
Last updated on 21st Apr 2026| 7363
Preparing for Microsoft Data Structures And Algorithms interviews is very important for freshers who want to build a successful software career. Microsoft focuses on problem-solving ability, coding efficiency, logical thinking, and understanding of core computer science concepts. DSA questions help recruiters evaluate how candidates approach real-world programming challenges using optimized solutions. Freshers are usually asked topics like arrays, linked lists, trees, sorting, searching, recursion, dynamic programming, and graph algorithms during technical rounds. Practicing 90+ Microsoft DSA Questions And Answers improves coding speed, confidence, and analytical skills required for placement interviews. Consistent preparation with coding practice, mock interviews, and problem-solving techniques can help candidates crack Microsoft technical interviews successfully.
1. What Is Data Structure?
Ans:
- Data structure is a way of organizing data in a computer. It helps in storing and managing information efficiently.
- Different data structures are used for different purposes. Arrays, linked lists, stacks, and queues are common examples. Data structures improve program performance and memory usage.
- They are important for coding interviews and problem solving. Understanding data structures is essential for software development.
2. What Is An Algorithm?
Ans:
An algorithm is a step-by-step procedure to solve a problem. It gives a clear sequence of instructions for execution. Algorithms help programmers write efficient solutions. Searching and sorting are common algorithm examples. Good algorithms reduce time and memory consumption. They are widely used in technical interviews. Algorithms are the foundation of computer programming.
3. What Is An Array?
Ans:
An array is a collection of elements stored in contiguous memory locations. It stores data of the same type. Array elements are accessed using indexes. Arrays are fast for accessing elements directly. They are commonly used in loops and sorting problems. Arrays are one of the basic DSA topics in interviews. They are simple and easy to understand.
4. What Is Linked List?
Ans:
- A linked list is a linear data structure made of nodes. Each node contains data and a reference to the next node.
- Linked lists use dynamic memory allocation. They are useful when frequent insertion and deletion are needed.
- Linked lists are slower for random access compared to arrays. Types include singly and doubly linked lists. They are important interview concepts.
5. What Is Stack?
Ans:
Stack is a linear data structure that follows LIFO principle. LIFO means Last In First Out. Elements are added using push operation. Elements are removed using pop operation. Stack is used in recursion and expression evaluation. Browser history is a common stack example. It is frequently asked in DSA interviews. Stack operations are performed only from the top side.
6. What Is Queue?
Ans:
Queue is a linear data structure that follows FIFO principle. FIFO means First In First Out. Elements are inserted from the rear side. Elements are removed from the front side. Queue is used in scheduling and buffering systems. Printer queue is a real-world example. It is an important topic in interviews. Queue improves task management in computer systems.
7. What Is Binary Search?
Ans:
Binary search is a searching algorithm for sorted arrays. It divides the array into two halves repeatedly. The middle element is compared with the target value. It reduces search time significantly. Binary search works in logarithmic time complexity. It is faster than linear search for large data. It is a common Microsoft interview question. Binary search requires the data to be sorted before searching.
8. What Is Linear Search?
Ans:
Linear search checks elements one by one in a sequence. It starts searching from the beginning of the array. It continues until the target element is found. Linear search works for sorted and unsorted arrays. Its time complexity is higher for large data. It is simple and easy to implement. Beginners often learn this algorithm first. Linear search is suitable for small datasets and simple applications.
9. Write A Program To Check Whether A Number Is Even Or Odd
Ans:
This program checks whether the given number is divisible by 2. If the remainder is zero, the number is even. Otherwise, it is odd. It uses a simple if-else condition for decision making. This is one of the most common beginner coding questions in interviews. It helps freshers understand conditional statements and modulus operators clearly. This logic is widely used in basic mathematical and programming applications.
- int n = 8;
- if(n % 2 == 0)
- System.out.println(“Even”);
- else
- System.out.println(“Odd”);
10. What Is Space Complexity?
Ans:
Space complexity measures memory usage of an algorithm. It shows how much extra memory is required. Efficient algorithms try to minimize memory usage. Space complexity is important for large applications. Recursive programs may use more stack memory. It is represented using Big O notation. Interviewers often ask about optimization techniques.
11. What Is Recursion?
Ans:
Recursion is a technique where a function calls itself. It solves problems by dividing them into smaller subproblems. Every recursive function must have a base condition. Without a base case, infinite recursion may occur. Recursion is used in tree and graph problems. Factorial calculation is a common example. It is a popular interview topic. Recursive solutions often make complex problems easier to understand.
12. What Is Sorting?
Ans:
Sorting is the process of arranging data in order. Data can be sorted in ascending or descending order. Sorting improves searching efficiency. Bubble sort, merge sort, and quick sort are examples. Efficient sorting reduces processing time. Sorting algorithms are commonly asked in coding rounds. They are essential in DSA preparation. Sorting helps organize large amounts of data effectively.
13. What Is Bubble Sort?
Ans:
Bubble sort repeatedly compares adjacent elements in an array. It swaps elements if they are in wrong order. Larger elements move toward the end after each pass. Bubble sort is simple but inefficient for large data. Its average time complexity is O(n²). It is mainly used for learning purposes. It is one of the basic sorting algorithms. Bubble sort is easy to understand and implement for beginners.
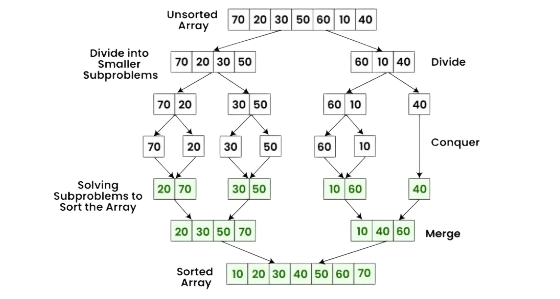
14. What Is Merge Sort?
Ans:
Merge sort is a divide-and-conquer sorting algorithm. It divides the array into smaller subarrays recursively. The subarrays are sorted and merged together. Merge sort has O(n log n) complexity. It is efficient for large datasets. It requires extra memory for merging process. It is widely used in real-world applications. Merge sort provides stable sorting performance for large data.
15. What Is Quick Sort?
Ans:
Quick sort is an efficient sorting algorithm. It selects a pivot element from the array. Elements are partitioned based on pivot value. Smaller elements move left and larger elements move right. Quick sort works efficiently for large inputs. Average time complexity is O(n log n). It is frequently asked in Microsoft interviews. Quick sort is preferred because of its fast practical performance.
16. What Is Tree Data Structure?
Ans:
Tree is a hierarchical data structure with nodes. The top node is called root node. Each node may have child nodes connected to it. Trees are used in databases and file systems. Binary tree is the most common type. Trees allow efficient searching and insertion. They are important in coding interviews. Tree structures help represent hierarchical relationships clearly.
17. What Is Binary Tree?
Ans:
- Binary tree is a tree where each node has at most two children. The children are called left and right nodes.
- Binary trees are used for hierarchical data representation. Traversal methods include inorder, preorder, and postorder.
- Binary trees are used in searching applications. They are common in technical interviews. Understanding trees improves problem-solving skills.
18. What Is Binary Search Tree?
Ans:
- Binary search tree is a special binary tree structure. Left child contains smaller values than parent node.
- Right child contains larger values than parent node. BST allows fast searching and insertion operations.
- Average complexity is O(log n). It is widely used in databases and systems. BST questions are common in interviews.
19. What Is Graph?
Ans:
Graph is a non-linear data structure with vertices and edges. Vertices represent nodes and edges represent connections. Graphs are used in networks and maps. Graph traversal methods include BFS and DFS. Graphs can be directed or undirected. They are useful in pathfinding problems. Graph problems are important in coding interviews. Graphs are widely used in social media and navigation applications.
20. What Is The Difference Between Stack And Queue?
Ans:
| Feature | Stack | Queue |
|---|---|---|
| Insertion And Deletion | Happens At Same End | Insertion At Rear And Deletion At Front |
| Main Operations | Push And Pop | Enqueue And Dequeue |
| Usage | Function Calls, Undo Operations | Scheduling, Buffering, Printing Tasks |
21. What Is DFS?
Ans:
DFS stands for Depth First Search. It explores one branch completely before backtracking. Stack or recursion is used in DFS. DFS is useful for pathfinding and cycle detection. It works efficiently for graph traversal problems. DFS is commonly used in maze-solving applications. It is an important interview topic. DFS helps in solving connectivity and traversal-related problems efficiently.
22. What Is Hashing?
Ans:
Hashing is a technique used for fast data retrieval. It maps data to unique indexes using hash functions. Hash tables provide average O(1) search complexity. Collisions may occur when indexes overlap. Hashing is widely used in databases and caching. It improves search efficiency significantly. It is frequently asked in interviews. Hashing is also used in password storage and data indexing systems
23. What Is Dynamic Programming?
Ans:
- Dynamic programming solves complex problems using smaller subproblems. It stores computed results for reuse
- DP reduces repeated calculations in recursive solutions. Fibonacci sequence is a common DP example. It improves algorithm efficiency significantly.
- DP problems are important in coding interviews. Practice is required to master dynamic programming.
24. What Is Greedy Algorithm?
Ans:
Greedy algorithm makes the best choice at every step. It aims to find optimal solutions efficiently. Greedy methods work for specific optimization problems. Activity selection is a common example. Greedy algorithms are simple and fast. They may not always give correct results for every problem. They are popular interview topics. Greedy algorithms are widely used in scheduling and optimization tasks
25. What Is Heap?
Ans:
Heap is a special tree-based data structure. It satisfies heap property for parent and child nodes. Max heap stores largest value at root. Min heap stores smallest value at root. Heaps are used in priority queues. Heap sort uses heap data structure. Heap questions are common in interviews. Heaps help in efficiently finding highest or lowest priority elements.
26. What Is Priority Queue?
Ans:
Priority queue is an abstract data structure. Elements are processed based on priority instead of insertion order. Heap is commonly used for implementation. Higher priority elements are removed first. It is used in scheduling systems and graphs. Priority queues improve efficiency in applications. They are important DSA concepts. Priority queues are commonly used in CPU scheduling and shortest path algorithms
27. Write A Program To Find The Largest Number?
Ans:
This program compares two numbers and prints the greater value. It uses a basic comparison operator with if-else statements. The logic is simple and helps freshers understand conditional programming. It is frequently asked in Microsoft coding interviews for beginners. This program improves problem-solving and logical thinking skills in programming. It also helps beginners understand how decision-making works in Java programs.
- int a = 10, b = 20;
- if(a > b)
- System.out.println(a);
- else
- System.out.println(b);
28. What Is Deque?
Ans:
Deque stands for double-ended queue. Elements can be inserted and removed from both ends. It combines features of stack and queue. Deque is useful in sliding window problems. It provides flexible operations. Deque is implemented using arrays or linked lists. It is important for coding interviews. Deque is widely used in caching and task scheduling applications.
29. What Is Circular Queue?
Ans:
Circular queue connects the last position to the first position. It efficiently uses memory space. Front and rear pointers are used for operations. Circular queue avoids memory wastage in linear queue. It is commonly used in buffering systems. It improves performance in scheduling tasks. It is an important DSA topic. Circular queues are useful in CPU scheduling and streaming systems.
30. What Is Selection Sort?
Ans:
Selection sort repeatedly selects smallest element from array. The selected element is placed in correct position. It reduces unnecessary swaps compared to bubble sort. Time complexity is O(n²). It is easy to understand and implement. Selection sort is useful for small datasets. It is often asked for beginners. Selection sort performs well when memory write operations are limited.
31. What Is Insertion Sort?
Ans:
Insertion sort builds sorted array one element at a time. Elements are inserted into their correct position. It works efficiently for small or nearly sorted data. Time complexity is O(n²) in worst case. It is simple and stable sorting algorithm. It is useful for educational purposes. It is a common interview question. Insertion sort is commonly used in hybrid sorting algorithms
32. What Is Recursion Stack?
Ans:
Recursion stack stores function calls during recursion. Each function call is placed in memory stack. When function completes, it is removed from stack. Deep recursion may cause stack overflow error. Recursion stack helps maintain execution order. It is important in recursive algorithms. Understanding stack behavior is essential. Recursion stack is automatically managed by the system memory.
33. What Is AVL Tree?
Ans:
AVL tree is a self-balancing binary search tree. Height difference between subtrees is limited. Rotations are used to maintain balance. AVL tree provides efficient search operations. Complexity remains O(log n) for insertion and deletion. It improves performance over normal BST. AVL trees are advanced interview topics. AVL trees maintain faster searching due to
34. What Is Red Black Tree?
Ans:
Red black tree is a balanced binary search tree. Nodes are colored red or black. Certain rules maintain tree balance automatically. It provides efficient insertion and deletion operations. Search complexity remains logarithmic. Red black trees are used in libraries and systems. They are commonly asked in advanced interviews. Red black trees provide balanced performance with fewer rotations.
35. What Is Divide And Conquer?
Ans:
Divide and conquer breaks problems into smaller subproblems. Each subproblem is solved independently. Results are combined to form final solution. Merge sort and quick sort use this technique. It improves efficiency for complex problems. Divide and conquer is widely used in algorithms. It is an important DSA concept. This technique helps reduce problem complexity significantly.
36. What Is Memoization?
Ans:
Memoization is an optimization technique in dynamic programming. It stores previously computed results in memory. Repeated calculations are avoided using cached values. Memoization improves recursive algorithm performance. Fibonacci calculation commonly uses memoization. It reduces execution time significantly. It is important for interview preparation. Memoization helps optimize overlapping subproblem calculations effectively.
37. What Is Backtracking?
Ans:
Backtracking solves problems by exploring all possibilities. If a solution fails, it backtracks to previous step. It is used in puzzles and permutations problems. N-Queens problem is a common example. Backtracking uses recursion heavily. It may have high time complexity. It is frequently asked in coding interviews. Backtracking is useful for constraint satisfaction problems.
38. What Is Graph Cycle?
Ans:
Graph cycle occurs when a path returns to same node. Cycles can exist in directed and undirected graphs. DFS is commonly used for cycle detection. Detecting cycles is important in scheduling systems. Cycles may create infinite loops in traversal. Graph cycle problems are common in interviews. They test graph understanding skills. Cycle detection helps ensure correctness in dependency systems
39. What Is Adjacency Matrix?
Ans:
Adjacency matrix represents graph using two-dimensional array. Rows and columns represent graph vertices. Matrix value indicates edge connection between nodes. It is simple to implement for dense graphs. Memory usage increases for large sparse graphs. Graph algorithms often use adjacency matrices. It is an important graph representation method. Adjacency matrix allows fast edge lookup operations.
40. What Is Adjacency List?
Ans:
Adjacency list represents graph using linked lists or arrays. Each vertex stores list of connected vertices. It is memory efficient for sparse graphs. Traversal operations are faster in many cases. Adjacency lists are widely used in graph problems. They reduce unnecessary memory consumption. They are commonly used in interviews.

Enroll in Data Structures And Algoritham Course and UPGRADE Your Skills
Weekday / Weekend BatchesSee Batch Details41. What Is Collision In Hashing?
Ans:
Collision occurs when two keys map to same index. It is common in hash table implementation. Chaining and open addressing solve collisions. Good hash functions reduce collision chances. Collisions may affect performance negatively. Handling collisions is important for efficiency. It is a popular interview question. Efficient collision handling improves overall hash table performance.
42. What Is Load Factor?
Ans:
Load factor measures occupancy of hash table. It is calculated using filled slots divided by table size. Higher load factor increases collision probability. Rehashing may occur when load factor becomes high. It affects search and insertion efficiency. Balanced load factor improves performance. It is important in hashing concepts. Maintaining optimal load factor ensures efficient hash table operations.
43. Write A Program To Reverse A String
Ans:
This program reverses a string using StringBuilder. The reverse() method changes the order of characters in the string. It is commonly used in string manipulation problems. Interviewers ask this question to test understanding of strings and built-in methods. This program is useful for learning object methods and string handling techniques. It also improves knowledge of Java classes and memory-efficient coding practices.
- String s = “Java”;
- String rev = new StringBuilder(s).reverse().toString();
- System.out.println(rev);
- System.out.println(“Done”);
44. What Is Queue Underflow?
Ans:
Queue underflow occurs when removing element from empty queue. It indicates invalid deletion operation. Underflow may cause runtime errors. Programs should check queue status before deletion. Underflow handling improves application stability. It is common in stack and queue operations. Interviewers often ask about it. Queue underflow can be prevented using proper condition checks before dequeue operation.
45. What Is Stack Overflow?
Ans:
Stack overflow occurs when stack memory exceeds limit. Infinite recursion is a common reason. Too many function calls increase stack usage. It may crash the program execution. Proper base conditions prevent stack overflow. Memory optimization reduces overflow risks. It is an important programming concept. Stack overflow errors are commonly seen in recursive programming problems.
46. What Is Stack Underflow?
Ans:
Stack underflow occurs when popping from empty stack. It indicates invalid stack operation. Programs should check stack status before removal. Underflow may lead to runtime issues. Proper error handling avoids application crashes. It is common in stack implementation problems. It is frequently asked in interviews. Stack underflow handling improves program reliability and execution safety.
47. What Is Sparse Matrix?
Ans:
Sparse matrix contains mostly zero values. Storing all elements wastes memory space. Special techniques store only non-zero elements. Sparse matrices improve efficiency in scientific computing. They are widely used in graph algorithms. Sparse representation reduces memory consumption. It is an advanced DSA topic. Sparse matrices help improve performance in large-scale mathematical computations
48. What Is Dense Matrix?
Ans:
- Dense matrix contains mostly non-zero values. All elements are generally stored in memory. Operations on dense matrices are straightforward.
- They are commonly used in mathematics applications. Dense matrices consume more memory compared to sparse matrices.
- Matrix problems are common in interviews. Understanding matrices improves coding skills.
49. What Is Topological Sorting?
Ans:
Topological sorting arranges vertices in directed acyclic graph order. A node appears before dependent nodes. It is used in scheduling and dependency resolution. DFS and BFS approaches solve topological sorting. Cyclic graphs cannot have topological order. It is important in compiler design. It is a common graph interview topic. Topological sorting helps manage task execution in correct dependency order.
50. What Is Dijkstra Algorithm?
Ans:
Dijkstra algorithm finds shortest path in weighted graphs. It works for graphs with non-negative weights. Priority queue is commonly used for implementation. It calculates minimum distance from source node. Networking systems use Dijkstra algorithm widely. Complexity depends on graph representation. It is a popular Microsoft interview question. Dijkstra algorithm is highly important in routing and navigation systems.
51. What Is Floyd Warshall Algorithm?
Ans:
Floyd Warshall algorithm finds shortest paths between all node pairs. It uses dynamic programming approach. The algorithm works for weighted graphs. It can handle negative edge weights. Complexity is higher compared to Dijkstra algorithm. It is useful for dense graphs. It is asked in advanced interviews. Floyd Warshall algorithm simplifies all-pairs shortest path calculations effectively.
52. What Is Kruskal Algorithm?
Ans:
- Kruskal algorithm finds minimum spanning tree in graphs. It selects smallest edges without forming cycles.
- Union-find data structure is commonly used. The algorithm works efficiently for sparse graphs. It reduces overall connection cost.
- Kruskal algorithm is important in networking problems. It is a common graph interview question.
53. What Is Prim Algorithm?
Ans:
Prim algorithm also finds minimum spanning tree. It starts from one node and expands tree gradually. Minimum weight edges are selected repeatedly. Priority queue improves efficiency of implementation. Prim algorithm works well for dense graphs. It is widely used in network design. It is important for interview preparation. Prim algorithm ensures optimized connectivity with minimum total cost.
54. What Is Sliding Window Technique?
Ans:
Sliding window technique optimizes array and string problems. A window moves across data elements gradually. It reduces unnecessary repeated calculations. Sliding window improves time complexity significantly. It is used in substring and maximum sum problems. Many coding interview problems use this method. Practice is important to master it. Sliding window technique is widely used in efficient coding solutions.
55. What Is Two Pointer Technique?
Ans:
Two pointer technique uses two indexes for problem solving. It is commonly applied on sorted arrays. The pointers move based on conditions. It reduces time complexity in many problems. Pair sum problems often use this approach. It improves efficiency compared to nested loops. It is frequently asked in coding rounds. Two pointer technique simplifies searching and comparison operations efficiently.
56. What Is Kadane Algorithm?
Ans:
Kadane algorithm finds maximum subarray sum efficiently. It uses dynamic programming approach. Current sum and maximum sum are tracked continuously. Complexity is O(n) for linear traversal. It is useful for optimization problems. Kadane algorithm is a famous interview topic. It improves understanding of array problems. Kadane algorithm is widely used in performance optimization challenges.
57. What Is Bit Manipulation?
Ans:
Bit manipulation works directly on binary representations. Operators like AND, OR, XOR, and shift are used. It improves efficiency in certain algorithms. Bit manipulation is useful in competitive programming. It reduces memory and execution time. Binary calculations become easier with bit operations. It is a common coding interview topic. Bit manipulation helps solve complex problems with optimized performance.
58. What Is XOR Operation?
Ans:
XOR is a bitwise operator in programming. It returns 1 when bits are different. XOR is useful for swapping and finding unique elements. Applying XOR twice restores original value. It is efficient for low-level operations. XOR problems are common in coding interviews. Understanding binary operations is important. XOR operation is widely used in encryption and error detection systems.
59. What Is Queue Using Stack?
Ans:
Queue can be implemented using two stacks. One stack handles insertion operations. Another stack handles deletion operations. Elements are transferred between stacks when needed. This implementation demonstrates data structure concepts. It is commonly asked in interviews. It tests logical problem-solving ability. Queue using stack improves understanding of data structure transformations.
60. What Is The Difference Between Array And Linked List?
Ans:
| Feature | Array | Linked List |
|---|---|---|
| Memory Allocation | Continuous Memory Location | Non-Continuous Memory Location |
| Access Speed | Faster Random Access | Sequential Access |
| ASize | Fixed Size | Dynamic Size |
| Insertion And Deletion | Slower Due To Shifting | Faster Using Pointers |

Learn Data Structure and Algorithms with Advanced Concepts By Industry Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
61. What Is Circular Linked List?
Ans:
Circular linked list connects last node to first node. It forms a continuous circular structure. Traversal can start from any node. Circular lists are useful in scheduling systems. They save traversal time in repeated operations. They are different from linear linked lists. It is an important DSA concept. Circular linked lists are widely used in round-robin processing systems.
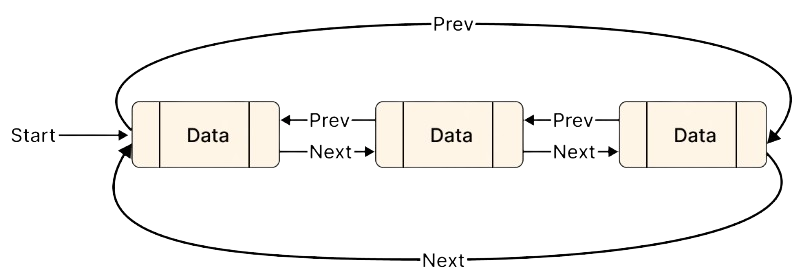
62. What Is Doubly Linked List?
Ans:
Doubly linked list contains previous and next pointers. It allows traversal in both directions. Insertion and deletion become easier. Memory usage increases due to extra pointer storage. Browser navigation uses doubly linked list concept. It is widely used in applications. It is commonly asked in interviews. Doubly linked lists improve flexibility in data traversal operations.
63. What Is Searching?
Ans:
- Searching is the process of finding target element in data. Linear and binary search are common methods.
- Efficient searching improves application performance. Search algorithms depend on data organization.
- Searching is used in databases and systems. It is one of the core DSA topics. It is essential for interview preparation.
64. Write A Program To Find Factorial Of A Number?
Ans:
This program calculates the factorial of a number using a loop. Factorial means multiplying all positive integers up to the given number. It is useful for learning loops and arithmetic operations. This question is very popular in DSA and programming interviews. It helps beginners understand iterative logic and variable updating concepts clearly. Factorial programs are also widely used in mathematics, probability, and algorithm calculations.
- int n = 5, fact = 1;
- for(int i = 1; i <= n; i++)
- fact *= i;
- System.out.println(fact);
65. What Is Unstable Sorting?
Ans:
- Unstable sorting may change order of equal elements. Quick sort is an example of unstable sorting.
- Stability is not always necessary in applications. Unstable algorithms may provide better performance sometimes.
- Understanding stability helps algorithm selection. Sorting behavior differs based on implementation. It is a common interview discussion topic.
66. What Is Balanced Tree?
Ans:
Balanced tree maintains nearly equal subtree heights. Balance improves searching and insertion efficiency. AVL and red black trees are examples. Balanced trees prevent skewed structures. Operations remain logarithmic in complexity. They are widely used in databases. Balanced tree concepts are important in interviews. Balanced trees provide faster performance for dynamic data operations.
67. What Is Skewed Tree?
Ans:
Skewed tree occurs when nodes form straight structure. It behaves similar to linked list. Search operations become slower in skewed trees. Skewed trees reduce efficiency of binary search trees. Balancing techniques solve this issue. They are important for tree optimization. It is a common interview topic. Skewed trees increase traversal time and reduce overall performance.
68. What Is Heap Sort?
Ans:
Heap sort uses heap data structure for sorting. Maximum or minimum element is repeatedly extracted. Heap property is maintained after each extraction. Complexity is O(n log n). Heap sort does not require extra memory like merge sort. It is efficient for large datasets. It is commonly asked in interviews. Heap sort provides stable performance for large-scale sorting operations.
69. What Is Radix Sort?
Ans:
Radix sort sorts numbers digit by digit. It does not use comparisons like traditional sorts. Counting sort is often used internally. Radix sort works efficiently for integers. Complexity depends on digit count. It is useful for large numeric datasets. It is an advanced sorting topic. Radix sort performs well when handling fixed-length numerical values.
70. Write A Program To Check Palindrome Number
Ans:
This program checks whether a number reads the same forward and backward. It reverses the number and compares it with the original value. If both are equal, the number is a palindrome. This problem helps in understanding loops and number operations. It also improves logical thinking and problem-solving skills for beginners. Palindrome programs are commonly asked in technical interviews and coding assessments.
- int n = 121, rev = 0, temp = n;
- while(n > 0){ rev = rev * 10 + n % 10; n /= 10; }
- System.out.println(temp == rev);
71. What Is Bucket Sort?
Ans:
Bucket sort divides elements into multiple buckets. Each bucket is sorted separately. It works efficiently for uniformly distributed data. Complexity may become linear in best case. Bucket sort is useful for floating point numbers. It combines distribution and sorting techniques. It is an advanced algorithm topic. Bucket sort improves performance when data distribution is balanced properly.
72. What Is Greedy Choice Property?
Ans:
Greedy choice property means local optimum leads to global optimum. Greedy algorithms rely on this principle. Not all problems satisfy greedy property. Activity selection problem follows greedy approach. It simplifies optimization problems significantly. Greedy methods are efficient and simple. Interviewers often ask about this property. Greedy choice property helps build faster algorithmic solutions.
73. What Is Optimal Substructure?
Ans:
Optimal substructure means optimal solution contains optimal subproblem solutions. Dynamic programming problems use this property. Divide and conquer algorithms also use it. It helps break problems into smaller parts. Understanding this property improves problem-solving skills. It is important in algorithm design. It is commonly discussed in interviews. Optimal substructure is essential for designing efficient recursive algorithms.
74. What Is Matrix Traversal?
Ans:
Matrix traversal means visiting all matrix elements systematically. Nested loops are commonly used for traversal. Traversal may occur row-wise or column-wise. Matrix problems are common in coding interviews. Efficient traversal improves algorithm performance. Spiral matrix traversal is a popular problem. It helps improve logical thinking. Matrix traversal techniques are widely used in image processing applications.
75. What Is String Matching?
Ans:
String matching searches pattern within larger text. It is used in search engines and editors. Naive and KMP algorithms solve matching problems. Efficient algorithms reduce unnecessary comparisons. Pattern matching is important in text processing. It is a common interview topic. Practice improves string problem-solving skills. String matching algorithms improve searching speed in large documents.
76. What Is KMP Algorithm?
Ans:
KMP stands for Knuth Morris Pratt algorithm. It improves string matching efficiency. Prefix table avoids repeated comparisons. Complexity becomes linear for pattern searching. KMP is useful for large text processing. It is more efficient than naive search. It is an advanced interview topic. KMP algorithm significantly reduces unnecessary string comparisons
77. What Is Longest Common Subsequence?
Ans:
Longest common subsequence finds common sequence between strings. Characters need not be continuous. Dynamic programming commonly solves this problem. It is used in text comparison applications. Complexity increases with string length. LCS is a famous coding interview problem. It improves DP understanding. Longest common subsequence helps measure similarity between sequences effectively.
78. What Is Longest Common Prefix?
Ans:
Longest common prefix finds shared starting substring. It is commonly used in string problems. Sorting or trie approaches may solve it. Prefix matching is important in search systems. Efficient solutions improve performance significantly. It is frequently asked in coding rounds. Practice strengthens string manipulation skills. Longest common prefix is useful in autocomplete and dictionary systems.
79. What Is Palindrome?
Ans:
Palindrome is a sequence that reads same forward and backward. Strings and numbers can be palindromes. Reverse comparison checks palindrome property. Palindrome problems are common in interviews. They test string and logical concepts. Examples include madam and level. It is a basic but important topic. Palindrome checking improves understanding of string traversal techniques.
80. What Is Anagram?
Ans:
Anagram means two strings contain same characters in different order. Sorting or hashing can check anagrams. Examples include listen and silent. Anagram problems test string manipulation skills. Efficient solutions reduce comparison time. They are frequently asked in coding interviews. Practice improves logical reasoning. Anagram detection is useful in word games and text analysis.
81. What Is Subarray?
Ans:
Subarray is a contiguous part of an array. Elements remain in original order. Multiple subarrays can exist in one array. Maximum subarray problems are very popular. Sliding window often solves subarray problems. Subarrays are important in coding interviews. Understanding them improves array handling skills. Subarray concepts are widely used in optimization and analytics problems.
82. What Is Subsequence?
Ans:
Subsequence is a sequence derived without changing order. Elements need not be contiguous. Many subsequences exist for a sequence. Dynamic programming commonly solves subsequence problems. Longest increasing subsequence is a famous example. Subsequence questions test logical thinking. They are important for interview preparation. Subsequences are important in sequence analysis and pattern recognition tasks.
83. What Is Permutation?
Ans:
Permutation means arrangement of elements in different orders. Recursion and backtracking generate permutations. Number of permutations increases factorially. Permutation problems are common in interviews. They improve understanding of recursion. Applications include scheduling and cryptography. Practice is essential for mastering permutations. Permutation algorithms are useful in combinational and optimization problems..
84. What Is Combination?
Ans:
- Combination means selecting elements without considering order. It differs from permutation significantly.
- Combinations are widely used in probability problems. Recursion and backtracking solve combination questions.
- Combination formulas are important in mathematics. Coding interviews often include these problems. They improve logical problem-solving ability.
85. Write A Program To Print Fibonacci Series?
Ans:
This program prints the Fibonacci series where each number is the sum of the previous two numbers. It uses a loop and variable swapping technique. Fibonacci problems are important for improving logical thinking skills. They are commonly asked in fresher technical interviews. This program helps beginners understand sequence generation and iterative programming concepts. Fibonacci logic is also widely used in mathematics, algorithms, and dynamic programming problems.
- int a = 0, b = 1;
- for(int i = 0; i < 5; i++){
- System.out.print(a + ” “);
- int c = a + b; a = b; b = c; }
86. What Is Max Heap?
Ans:
Max heap stores maximum element at root node. Parent nodes are larger than child nodes. It supports efficient maximum element retrieval. Heap sort often uses max heap structure. Insertions and deletions maintain heap property. Max heaps are used in scheduling systems. It is frequently asked in interviews. Max heap improves priority-based data processing performance effectively.
87. What Is Depth Of Tree?
Ans:
Depth of tree represents longest path from root node. It measures tree height and complexity. Recursive methods commonly calculate tree depth. Balanced trees usually have smaller depth. Greater depth may reduce performance efficiency. Tree depth problems are common in interviews. They improve recursion understanding. Tree depth analysis helps optimize hierarchical data structures efficiently.
88. What Is Level Order Traversal?
Ans:
Level order traversal visits tree nodes level by level. Queue data structure is commonly used. It is also called breadth first traversal. Nodes are processed from left to right. It is useful for tree visualization problems. Many interview questions use this traversal. It is an important tree concept. Level order traversal helps understand tree structure systematically.
89. What Is Inorder Traversal?
Ans:
Inorder traversal visits left subtree first. Root node is processed after left subtree. Right subtree is processed at the end. In binary search trees, inorder gives sorted output. Recursion is commonly used for implementation. It is one of the major tree traversals. It is frequently asked in interviews. Inorder traversal is widely used for sorted data retrieval operations..
90. What Is Preorder Traversal?
Ans:
Preorder traversal processes root node first. Left subtree is visited after root. Right subtree is visited last. Preorder traversal is useful for copying trees. Recursive implementation is common. It is widely used in expression trees. It is an important interview topic. Preorder traversal helps recreate tree structures efficiently.
91. What Is Postorder Traversal?
Ans:
Postorder traversal visits left subtree first. Right subtree is processed after left subtree. Root node is processed at the end. It is useful for deleting trees safely. Recursive methods commonly implement postorder traversal. It is one of the important tree traversals. Interviewers often ask about it. Postorder traversal ensures child nodes are processed before parent nodes
92. What Is Disjoint Set?
Ans:
Disjoint set is a data structure for grouping elements. It supports union and find operations. Path compression improves efficiency significantly. Disjoint set is useful in graph algorithms. Kruskal algorithm commonly uses it. It is important in advanced DSA concepts. It is a popular interview topic. Disjoint sets help efficiently manage connected components in graphs.
93. What Is Path Compression?
Ans:
Path compression optimizes disjoint set operations. It shortens paths during find operations. Future searches become much faster. It improves overall algorithm performance. Path compression is used with union-find structures. It reduces tree height significantly. It is important in graph problems. Path compression greatly improves efficiency in repeated search operations.
94. What Is Union By Rank?
Ans:
Union by rank balances disjoint set trees. Smaller tree joins larger tree during union. It reduces overall tree height. Search operations become more efficient. Union by rank works with path compression. Together they provide near constant complexity. It is commonly discussed in interviews. Union by rank improves scalability of union-find data structures.
95. What Is Shortest Path Problem?
Ans:
Shortest path problem finds minimum distance between nodes. Graph algorithms commonly solve this problem. Dijkstra and Bellman Ford are popular methods. Applications include Efficient solutions improve routing performance. It is a major graph interview topic. Practice strengthens graph problem-solving skills.
96. What Is Bellman Ford Algorithm?
Ans:
Bellman Ford algorithm finds shortest paths in weighted graphs. It can handle negative edge weights. The algorithm relaxes edges repeatedly. It also detects negative weight cycles. Complexity is higher compared to Dijkstra algorithm. Bellman Ford is useful for specific graph problems. It is asked in advanced interviews. Bellman Ford algorithm is valuable for complex weighted graph analysis.
97. What Is Negative Cycle?
Ans:
Negative cycle occurs when graph cycle has negative total weight. Traversing cycle repeatedly reduces path cost infinitely. Bellman Ford detects negative cycles efficiently. Negative cycles create issues in shortest path problems. Graph algorithms must handle them carefully. They are important in advanced graph theory. Interviewers may ask related questions. Negative cycles can make shortest path calculations unreliable.
98. What Is Complexity Analysis?
Ans:
Complexity analysis evaluates efficiency of algorithms. Time and space complexities are commonly analyzed. It helps compare different approaches objectively. Efficient algorithms reduce execution cost significantly. Big O notation represents complexity formally. Complexity analysis is important in interview discussions. It improves optimization and coding skills. Complexity analysis helps developers design scalable software solutions.
99. What Is NP Hard Problem?
Ans:
NP hard problems are highly complex computational problems. No known polynomial-time solution exists currently. Traveling salesman problem is a famous example. Approximation algorithms are often used for solutions. NP hard concepts belong to theoretical computer science. They are discussed in advanced interviews. Understanding them improves algorithm knowledge. NP hard problems are important in optimization and research fields.
100. Why Is DSA Important In Interviews?
Ans:
DSA is important because it improves problem-solving ability. Companies use DSA questions to test logical thinking. Efficient coding skills are evaluated through algorithms. Data structures help optimize memory and execution time. Strong DSA knowledge increases chances of job selection. Microsoft and other top companies focus heavily on DSA. DSA preparation also improves confidence during technical interview rounds




