
Last updated on 18th Apr 2026| 7335
Microsoft Technical Interview Questions for Freshers is a valuable resource designed to help candidates prepare for the technical hiring process at Microsoft. It includes frequently asked questions on data structures, algorithms, programming concepts, databases, operating systems, and problem-solving techniques, along with clear and simple explanations. This guide helps freshers understand the interview pattern, strengthen their technical skills, and build the confidence needed to perform well in coding rounds and technical interviews.
1. What is Microsoft technical interview process?
Ans:
Microsoft technical interview process consists of multiple rounds designed to evaluate problem-solving ability, coding skills, and system design understanding of candidates effectively. It typically includes online assessments, technical interviews, and behavioral discussions that focus on both technical knowledge and communication clarity. Interviewers assess logical thinking, coding efficiency, and the ability to explain solutions in a structured and understandable manner. The process also evaluates adaptability and how effectively candidates handle follow-up questions and problem variations. Understanding the interview process helps in preparing strategically and improving overall performance during each stage.
2. What are stages in Microsoft interview process?
Ans:
- Online assessment stage evaluates coding ability through algorithm-based problems that test understanding of data structures, logical thinking, and efficiency of solutions under time constraints. This round often acts as the first technical filter for candidates. Strong speed and accuracy are important.
- Technical interview rounds focus on coding, problem-solving, and system design where candidates are expected to explain approaches clearly and optimize solutions effectively. Interviewers also ask follow-up questions to test depth of understanding. Clear communication matters greatly.
- Behavioral interview rounds assess communication skills, teamwork, adaptability, and alignment with company values through structured questions and real-world scenarios. These rounds help evaluate workplace readiness beyond technical skills. Honest examples create strong impact.
- Final evaluation stage involves overall assessment of technical and behavioral performance to determine suitability for the role and organizational fit. Consistency across rounds improves final selection chances significantly. Balanced preparation is valuable.
3. What is importance of data structures in interviews?
Ans:
Data structures are fundamental components used to organize and manage data efficiently for solving computational problems effectively. They help in optimizing solutions by improving time and space complexity in coding tasks. Understanding data structures allows efficient handling of operations such as searching, sorting, and data manipulation. They are widely used in technical interviews to evaluate problem-solving ability and coding skills. Strong knowledge of data structures is essential for performing well in Microsoft technical interviews.
4. What are commonly used data structures?
Ans:
- Arrays are used for storing elements in contiguous memory locations and are widely applied in problems involving indexing and iteration. They provide fast random access using indexes. Arrays are common in coding rounds.
- Linked lists provide dynamic memory allocation and efficient insertion or deletion operations compared to arrays in certain scenarios. They are useful when frequent structural changes occur. Pointer understanding is important here.
- Stacks and queues are used for handling problems involving order-based processing such as recursion, scheduling, and traversal operations. These structures follow specific insertion and removal rules. Many interview problems use them.
- Trees and graphs are used for hierarchical and network-based problems, enabling efficient representation and traversal of complex data relationships. They appear in advanced technical rounds frequently. Strong concepts improve performance.
5. What is algorithm?
Ans:
An algorithm is a step-by-step procedure designed to solve a problem or perform a specific task efficiently and accurately. It provides a clear sequence of instructions that guide the execution of operations in a logical manner. Algorithms are evaluated based on correctness, efficiency, and scalability in different problem scenarios. They play a crucial role in software development and optimization of solutions. Understanding algorithms is essential for solving coding problems in technical interviews.
6. What are types of algorithms?
Ans:
- Sorting algorithms such as quick sort and merge sort are used to arrange data in a specific order efficiently. Sorted data improves later searching and processing tasks. These algorithms are frequently discussed in interviews.
- Searching algorithms like binary search help in locating elements quickly within structured datasets. Efficient searching saves time for large inputs significantly. Binary search is especially important.
- Dynamic programming algorithms solve problems by breaking them into smaller subproblems and storing results for optimization. This avoids repeated calculations and improves performance. It is common in advanced rounds.
- Greedy algorithms make locally optimal choices at each step to find globally optimal solutions in certain problems. They are simpler than DP for suitable cases. Choosing the right approach is important.
7. What is time complexity?
Ans:
Time complexity is a measure used to evaluate the efficiency of an algorithm based on how execution time grows with input size. It helps in comparing different solutions and selecting the most efficient approach for a problem. Understanding time complexity ensures that solutions are scalable and perform well for large inputs. Efficient algorithms reduce computation time and improve performance of applications. Knowledge of time complexity is essential for writing optimized code in technical interviews.
8. What are common time complexities?
Ans:
- Constant time complexity O(1) represents operations that execute in the same time regardless of input size. Examples include direct index access in arrays. This is highly efficient.
- Linear time complexity O(n) represents operations that grow proportionally with input size. Single loops over arrays often fall in this category. It is common in coding solutions.
- Logarithmic time complexity O(log n) represents efficient algorithms such as binary search that reduce problem size iteratively. Growth remains slow even for large inputs. This is desirable performance.
- Quadratic time complexity O(n²) represents nested iterations and is less efficient for large inputs. Brute-force pair comparisons often use this pattern. Optimization is usually preferred.
9. What is space complexity?
Ans:
Space complexity refers to the amount of memory required by an algorithm during its execution. It helps in evaluating efficiency in terms of memory usage and optimization. Balancing time and space complexity is important for achieving optimal performance. Efficient memory usage is crucial for handling large-scale data problems. Understanding space complexity is essential for writing efficient programs.
10. What are ways to optimize space complexity?
Ans:
- Using in-place algorithms reduces additional memory usage and improves efficiency in solving problems effectively. Existing data structures are reused smartly. This is common in array problems.
- Avoiding unnecessary data structures helps minimize memory consumption during execution. Extra arrays or lists should be used only when required. Cleaner logic often saves memory.
- Reusing variables and optimizing storage improves memory management and performance. Temporary variables should be limited when possible. Small improvements matter in large systems.
- Analyzing trade-offs between time and space helps in selecting optimal solutions. Sometimes faster code needs more memory and vice versa. Balanced decisions are important.
11. What is recursion?
Ans:
Recursion is a programming technique where a function calls itself to solve smaller instances of a problem. It helps in breaking complex problems into simpler subproblems for easier implementation. Recursion is commonly used in problems involving trees, graphs, and backtracking. Proper base conditions are required to prevent infinite loops and ensure correct execution. Understanding recursion is important for solving advanced coding problems in interviews.
12. What is the difference between recursion and iteration?
Ans:
| Criteria | Recursion | Iteration |
|---|---|---|
| Method | Function calls itself repeatedly. | Uses loops like for or while. |
| Memory | Uses stack memory for calls. | Usually uses less memory. |
| Best Use | Trees, backtracking, divide-conquer. | Simple repeated operations. |
| Speed | Can be slower due to call overhead. | Often faster in simple cases. |
13. What is dynamic programming?
Ans:
Dynamic programming is an optimization technique used to solve problems by breaking them into overlapping subproblems and storing results. It improves efficiency by avoiding repeated calculations and reducing time complexity. This approach is widely used in problems such as shortest path, knapsack, and sequence alignment. Dynamic programming helps in solving complex problems efficiently. Understanding dynamic programming is essential for advanced technical interviews.
14. What are types of dynamic programming?
Ans:
- Top-down approach uses recursion with memoization to store results of subproblems for reuse. It is intuitive for recursive thinkers. Cached results improve speed significantly.
- Bottom-up approach builds solutions iteratively from smaller subproblems to larger ones efficiently. It often avoids recursion stack overhead. This is widely preferred in interviews.
- Tabulation technique uses arrays to store intermediate results and optimize performance. Tables make transitions easy to visualize clearly. It is useful for learning DP.
- Optimization problems benefit from dynamic programming by reducing redundant computations significantly. Many difficult interview questions rely on this pattern. Practice is essential.
15. What is greedy algorithm?
Ans:
Greedy algorithm is an approach that makes the best possible choice at each step to find an optimal solution. It focuses on local optimization with the hope of achieving a global optimum. Greedy algorithms are used in problems such as scheduling, minimum spanning tree, and Huffman coding. They are simple and efficient for certain types of problems. Understanding greedy algorithms is important for solving optimization problems in interviews.
16. What are examples of greedy algorithms?
Ans:
- Activity selection problem selects maximum number of non-overlapping activities efficiently. Earliest finishing choices help maximize total selections. This is a classic greedy example.
- Huffman coding is used for data compression by assigning variable-length codes. Frequent characters receive shorter codes for efficiency. It is widely known in theory.
- Kruskal’s algorithm finds minimum spanning tree in a graph effectively. It adds smallest safe edges step by step. Sorting edges is important here.
- Dijkstra’s algorithm calculates shortest path in weighted graphs with non-negative edges. Greedy nearest-node expansion drives the logic. It is common in interviews.
17. What is sorting?
Ans:
Sorting is the process of arranging data in a specific order such as ascending or descending. It helps in improving efficiency of searching and data processing operations. Sorting algorithms are widely used in various applications such as databases and analytics. Different sorting techniques have different time and space complexities. Understanding sorting is essential for solving many coding problems in interviews.
18. Write a program to perform Binary Search.
Ans:
This program searches an element in a sorted array using Binary Search.
- #include <stdio.h>
- int main() {
- int arr[5]={2,4,6,8,10};
- int key=8, low=0, high=4, mid;
- while(low<=high){
- mid=(low+high)/2;
- if(arr[mid]==key){
- printf(“Found”);
- break;
- }
- else if(key>arr[mid]) low=mid+1;
- else high=mid-1;
- }
- return 0;
- }
In this example, the program searches value 8 successfully.
19. What is searching?
Ans:
Searching is the process of finding a specific element within a dataset efficiently. It is essential for retrieving data quickly in various applications. Different searching techniques are used based on data structure and organization. Efficient searching improves performance and reduces computation time. Understanding searching techniques is important for coding interviews.
20. What are types of searching algorithms?
Ans:
- Linear search scans each element sequentially and is simple but less efficient for large datasets. It works even on unsorted data. This method is easy to implement.
- Binary search divides sorted data into halves to locate elements efficiently with logarithmic complexity. It is much faster than linear search for large sorted arrays. Sorted order is required.
- Hash-based searching uses hash tables for constant time lookup in many scenarios. This is common in dictionaries and caches. Hash quality affects performance.
- Tree-based searching uses binary search trees and balanced trees for efficient data retrieval. Ordered structures also support range queries effectively. Trees are useful in many systems.
21. What is hashing?
Ans:
Hashing is a technique used to map data to a fixed-size value using a hash function for efficient storage and retrieval operations. It allows quick access to data by converting keys into indices in a hash table structure. Hashing is widely used in applications such as databases, caching systems, and password storage mechanisms. Efficient hashing reduces search time complexity and improves performance significantly. Understanding hashing is essential for solving optimization problems in technical interviews.
22. What are collision handling techniques in hashing?
Ans:
- Chaining technique handles collisions by storing multiple elements at the same index using linked lists or dynamic structures, ensuring efficient data organization even when collisions occur frequently. Each bucket can hold multiple entries safely. This method is simple and widely used.
- Open addressing resolves collisions by finding alternative empty slots within the hash table using probing methods such as linear probing, quadratic probing, or double hashing. Elements remain inside the table itself. This saves pointer overhead in some cases.
- Rehashing technique involves resizing the hash table and recalculating hash values when the load factor exceeds a certain threshold, improving efficiency and reducing collisions. Larger tables reduce clustering issues significantly. Performance becomes more stable.
- Proper hash function design minimizes collisions and ensures uniform distribution of data across the table for better performance. Balanced distribution prevents overloaded buckets naturally. Good design is highly important.
23. What is stack?
Ans:
A stack is a linear data structure that follows the Last In First Out (LIFO) principle for storing and accessing elements. It allows insertion and deletion operations only at one end, known as the top of the stack. Stacks are commonly used in applications such as expression evaluation, recursion, and backtracking algorithms. They provide efficient implementation for reversing data and managing function calls. Understanding stacks is essential for solving problems involving order-based operations in interviews.
24. What are applications of stack?
Ans:
- Expression evaluation uses stacks to convert and evaluate infix, postfix, and prefix expressions efficiently in compiler design and mathematical computations. Operators and operands are processed in controlled order. This is a classic stack use case.
- Function call management utilizes stacks to maintain execution context during recursion and nested function calls in programming languages. Return addresses and local variables are stored temporarily. This enables proper execution flow.
- Backtracking algorithms rely on stacks to store intermediate states while exploring possible solutions in problems like maze solving and permutations. Previous choices can be restored easily. This supports systematic exploration.
- Undo and redo operations in applications use stacks to track changes and restore previous states efficiently. Editors commonly use this mechanism daily. It improves user convenience greatly.
25. What is queue?
Ans:
A queue is a linear data structure that follows the First In First Out (FIFO) principle for processing elements sequentially. It allows insertion at the rear and deletion from the front, ensuring ordered processing of data. Queues are widely used in scheduling, buffering, and resource management systems. They help in handling tasks in a systematic and efficient manner. Understanding queues is essential for solving problems involving sequential processing in interviews.
26. What are types of queues?
Ans:
- Simple queue processes elements in FIFO order and is used in scheduling tasks and handling requests sequentially. It is the basic queue model used in many systems. Order remains predictable.
- Circular queue improves efficiency by reusing vacant spaces created after deletions, avoiding memory wastage. Rear wraps around to the front position. This uses array space better.
- Priority queue processes elements based on priority rather than order, widely used in scheduling and graph algorithms. Important tasks are handled first. Heaps often implement this structure.
- Double-ended queue allows insertion and deletion from both ends, providing flexibility in data handling operations. It supports stack and queue style behavior. Deques are highly versatile.
27. What is linked list?
Ans:
A linked list is a linear data structure where elements are stored in nodes connected through pointers. Each node contains data and a reference to the next node in the sequence. Linked lists allow dynamic memory allocation and efficient insertion or deletion operations. They are widely used in applications where frequent modifications are required. Understanding linked lists is important for solving memory management problems in interviews.
28. What is the difference between stack and queue?
Ans:
| Criteria | Stack | Queue |
|---|---|---|
| Principle | Follows Last In First Out (LIFO). | Follows First In First Out (FIFO). |
| Insertion | Insertion happens at top. | Insertion happens at rear. |
| Deletion | Deletion happens from top. | Deletion happens from front. |
| Applications | Recursion, undo, expression evaluation. | Scheduling, buffering, BFS traversal. |
29. What is tree data structure?
Ans:
A tree is a hierarchical data structure consisting of nodes connected through edges, representing parent-child relationships. It is used to organize data in a structured and efficient manner for searching and traversal operations. Trees are widely used in databases, file systems, and hierarchical data representation. They support efficient operations such as insertion, deletion, and traversal. Understanding trees is essential for solving complex data structure problems in interviews.
30. What are types of trees?
Ans:
- Binary tree consists of nodes where each node has at most two children, commonly used in hierarchical data representation. Left and right child references create simple structures. It is foundational for tree concepts.
- Binary search tree maintains sorted order, enabling efficient searching, insertion, and deletion operations. Left values stay smaller and right values larger. This supports faster lookups.
- AVL tree is a self-balancing tree that ensures height balance for optimized performance. Rotations maintain balanced height automatically. This avoids worst-case skewed trees.
- Heap is a specialized tree structure used in priority queues and efficient sorting algorithms. Root contains highest or lowest priority value. Heaps support fast extraction.
31. What is graph?
Ans:
A graph is a data structure consisting of vertices and edges used to represent relationships between entities. It is widely used in networking, social media, and route optimization problems. Graphs can be directed or undirected based on the nature of connections. They support traversal techniques such as BFS and DFS for exploring nodes. Understanding graphs is essential for solving complex connectivity problems in interviews.
32. What are graph traversal techniques?
Ans:
- Breadth First Search explores nodes level by level using a queue, ensuring shortest path in unweighted graphs. Nearby nodes are processed first logically. BFS is common in interview questions.
- Depth First Search explores nodes deeply using recursion or stack, useful for pathfinding and cycle detection. It follows one branch before backtracking. DFS is powerful for structural analysis.
- Topological sorting orders vertices in directed acyclic graphs for dependency resolution. Tasks are arranged in valid execution order. This is useful in scheduling systems.
- Shortest path algorithms like Dijkstra and Bellman-Ford help in finding optimal routes in weighted graphs. These methods are widely used in navigation and networking. Path optimization is important.
33. What is binary search?
Ans:
Binary search is an efficient searching algorithm used to find elements in a sorted dataset by repeatedly dividing the search space. It reduces the number of comparisons significantly compared to linear search. Binary search operates with logarithmic time complexity, making it highly efficient for large datasets. It is widely used in applications requiring fast lookup operations. Understanding binary search is essential for solving search-related problems in interviews.
34. What are advantages of binary search?
Ans:
- Binary search significantly reduces search time by dividing the dataset into halves repeatedly, improving efficiency. Each step removes half the remaining range. This gives excellent performance.
- It is highly efficient for large datasets due to its logarithmic time complexity. Growth in input size has limited effect on search steps. This is ideal for large arrays.
- Binary search ensures faster lookup compared to linear search in sorted arrays. Sequential scanning becomes unnecessary. Sorted data gains major advantage.
- It is widely used in real-world applications such as databases and search engines. Fast retrieval is valuable in production systems. Practical relevance is high.
35. What is sorting complexity?
Ans:
Sorting complexity refers to the time and space requirements needed by sorting algorithms to arrange data. It helps in selecting appropriate algorithms based on problem requirements and constraints. Different sorting algorithms have varying complexities depending on input size and structure. Understanding sorting complexity improves efficiency in solving problems. It is essential for optimizing performance in technical interviews.
36. Write a program to implement Queue using Array.
Ans:
This program inserts elements into queue and displays them.
- #include <stdio.h>
- int main() {
- int q[5], front=0, rear=-1;
- q[++rear]=10;
- q[++rear]=20;
- q[++rear]=30;
- for(int i=front;i<=rear;i++)
- printf(“%d “, q[i]);
- return 0;
- }
In this example, output will be 10 20 30.
37. What is recursion vs iteration?
Ans:
Recursion involves a function calling itself to solve smaller instances of a problem, while iteration uses loops for repeated execution. Both approaches aim to solve problems efficiently but differ in implementation and memory usage. Recursion provides a simpler and more readable solution for certain problems. Iteration is generally more memory-efficient and avoids stack overflow issues. Understanding both approaches is important for choosing optimal solutions in interviews.
38. What are differences between recursion and iteration?
Ans:
- Recursion uses function calls and stack memory, while iteration uses loops and is generally more memory efficient. Recursive depth can increase memory usage significantly. Iteration is often safer for large inputs.
- Recursive solutions are often simpler and easier to understand for complex problems compared to iterative solutions. Tree and divide-and-conquer problems fit recursion naturally. Readability can improve greatly.
- Iterative approaches avoid overhead of function calls, making them faster in some cases. Repeated stack frame creation is not required. Performance may improve noticeably.
- Recursion is preferred for problems involving tree traversal and divide-and-conquer strategies. Natural hierarchical breakdown suits recursive logic well. Many classic algorithms use it.
39. What is backtracking?
Ans:
Backtracking is an algorithmic technique used to find solutions by exploring all possible options and discarding invalid ones. It is commonly used in problems such as permutations, combinations, and constraint satisfaction. Backtracking involves recursion and systematic exploration of solution space. It ensures that all possibilities are considered for finding correct solutions. Understanding backtracking is important for solving complex algorithmic problems in interviews.
40. What are applications of backtracking?
Ans:
- N-Queens problem uses backtracking to place queens on a chessboard without conflicts effectively. Invalid placements are removed early. This reduces unnecessary search.
- Sudoku solving applies backtracking to fill grids while satisfying constraints efficiently. Each placement is checked before continuing deeper. Logical pruning improves speed.
- Permutation and combination problems use backtracking to generate all possible arrangements. Choices are built step by step recursively. This is a common interview pattern.
- Maze solving algorithms use backtracking to find paths by exploring all possible routes systematically. Dead ends are abandoned and previous states restored. This demonstrates search strategy clearly.

Enroll in Java Certification Course and UPGRADE Your Skills
Weekday / Weekend BatchesSee Batch Details41. What is divide and conquer?
Ans:
Divide and conquer is an algorithmic technique that breaks a problem into smaller subproblems, solves each independently, and combines results for a final solution. It helps in simplifying complex problems and improving efficiency through recursive decomposition. This approach is widely used in sorting, searching, and optimization algorithms. Divide and conquer improves performance by reducing time complexity significantly. Understanding this technique is essential for solving advanced problems in technical interviews.
42. What are examples of divide and conquer algorithms?
Ans:
- Merge sort divides the array into smaller subarrays, sorts them individually, and merges them to produce a sorted output efficiently. This method guarantees stable sorting with predictable performance. It is a classic divide and conquer example.
- Quick sort partitions the dataset around a pivot element and recursively sorts subarrays for optimized performance. Good pivot selection improves average speed significantly. It is widely used in practice.
- Binary search repeatedly divides the search space into halves to locate elements efficiently in sorted data. Each step removes half of the remaining range quickly. This gives logarithmic complexity.
- Strassen’s algorithm uses divide and conquer to perform matrix multiplication more efficiently than traditional methods. It reduces multiplication operations compared with naive methods. This is useful in advanced computing.
43. What is bit manipulation?
Ans:
Bit manipulation involves performing operations directly on binary representations of numbers using bitwise operators. It is used to optimize computations and reduce time complexity in certain problems. Bitwise operations include AND, OR, XOR, and shift operations. These techniques are widely used in low-level programming and performance optimization. Understanding bit manipulation is important for solving efficient coding problems in interviews.
44. What are applications of bit manipulation?
Ans:
- Bit masking is used to store and manipulate multiple boolean values efficiently within a single integer. This saves memory and enables quick checks clearly. It is common in optimization problems.
- Checking parity and counting set bits helps in solving mathematical and optimization problems effectively. Many interview questions use these operations frequently. Bit tricks improve speed.
- Swapping values without using extra variables can be achieved using XOR operations. This demonstrates clever binary manipulation logic. It is a popular concept question.
- Efficient subset generation and combinatorial problems can be solved using bit manipulation techniques. Binary states represent inclusion and exclusion naturally. This is powerful in recursion alternatives.
45. Write a program for string reversal.
Ans:
This example reverses a string using two pointer technique.
- #include <stdio.h>
- #include <string.h>
- int main() {
- char str[] = “hello”;
- int i=0, j=strlen(str)-1;
- char temp;
- while(i<j) {
- temp=str[i];
- str[i]=str[j];
- str[j]=temp;
- i++; j–;
- }
- printf(“%s”, str);
- return 0;
- }
In this example, the string “hello” becomes “olleh”.
46. What are common string algorithms?
Ans:
- KMP algorithm efficiently searches for patterns within strings by avoiding redundant comparisons. Prefix information prevents restarting from the beginning repeatedly. This improves search performance.
- Rabin-Karp algorithm uses hashing to find patterns in strings efficiently. Rolling hash makes repeated comparisons faster significantly. It is useful for multiple pattern checks.
- Longest common subsequence algorithm identifies common patterns between strings using dynamic programming. It is useful in version comparison and bioinformatics tasks. DP helps manage subproblems.
- String reversal and palindrome checking are basic operations used in many problem-solving scenarios. These topics are common in beginner interviews frequently. Strong basics are valuable.
47. What is heap data structure?
Ans:
Heap is a specialized tree-based data structure that satisfies the heap property for efficient retrieval of minimum or maximum elements. It is commonly implemented as a binary tree and stored using arrays. Heaps are widely used in priority queues and scheduling algorithms. They provide efficient insertion and deletion operations. Understanding heaps is important for solving optimization problems in interviews.
48. What are types of heaps?
Ans:
- Min heap ensures that the smallest element is always at the root, enabling efficient access to minimum values. This is useful for priority scheduling and top-k problems. Retrieval becomes fast.
- Max heap ensures that the largest element is always at the root for efficient retrieval of maximum values. It is useful when highest priority items are needed first. Root access is constant time.
- Binary heap is a complete binary tree used for implementing priority queues effectively. Array representation makes storage efficient. It is the most common heap type.
- Fibonacci heap provides improved performance for certain operations like decrease key and merging heaps. It appears in advanced algorithm discussions. Specialized use cases benefit from it.
49. What is priority queue?
Ans:
Priority queue is a data structure where elements are processed based on priority rather than insertion order. It is commonly implemented using heaps for efficient operations. Priority queues are used in scheduling, pathfinding, and resource allocation systems. They allow efficient insertion and deletion of elements. Understanding priority queues is essential for solving advanced algorithmic problems.
50. What are applications of priority queue?
Ans:
- Dijkstra’s algorithm uses priority queues to determine shortest paths in weighted graphs efficiently. Minimum distance nodes are selected quickly each step. This improves graph performance.
- CPU scheduling systems use priority queues to manage tasks based on priority levels. Important tasks can run earlier when needed. Scheduling becomes organized.
- Event-driven simulations use priority queues to process events in order of occurrence. Earliest events are handled first logically. This is common in simulation systems.
- Huffman coding uses priority queues to build optimal prefix codes for data compression. Lowest frequency nodes are combined repeatedly. This creates efficient encodings.
51. What is greedy vs dynamic programming?
Ans:
Greedy algorithms make locally optimal choices at each step, while dynamic programming solves problems by considering all possible subproblems. Greedy approach is simpler and faster but may not always produce optimal results. Dynamic programming ensures optimal solutions by storing intermediate results. Choosing between them depends on problem constraints and requirements. Understanding both approaches is essential for solving optimization problems effectively.
52. What is the difference between greedy and dynamic programming?
Ans:
| Criteria | Greedy | Dynamic Programming |
|---|---|---|
| Approach | Makes best local choice at each step. | Solves all subproblems systematically. |
| Memory | Usually low memory usage. | Uses table or memoization storage. |
| Optimal Result | May not always give optimal answer. | Usually gives optimal solution. |
| Examples | Activity selection, Huffman coding. | Knapsack, Fibonacci, LCS. |
53. What is sliding window technique?
Ans:
Sliding window technique is used to solve problems involving subarrays or substrings efficiently by maintaining a dynamic window of elements. It reduces time complexity compared to brute-force approaches. This technique is widely used in problems involving sums, maximum values, and pattern matching. Sliding window improves performance by avoiding redundant computations. Understanding this technique is essential for solving array and string problems in interviews.
54. What are applications of sliding window?
Ans:
- Finding maximum sum subarray of fixed size can be solved efficiently using sliding window technique. Old values leave while new values enter smoothly. This avoids recalculating sums.
- Longest substring without repeating characters is a common problem solved using dynamic window adjustment. Window size changes based on duplicates. This is popular in interviews.
- Counting valid subarrays based on constraints can be optimized using sliding window approach. Many brute-force problems become linear with this pattern. Efficiency improves greatly.
- Sliding window helps in reducing time complexity from quadratic to linear in many problems. Controlled movement of pointers saves repeated work naturally. It is highly valuable.
55. What is two pointer technique?
Ans:
Two pointer technique involves using two indices to traverse data structures efficiently for solving problems. It is widely used in sorted arrays and linked lists. This approach helps in reducing time complexity by avoiding nested loops. It is commonly used in problems such as pair finding and partitioning. Understanding two pointer technique is essential for efficient problem solving.
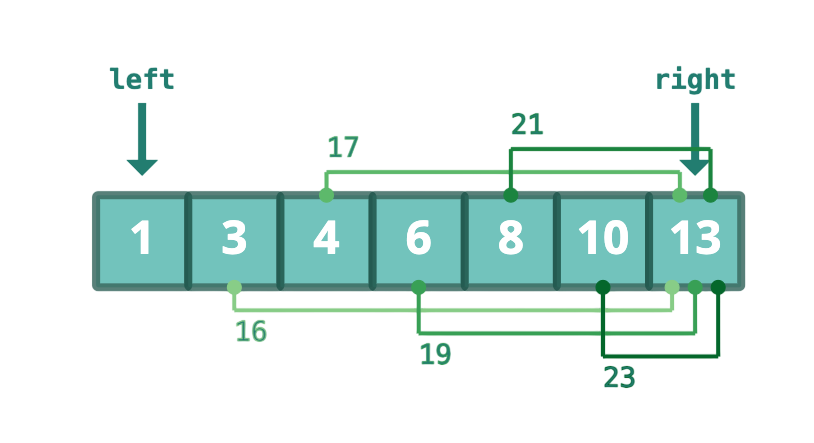
56. What are applications of two pointer technique?
Ans:
- Finding pairs with specific sum in sorted arrays can be efficiently solved using two pointers. Movement depends on comparison with target values. This gives linear time.
- Removing duplicates from sorted arrays can be achieved using two pointer approach effectively. One pointer tracks position while another scans forward. In-place updates become simple.
- Partitioning arrays for problems like quick sort uses two pointer technique. Opposite-side scanning helps rearrange elements correctly. This is widely used.
- Merging sorted arrays can be done efficiently using two pointers. Both lists are scanned in order without repeated searching. This saves time significantly.
57. What is recursion tree?
Ans:
Recursion tree is a visualization tool used to represent recursive function calls and their execution flow. It helps in analyzing time complexity of recursive algorithms. Each node represents a function call and its subproblems. Recursion trees are useful for understanding divide-and-conquer algorithms. Understanding recursion trees is important for analyzing algorithm efficiency.
58. What are advantages of recursion tree?
Ans:
- Recursion tree helps visualize execution of recursive algorithms clearly and systematically. Complex call structures become easier to understand. Visual learning improves clarity.
- It aids in analyzing time complexity and identifying overlapping subproblems effectively. Repeated branches become visible quickly. This helps optimization decisions.
- It simplifies understanding of complex recursive logic and function calls. Step-by-step structure reduces confusion significantly. Students learn recursion faster.
- Recursion tree assists in converting recursive solutions into iterative ones. Understanding flow helps redesign logic clearly. This supports advanced problem solving.
59. What is memoization?
Ans:
Memoization is an optimization technique used to store results of expensive function calls and reuse them. It helps in reducing redundant computations in recursive algorithms. Memoization improves performance significantly by avoiding repeated calculations. It is widely used in dynamic programming problems. Understanding memoization is essential for optimizing recursive solutions.
60. What are benefits of memoization?
Ans:
- Memoization reduces time complexity by storing intermediate results and avoiding repeated calculations. Previously solved states are reused instantly. This can transform exponential solutions.
- It improves efficiency of recursive algorithms significantly. Slow repeated branching is minimized greatly. Performance becomes practical.
- Memoization is easy to implement using arrays or hash maps. Storage choice depends on state type clearly. Simplicity is an advantage.
- It enhances performance in problems with overlapping subproblems. Fibonacci and path counting are common examples. DP concepts become clearer.

Learn Java Training with Advanced Concepts By Industry Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
61. What is tabulation in dynamic programming?
Ans:
Tabulation is a bottom-up dynamic programming approach where solutions are built iteratively using a table to store intermediate results efficiently. It avoids recursion by solving smaller subproblems first and combining them to solve larger problems. This approach improves performance by eliminating function call overhead and reducing stack usage. Tabulation ensures better control over computation order and memory utilization. Understanding tabulation is essential for optimizing dynamic programming solutions in interviews.
62. What are advantages of tabulation?
Ans:
- Tabulation eliminates recursion overhead and stack limitations, making it more efficient for large-scale problems involving multiple subproblems. Iterative solutions avoid deep recursion risks. This improves reliability.
- It provides better control over memory usage by storing results in a structured table format for reuse. Developers can optimize dimensions carefully. Memory planning becomes easier.
- Tabulation ensures faster execution compared to recursive approaches due to iterative computation. Function call costs are removed significantly. Runtime often improves.
- It simplifies debugging and implementation by clearly defining the order of computation. Each state is filled step by step logically. This aids learning.
63. What is system design?
Ans:
System design refers to the process of defining architecture, components, and interactions within a software system to meet specific requirements. It involves designing scalable, reliable, and efficient systems capable of handling large workloads. System design focuses on aspects such as databases, APIs, and infrastructure. It is an important part of technical interviews for evaluating architectural thinking. Understanding system design is essential for building real-world applications.
64. What are key components of system design?
Ans:
- Load balancers distribute incoming traffic across multiple servers to ensure efficient handling of requests and prevent overload. They improve availability and response time clearly. Traffic becomes balanced.
- Databases store and manage data efficiently while ensuring consistency, availability, and scalability. Correct database choice affects architecture greatly. Storage is foundational.
- Caching systems improve performance by storing frequently accessed data for faster retrieval. This reduces repeated database load significantly. User experience improves.
- APIs enable communication between different components and services within a system. Standard interfaces simplify integration naturally. Services cooperate effectively.
65. What is scalability?
Ans:
Scalability refers to the ability of a system to handle increasing workload without affecting performance or reliability. It ensures that systems can grow and manage higher user demand effectively. Scalable systems use techniques such as load balancing and distributed computing. Scalability is essential for modern applications handling large volumes of data. Understanding scalability is crucial for system design interviews.
66. What are types of scalability?
Ans:
- Vertical scalability increases resources such as CPU and memory in a single system to handle more load efficiently. This is simple but has hardware limits. It is common initially.
- Horizontal scalability adds multiple machines to distribute workload and improve system performance. Additional nodes support larger traffic smoothly. This is common in cloud systems.
- Elastic scalability dynamically adjusts resources based on demand for optimal utilization. Systems scale up or down automatically significantly. Costs become efficient.
- Distributed systems enable scalability by spreading tasks across multiple nodes. Workloads are shared effectively across infrastructure. Reliability can improve too.
67. What is load balancing?
Ans:
Load balancing is a technique used to distribute network traffic across multiple servers to ensure optimal performance and availability. It prevents any single server from becoming overloaded. Load balancers improve reliability by redirecting traffic to healthy servers. They enhance system performance and reduce response time. Understanding load balancing is essential for designing scalable systems.
68. What are types of load balancing?
Ans:
- Round robin distributes requests sequentially across servers to ensure balanced workload. It is simple and easy to implement clearly. Small systems often use it.
- Least connections method assigns requests to servers with fewer active connections. This helps when request duration varies significantly. Load becomes smarter.
- IP hash uses client IP addresses to determine server allocation for consistency. Same users may reach same server repeatedly. Session stability improves.
- Dynamic load balancing adjusts distribution based on server performance and load. Real-time metrics guide traffic decisions naturally. Efficiency improves greatly.
69. What is database normalization?
Ans:
Database normalization is the process of organizing data to reduce redundancy and improve data integrity. It involves dividing large tables into smaller related tables. Normalization ensures efficient data storage and retrieval. It improves consistency and reduces anomalies in database operations. Understanding normalization is essential for database design in interviews.
70. What are normal forms in databases?
Ans:
- First normal form ensures atomicity by eliminating repeating groups and storing data in structured format. Each field holds single values clearly. Basic table design improves.
- Second normal form removes partial dependencies and ensures full functional dependency on primary key. Composite key issues are resolved significantly. Redundancy reduces.
- Third normal form eliminates transitive dependencies to improve data integrity. Non-key attributes depend only on keys properly. Consistency becomes stronger.
- Boyce-Codd normal form further refines normalization to handle advanced dependency cases. It is stricter than third normal form. Complex schemas benefit from it.
71. What is process vs thread?
Ans:
A process is an independent program in execution with its own memory space, while a thread is a lightweight unit of execution within a process sharing the same memory. Processes are isolated from each other, ensuring stability and security, whereas threads communicate easily within the same process. Thread creation and context switching are faster compared to processes. Processes are heavier and consume more resources than threads. Understanding the difference is essential for system design and performance optimization in interviews.
72. What is the difference between process and thread?
Ans:
| Criteria | Process | Thread |
|---|---|---|
| Memory | Has separate memory space. | Shares memory within process. |
| Execution | Independent running program. | Lightweight execution unit. |
| Speed | Creation is slower. | Creation is faster. |
| Communication | More complex communication. | Easy communication through shared memory. |
73. What is memory management?
Ans:
Memory management is the process of controlling and allocating memory resources efficiently in a computer system. It ensures optimal use of available memory while preventing conflicts between processes. Memory management techniques include paging, segmentation, and virtual memory. Efficient memory management improves system performance and stability. Understanding memory management is crucial for operating system concepts in interviews.
74. What are memory management techniques?
Ans:
- Paging divides memory into fixed-size blocks, enabling efficient allocation and reducing fragmentation. Fixed pages simplify memory tracking and management clearly. This method is widely used in operating systems.
- Segmentation divides memory into variable-sized segments based on logical divisions of programs. It reflects natural program structure such as code and data sections. This improves organization.
- Virtual memory allows execution of large programs using disk storage when physical memory is insufficient. It creates an illusion of larger available memory significantly. This supports multitasking.
- Swapping moves processes between memory and disk to manage memory efficiently. Temporary movement frees RAM for active tasks naturally. It helps resource utilization.
75. What is virtual memory?
Ans:
Virtual memory is a technique that allows execution of programs larger than physical memory by using disk space as an extension. It provides an abstraction of large memory to processes. Virtual memory improves system efficiency and multitasking capability. It uses paging and segmentation for implementation. Understanding virtual memory is essential for operating system concepts in interviews.
76. What are advantages of virtual memory?
Ans:
- Virtual memory allows execution of large programs without requiring equivalent physical memory resources. Applications can run even with limited RAM available. This increases flexibility.
- It improves system efficiency by enabling multiple processes to run simultaneously. More programs stay active through smart memory sharing significantly. This supports multitasking.
- Virtual memory provides better memory utilization and reduces wastage. Unused memory areas can be managed more effectively clearly. Efficiency increases overall performance.
- It enhances system performance by isolating processes and managing memory effectively. Process separation improves stability and reliability naturally. Protection is also improved.
77. What is deadlock prevention?
Ans:
Deadlock prevention refers to techniques used to ensure that a system never enters a deadlock state. It involves breaking at least one necessary condition required for deadlock. Prevention ensures smooth execution of processes without resource conflicts. It improves system reliability and performance. Understanding deadlock prevention is essential for operating system interviews.
78. What are deadlock conditions?
Ans:
- Mutual exclusion ensures that resources are used by only one process at a time, leading to potential deadlocks. Exclusive resources cannot be shared simultaneously clearly. This creates waiting situations.
- Hold and wait condition occurs when processes hold resources while waiting for additional ones. Partial allocation increases chances of blocking significantly. This is a major deadlock cause.
- No preemption prevents resources from being forcibly taken from processes. Resources remain occupied until voluntarily released naturally. This can prolong waiting chains.
- Circular wait occurs when processes form a cycle of waiting for each other’s resources. Each process waits for the next one in sequence. This creates complete deadlock.
79. What is scheduling?
Ans:
Scheduling is the process of selecting and allocating CPU time to processes based on specific algorithms. It ensures efficient utilization of CPU resources. Scheduling algorithms determine execution order of processes. It improves system performance and responsiveness. Understanding scheduling is important for operating system concepts.
80. What are scheduling algorithms?
Ans:
- First Come First Serve schedules processes in order of arrival, ensuring fairness but may cause delays. Long jobs can block short tasks significantly. It is simple to implement.
- Shortest Job First selects processes with shortest execution time for improved efficiency. Average waiting time can reduce greatly in many cases. Accurate burst prediction is needed.
- Round Robin allocates time slices to processes for fair CPU sharing. Each task gets repeated chances to run clearly. This is common in time-sharing systems.
- Priority scheduling assigns priority levels to processes for execution order. Important tasks receive CPU earlier naturally. Starvation must be managed carefully.
81. What is DBMS?
Ans:
Database Management System is software used to store, manage, and retrieve data efficiently. It ensures data integrity, security, and consistency. DBMS supports structured data storage and query processing. It is widely used in applications requiring data management. Understanding DBMS is essential for database-related interview questions.
82. What are advantages of DBMS?
Ans:
- DBMS ensures data consistency and integrity across applications. Centralized control reduces duplicate or conflicting records clearly. Reliable data supports business operations.
- It provides security mechanisms to protect sensitive data. Permissions and access control improve confidentiality significantly. Secure systems build trust.
- DBMS enables efficient data retrieval using query optimization techniques. Indexed search methods improve response speed effectively. Performance becomes better.
- It supports multi-user access and concurrency control. Many users can work simultaneously without corruption naturally. Collaboration becomes easier.
83. What is SQL?
Ans:
SQL is a structured query language used to interact with relational databases. It is used for querying, inserting, updating, and deleting data. SQL provides powerful tools for data manipulation and retrieval. It is widely used in database management systems. Understanding SQL is essential for technical interviews.
84. What are types of SQL commands?
Ans:
- DDL commands define database structure including tables and schemas. They are used for create, alter, and drop operations clearly. Structure management depends on them.
- DML commands manipulate data within tables efficiently. Insert, update, and delete operations belong to this category significantly. Data handling uses DML often.
- DCL commands control access and permissions for users. Grant and revoke commands improve database security effectively. Access management is important.
- TCL commands manage transactions and ensure data consistency. Commit and rollback maintain reliable operations naturally. Transaction safety depends on them.
85. What is NoSQL?
Ans:
NoSQL databases are non-relational databases designed for handling unstructured data efficiently. They provide flexibility and scalability for modern applications. NoSQL supports large-scale distributed systems. It is widely used in big data and real-time applications. Understanding NoSQL is important for modern system design interviews.
86. What are types of NoSQL databases?
Ans:
- Document-based databases store data in JSON-like formats for flexibility. Semi-structured records are easy to manage clearly. They suit modern applications.
- Key-value stores provide fast data access using unique keys. Simple lookup operations make them highly efficient significantly. Caching systems often use them.
- Column-family databases store data in columns for efficient queries. They are useful for analytical workloads and large datasets effectively. Scalability is strong.
- Graph databases represent relationships between data effectively. Connected data such as social networks benefits greatly. Relationship queries become easier.
87. What is cloud computing?
Ans:
Cloud computing provides computing resources such as storage and servers over the internet. It enables scalable and on-demand access to resources. Cloud platforms support modern application development. It reduces infrastructure costs and improves efficiency. Understanding cloud computing is essential for technical roles.
88. What are types of cloud services?
Ans:
- Infrastructure as a Service provides virtualized computing resources. Users manage operating systems and applications clearly. Hardware ownership is not required.
- Platform as a Service offers development and deployment environments. Developers focus on coding instead of infrastructure significantly. Productivity improves.
- Software as a Service delivers applications over the internet. Users access ready-made software through browsers effectively. Maintenance is handled by providers.
- Serverless computing allows execution without managing infrastructure. Developers deploy functions directly and scale automatically naturally. Operational burden decreases.
89. What is REST API?
Ans:
REST API is a web service that follows REST architecture principles for communication between systems. It uses HTTP methods such as GET, POST, PUT, and DELETE. REST APIs are stateless and scalable. They enable seamless integration between applications. Understanding REST APIs is essential for backend development roles.
90. What are HTTP methods?
Ans:
- GET retrieves data from a server without modifying resources. It is mainly used for read-only operations clearly. Safe requests commonly use GET.
- POST sends data to the server to create new resources. Form submissions and record creation use it significantly. It changes server state.
- PUT updates existing resources with new data. Full replacement or update operations are common effectively. APIs use it frequently.
- DELETE removes resources from the server. It is used when records must be erased naturally. Proper authorization is important.
91. What is API?
Ans:
API is a set of rules that allows communication between different software systems. It enables integration and data exchange between applications. APIs are widely used in web and mobile applications. They improve modularity and scalability. Understanding APIs is essential for software development.
92. What are types of APIs?
Ans:
- REST APIs use HTTP protocols for communication. They are lightweight and widely adopted clearly. Many web systems use REST.
- SOAP APIs use XML-based messaging for structured communication. Strong standards and contracts are common significantly. Enterprise systems often use SOAP.
- GraphQL APIs provide flexible data querying. Clients request only needed fields effectively. This reduces over-fetching.
- Internal APIs enable communication within systems. They connect services inside organizations naturally. Internal integration improves architecture.
93. What is version control?
Ans:
Version control is a system used to manage changes to code over time. It allows tracking and collaboration among developers. Version control systems maintain history of changes. They help in managing different versions of code. Understanding version control is essential for development workflows.
94. What are types of version control systems?
Ans:
- Centralized systems use a single repository for code management. All users connect to one central server clearly. Administration becomes easier.
- Distributed systems allow multiple repositories for collaboration. Every developer can keep a local full copy significantly. Reliability improves.
- Git is widely used distributed version control system. Branching and merging features are powerful effectively. It is popular worldwide.
- Version control improves collaboration and code management. Teams track changes and recover history naturally. Productivity increases greatly.
95. What is debugging?
Ans:
Debugging is the process of identifying and fixing errors in software programs. It ensures correct functionality of code. Debugging improves reliability and performance of applications. It is essential for maintaining code quality. Understanding debugging is important for software development.
96. Write a program to swap two numbers without third variable.
Ans:
This program swaps two numbers without using extra variable.
- #include <stdio.h>
- int main() {
- int a=5, b=10;
- a = a + b;
- b = a – b;
- a = a – b;
- printf(“%d %d”, a, b);
- return 0;
- }
In this example, output will be 10 5.
97. What is software testing?
Ans:
Software testing is the process of evaluating applications to ensure they meet requirements. It helps identify defects and improve quality. Testing ensures reliability and performance. It is essential for delivering error-free software. Understanding testing is important for development lifecycle.
98. What are types of testing?
Ans:
- Unit testing tests individual components of software. Small modules are verified separately clearly. Early defect detection becomes easier.
- Integration testing verifies interaction between modules. Combined components are checked for communication issues significantly. Interfaces are validated.
- System testing evaluates complete system functionality. Full application behavior is tested effectively. End-to-end quality is measured.
- Acceptance testing ensures requirements are met. Final users confirm readiness naturally. Approval happens at this stage.
99. What is DevOps?
Ans:
DevOps is a practice that combines development and operations to improve efficiency. It focuses on automation and continuous delivery. DevOps enhances collaboration between teams. It reduces development cycles and improves quality. Understanding DevOps is important for modern software development.
100. What are final tips for Microsoft interview success?
Ans:
- Strong understanding of data structures and algorithms ensures success in technical rounds. Core concepts help solve coding problems efficiently. Fundamentals are highly important.
- Consistent practice and problem-solving improve coding skills and efficiency. Daily effort builds speed and confidence significantly. Practice creates strong results.
- Clear communication and structured thinking enhance interview performance. Explaining logic well creates better interviewer impression effectively. Communication matters greatly.
- Confidence, discipline, and preparation are key factors for success. Calm mindset with planning improves outcomes naturally. Consistency leads to selection.




