge, and affair plugins, allowing for expansive customization and processing capabilities. Pollutants in Logstash can enrich the data, remove gratuitous information, and transfigure formats as demanded.
44. Where can the log store collect its information from?
Ans:
Logstash can collect data from a different range of sources, making it an adaptable tool for aggregating and processing data. It can ingest data from lines, logs, system criteria, web operations, and communication ranges. Logstash supports colourful input plugins that allow it to admit data over HTTP, TCP/ UDP, and from specific sources like Syslog, log lines, AWS services, Kafka, and numerous others. Also, it can poll data from databases using JDBC. This inflexibility enables Logstash to serve as a central processing point for data from different surroundings and platforms, including pall- -bounded sources, on-demand servers, and IoT bias, easing comprehensive data analysis and visualization sweats within the Elastic Stack.
45. What are Elasticsearch and Kibana harborage figures?
Ans:
- Elasticsearch and Kibana use specific dereliction harborage figures to communicate with each other and with users.
- Elasticsearch, the core machine of the Elastic Stack, generally listens on harborage 9200 for HTTP communication and harborage 9300 for internal cluster communication.
- These anchorages are used for entering API requests, performing operations on data, and managing cluster functions. Kibana, on the other hand, defaults to using harborage 5601 for its web interface.
- Users pierce Kibana through a web cybersurfer connecting to this harborage, where they can produce, manage, and view dashboards and visualizations that interact with the data stored in Elasticsearch.
46. What’s the Discover tab in Kibana?
Ans:
The Discover tab in Kibana is an important point that allows users to explore and search their data in Elasticsearch in real time. It provides a user-friendly interface where users can snappily pierce and fantasize about the raw data stored in Elasticsearch indicators. By opting for an indicator pattern, users can filter and drill down into specific datasets, view document details, and understand data trends over time. The Discover tab supports a full- textbook hunt and allows the use of Kibana Query Language( KQL) for more complex queries, making it invaluable for original data disquisition, debugging, and perceptivity without creating full visualizations.
47. What’s the Fantasize tab in Kibana?
Ans:
The Fantasize tab in Kibana serves as the mecca for creating, managing, and exploring visualizations of the data stored in Elasticsearch. Users can make a wide array of visualization types, including line maps, bar graphs, pie maps, charts, and more, to represent their data graphically. This point enables users to transfigure their raw data into meaningful perceptivity through interactive and customizable visualizations. The Fantasize tab supports aggregations and criteria to epitomize and dissect data trends, patterns, and anomalies, easing complex data analysis tasks and empowering users to produce comprehensive dashboards.
48. What are Elasticsearch Development Tools?
Ans:
Elasticsearch Development Tools relate to a suite of serviceability and interfaces designed to help inventors and directors interact with Elasticsearch. These tools include the Dev Tools comfort in Kibana, which offers an interactive interface for composing and executing queries directly against the Elasticsearch REST API, allowing for testing, debugging, and managing the cluster. Other development tools include customer libraries for colorful programming languages, enabling flawless integration and manipulation of Elasticsearch data within operations. These tools inclusively enhance the development experience, offering important capabilities for data ingestion, query development, cluster operation, and performance optimization.
49. What’s the Shakespeare Dataset in Kibana?
Ans:
- The Shakespeare Dataset in Kibana is a sample dataset handed over by Elastic. It contains a comprehensive collection of Shakespeare’s workshops.
- It includes the textbook of each play, along with act and scene information, making it an excellent resource for exploring textbook analysis, full-textbook hunt capabilities, and visualization features in Kibana.
- By importing the Shakespeare dataset into Elasticsearch, users can experiment with the colorful features of the Elastic Stack, which are similar to textbook hunts and aggregations, and they can create visualizations to dissect the dataset.
- It serves as a practical illustration for users to learn how to handle and fantasize textual data within Kibana.
50. How does the Discover tab work in Kibana?
Ans:
The Discover tab in Kibana allows users to interactively explore their data listed in Elasticsearch without the need for predefined queries or visualizations. Upon opting for an indicator pattern, users are presented with a timeline of their data and a list of documents that match the indicator criteria, with the capability to acclimate the time range to concentrate on specific ages. Users can perform free- textbook quests, apply pollutants, and use the Kibana Query Language( KQL) for advanced querying. Each document’s detailed contents can be expanded to view field values, easing a deeper understanding of the data trends and anomalies. This dynamic disquisition capability makes the Discover tab a starting point for data analysis and understanding before moving on to further structured visualizations or dashboard creation.
51. What information can be added to better understand logs?
Ans:
To enhance the impenetrability of logs, contextual information similar as timestamp, log position(e.g., word, ERROR, DEBUG), source(e.g., operation name, garçon IP), user conduct, and sale IDs can be added. Incorporating error canons or dispatches and the specific part of the operation or system where the log was generated(e.g., module or function name) also provides pivotal perceptivity. For troubleshooting, mound traces or references to affiliated events logs are inestimable. Structured logging, where logs are written in a harmonious format or with specific fields, aids in filtering and querying logs more effectively in tools like Kibana.
52. Can logs be switched to another indicator?
Ans:
Yes, logs can be diverted or switched to another indicator in Elasticsearch, which Kibana also accesses for visualization and analysis. This can be achieved through colorful styles, including using Elasticsearch Index Aliases to tore-point to a new indicator, enforcing indicator lifecycle operation( ILM) programs to roll over logs to a new indicator grounded on criteria like size or age, or using Elasticsearch’s reindex API to move documents from one indicator to another. These approaches enable the effective operation of logs and indicators, optimize performance and storehouse, and ease better association and availability of data in Kibana.
53. What’s the purpose of the “is” field in Kibana?
Ans:
- The” is” field in Kibana doesn’t relate to a specific erected-in point or field but might be mentioned in the environment of query or sludge syntax within Kibana’s Discover, fantasize, or Dashboard features.
- In Kibana query language( KQL),” is” could be used as part of a query to sludge data, similar to chancing documents where a certain field matches a specified value.
- For illustration, the status is” active” could be a query to sludge documents in which the” status” field has the value” active”. It’s important to use the correct syntax and environment when working with fields and queries in Kibana to efficiently filter and dissect data.
54. What’s an introductory pie map that can be used in Kibana?
Ans:
An introductory pie map in Kibana can be used to fantasize about the composition of a dataset, showing how different orders contribute to the whole. To produce one, you select the Pie Chart visualization from Kibana’s Fantasize library, choose an indicator pattern, and define a metric similar to the count of documents. You also resolve the pie by slices grounded on a specific field(e.g., status law, product order) using a terms aggregation. This type of visualization is helpful for snappily understanding the distribution of data across different orders, pressing proportions and implicit areas of interest or concern within the dataset.
55. How can bar maps for different indicators be made in Kibana?
Ans:
Creating bar maps for different indicators in Kibana involves opting for the Bar Map visualization from the fantasizeFantasize library and also choosing the separate indicator pattern for each map you want to produce. For each bar map, you can define the specific criteria and pail aggregations to display. For illustration, you might produce one bar map showing deals over time from a deals data indicator and another showing error counts over time from an operation logs indicator. Each map can be customized with aggregations like sum, average, or count and can be further split by terms to compare different groups within the data. These maps can also be combined on a dashboard, allowing visualization and analysis across multiple indicators.
56. What’s a date histogram in Kibana?
Ans:
- A date histogram in Kibana is a type of aggregation that shows how data points are distributed across time intervals. It groups data into pails grounded on a timestamp field, allowing users to fantasize about trends, patterns, or changes over time.
- When creating a visualization like a line map or bar map, you can specify a date histogram on the X-axis to display, for example, the count of log entries, deals, or any other metric segmented by day, week, month, or any other time interval.
- This important point helps relate time-grounded trends, making it essential for time series data analysis, similar to covering website business, deal performance, or system health over specified ages.
57. What’s the purpose of creating reports in Kibana?
Ans:
Creating reports in Kibana serves the purpose of participating in perceptivity and analyses deduced from data visualizations with others, easing data-driven decision- timber. Reports can be generated from dashboards, visualizations, or Discover quests, allowing users to document and distribute their findings in a movable format, similar to PDF or CSV. This point is particularly useful for presenting data analysis results, covering reports, or participating in data shots with stakeholders who might need direct access to Kibana. It supports collaboration and communication within brigades and with external parties, ensuring that data perceptivity is accessible and practicable.
58. How can a visualization be saved in Kibana?
Ans:
To save a visualization in Kibana, after creating or modifying it, you can click the” Save” button set up in the toolbar at the top of the visualization editor. You’ll be urged to enter a name for your visualization, which will allow you to identify and recoup it later from the” fantasize” library. Voluntarily, you can also describe the visualization for a better environment. Saving visualizations enables you to use them in dashboards or partake them with other users, easing collaboration and the exercise of data analyses across your association.
59. How do you secure Kibana?
Ans:
- Securing Kibana involves configuring Elasticsearch security features, such as enabling HTTPS for translated communication, using erected-in or custom places to control access to data and features, and integrating with authentication providers( LDAP, Active Directory, SAML, etc.) for user authentication.
- Also, using Kibana Spaces to organize and secure dashboards, visualizations, and other saved objects by platoon or design can enhance security. Regularly streamlining Kibana and Elasticsearch to the rearmost performances also helps alleviate security vulnerabilities.
60. How can a new visualization be created in Kibana?
Ans:
To produce a new visualization in Kibana, navigate to the” fantasize” operation from the main menu and click the” produce visualization” button. You will be presented with colourful visualization types to choose from, similar to bar maps, line maps, pie maps, etc. After opting for the visualization type, you must choose the data source( generally an indicator pattern) that your visualization will use. Next, configure your visualization by specifying the criteria to measure and the confines to resolve the data. Through an interactive and intuitive UI, you can upgrade your visualization with pollutants, aggregations, and styling options. Once satisfied, save the visualization for use in dashboards or for participating with others.

61. How can a user sludge data in Kibana?
Ans:
- In Kibana, users can filter data in colourful situations, including dashboards, visualizations, and the Discover point. Pollutants can be applied through the hunt bar using Kibana Query Language( KQL) for precise criteria or by clicking on rudiments within visualizations, similar to map bars or parts, to stoutly upgrade the dataset.
- Also, the sludge bar allows users to add and configure pollutants grounded on the fields within the dataset, including operations like” is”,” is not”,” exists”, and range pollutants. These pollutants enable users to constrict the data to specific subsets, easing focused analysis and perceptivity into specific areas of interest.
62. What Is Filebeat?
Ans:
Filebeat is a featherlight, open-source shipper for forwarding and centralizing log data. Installed as an agent on servers, Filebeat monitors the log lines or locales specified by the users, collects log events, and forwards them either to Elasticsearch or Logstash for indexing. It’s part of the Elastic Stack( formerly known as ELK Stack), optimized for trustability and low quiescence, with features like backpressure-sensitive protocols and secure event forwarding. Filebeat comes with modules that simplify the collection, parsing, and visualization of common log formats, making it easier to dissect data without demanding expansive configuration. Its simplicity and effectiveness make Filebeat a popular choice for log collection in a variety of IT surroundings.
63. What Are The Main Components Of Kibana Interface?
Ans:
The Kibana interface consists of several crucial factors that grease data disquisition and visualization. The main factors include the Discover tab, which allows users to search and view documents in their Elasticsearch indicators. The Fantasize tab lets users produce and configure a wide range of visualizations from their data. The Dashboard tab enables the combination of multiple visualizations into a single comprehensive dashboard. The Dev Tools give an interactive press for advanced data disquisition and debugging. The Management section allows for the configuration of indicators, spaces, users, and places, among other settings. Incipiently, the Machine Learning features( if enabled) support anomaly discovery and data perceptivity directly within Kibana.
64. What’s Kibana Aggregation?
Ans:
Kibana aggregation is an important point used to reuse data and excerpt summaries or perceptivity by grouping and assaying data from Elasticsearch indicators. Aggregations help in performing complex data analysis and calculations, similar to casting up values, calculating pars, or relating min/ maximum values across a dataset. In Kibana, aggregations are foundational for creating visualizations and dashboards, enabling users to transfigure raw data into meaningful patterns, trends, and statistics. This point leverages Elasticsearch’s aggregation frame, allowing for the discourse of large volumes of data in real-time.
65. What’s Bucket Aggregation in Kibana?
Ans:
- Pail Aggregation in Kibana categorizes documents into pails or groups based on certain criteria, similar to field values, ranges, or geographical boundaries.
- This type of aggregation organizes data into meaningful groups, making it easier to dissect and fantasize about different parts of the data independently. Exemplifications include grouping deals data by product order or dividing client data by age ranges.
- Pail aggregations are essential for creating histograms, pie maps, geo charts, and other visualizations in Kibana that bear data segmentation.
66. What’s Metric Aggregation in Kibana?
Ans:
Metric Aggregation in Kibana focuses on calculating quantitative criteria on dataset subsets, similar to counting documents and calculating pars, totalities, minimums, and outsides. It’s frequently used in confluence with pail aggregations to cypher these criteria for each group or pail of data. After dividing deals data into pails by region, you might use metric aggregation to calculate the total deals or average trade quantum for each region. This enables detailed analysis and comparison of numerical data across different confines.
67. What are Kibana Settings?
Ans:
Kibana settings are configurations that allow users to customize and manage colorful aspects of their Kibana case. These settings include indicator pattern configuration, saved objects operation( like dashboards, visualizations, and quests), advanced settings for UI customization, and Kibana point controls. The settings also cover security aspects, such as part-grounded access control, spaces for organizing dashboards and visualizations, and integration settings for Elasticsearch and other Elastic Stack features. Accessible through the operation tab, these settings enable directors to knitter Kibana to meet their specific requirements and security conditions.
68. What are the advantages of Kibana?
Ans:
Kibana offers several advantages, including the capability to perform advanced data analysis and visualization on large datasets in real-time. It provides:
- A user-friendly interface for exploring Elasticsearch data.
- Creating complex queries without demanding to write law.
- Erecting interactive dashboards that aggregate data from multiple sources.
Kibana facilitates collaboration across brigades by participating in perceptivity and visualizations. It also enhances functional intelligence by covering operation performance and security analytics. Kibana’s inflexibility and extensibility, integrated with the Elastic Stack, make it an important tool for data-driven decision-making.
69. What’s meant by boolean queries in Kibana?
Ans:
Boolean queries in Kibana relate to advanced hunt ways that use Boolean sense to combine multiple query conditions for precise data filtering. These queries allow users to include, count, or combine quests grounded on specific criteria using drivers similar to AND, OR, and NOT. For illustration, a boolean query can find documents that match certain terms while banning others, enabling largely targeted hunt results. This functionality is crucial to refining data quests and analyses in Kibana, allowing users to drill down into complex datasets and excerpt exactly the information they need.
70. Explain wildcard Queries in Kibana.
Ans:
- Wildcard queries in Kibana allow users to search for documents independently by using asterisks( *) or question marks(?) to represent any number of characters or a single character.
- This is particularly useful when you are still determining the exact value you are searching for or when you want to include a broad range of particulars in your hunt results.
- For illustration, a wildcard query can help find documents containing terms that start with a specific prefix.
- Still, while important, wildcard queries can be resource-intensive and slow if used carelessly, especially over large datasets. Therefore, they should be used judiciously to balance inflexibility and performance.
71. What’s meant by Documents in Elasticsearch?
Ans:
In Elasticsearch, a document is the introductory unit of information that can be listed. Each document is a JSON object that consists of zero or further fields or crucial-value dyads. The fields can contain colourful types of data, similar to strings, figures, and dates. Documents are stored in indicators and are uniquely linked by an ID. Elasticsearch is designed to store, recoup, and manage document-acquainted or semi-structured data. Documents in Elasticsearch can represent anything from a row in a database, a log entry, or any item that can be described in a structured form.
72. Explain about indicators?
Ans:
An indicator in Elasticsearch is a collection of documents that have kindly analogous characteristics. It’s the loftiest- position reality that you interact with when storing, searching, streamlining, and deleting data in Elasticsearch. Indicators are used to organize and partition data logically, easing effective reclamation. Each indicator is linked by a unique name that’s used to relate to the indicator while performing operations. Also, indicators can be configured with specific settings and mappings to define how documents and their fields are stored and listed, affecting hunt performance and applicability.
73. Tell us about the Inverted Index.
Ans:
The reversed indicator is an abecedarian data structure used by Elasticsearch and other hunt machines to achieve fast hunt capabilities. It maps keywords to their locales within a set of documents. Rather than listing all words or terms as they appear in a document, the reversed indicator lists all documents containing a particular term. This makes it extremely effective to query which documents contain a term or combination of terms, easing quick full-textbook quests. The effectiveness and speed of the reversed indicator structure are crucial to the performance of Elasticsearch as a hunting machine.
74. What’s meant by Elasticsearch Cluster?
Ans:
- An Elasticsearch cluster is a group of one or more bumps(servers) that hold all of your data and provide allied indexing and hunt capabilities across all bumps.
- A unique name links a cluster, which automatically manages the distribution of data and query cargo across all bumps.
- Clusters are designed to be flexible, automatically redistributing data if a knot fails and ensuring that data is accessible indeed in the face of tackle failures.
- The scalability and high vacuity of Elasticsearch are primarily attributed to its cluster armature, enabling it to handle large volumes of data and queries.
75. Explain about Bumps.
Ans:
A knot is a single garçon that’s part of an Elasticsearch cluster. Each knot participates in the cluster’s indexing and hunt capabilities. Bumps can have different places, similar to data bumps that store data and execute data-related operations, master bumps that manage cluster-wide operations like creating or deleting indicators and coordinating bumps that distribute hunt requests and aggregate results. Bumps communicate with each other to perform operations and maintain cluster health. Adding further bumps to a cluster can increase its capacity, adaptability, and performance, demonstrating the scalability of Elasticsearch.
76. What’s meant by shards in Elasticsearch?
Ans:
Shards in Elasticsearch are individual partitions of an indicator, each holding a portion of the indicator’s data. This medium allows Elasticsearch to horizontally gauge data across multiple bumps, enhancing performance and capacity. Primary shards distribute data across the cluster, and their number is defined at indicator creation and can not be changed later. Sharding enables Elasticsearch to manage large datasets efficiently by parallelizing operations across shards, thereby perfecting hunt and reclamation performance.
77. Explain about Replicas in Elasticsearch.
Ans:
Clones in Elasticsearch are clones of primary shards and serve two main purposes: furnishing high vacuity and perfecting performance. However, a replica shard can be promoted to a primary shard, ensuring data vacuity if a primary shard fails. Also, replica shards can handle hunt queries, distributing the hunt cargo and thereby enhancing the read performance of the Elasticsearch cluster. The number of replica shards is configurable, allowing for inflexibility in balancing between redundancy and resource operation.
78. How do I recoup the list of all Elasticsearch documents from an indicator?
Ans:
- To recoup all documents from an Elasticsearch indicator, you can use the search API endpoint with a match_all query.
- Still, Elasticsearch limits the number of documents returned in a single query by dereliction for performance reasons.
- To recoup all documents, consider using the Scroll API for large datasets. This allows you to recoup large numbers of documents more effectively by maintaining a hunt environment to scroll through the dataset.
79. Explain the term shot Lifecycle operation.
Ans:
Shot Lifecycle operation( SLM) in Elasticsearch is a point that automates the creation, omission, and operation of shots of your indicators. Shots give a way to back up data in Elasticsearch clusters. SLM allows you to define programs specifying when and how frequently shots should be taken, where they should be stored, and the retention period for these shots. This ensures that data is backed up regularly and that storehouse coffers are used efficiently by automatically removing old shots.
80. How can you define the Kibana Docker image?
Ans:
The Kibana Docker image is a preconfigured vessel image that allows users to run Kibana in Docker holders. This image includes Kibana and all its dependencies, offering a straightforward way to place Kibana in containerized surroundings. Users can customize the Kibana Docker vessel by setting terrain variables, mounting configuration lines, or extending the base image. This simplifies the deployment and scaling of Kibana across different surroundings, ensuring harmonious setups.
81. ExplainX-pack and a replica in Kibana
Ans:
- X-Pack is an extension for Elasticsearch and Kibana that provides a host of fresh features, including security, waking, covering, reporting, and machine literacy. X-Pack integrates seamlessly into Kibana, enhancing its capabilities with features like secured access, waking on data anomalies, and generating reports.
- As for clones in Kibana’s environment, this generally refers back to Elasticsearch’s replica shards, which Kibana accesses to recoup data. Kibana itself does not manage data or clones but interacts with Elasticsearch, which handles the data, including clones, for high vacuity and performance.
82. What’sKibana.yml?
Ans:
It is the configuration train for Kibana, used to customize and control colorful aspects of Kibana’s operation. Through this train, directors can define settings similar to the Elasticsearch URL, anchorages on which Kibana listens, enabled features, and security settings. Thekibana.yml train offers a flexible way to knit Kibana’s geste to meet specific requirements, similar to integrating with an Elasticsearch cluster, configuring logging, and setting up authentication and authorization.
83. Is Elasticsearch a NoSQL DB?
Ans:
- Yes, Elasticsearch is classified as a NoSQL database. It’s designed to store, search, and manage document-acquainted or semi-structured data.
- Elasticsearch excels in full-textbook hunt, real-time analytics, and scalability, using a reversed indicator for fast query prosecution.
- This makes it suitable for use cases that require searching large volumes of textbook-heavy information or logical queries on semi-structured data.
- Unlike traditional relational databases, Elasticsearch doesn’t apply a schema, allowing for inflexibility in data ingestion and representation. Its distributed armature ensures high vacuity and adaptability, making it a popular choice for hunt and analytics operations.
84. What parts does Filebeat cover?
Ans:
Filebeat is a featherlight log shipper that’s part of the Elastic Stack. It’s designed to cover log lines or locales and further them to Elasticsearch or Logstash for indexing. Filebeat can cover log lines from all feathers of sources, including lines generated by Apache, Nginx, system logs in Linux, operation logs, and any plaintext train. Filebeat works by trailing these lines, keeping track of changes, and transferring new log entries to Elasticsearch or Logstash. It’s largely configurable, with modules and prospectors that allow it to efficiently manage the way it collects, pollutants, and forwards log data, making it largely effective in log monitoring and aggregation scripts.
85. What language is Kibana written in?
Ans:
Kibana is primarily written in JavaScript and uses Node.js for its garçon-side operations. The front end of Kibana is erected using colorful JavaScript fabrics and libraries, including React and AngularJS, which grease its interactive and dynamic user interface. The choice of JavaScript allows Kibana to run easily in web cybersurfers, furnishing a rich user experience for data visualization and analysis. This tech mound contributes to Kibana’s inflexibility and extensibility, enabling inventors to fluently make and integrate new features and plugins to enhance its capabilities.
86. Is Kibana like Splunk?
Ans:
- Kibana and Splunk are similar in that both are used for monitoring, searching, and imaging log data, but they serve different ecosystems and have distinct features. Kibana is part of the Elastic Stack, primarily designed to work with Elasticsearch for log and time series data visualization, dashboarding, and analytics.
- It’s open source and focused on scalability and integration within the Elastic ecosystem. Splunk, on the other hand, is a more comprehensive data analysis tool with a broader focus, including log operation, security information and event operation( SIEM), and functional intelligence. Splunk is known for its important hunt capabilities and personal software.
- While both tools offer important data analysis capabilities, the choice between them frequently comes down to specific use cases, budget considerations, and the technology mound.
87. Is Kibana a DevOps tool?
Ans:
Kibana can be considered a part of the DevOps toolkit, especially in surrounds where monitoring, log analysis, and functional intelligence play a pivotal part in the software development lifecycle. While Kibana itself isn’t a DevOps tool in the traditional sense, like CI/ CD tools or configuration operation tools, it facilitates DevOps practices by furnishing perceptivity into operation performance, system monitoring, and troubleshooting through visualization of logs and criteria. It supports DevOps brigades in achieving nonstop enhancement and functional excellence by enabling data-driven decision-making. Thus, Kibana is a precious asset in the DevOps ecosystem, completing other tools by enhancing observability and functional mindfulness.
88. How do I run an effortless script in Kibana?
Ans:
Running an effortless script in Kibana generally involves using the script in the environment of Elasticsearch queries, aggregations, or scripted fields within Kibana’s Discover, Fantasy, or Dashboard features. To run an effortless script, you would first navigate to the applicable Kibana point where the script is demanded. For illustration, to produce a scripted field, go to the indicator Patterns section under Stack Management, choose the indicator pattern, and also add a scripted field where you can enter your effortless script law. In visualizations or when querying, you can use the effortless script in the Kibana Query Language( KQL) bar or within the advanced settings of specific visualization types to manipulate or calculate data on the cover. Ensure your script follows the effortless scripting language syntax and is tested for correctness and performance impacts.
89. Is Grafana a Kibana chopstick?
Ans:
- No, Grafana isn’t a chopstick of Kibana. Although Grafana and Kibana are both open-source visualization and monitoring tools, they were developed separately with different original focuses and strengths.
- Grafana began with a strong emphasis on time-series data visualization, frequently used with monitoring tools like Prometheus and Graphite, making it a popular choice for functional monitoring, especially in DevOps and observability surrounds.
- Kibana, part of the Elastic Stack, is tightly integrated with Elasticsearch and excels at searching, viewing, and interacting with data stored in Elasticsearch indicators.
- While both tools have evolved to offer broader capabilities beyond their original reaches, including features that lap, they remain distinct systems with unique features, user interfaces, and data source integrations.
90. what are the disadvantages of kibana?
Ans:
- Dependence on Elasticsearch Kibana is tightly coupled with Elasticsearch. This reliance means that it can only be used as a standalone visualization tool for data stored in other types of databases or data sources if it firstfintegratesgrates them into the Elastic Stack f
- Complex Setup and Configuration Setting up Kibana and configuring it to meet specific requirements can be complex, especially in large-scale or secure environments. The learning curve for fine-tuning and optimizing performance might be steep for users new to the Elastic Stack.
- Resource Intensity For large datasets or largely complex queries, Kibana( and the underpinning Elasticsearch) can be resource-ferocious, requiring significant memory and CPU coffers to perform efficiently. This can lead to scalability issues in environments with limited coffers.
- Security enterprises While Kibana offers security features like part-grounded access control, setting up a secure Kibana case( especially in earlier performances) can be grueling and requires fresh configuration and frequent an anX-Pack subscription for advanced security features.