
Last updated on 17th Apr 2026| 7337
Infosys interviews often assess both technical and behavioral skills. Candidates can expect questions on programming languages, data structures, and algorithms for technical roles. Behavioral questions may focus on teamwork, problem-solving, and adaptability. It’s essential to prepare examples from past experiences that showcase your skills and align with Infosys’s core values, emphasizing your ability to learn and collaborate effectively.
1. Explain OOP concepts in Java ?
Ans:
Object-Oriented Programming (OOP) has four main pillars: Encapsulation, Abstraction, Inheritance, and Polymorphism. Encapsulation means wrapping data and methods inside a class and restricting direct access using private/public, improving security. Abstraction hides implementation details and shows only essential features using abstract classes or interfaces. Inheritance allows a child class to reuse properties and methods of a parent class, reducing code duplication. Polymorphism means one method behaves in different ways, like method overloading or overriding, making code flexible and reusable.
2. Difference between C and Java ?
Ans:
| Feature | C Language | Java |
|---|---|---|
| Programming Type | Procedural programming language | Object-oriented programming language |
| Approach | Top-down approach | Bottom-up approach |
| Platform Dependency | Platform dependent | Platform independent (JVM based) |
| Memory Management | Manual (using pointers, malloc/free) | Automatic (Garbage Collection) |
| OOP Support | Does not support OOP concepts | Fully supports OOP (Encapsulation, Inheritance, Polymorphism, Abstraction) |
| Security | Less secure | More secure due to JVM and no direct pointers |
3. What distinguishes Method Overloading and Method Overriding in Java?
Ans:
DBMS (Database Management System) is software used to store, manage, and retrieve data in an organized way. It acts as an interface between the user and the database, allowing easy access and manipulation of data. DBMS helps in operations like inserting, updating, deleting, and querying data efficiently. It also ensures data security, reduces redundancy, and maintains data integrity. Examples of DBMS include MySQL, Oracle, and SQL Server. It is widely used in applications like banking systems, airline reservations, and online shopping platforms.
4. How do ClassesWhat is Normalization in DBMS and why is it important in database design?and Interfaces vary in Java?
Ans:
- Normalization is the process of organizing data in a database in a structured and efficient way.
- It is used to reduce data redundancy (duplicate data) and improve data consistency.
- It divides large tables into smaller related tables and connects them using relationships.
- This process helps in eliminating insertion, update, and deletion anomalies in databases.
- Normalization follows a set of rules called Normal Forms such as 1NF, 2NF, 3NF, and BCNF.
- Each normal form improves the structure of the database step by step.
- It ensures better data integrity, meaning data remains accurate and reliable.
5. What is a programming language??
Ans:
A programming language is a formal set of instructions used to communicate with a computer and make it perform specific tasks. It allows developers to write code that can be executed by a machine to solve problems, process data, and build software applications. Programming languages act as a bridge between human-readable logic and machine-understandable instructions. Examples include C, C++, Java, Python, and JavaScript. These languages are used in different domains such as web development, mobile apps, data science, and system programming.
6. What is SDLC and what are the main phases involved in it??
Ans:
- SDLC (Software Development Life Cycle) is a structured process used to design, develop, test, and deploy software applications.
- It ensures that software is built in a systematic and efficient way with high quality.
- SDLC helps developers manage time, cost, and resources effectively during software development.
- It consists of several important phases that guide the entire development process.
7.What is Agile methodology and how is it useful in software development?
Ans:
Agile methodology is a modern software development approach that focuses on flexibility, collaboration, and continuous improvement. It divides a project into small parts called sprints or iterations, where each sprint delivers a working version of the software. After every sprint, feedback is taken from customers and improvements are made. Agile allows changes even in later stages of development, making it highly adaptable.
8. What is SQL ?
Ans:
SQL (Structured Query Language) is a standard language used to manage data in relational databases. It allows users to perform operations like SELECT, INSERT, UPDATE, and DELETE. SQL helps store, retrieve, and organize large data efficiently. It ensures data integrity, security, and easy access, and is widely used in database systems like MySQL and Oracle.
9. What is the difference between compiler and interpreter?
Ans:
| Feature | Compiler | Interpreter |
|---|---|---|
| Translation | Translates entire program at once | Translates code line by line |
| Execution Speed | Faster execution after compilation | Slower due to line-by-line execution |
| Error Handling | Shows all errors after compilation | Stops and shows error immediately |
| Example | C, C++ | Python, JavaScript |
10. What is cloud computing?
Ans:
Cloud computing is the delivery of computing services such as servers, storage, databases, networking, and software over the internet instead of using local computers. It allows users to access resources anytime, anywhere, with high scalability and flexibility. It reduces costs by eliminating the need for physical hardware and maintenance, as users pay only for the services they use.
11. Why should we hire you?
Ans:
- Strong understanding of required technical skills with the ability to apply them effectively in real-world situations. Quick learner who adapts easily to new tools, technologies, and working environments, ensuring smooth performance in different tasks.
- Good problem-solving and analytical thinking abilities with a strong focus on teamwork and communication. Responsible, reliable, and committed to deadlines with a positive attitude, initiative-taking mindset, and eagerness to grow and contribute to company success.
12. What is the difference between HTTP and HTTPS?
Ans:
| Feature | HTTP | HTTPS |
|---|---|---|
| Full Form | HyperText Transfer Protocol | HyperText Transfer Protocol Sec. |
| Security | Not secure | Secure (SSL/TLS encryption) |
| Data Protection | Plain text transfer | Encrypted data transfer |
| Port | 80 | 443 |
| Usage | General websites | Secure sites (login, payments) |
13. What is a computer network?
Ans:
A computer network is a collection of interconnected computers and devices that communicate with each other to share data, resources, and services. It allows users to exchange information, access the internet, share files, and use hardware like printers efficiently. Networks can be wired or wireless and help improve communication, collaboration, and resource utilization across systems.
14. What is an operating system?
Ans:
An operating system (OS) is system software that acts as an interface between the user and the computer hardware. It manages hardware resources, runs applications, handles memory, files, and processes, and ensures smooth functioning of the computer. Examples include Windows, Linux, and macOS.
15. What is a class in OOP?
Ans:
- A class in OOP is a blueprint for creating objects. It acts like a design or template that defines how objects should be structured and behave. Without a class, we cannot create multiple similar objects in a structured way.
- It defines properties (attributes) and behaviors (methods). Attributes store data like name or age, while methods define actions like run() or display(). Together they represent the characteristics and functionality of an object.
- Objects are instances of a class. This means an object is a real entity created using the class blueprint. Each object can have its own values but follows the same structure defined by the class.
16. What is an object?
Ans:
- An object is an instance of a class in OOP. It is created using a class blueprint and represents a specific example of that class in memory with its own unique identity.
- It represents a real-world entity with state and behavior. This means an object can model things like a student, car, or bank account, combining both data and actions in a single unit.
- State is defined by attributes (data). These attributes store information about the object such as name, color, age, or speed, which describe its current condition or properties.
- Example: A “Car” object can be a specific car like red Toyota with actions like start and stop. Each car object can differ in color or model but still share common behaviors defined in the Car class.
17. What is exception handling?
Ans:
Exception handling is a mechanism used in programming to handle runtime errors and prevent program crashes. It uses keywords like try, catch, finally, and throw. For example, dividing a number by zero can cause an exception, which can be handled gracefully using exception handling techniques. It improves user experience.
18. What is Method overloading?
Ans:
- Method overloading is a feature in object-oriented programming where multiple methods can have the same name but must differ in their parameter list. This means the method name remains the same, but the number, type, or order of parameters changes, allowing the same method name to perform different tasks based on input.
- It allows methods to perform similar tasks with different types or numbers of inputs. This makes programming more flexible because a single method name can handle various operations depending on the data passed to it, reducing confusion and improving code organization.
- It is an example of compile-time polymorphism. The decision of which method to call is made during compilation, not runtime, which helps in improving performance and efficiency in execution.
19. What is method overriding?
Ans:
Method overriding is a feature in object-oriented programming where a child class provides its own implementation of a method that is already defined in its parent class. The method in both classes must have the same name, same parameters, and same return type. Method overriding supports runtime polymorphism, meaning the decision of which method to execute is made at runtime based on the object type. For example, if a parent class Animal has a method sound(), a child class Dog can override it to define its own behavior like “Bark”.
20. What is a pointer in C, How We Use?
Ans:
A pointer is a variable that stores the memory address of another variable. It is used in C programming to access and manipulate memory directly. Pointers are powerful but must be used carefully to avoid errors like memory leaks. They are widely used in dynamic memory allocation and data structures like linked lists.
20. What is Java Virtual Machine (JVM)?
Ans:
JVM (Java Virtual Machine) is a part of Java Runtime Environment that executes Java bytecode. It makes Java platform-independent because the same code can run on any system with JVM installed. JVM handles memory management, garbage collection, and execution of programs, ensuring smooth performance of Java applications.
21. What is SQL JOIN?
Ans:
SQL JOIN is used to combine data from two or more tables based on a related column between them. It helps retrieve meaningful information by linking tables using primary and foreign keys. INNER JOIN returns only matching records, LEFT JOIN returns all records from the left table and matched ones from the right, RIGHT JOIN does the opposite, and FULL JOIN returns all records when there is a match in either table.
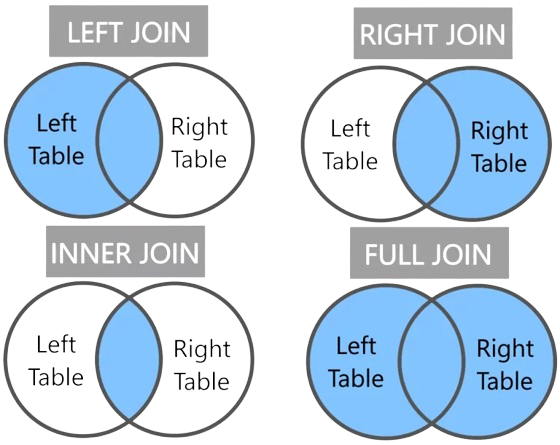
22. What is primary key in DBMS??
Ans:
- A primary key is a column or set of columns used to uniquely identify each record in a database table. It ensures every row has a unique identity.
- It must contain unique values for each record. No two rows in the table can have the same primary key value, which avoids duplication of data.
- A primary key cannot contain NULL values. Every record must have a valid value, ensuring completeness and reliability of the database.
- A table can have only one primary key. However, that key may consist of multiple columns combined, known as a composite key.
23. What is foreign key?
Ans:
A foreign key is a column or set of columns in a database table that refers to the primary key of another table. It is used to create and maintain relationships between two tables in a relational database. The foreign key ensures referential integrity, meaning that the value in the foreign key column must match an existing value in the referenced primary key column or can be NULL. It helps link related data across tables and prevents invalid data entries. For example, in a Student and Department table, Department_ID in the Student table can act as a foreign key referring to the Department table’s primary key.
24.What is recursion?
Ans:
Recursion is a programming technique where a function calls itself to solve a problem. It breaks a complex problem into smaller sub-problems until it reaches a base condition, which stops the function from calling itself again. Recursion is commonly used in problems like factorial calculation, Fibonacci series, and tree traversal. However, if not used properly with a base case, it can lead to infinite loops or stack overflow errors.
25. What is software testing?
Ans:
Software testing is the process of evaluating and verifying that a software application works correctly and meets the required requirements. It is done to find bugs, errors, or missing features before the software is released to users. Testing helps improve software quality, performance, security, and reliability. The main goal of software testing is to ensure the software is stable and works as expected in all conditions.
26. What is SDLC waterfall model?
Ans:
- The Waterfall Model is a linear SDLC approach where each phase is completed step by step. It is simple and easy to manage for small projects.
- It includes stages like requirement gathering, design, coding, testing, deployment, and maintenance. Each phase must be finished before the next begins.
- It is best for projects with clear and fixed requirements. However, changes are difficult once development starts, making it less flexible.
27. What is a variable?
Ans:
A variable is a named memory location used to store data that can be changed during program execution. It acts as a container for holding values like numbers, characters, or strings. Each variable has a specific data type that defines the kind of data it can store. Variables make it easier to write flexible and reusable programs by allowing values to be updated and used in different operations.
28. What is cloud storage?
Ans:
- Cloud storage is a service that allows users to store data such as files, photos, and documents on remote servers accessed through the internet instead of local storage devices. It provides easy access to data from anywhere, at any time, using different devices. Cloud storage offers scalability, backup, and data security, and users can increase or decrease storage based on their needs. Examples include Google Drive, Dropbox, and OneDrive.
29. What is a function in programming?
Ans:
- A function is a block of code designed to perform a specific task. It runs only when called and helps organize program logic into smaller, reusable parts for better structure and clarity.
- It helps in breaking a program into smaller, manageable parts. This makes complex problems easier to solve by dividing them into simple steps that can be handled separately and efficiently.
- Functions improve code reusability and avoid repetition. Once defined, a function can be used multiple times in a program without rewriting the same code again and again.
30. What is debugging?
Ans:
Debugging is the process of identifying, analyzing, and fixing errors or bugs in a computer program. These errors may cause the program to behave incorrectly or stop working. Debugging helps developers find the root cause of issues and correct them to ensure the software runs smoothly and produces the expected output. The main goal of debugging is to improve the quality, reliability, and performance of the software.
31. What is inheritance?
Ans:
Inheritance is an object-oriented programming concept where one class (child class) acquires the properties and behaviors of another class (parent class). It helps in code reusability, reduces duplication, and makes programs easier to manage. The child class can also add new features or override existing ones. For example, a “Vehicle” class can be a parent class, and a “Car” class can inherit its features like wheels and engine.
32. What is polymorphism?
Ans:
Polymorphism is an object-oriented programming concept where a single action or method can have different behaviors depending on the object or context. The word means “many forms.” It allows the same function or method name to perform different tasks. Polymorphism can be achieved through method overloading (compile-time) and method overriding (run-time).
33. What is encapsulation?
Ans:
- Encapsulation is an OOP concept that combines data and methods into a single unit called a class, helping to organize code and improve structure.
- It restricts direct access to data using access modifiers like private, protecting information and ensuring data security and controlled access.
34. What is a loop in programming?
Ans:
A loop in programming is used to execute a block of code repeatedly until a specific condition is met. It helps reduce repetition and makes code more efficient.
- #include
int main() { for(int i = 1; i <= 5; i++) { printf("%d\n", i); } return 0; }
In this example, the for loop prints numbers from 1 to 5 by repeating the same code multiple times until the condition becomes false.
35. What is an identifier?
Ans:
An identifier is the name given to variables, functions, arrays, or classes in programming. It helps in identifying and differentiating elements in a program. Identifiers must follow rules like starting with a letter or underscore and not using keywords. They improve readability and structure of the code, making it easier for developers to understand and maintain programs.
36. What is data structure?
Ans:
A data structure is a way of organizing and storing data efficiently so that it can be accessed and modified easily. Examples include arrays, linked lists, stacks, queues, trees, and graphs. Choosing the right data structure improves program performance. It is widely used in software development to handle large and complex datasets effectively.
37. What is stack?
Ans:
A stack is a linear data structure that follows the Last In, First Out (LIFO) principle, where the last element added is the first one to be removed. It supports basic operations such as push (to add an element), pop (to remove the top element), and peek (to view the top element without removing it). Stacks are commonly used in computer science for managing function calls, evaluating expressions, and implementing features like undo and redo in applications.
38. What is queue?
Ans:
A queue is a linear data structure that follows the “First In, First Out” (FIFO) principle, meaning the first element added is the first one to be removed. It works like a line of people waiting for a service. The main operations are enqueue (adding an element at the rear) and dequeue (removing an element from the front). Queues are widely used in computer systems for scheduling tasks, managing resources, handling requests, and in processes like printing and data buffering.
39. What is time complexity?
Ans:
- Time complexity measures how the running time of an algorithm increases as the input size grows. It helps understand how efficient a program is when handling small or large amounts of data.
- It is commonly expressed using Big O notation, such as O(1), O(n), and O(n²), which describe the growth rate of operations rather than exact execution time on a specific machine.
40. What is space complexity?
Ans:
- Space complexity refers to the amount of memory an algorithm uses as the input size increases. It includes both the memory required for input data and the extra space needed for variables, arrays, or functions.
- It is usually expressed using Big O notation, such as O(1), O(n), or O(n²), which shows how memory usage grows relative to input size rather than exact memory in bytes.
- Space complexity considers auxiliary space, which is the extra memory used by the algorithm excluding input data. Efficient algorithms aim to minimize this extra memory usage.
41. What is Agile model?
Ans:
Agile is a software development methodology that focuses on iterative development and continuous feedback. Work is divided into small cycles called sprints. It allows flexibility to adapt to changes quickly. Agile improves collaboration between teams and customers, ensuring faster and better product delivery.
42. What is Scrum?
Ans:
Scrum is an agile framework used for managing and completing complex projects, especially in software development. It focuses on iterative progress through short cycles called sprints, where teams plan, develop, and review work in small increments. Scrum emphasizes teamwork, continuous feedback, and adaptability to changing requirements. Key roles include the Scrum Master, Product Owner, and development team, all working together to deliver high-quality products efficiently.
42. What is SDLC requirement phase?
Ans:
The requirement phase in the Software Development Life Cycle (SDLC) is the stage where system needs are collected, analyzed, and documented. It involves gathering requirements from stakeholders through methods like interviews and surveys. These requirements include functional and non-functional needs. The final output is a clear requirement specification document that guides design and development. This phase is important because errors here can affect the entire project.
43. What is testing in SDLC?
Ans:
- Testing in SDLC is the phase where the developed software is checked to find errors, bugs, or defects before it is released to users. It ensures the system works as expected.
- It involves different levels like unit testing, integration testing, system testing, and user acceptance testing to verify each part of the software and the whole application.
- The main goal of testing is to improve software quality, reliability, and performance by identifying and fixing issues early in the development process.
- Testing in SDLC is the phase where the developed software is checked to find errors, bugs, or defects before it is released to users. It ensures the system works as expected.
- It involves different levels like unit testing, integration testing, system testing, and user acceptance testing to verify each part of the software and the whole application.
- The main goal of testing is to improve software quality, reliability, and performance by identifying and fixing issues early in the development process.
- Paging is a memory management technique where logical memory is divided into fixed-size pages and physical memory into frames, allowing non-contiguous allocation and efficient memory usage in operating systems.
- It uses a page table to map pages to frames, helping reduce external fragmentation and improving memory utilization by efficiently managing how processes are stored and accessed.
- Deadlock is a situation in an operating system where two or more processes are blocked because each process is waiting for a resource held by another process, causing a permanent waiting state.
- It occurs due to circular waiting and improper resource allocation, and can be handled using prevention, avoidance, detection, or recovery techniques in operating systems.
- Synchronization is the process of coordinating multiple threads or processes to ensure safe access to shared resources, preventing conflicts and maintaining data consistency in a system.
- It uses mechanisms like locks, semaphores, and monitors to control execution order and avoid issues like race conditions in concurrent programming environments.
- The life cycle of a thread in Java describes the different states a thread goes through during its execution. A thread is created in the New state when an object of Thread class is created. When the start() method is called, it moves to the Runnable state, where it is ready to run and waiting for CPU time.
- When the thread is actually executing, it enters the Running state. If the thread is temporarily paused due to waiting for resources, sleep, or input/output operations, it goes into the Blocked or Waiting state. After completing its execution, the thread enters the Terminated (Dead) state, where it cannot be restarted again.
- Compiler optimization is the process of improving the efficiency of generated machine code without changing its output, making programs run faster and use fewer system resources.
- It removes redundant code, reduces unnecessary computations, and improves instruction execution during compilation to enhance overall program performance.
- Debugging tools are software utilities that help developers identify, analyze, and fix errors or bugs in programs by allowing step-by-step execution and code inspection.
- They provide features like breakpoints, variable monitoring, and memory analysis to trace program flow and improve software quality and reliability.
- A flowchart is a diagram that represents an algorithm using symbols like rectangles, diamonds, and arrows to show the flow of steps and decisions.
- It helps programmers visualize program logic before coding, making it easier to understand, debug, and communicate system design clearly.
- Sorting is the process of arranging data in a specific order such as ascending or descending to improve data organization and access.
- Common sorting algorithms include bubble sort, selection sort, merge sort, and quick sort, used in databases and applications for efficient data handling.
- Searching is the process of finding a specific element in a data structure such as arrays or databases.
- Methods like linear search and binary search are used, where binary search is faster but requires sorted data for efficient operation.
- Big O notation describes the performance of an algorithm in terms of time and space complexity as input size grows.
- Common examples include O(1), O(n), O(log n), and O(n²), which help compare efficiency of different algorithms in programming.
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
- A graph is a data structure consisting of vertices (nodes) connected by edges, used to represent relationships between different objects or data points.
- It can be directed or undirected and is used in real-world applications like social networks, maps, and computer networks. Traversal methods include BFS and DFS.
- Inheritance in Java is an OOP concept where one class acquires properties and methods of another class, promoting code reusability.
- It forms a parent-child relationship between classes. Types include single, multilevel, and hierarchical inheritance.
- An interface in Java is a blueprint of a class that contains abstract methods used to achieve abstraction and multiple inheritance.
- A class implements an interface and provides method definitions, improving flexibility and supporting better system design.
- An abstract class in Java is a class that cannot be instantiated and may contain both abstract and non-abstract methods.
- It is used for partial abstraction, and subclasses must implement abstract methods to provide specific functionality.
- A constructor is a special method in a class that is automatically called when an object is created to initialize values.
- It has the same name as the class and does not return any value. It can be default or parameterized depending on requirement.
44. What is testing in SDLC?
Ans:
45. What is black box testing?
Ans:
Black box testing is a software testing method where the tester checks the functionality of an application without knowing its internal code or structure. It focuses only on inputs and outputs. Testers give different inputs and verify whether the output matches expected results. It is used to check user requirements and ensure the system works correctly from an external user point of view.

Enroll in Java Certification Course and UPGRADE Your Skills
Weekday / Weekend BatchesSee Batch Details46. What is white box testing?
Ans:
White box testing is a testing technique where the tester has knowledge of the internal code structure. It focuses on checking logic, loops, conditions, and code paths to ensure proper functioning. Developers usually perform this type of testing during development. It helps in finding hidden errors, improving code quality, and ensuring that all internal components work correctly as expected.
47. What is SDLC maintenance phase?
Ans:
The maintenance phase in SDLC occurs after the software is deployed to users. It involves fixing bugs, improving system performance, and updating the software based on user feedback. This phase ensures that the application continues to run smoothly over time. It also helps the system adapt to new requirements, security updates, and changing business needs for long-term usability.
48. What is HTML?
Ans:
HTML (HyperText Markup Language) is the standard language used to create and design web pages. It structures content such as text, images, links, and multimedia on the internet. HTML uses tags like <p>, <h1>, and <a> to define elements. It forms the basic building block of all websites and works along with CSS and JavaScript to create complete web pages.
49. What is CSS?
Ans:
CSS (Cascading Style Sheets) is used to style and design web pages. It controls the layout, colors, fonts, spacing, and overall appearance of HTML elements. CSS helps make websites visually attractive and user-friendly. It separates design from content, making web development easier and more organized. It is widely used to enhance the look and feel of modern websites.
50. What is JavaScript?
Ans:
JavaScript is a programming language used to make web pages interactive and dynamic. It allows features like form validation, animations, pop-ups, and real-time updates. JavaScript works along with HTML and CSS to build complete web applications. It is widely used in front-end development and also supports back-end development through environments like Node.js.
51. What is API?
Ans:
API (Application Programming Interface) is a set of rules that allows different software applications to communicate with each other. It enables data sharing and functionality exchange between systems. APIs are widely used in web development, mobile applications, and cloud services. They help developers integrate external services like payment gateways, maps, and social media into applications.
52. What is REST API?
Ans:
REST API is a web service that follows REST (Representational State Transfer) architecture principles. It uses standard HTTP methods such as GET, POST, PUT, and DELETE for communication. REST APIs are lightweight, scalable, and easy to use. They are commonly used in web and mobile applications to transfer data between client and server efficiently in JSON or XML format.
53. What is JSON?
Ans:
JSON (JavaScript Object Notation) is a lightweight data format used to store and exchange information between systems. It is easy for humans to read and write and easy for machines to parse. JSON is commonly used in APIs to transfer data between client and server. It organizes data in key-value pairs and is widely supported in modern programming languages.
54. What is Paging in OS?
Ans:
55. What is Deadlock?
Ans:
56. What is Synchronization?
Ans:
57. What Is Life Cycle Of Thred In Java
Ans:
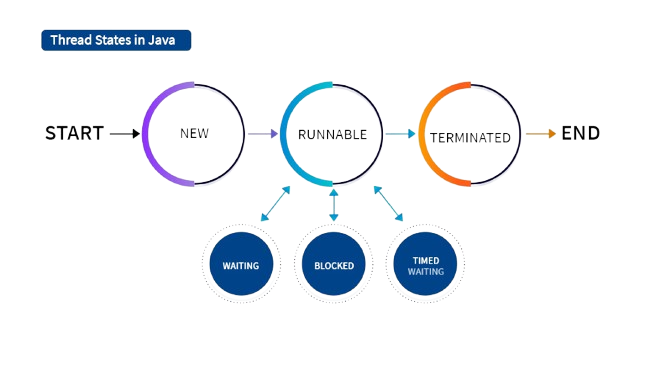
58. What is Compiler Optimization?
Ans:
59. What are Debugging Tools?
Ans:
60. What is virtual memory?
Ans:
Virtual memory is a memory management technique that uses disk space as an extension of RAM. It allows systems to run large programs even when physical memory is limited. It improves multitasking and system performance by efficiently managing memory usage. It works by temporarily moving data between RAM and disk storage when required, allowing smooth execution of multiple applications. It also helps prevent system crashes by providing additional usable memory space.
61. What is normalization in DBMS?
Ans:
Normalization is the process of organizing database tables to reduce redundancy and improve data integrity. It divides large tables into smaller related tables to avoid duplication of data. It ensures proper relationships between tables using keys like primary and foreign keys. This process improves storage efficiency and maintains consistency of data across the database system.
62. What is indexing in DBMS?
Ans:
Indexing is a technique used in databases to speed up data retrieval by creating a separate structure for quick searching. It improves query performance and reduces the time required to find records. Instead of scanning the entire table, the database uses an index to locate data faster. However, it requires extra storage space and maintenance during data updates.
63. What is ER diagram?
Ans:
An ER diagram is a visual representation of database structure that shows entities, attributes, and relationships between them. It is used in database design to clearly understand how data is organized before implementation. It helps developers design efficient databases and visualize system structure in a simple and understandable way.
64. What is an algorithm?
Ans:
An algorithm is a step-by-step procedure used to solve a problem or perform a task. It takes input, processes it, and produces output in a finite number of steps. Algorithms are independent of programming languages and form the foundation of programming. They help in designing efficient solutions for computational problems.
65. What is flowchart?
Ans:
66. What is sorting?
Ans:
67. What is searching?
Ans:
68. What is Big O notation?
Ans:

Learn Java Training with Advanced Concepts By Industry Experts
69. What is a compiler?
Ans:
A compiler is a program that converts high-level programming language code into machine language so that the computer can execute it. It scans the entire program at once and generates an executable file. Errors are displayed after compilation is completed. It is faster during execution because the code is already translated before running. Examples include GCC for C/C++ and Javac for Java.
70. What is an interpreter?
Ans:
An interpreter is a program that executes code line by line instead of translating the whole program at once. It stops execution immediately when an error occurs, making debugging easier. Interpreted languages include Python and JavaScript. It is slower than a compiler but useful for testing and development because it runs code step by step.
71. What is an array list?
Ans:
An ArrayList is a dynamic data structure in Java that can grow or shrink in size during program execution. It is part of the Java Collections Framework and provides flexibility compared to fixed-size arrays. It allows easy insertion, deletion, and traversal of elements. It is widely used in programming for managing dynamic data efficiently.
72. What is linked list?
Ans:
A linked list is a linear data structure where elements are stored in nodes, and each node contains data and a reference to the next node. It is dynamic in nature and allows efficient memory usage. It supports easy insertion and deletion of elements. Types include singly linked list, doubly linked list, and circular linked list.
73. What is tree data structure?
Ans:
A tree is a hierarchical data structure consisting of nodes connected by edges, with a root node at the top and child nodes below. It is used to represent hierarchical relationships. Common types include binary trees and binary search trees. Trees are widely used in databases, file systems, and searching algorithms.
74. What is graph?
Ans:
75. What is inheritance in Java?
Ans:
76. What is interface in Java?
Ans:
77. What is abstract class?
Ans:
78. What is constructor?
Ans:
79. What is destructor?
Ans:
A destructor is used to destroy objects and free memory allocated to them. In languages like C++, destructors are automatically called when an object goes out of scope. It helps in releasing system resources properly. Java does not use explicit destructors because it has automatic garbage collection to manage memory efficiently and remove unused objects.
80. What is exception in Java?
Ans:
An exception in Java is an event that occurs during program execution and disrupts the normal flow of the program. It happens due to errors like division by zero, null pointer access, or file not found. Java handles exceptions using try-catch blocks, which helps in maintaining program stability and preventing unexpected program termination.
81. What is try-catch block?
Ans:
A try-catch block is used in Java to handle exceptions and prevent program crashes. The code that may cause an error is written inside the try block, and if an error occurs, the catch block handles it. This mechanism ensures smooth program execution and improves reliability by managing runtime errors effectively.
82. What is final keyword?
Ans:
The final keyword in Java is used to restrict modification. A final variable cannot be changed once assigned, a final method cannot be overridden, and a final class cannot be inherited. It is used to provide security, maintain consistency, and prevent unwanted changes in programs, ensuring stable and predictable behavior.
83. What is static keyword?
Ans:
The static keyword is used to declare class-level members that belong to the class rather than individual objects. Static variables and methods are shared among all instances of a class. It is commonly used for memory management and utility functions, as it allows access without creating an object of the class.
84. What is memory leak?
Ans:
A memory leak occurs when a program fails to release unused memory, causing a gradual reduction in available system memory. It happens due to improper memory management and can lead to slow performance or system crashes. It is a common issue in long-running applications if resources are not properly released.
85. What is garbage collection?
Ans:
Garbage collection is an automatic memory management process in Java that removes unused objects from memory. It helps in freeing up memory space without requiring manual intervention from the programmer. This process improves application performance and prevents memory leaks by efficiently managing system resources.
86. What is file handling?
Ans:
File handling refers to operations such as creating, reading, writing, and deleting files in a computer system. It allows programs to store data permanently and retrieve it when needed. Programming languages provide libraries and functions to handle files efficiently, making data storage and management easier for applications.
87. What is networking socket?
Ans:
A socket is an endpoint used for communication between two machines over a network. It enables data exchange between client and server applications. Sockets are widely used in network programming, web applications, and real-time systems to establish reliable communication between devices.
88. What is URL?
Ans:
URL (Uniform Resource Locator) is the address used to access resources on the internet such as web pages, files, or services. It consists of protocol, domain name, and path. The URL helps browsers locate and retrieve specific resources from the web efficiently.
89. What is DNS?
Ans:
DNS (Domain Name System) is a system that translates domain names into IP addresses so that computers can understand and load websites. It works like a phonebook of the internet, allowing users to access websites using easy-to-remember names instead of numeric IP addresses.
90. What is encryption?
Ans:
Encryption is the process of converting data into a coded format to prevent unauthorized access. It ensures data security during transmission and storage. Only authorized users with a valid key can decrypt the data and read the original information, making it an important technique for protecting sensitive information in computer systems and networks.




