
Last updated on 24th Sep 2025| 12779
- What is Hashing in Data Structures?
- Hash Functions
- Hash Tables
- Collisions and Resolution Techniques
- Load Factor and Resizing
- Applications of Hashing
- Hash vs Search Trees
- Cryptographic Hashing
- Conclusion
What is Hashing in Data Structures?
Hashing is a fundamental technique in computer science used to uniquely identify data and enable efficient data retrieval. It involves transforming input data of arbitrary size into a fixed-size value called a hash code or hash value using a hash function. This hash code acts like a digital fingerprint for the original data. The primary goal of hashing is to provide fast access to data. For example, in data structures like hash tables, hashing allows for nearly constant-time complexity (O(1)) when searching, inserting, or deleting elements Full Stack Training. The hash function maps data to specific locations called buckets or slots in the hash table, making lookup operations extremely efficient. However, different inputs can sometimes produce the same hash value, causing a collision. Handling collisions effectively is crucial for maintaining performance and accuracy. Common collision resolution techniques include chaining (storing multiple elements in a list at the same bucket) and open addressing (finding another available bucket). Hashing in Data Structures is widely used beyond data storage in areas like cryptography for securing data, data integrity verification, password storage, and more. Overall, hashing is a powerful method for optimizing data management and ensuring quick access across many computing applications.
Hash Functions
- Definition: A hash function converts input data of any size into a fixed-size hash value or hash code.
- Deterministic: The same input always produces the same hash output.
- Fast Computation: Designed to compute the hash value quickly for efficient data retrieval.
- Uniform Distribution: Ideally, hash functions distribute inputs evenly across the output range to minimize collisions.
- Collision Resistance: Good hash functions minimize the chances of two different inputs producing the same Web Developer vs Software Developer hash value.
- Applications: Used in hash tables, data indexing, cryptography, checksums, and data integrity verification.
- Examples: Common hash functions include MD5, SHA-1, SHA-256, and simple modulo operations in hash tables.
Hash Tables
A hash table is a data structure that implements an associative array, mapping keys to values using a hash function. Internally, it maintains an array where each element is a bucket that stores entries. The hash function computes the index of the array where the key-value pair is stored. When implemented correctly, hash tables provide very fast data access with an average-case time complexity of O(1) for insertion, deletion, and lookup. Common programming languages offer built-in implementations of hash tables: Python has dictionaries, Java has HashMap, and C++ has unordered_map.
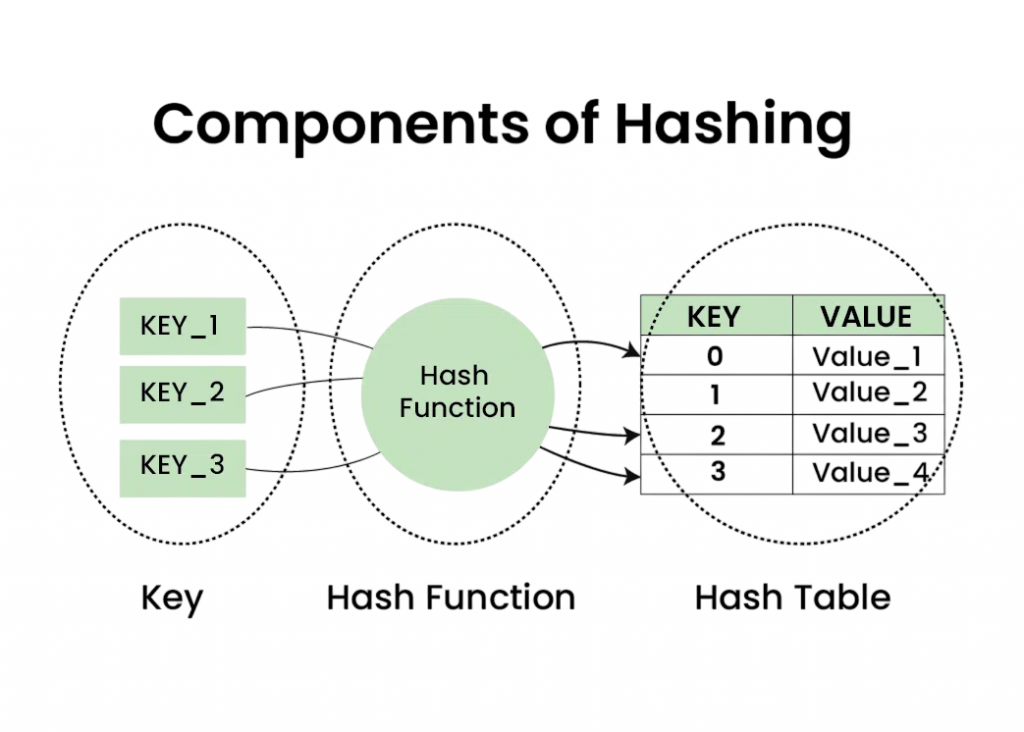
A hash table is a data structure that stores key-value pairs for efficient data retrieval. It uses a hash function to convert keys into hash codes, which determine the index or bucket Backend Development where the value is stored. This allows near-constant-time access (O(1)) for inserting, searching, and deleting data. However, collisions when two keys produce the same hash code can occur and are handled using techniques like chaining or open addressing. Hash tables are widely used in databases, caching, and implementing associative arrays due to their speed and efficiency in managing large datasets.
Interested in Obtaining Your Full stack Certificate? View The Full Stack Developer Course Offered By ACTE Right Now!
Collisions and Resolution Techniques
Collisions occur when two keys hash to the same index in the hash table. Since each index can store only one key-value pair, a mechanism is needed to handle collisions.
There are several collision resolution strategies:
- Chaining: Each index in the array holds a linked list. All elements that hash to the same index are stored in the list.
- Open Addressing: All elements are stored in the array itself, and a probing sequence is used to find the next available spot. Software Developer vs Software Engineer Techniques include linear probing, quadratic probing, and double hashing.
- Rehashing: When too many collisions occur, a new, larger table is created and all keys are rehashed using a new hash function.
Choosing the right method depends on the specific use case and performance requirements.
Gain Your Master’s Certification in Full Stack Developer by Enrolling in Our Full Stack Master Program Training Course Now!
Load Factor and Resizing
The load factor is the ratio of the number of entries to the number of buckets in a hash table. It is a critical factor in determining the performance of a hash table. A high load factor can lead to more collisions and slower operations, while a low load factor may result in inefficient use of memory. Most implementations maintain a threshold load factor (typically 0.7). When this threshold is exceeded, the hash table is resized usually doubled in size and all existing entries are rehashed. This process helps in maintaining a balance Full Stack Training between space and time efficiency. The load factor of a hash table is the ratio of the number of stored elements to the total number of buckets. It measures how full the table is. A high load factor increases the chances of collisions, which can slow down operations like search and insertion. To maintain efficiency, hash tables resize usually by increasing the number of buckets when the load factor exceeds a certain threshold (commonly around 0.7). Resizing involves creating a larger table and rehashing all existing elements to redistribute them evenly, ensuring faster access and reducing collisions.

Develop Your Skills with Full stack Developer Certification Course
Weekday / Weekend BatchesSee Batch DetailsApplications of Hashing
Applications of Hashing is extensively used in various areas of computer science and everyday software applications:
- Databases: Indexing and quick lookups of records.
- Caching: Storing computed results or frequently accessed data.
- Symbol Tables: IT Engineer Salary in India Compilers use hash tables to store variable names and their attributes.
- Password Storage: Securely storing user credentials using cryptographic hashes.
- File Systems: Hashing helps in data deduplication and efficient storage.
- Blockchain: Cryptographic hashing ensures data integrity and immutability.
Are You Preparing for Full Stack Jobs? Check Out ACTE’s Full stack Interview Questions and Answers to Boost Your Preparation!
Hash vs Search Trees
- Hash Tables offer O(1) average time for lookup, insert, and delete.
- Search Trees provide O(log n) operations if balanced.
- Hash Tables do not maintain order.
- Search Trees keep elements in sorted order Best Software Development Courses .
- Hash Tables are ideal for fast key-based access.
- Search Trees are better for range queries and sorted data traversal.
- Hash Tables may face collisions; require handling strategies.
- Search Trees do not have collisions.
- Hash Table performance depends on hash function and load factor.
- Search Trees offer more predictable performance, especially if self-balancing (e.g., AVL, Red-Black Tree).
Access Time:
Ordering:
Use Cases:
Collisions:
Performance Stability:
Cryptographic Hashing
Cryptographic hash functions are designed to be secure and non-reversible. They are used primarily in security applications rather than data structures Become an IT Engineer. Characteristics of cryptographic hashes include:
- Pre-image resistance: Difficult to reverse-engineer the input from the hash.
- Collision resistance: Hard to find two inputs that hash to the same output.
- Avalanche effect: Small changes in input result in significant changes in output.
Popular cryptographic hash functions include SHA-1, SHA-256, and MD5 (now considered weak). These functions are vital for digital signatures, integrity checks, password hashing, and blockchain technology.
Conclusion
Hashing is a powerful concept in data structures that enables constant-time data access. It involves using hash functions to compute an index for storing and retrieving data in a hash table. Proper collision resolution and load factor management are key to maintaining high performance Full Stack Training. Applications of Hashing finds widespread application in software systems, ranging from simple data lookup to complex security and cryptographic systems. Understanding hashing is essential for developers, computer scientists, and data engineers aiming to build efficient and scalable software solutions.




