
Last updated on 18th Apr 2026| 7370
TCS AI/ML Basic Interview Questions for Beginners is a beginner-friendly guide designed to help candidates prepare for entry-level roles at Tata Consultancy Services. It includes commonly asked questions on fundamental concepts such as machine learning basics, supervised and unsupervised learning, algorithms, data preprocessing, and simple AI concepts, along with clear explanations. This resource helps beginners build a strong foundation in AI and machine learning, understand interview expectations, and gain the confidence needed to perform well in technical interview rounds.
1. What is Artificial Intelligence?
Ans:
Artificial Intelligence is a branch of computer science focused on creating systems that perform tasks requiring human-like intelligence. These tasks may include learning from data, reasoning, decision-making, language understanding, and image recognition activities. AI helps organizations automate repetitive work and improve speed, accuracy, and business efficiency significantly. Many industries use AI in healthcare, banking, retail, manufacturing, and customer support operations. Basic AI understanding is highly valuable for beginner interview preparation.
2. What are the fundamental concepts of Artificial Intelligence?
Ans:
- Learning the definition, goals, and real-world applications of Artificial Intelligence creates a strong conceptual foundation for beginners. It helps understand how AI is used across industries. This clarity improves confidence during interviews.
- Studying common AI branches such as machine learning, deep learning, computer vision, and natural language processing improves awareness significantly. It shows understanding of the AI ecosystem. This adds depth to answers.
- Reading practical business examples helps connect theory with modern industry usage effectively. It makes answers more relatable and realistic. This improves interview performance.
- Revising common beginner interview questions builds stronger confidence for introductory rounds. It helps recall answers quickly. This reduces hesitation during interviews.
3. What is Machine Learning?
Ans:
Machine Learning is a subset of Artificial Intelligence that enables systems to learn patterns from data automatically. Instead of explicit programming for every task, algorithms improve performance through training experiences. Machine learning is used in fraud detection, recommendations, spam filtering, and forecasting solutions. It helps businesses make predictions and automate decision processes efficiently. Machine learning basics are commonly asked in fresher interviews.
4. What are the core fundamentals of Machine Learning?
Ans:
- Understanding supervised, unsupervised, and reinforcement learning builds the strongest beginner foundation quickly. These are core machine learning types. Knowing them helps answer most basic questions.
- Learning common use cases such as recommendations and predictions adds practical interview relevance effectively. It shows real-world understanding. This improves answer quality.
- Revising terms like model, training data, features, and accuracy improves confidence significantly. These are frequently used concepts. Strong basics make explanations easier.
- Practicing simple explanations in clear language helps during technical discussions naturally. It improves communication skills. This creates a better impression.
5. What is the difference between Artificial Intelligence and Machine Learning?
Ans:
| Criteria | Artificial Intelligence | Machine Learning |
|---|---|---|
| Meaning | Broad concept of machines performing intelligent tasks. | Subset of AI that learns from data. |
| Scope | Includes ML, robotics, NLP, expert systems. | Focuses on prediction and pattern learning. |
| Working | Can use rules or learning methods. | Uses algorithms trained on datasets. |
| Examples | Chatbots, robotics, virtual assistants. | Spam filters, recommendations, fraud detection. |
6. What are the key points to describe AI and ML difference clearly?
Ans:
- Explaining AI as the broad umbrella concept and ML as one branch creates clarity immediately. It shows structured understanding. This makes answers easy to follow.
- Mentioning AI examples like chatbots and robotics adds stronger practical understanding significantly. It connects theory with real usage. This improves impact.
- Mentioning ML examples like spam filters and recommendation engines improves relevance effectively. It shows practical knowledge. This strengthens your explanation.
- Keeping explanation simple and structured creates stronger interviewer impression naturally. It avoids confusion. This increases clarity and confidence.
7. What is Data Science?
Ans:
Data Science is a multidisciplinary field that extracts useful insights from structured and unstructured data sources. It combines statistics, programming, domain knowledge, and machine learning techniques together. Organizations use data science for decision-making, forecasting, and customer behavior analysis. This field supports innovation through evidence-based strategies and measurable outcomes. Data science basics are useful for AI/ML interviews.
8. What are the core concepts of Data Science?
Ans:
- Learning the role of data collection, cleaning, analysis, and visualization creates strong understanding steadily. It explains the complete data lifecycle. This builds a solid base.
- Understanding relationship between statistics, programming, and machine learning improves conceptual depth significantly. It shows interdisciplinary knowledge. This strengthens answers.
- Studying business examples such as sales forecasting adds practical value effectively. It connects theory to real-world problems. This improves explanation skills.
- Revising beginner terminology improves readiness for interview questions naturally. It helps in quick recall. This boosts confidence.
9. What is Deep Learning?
Ans:
Deep Learning is a subset of machine learning that uses multi-layer neural networks. It is highly effective for image recognition, speech processing, and language understanding tasks. Deep learning models automatically learn complex features from large datasets efficiently. These methods often require higher computing power and larger training data volumes. Basic deep learning knowledge is valuable for beginner candidates.
10. What are the fundamental concepts of Deep Learning?
Ans:
- Understanding neural networks, layers, neurons, and activation functions creates a useful beginner foundation quickly. These are core deep learning concepts. This helps in answering technical questions.
- Learning applications such as facial recognition and voice assistants improves relevance significantly. It shows real-world understanding. This enhances your answers.
- Comparing deep learning with traditional machine learning helps conceptual clarity effectively. It removes confusion between topics. This improves understanding.
- Revising key terminology builds stronger interview confidence naturally. It improves recall speed. This helps in smooth communication.
11. What is supervised learning?
Ans:
Supervised learning is a machine learning approach where models learn from labeled training data. Input data is paired with correct output values during the training process. The model then predicts outputs for unseen future data examples accurately. Common tasks include classification and regression problems across industries. This concept is one of the most asked beginner topics.
12. What is concept of finding maximum of two numbers?
Ans:
Finding the maximum of two numbers is a basic logical operation used to compare values and determine the greater one. It is commonly applied in decision-making processes within algorithms and programming. This concept forms the foundation for conditional statements such as if-else, which control the flow of execution based on comparisons. Understanding this improves problem-solving ability in tasks like sorting, searching, and optimization. Strong clarity in comparison logic is essential for building efficient solutions in technical interviews.
13. What is unsupervised learning?
Ans:
Unsupervised learning is a machine learning method that uses unlabeled data during training. The algorithm identifies hidden patterns, structures, or groups without known outputs. Common tasks include clustering, association, and dimensionality reduction applications. Businesses use unsupervised learning for segmentation and anomaly discovery. This topic is important for AI/ML beginner interviews.
14. Where is Unsupervised Learning commonly applied?
Ans:
- Learning unlabeled data meaning with examples creates a strong conceptual base quickly. It explains how models work without outputs. This improves clarity.
- Understanding clustering methods such as K-means improves technical relevance significantly. It shows knowledge of algorithms. This strengthens answers.
- Studying business applications like customer segmentation adds practical value effectively. It connects theory to real use cases. This improves impact.
- Comparing supervised and unsupervised learning improves memory naturally. It helps differentiate concepts clearly. This avoids confusion.
15. What is reinforcement learning?
Ans:
Reinforcement learning is a method where an agent learns through rewards and penalties. The system interacts with an environment and improves actions over time. This approach is used in robotics, gaming, and optimization scenarios. It focuses on maximizing long-term rewards through repeated decision-making cycles. Reinforcement learning is a common conceptual interview topic.
16. When is Reinforcement Learning most useful?
Ans:
- Understanding terms such as agent, environment, reward, and action creates strong clarity quickly. These are core reinforcement learning concepts. This builds a solid foundation.
- Studying examples like game playing systems improves practical understanding significantly. It shows real-world applications. This improves explanation.
- Comparing reinforcement learning with supervised learning builds conceptual depth effectively. It highlights differences clearly. This strengthens answers.
- Revising beginner diagrams helps memory retention naturally. Visual learning improves recall. This supports quick answering.
17. What is training data?
Ans:
Training data is the dataset used to teach a machine learning model patterns. It contains examples that help algorithms understand relationships within information. Model quality often depends heavily on training data relevance and cleanliness. Poor training data can reduce accuracy and create unreliable predictions. This term is essential for beginner AI interviews.
18. What are the key data-related terms in Machine Learning?
Ans:
- Learning terms such as training data, test data, labels, and features builds foundation strongly. These are essential concepts. This improves understanding.
- Understanding why data quality matters improves practical interview answers significantly. It shows real-world awareness. This adds depth.
- Using simple examples helps convert abstract concepts into clear understanding effectively. It makes answers easy to explain. This improves communication.
- Revising terminology regularly improves recall speed naturally. It helps in quick answering. This boosts confidence.
19. What is test data?
Ans:
Test data is the portion of data used to evaluate model performance after training. It helps measure how well the model generalizes to unseen examples. Using separate test data prevents misleading evaluation based only on memorized patterns. Accurate testing is essential before real-world deployment decisions are made. This concept is frequently asked in beginner rounds.
20. Where is training data and test data distinction important?
Ans:
- Training data teaches the model patterns, while test data measures final performance clearly. This explains their roles. It builds conceptual clarity.
- Explaining unseen data importance shows understanding of real-world reliability significantly. It highlights generalization. This strengthens answers.
- Mentioning overfitting risks adds stronger technical maturity effectively. It shows deeper knowledge. This improves impression.
- Using simple student exam analogy improves interviewer understanding naturally. It makes explanation easy. This increases clarity.
21. What is model accuracy?
Ans:
Model accuracy is a metric showing how many predictions were correct overall. It is commonly used in classification tasks to evaluate performance quickly. Higher accuracy often indicates better results, but context still matters greatly. Imbalanced datasets may require additional metrics beyond simple accuracy values. Accuracy basics are important for beginner interviews.
22. What are the basic evaluation metrics in Machine Learning?
Ans:
- Learning accuracy, precision, recall, and F1-score builds strong evaluation understanding quickly. These are key performance metrics. This improves technical clarity.
- Knowing when accuracy alone is insufficient improves conceptual depth significantly. It shows real-world awareness. This strengthens answers.
- Using fraud detection examples helps practical explanation effectively. It connects theory with application. This improves understanding.
- Revising formulas and meanings improves interview confidence naturally. It helps in quick recall. This supports better performance.
23. What is overfitting?
Ans:
Overfitting happens when a model learns training data too specifically. It performs very well on training data but poorly on new unseen data. This occurs when noise and unnecessary patterns are memorized excessively. Regularization and validation techniques help reduce overfitting problems. Overfitting is a highly common interview concept.
24. What is prevent overfitting in models?
Ans:
- Using more quality training data often improves generalization and reduces memorization risk significantly. It helps models learn better patterns. This improves performance.
- Applying cross-validation methods helps evaluate stability effectively across multiple data splits. It ensures reliable results. This adds technical depth.
- Simplifying model complexity can prevent unnecessary pattern learning strongly. It reduces overfitting risk. This improves accuracy on new data.
- Using regularization and dropout methods adds practical technical depth naturally. These are common techniques. This strengthens interview answers.
25. What are final beginner tips for TCS AI/ML interviews?
Ans:
Success in beginner AI/ML interviews depends on strong conceptual clarity rather than advanced mathematics alone. Candidates should know definitions, algorithms, applications, and common data terminology thoroughly. Simple explanations with confidence often create stronger impressions than memorized complexity. Regular revision and project examples improve technical discussion quality significantly. Balanced preparation gives the best chance of fresher selection success.
26. What is underfitting in Machine Learning?
Ans:
Underfitting happens when a machine learning model is too simple to capture important patterns from data. Such models perform poorly on both training data and unseen test data consistently. This problem often occurs when insufficient features or weak algorithms are selected. Increasing model complexity and better feature engineering can improve performance significantly. Underfitting is a common beginner interview concept.
27. When to reduce underfitting problems?
Ans:
- Choosing stronger algorithms with better learning capacity helps models capture useful patterns more effectively. It improves model performance. This reduces underfitting.
- Adding relevant features and improving input data quality can increase prediction performance significantly. Better data leads to better learning. This strengthens results.
- Training for more iterations often allows the model to learn deeper relationships properly. It improves learning. This reduces errors.
- Reviewing bias-related errors helps identify underfitting causes quickly and accurately. It improves debugging. This strengthens understanding.
28. What is classification in Machine Learning?
Ans:
Classification is a supervised learning task where outputs belong to predefined categories or classes. Examples include spam detection, disease prediction, and customer churn identification systems. The model learns from labeled examples and predicts future class labels accurately. Binary and multi-class classification are common forms used in practice. Classification is frequently asked in AI interviews.
29. When is Classification used in Machine Learning?
Ans:
- Learning binary classification examples such as spam or not spam builds strong conceptual clarity quickly. It explains basic classification clearly. This improves understanding.
- Understanding multi-class classification cases like image category prediction improves relevance significantly. It shows advanced knowledge. This strengthens answers.
- Studying algorithms such as logistic regression and decision trees adds practical depth effectively. These are commonly used methods. This improves confidence.
- Revising confusion matrix basics strengthens evaluation understanding naturally. It helps measure performance. This improves technical clarity.
30. What is regression in Machine Learning?
Ans:
Regression is a supervised learning task used to predict continuous numerical values. Examples include house price prediction, sales forecasting, and temperature estimation models. The algorithm learns relationships between input variables and target numeric outputs. Linear regression is one of the most basic and popular regression methods. Regression is an essential beginner interview topic.
31. Where is Regression applied in real-world problems?
Ans:
- Understanding continuous output prediction with real business examples creates strong interview clarity quickly. It explains regression clearly. This improves answers.
- Learning linear regression purpose and working principle adds useful technical depth significantly. It shows algorithm understanding. This strengthens knowledge.
- Comparing regression with classification helps remove confusion effectively for beginners. It improves clarity. This avoids mistakes.
- Revising metrics like MAE and RMSE improves preparation naturally. These are evaluation metrics. This improves confidence.
32. What is feature in Machine Learning?
Ans:
A feature is an individual input variable used by a model for learning patterns. Examples include age, salary, temperature, and transaction amount in datasets. Good feature selection strongly affects model performance and prediction quality. Irrelevant features may reduce efficiency and increase noise in training. Feature knowledge is important for beginner AI rounds.
33. What are the key aspects of Feature Selection?
Ans:
- Learning that features are input columns helps create strong dataset understanding immediately. It explains data structure clearly. This builds foundation.
- Identifying relevant variables improves model accuracy and training efficiency significantly. It enhances performance. This is important in practice.
- Removing duplicate or unnecessary features reduces complexity effectively in many cases. It simplifies models. This improves efficiency.
- Practicing with sample datasets builds stronger intuition naturally over time. It improves hands-on understanding. This strengthens learning.
34. What is label in Machine Learning?
Ans:
A label is the target output value that a supervised model learns to predict. In spam detection, spam or not spam acts as the label category. In house price prediction, the price itself becomes the label value. Labels are essential during supervised training for learning correct relationships. This term is commonly asked in beginner interviews.
35. What are the key dataset-related terminologies?
Ans:
- Learning terms such as features, labels, rows, columns, and samples builds strong fundamentals quickly. These are basic concepts. This improves clarity.
- Using simple tables and examples helps convert theory into practical understanding effectively. It makes learning easier. This improves explanation.
- Revising labeled versus unlabeled data improves conceptual clarity significantly. It helps differentiate concepts. This avoids confusion.
- Practicing explanations aloud strengthens interview communication naturally. It improves confidence. This enhances performance.
36. What is decision tree algorithm?
Ans:
A decision tree is a supervised learning algorithm that splits data using rule-based decisions. It resembles a tree structure containing root nodes, branches, and leaf outcomes. Decision trees are easy to understand and useful for classification tasks. They can also be applied to regression problems with modifications. Decision trees are popular beginner interview topics.
37. When is Decision Tree algorithm preferred?
Ans:
- Understanding how data splits based on conditions creates strong algorithm clarity immediately. It explains decision making clearly. This improves understanding.
- Learning concepts such as nodes, branches, and leaves improves technical confidence significantly. These are key terms. This strengthens answers.
- Studying examples like loan approval decisions adds practical relevance effectively. It connects theory with real cases. This improves impact.
- Revising advantages and limitations strengthens final preparation naturally. It shows balanced understanding. This improves interview quality.
38. What is random forest algorithm?
Ans:
Random Forest is an ensemble learning method that combines many decision trees together. Multiple trees vote or average outputs to improve prediction performance significantly. This method usually reduces overfitting compared to a single decision tree. Random Forest is widely used in classification and regression tasks. It is a common beginner machine learning interview concept.
39. Where is Random Forest commonly used?
Ans:
- Explaining multiple decision trees working together creates immediate conceptual clarity for interviewers. It shows ensemble learning. This improves understanding.
- Mentioning voting for classification and averaging for regression adds useful depth significantly. It explains working clearly. This strengthens answers.
- Highlighting reduced overfitting compared to single trees improves answer quality effectively. It shows advantage. This adds value.
- Using simple forest analogy strengthens memory and communication naturally. It makes explanation easy. This improves clarity.
40. What is logistic regression?
Ans:
Logistic Regression is a supervised learning algorithm mainly used for classification tasks. Despite the name regression, it predicts class probabilities rather than continuous values. It is commonly used for binary outcomes such as yes or no decisions. The algorithm is simple, fast, and interpretable for many beginner problems. Logistic regression is widely asked in interviews.

Enroll in AI and Machine Learning Course and UPGRADE Your Skills
Weekday / Weekend BatchesSee Batch Details41. When is Logistic Regression used?
Ans:
- Learning binary classification examples such as fraud detection builds practical understanding quickly. These examples show how models predict yes/no outcomes. This improves clarity in real-world applications.
- Understanding probability output and threshold concepts improves technical clarity significantly. Logistic regression gives probabilities instead of direct classes. Thresholds help convert probabilities into final predictions.
- Comparing logistic regression with linear regression removes confusion effectively. It highlights differences in output type and use cases. This comparison strengthens conceptual understanding.
- Revising use cases and benefits strengthens confidence naturally. It helps recall where logistic regression is applied. This improves interview performance.
42. What is K-means clustering?
Ans:
K-means clustering is an unsupervised algorithm used to group similar data points together. The method divides data into K number of clusters based on similarity measures. It is commonly used for customer segmentation and pattern discovery tasks. Centroids are updated repeatedly until stable clusters are formed. K-means is a very common beginner interview topic.
43. Where is Clustering applied?
Ans:
- Understanding unlabeled grouping purpose creates strong unsupervised learning clarity quickly. Clustering works without predefined outputs. This helps in recognizing patterns in data.
- Learning centroid movement and iteration process adds useful algorithm depth significantly. It explains how clusters are formed step by step. This improves technical explanation ability.
- Studying customer segmentation examples improves practical business relevance effectively. It shows how clustering is used in marketing. This connects theory with real-world usage.
- Comparing clustering with classification strengthens conceptual memory naturally. It highlights supervised vs unsupervised learning differences. This reduces confusion during interviews.
44. What is model training?
Ans:
Model training is the process of allowing an algorithm to learn from training data. During training, parameters are adjusted to reduce prediction errors gradually. The quality of training depends on data, features, and algorithm selection. Proper training helps create models that generalize well on unseen data. Training is a foundational AI interview concept.
45. How to prepare model training basics?
Ans:
- Learning how algorithms adjust parameters builds strong conceptual understanding immediately. It explains how models learn from data. This forms the base of machine learning knowledge.
- Understanding relationship between training data and performance improves clarity significantly. Better data leads to better models. This highlights importance of data quality.
- Studying epochs, iterations, and optimization basics adds practical depth effectively. These terms explain training cycles and improvement process. This improves technical confidence.
- Revising examples helps simplify technical explanations naturally. Examples make abstract concepts easier to understand. This helps during interviews.
46. What is model testing?
Ans:
Model testing is the evaluation phase where trained models are checked using unseen data. It helps estimate how the system may perform in real-world situations. Testing prevents false confidence based only on training results. Reliable testing is essential before deployment decisions are made. Testing concepts are commonly asked in beginner rounds.
47. When is Model Evaluation important?
Ans:
- Learning why unseen data matters creates strong generalization understanding quickly. It shows how models perform in real-world situations. This prevents overconfidence.
- Studying train-test split methods improves technical readiness significantly. It explains how data is divided for training and testing. This is a core evaluation concept.
- Revising metrics such as accuracy and error rates adds practical value effectively. These metrics measure model performance. Understanding them improves analysis skills.
- Comparing training versus testing performance helps detect problems naturally. It identifies overfitting or underfitting issues. This strengthens problem-solving ability.
48. What is bias in Machine Learning?
Ans:
Bias in machine learning may refer to systematic error caused by oversimplified assumptions. High bias models often underfit because they fail to learn complex relationships. Bias can also relate to unfair data patterns affecting predictions negatively. Reducing harmful bias requires balanced data and better modeling choices. Bias is an important beginner concept in interviews.
49. What are the key concepts of Bias in Machine Learning?
Ans:
- Learning bias as model error due to oversimplification creates immediate clarity strongly. It explains why simple models fail. This builds conceptual understanding.
- Understanding relation between bias and underfitting improves conceptual depth significantly. High bias leads to poor learning. This helps in explaining model limitations.
- Studying fairness examples in datasets adds modern practical relevance effectively. It highlights ethical issues in AI. This improves awareness.
- Revising bias versus variance differences strengthens confidence naturally. It helps compare two important concepts. This is commonly asked in interviews.
50. What are final tips for AI/ML beginners after first preparation stage?
Ans:
Strong beginner preparation should focus on concepts, terminology, and real-world applications clearly. Candidates should understand algorithms at high level rather than memorizing excessive mathematics initially. Simple project examples and confident explanations improve technical discussion quality significantly. Regular revision helps retain definitions, differences, and evaluation concepts effectively. Consistent learning creates the best path toward fresher success.
51. What is variance in Machine Learning?
Ans:
Variance refers to how much a machine learning model changes when trained on different datasets. High variance models often memorize training data and fail on unseen examples. This issue is strongly connected with overfitting in many practical scenarios. Reducing variance helps improve stability and real-world prediction consistency significantly. Variance is an important beginner interview concept.
52. When are variance reduction techniques applied?
Ans:
- Using simpler algorithms or reducing unnecessary complexity often lowers unstable prediction behavior significantly. Complex models tend to overfit. Simpler models improve stability.
- Increasing training data quantity and quality helps models generalize more effectively over time. More data reduces sensitivity to noise. This improves performance.
- Applying regularization techniques can control over-learning of noisy patterns strongly. Regularization limits model complexity. This prevents overfitting.
- Ensemble methods such as Random Forest improve stability in many practical cases naturally. Multiple models work together. This increases accuracy and reliability.
53. What is the difference between bias and variance in Machine Learning?
Ans:
| Criteria | Bias | Variance |
|---|---|---|
| Meaning | Error from overly simple assumptions. | Error from sensitivity to training data. |
| Effect | Often causes underfitting. | Often causes overfitting. |
| Behavior | Misses important patterns. | Learns noise and fluctuations. |
| Solution | Use better features or stronger model. | Use regularization or more data. |
54. What are the key concepts of Bias-Variance Tradeoff?
Ans:
- Learning underfitting and overfitting first makes tradeoff understanding much easier for beginners. These are core concepts. They explain model behavior clearly.
- Using graph-based examples of model complexity improves conceptual clarity significantly. Visuals show how errors change. This improves understanding.
- Studying real scenarios where too simple or too complex models fail adds value effectively. It connects theory with practice. This improves explanation ability.
- Revising definitions repeatedly helps stronger memory retention naturally. It ensures quick recall during interviews. This builds confidence.
55. What is cross validation?
Ans:
Cross validation is a method used to evaluate model performance on multiple data splits. It provides more reliable results than depending on only one train-test division. K-fold cross validation is the most common form used widely in practice. This method helps measure consistency and reduce evaluation bias significantly. Cross validation is valuable for beginner AI interviews.
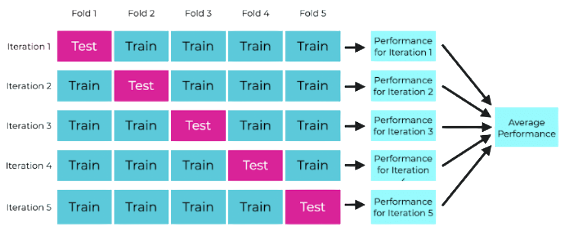
56. What are the key concepts of Cross Validation?
Ans:
- Explaining repeated training and testing on different data portions creates immediate clarity strongly. It shows how models are evaluated multiple times. This improves reliability understanding.
- Mentioning K-fold process where data is divided into equal parts improves relevance significantly. Each part is used for testing once. This explains the process clearly.
- Highlighting more reliable performance estimation adds practical value effectively. It reduces dependency on one split. This improves evaluation accuracy.
- Comparing with single train-test split helps interview understanding naturally. It shows advantages of cross validation. This strengthens answers.
57. What is feature engineering?
Ans:
Feature engineering is the process of creating or improving input variables for better model learning. Good features often increase model accuracy more than complex algorithms alone. Examples include date conversion, scaling values, and combining related columns together. This step requires domain understanding and analytical thinking in projects. Feature engineering is an important practical interview topic.
58. What are the key concepts of Feature Engineering?
Ans:
- Learning that better input data often improves models more than algorithm changes creates clarity quickly. Data quality plays a major role. This builds strong foundation.
- Studying examples like extracting month from dates adds practical relevance significantly. It shows how raw data is transformed. This improves understanding.
- Understanding removal of useless columns improves technical maturity effectively. It reduces noise in data. This improves model performance.
- Revising preprocessing workflow strengthens confidence naturally for interviews. It helps organize steps clearly. This improves explanation skills.
59. What is feature scaling?
Ans:
Feature scaling is the process of bringing input variables into similar numerical ranges. Some algorithms perform better when large and small values are normalized consistently. Methods include standardization and min-max normalization techniques commonly used. Scaling can improve training speed and model performance significantly. This is a frequent beginner machine learning topic.
60. When is Feature Scaling required in Machine Learning?
Ans:
- Understanding why unequal feature ranges affect algorithms creates strong conceptual clarity immediately. Some algorithms depend on distance calculations. Large values can dominate results.
- Learning standardization and normalization differences improves technical readiness significantly. These are common scaling methods. Knowing when to use them is important.
- Studying examples with salary and age values adds practical value effectively. It shows real-world scaling needs. This improves understanding.
- Revising algorithm types needing scaling strengthens memory naturally. Algorithms like KNN and SVM require scaling. This helps in interviews.

Learn AI and Machine Learning Course with Advanced Concepts By Industry Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
61. What is normalization in Machine Learning?
Ans:
Normalization is a scaling technique that transforms values into a fixed range, often zero to one. It helps algorithms compare variables fairly without dominance from larger magnitudes. Normalization is especially useful in distance-based learning methods frequently. This process supports stable and efficient model training significantly. Normalization basics are useful for beginner interviews.
62. What are the key concepts of Normalization?
Ans:
- Defining normalization as converting values into common range creates instant understanding strongly. It simplifies how different scales are adjusted equally. This helps beginners grasp the concept quickly.
- Mentioning zero to one scaling improves technical clarity significantly. It shows the standard range used in many algorithms. This makes explanations more precise.
- Explaining usefulness in K-means and nearest neighbor methods adds relevance effectively. These algorithms depend on distance calculations. Proper scaling improves their accuracy.
- Comparing with raw unscaled data helps memory naturally. It highlights problems caused by large value differences. This comparison strengthens understanding.
63. What is standardization in Machine Learning?
Ans:
Standardization transforms data so values have mean zero and standard deviation one. It is useful when algorithms assume centered and comparable input distributions. Methods like logistic regression and support vector machines often benefit strongly. Standardization may perform better than normalization in certain scenarios. This concept is commonly asked in beginner rounds.
64. What are the fundamental concepts of Standardization?
Ans:
- Learning mean zero and unit variance meaning builds conceptual confidence quickly.
- Understanding difference between standardization and normalization removes confusion significantly.
- Studying algorithm examples needing standardized data adds practical value effectively.
- Revising formulas improves retention naturally for interviews.
65. What is confusion matrix?
Ans:
A confusion matrix is a table used to evaluate classification model predictions. It shows true positives, true negatives, false positives, and false negatives clearly. This matrix helps derive metrics such as precision and recall values. It gives deeper insight than accuracy alone in many cases. Confusion matrix is a popular beginner interview topic.
66. What are the key concepts of Confusion Matrix?
Ans:
- Learning four major outcomes in classification builds strong evaluation understanding immediately. These include true positive, true negative, false positive, and false negative. This forms the foundation of model evaluation.
- Using disease detection or spam examples improves practical clarity significantly. Real-world scenarios make concepts easier to understand. This improves explanation skills.
- Studying precision and recall formulas adds technical depth effectively. These metrics are derived from the confusion matrix. This strengthens analytical understanding.
- Comparing with plain accuracy strengthens conceptual maturity naturally. It shows why accuracy alone is not enough. This improves interview answers.
67. What is precision in Machine Learning?
Ans:
Precision measures how many predicted positive cases were actually correct positives. It becomes highly important when false positives create serious business problems. Examples include fraud alerts and spam detection systems widely used today. Higher precision means fewer incorrect positive predictions overall. Precision basics are important for beginner interview preparation.
68. What are the key concepts of Precision?
Ans:
- Defining precision as correctness among predicted positives creates quick clarity strongly. It explains how many predicted results are actually correct. This simplifies the concept.
- Using spam email example improves practical understanding significantly. It shows how incorrect classifications affect results. This makes learning relatable.
- Mentioning false positive reduction adds business relevance effectively. It highlights importance in real applications. This improves interview impact.
- Comparing precision with recall helps memory naturally. It shows the difference clearly. This improves conceptual clarity.
69. What is recall in Machine Learning?
Ans:
Recall measures how many actual positive cases were correctly identified by the model. It is critical when missing positives causes major risk or loss. Examples include disease detection and fraud prevention systems commonly used. Higher recall means fewer missed positive cases overall. Recall is a common beginner interview metric.
70. What are the key concepts of Recall?
Ans:
- Defining recall as captured positives among actual positives builds clarity immediately. It shows how many real cases are identified. This simplifies understanding.
- Using medical diagnosis examples improves practical relevance significantly. It highlights importance of detecting all critical cases. This makes the concept meaningful.
- Highlighting false negative reduction adds stronger understanding effectively. It explains risks of missing important cases. This improves conceptual depth.
- Comparing recall with precision improves interview confidence naturally. It clarifies differences between metrics. This strengthens answers.
71. What is the difference between precision and recall in Machine Learning?
Ans:
| Criteria | Precision | Recall |
|---|---|---|
| Meaning | Correct positives among predicted positives. | Captured positives among actual positives. |
| Focus | Reduces false positive errors. | Reduces false negative errors. |
| Use Cases | Spam filters, fraud alerts. | Disease detection, security checks. |
| Best When | Wrong positive alerts are costly. | Missing positives is risky. |
72. What are the key concepts of F1 Score?
Ans:
- Learning F1 score as balance between precision and recall creates immediate understanding strongly. It shows combined performance measure. This simplifies evaluation concepts.
- Studying why imbalanced datasets need F1 improves technical maturity significantly. It explains limitations of accuracy. This improves deeper understanding.
- Using fraud detection examples adds practical value effectively. It connects theory with real-world problems. This improves explanation quality.
- Revising formula and interpretation improves confidence naturally. It helps recall during interviews. This strengthens performance.
73. What is hyperparameter in Machine Learning?
Ans:
Hyperparameters are settings chosen before training that control model learning behavior. Examples include tree depth, learning rate, and number of clusters. They differ from model parameters learned automatically during training. Good hyperparameter tuning can significantly improve final model performance. This is an important beginner interview topic.
74. What are the key concepts of Hyperparameters?
Ans:
- Defining hyperparameters as pre-training settings creates strong conceptual clarity quickly. It distinguishes them from learned parameters. This removes confusion.
- Giving examples like K in K-means improves interview relevance significantly. It shows practical usage. This makes answers stronger.
- Comparing with learned parameters removes common beginner confusion effectively. It highlights differences clearly. This improves understanding.
- Mentioning tuning benefits adds practical technical depth naturally. It shows impact on model performance. This strengthens interview responses.
75. What are final tips after intermediate AI/ML preparation stage?
Ans:
Candidates should now focus on evaluation metrics, preprocessing, and algorithm comparisons carefully. Understanding why techniques are used is more valuable than memorizing definitions alone. Simple project examples can strongly improve practical discussion quality significantly. Regular revision helps retain formulas, terminology, and interview confidence effectively. Consistent learning creates stronger chances of fresher success.
76. What is learning rate in Machine Learning?
Ans:
Learning rate is a tuning parameter that controls how much model weights change during optimization steps. A very high learning rate may skip good solutions and create unstable training behavior. A very low learning rate may slow training and increase computation time greatly. Choosing balanced values helps models converge efficiently toward better results. Learning rate is a common beginner interview concept.
77. When is Learning Rate important in Machine Learning?
Ans:
- Understanding learning rate as step size during optimization creates immediate conceptual clarity strongly. It explains how models update weights. This simplifies the idea.
- Studying effects of very high and very low values improves technical maturity significantly. It shows impact on training stability. This improves understanding.
- Using hill-climbing or staircase examples adds practical explanation value effectively. Visual examples make concepts easier. This improves memory.
- Revising optimizer basics helps stronger interview confidence naturally. It connects with gradient descent concepts. This strengthens preparation.
78. What is gradient descent?
Ans:
Gradient descent is an optimization algorithm used to minimize model error during training. It updates parameters gradually in the direction that reduces loss values. This method is widely used in regression, neural networks, and deep learning systems. Several versions include batch, stochastic, and mini-batch gradient descent methods. Gradient descent is frequently asked in AI interviews.
79. What are the key concepts of Gradient Descent?
Ans:
- Defining gradient descent as moving step by step toward lower error creates clarity quickly. It simplifies optimization process. This helps beginners understand easily.
- Mentioning loss reduction during training improves conceptual understanding significantly. It explains the goal of the algorithm. This adds clarity.
- Learning batch and stochastic variants adds useful technical depth effectively. It shows different approaches. This improves interview answers.
- Using valley or mountain analogies improves memory naturally. Visual comparisons make learning easier. This strengthens retention.
80. What is neural network?
Ans:
A neural network is a computing model inspired by interconnected neurons in the brain. It contains layers of nodes that process input data and learn patterns automatically. Neural networks are widely used in image recognition, speech tasks, and forecasting. Deep neural networks contain many hidden layers for complex learning tasks. Neural network basics are valuable for beginners.
81. What are the fundamental concepts of Neural Networks?
Ans:
- Learning input, hidden, and output layer roles creates strong structural understanding quickly. It explains how data flows in networks. This builds foundation.
- Understanding weights, activation functions, and training improves technical clarity significantly. These are key components of learning. This improves depth.
- Studying real examples like handwriting recognition adds practical relevance effectively. It connects theory with real-world use. This improves explanation.
- Revising diagrams regularly strengthens memory naturally for interviews. Visual learning improves recall. This boosts confidence.
82. What is activation function?
Ans:
An activation function decides whether a neuron should pass information forward in a network. It introduces non-linearity, allowing neural networks to learn complex relationships effectively. Common activation functions include ReLU, Sigmoid, and Tanh methods widely used. Without activation functions, deep models would behave like simple linear systems. This topic is commonly asked in AI interviews.
83. What are the key concepts of Activation Functions?
Ans:
- Learning purpose of non-linearity creates immediate conceptual clarity strongly for beginners. It explains why simple linear models are not enough. This builds strong basics.
- Studying ReLU, Sigmoid, and Tanh differences improves technical readiness significantly. It shows when to use each function. This improves depth.
- Understanding why activation functions matter in deep learning adds depth effectively. It explains model learning capability. This strengthens concepts.
- Revising practical use cases strengthens interview confidence naturally. It helps connect theory with applications. This improves answers.
84. What is epoch in Machine Learning?
Ans:
An epoch means one complete pass of the full training dataset through the model. During multiple epochs, the model gradually improves by learning repeatedly from data. Too few epochs may cause underlearning, while too many may overfit data. Choosing suitable epochs depends on model behavior and validation performance. Epoch is a common beginner interview term.

85. What are the key concepts of Epochs?
Ans:
- Defining epoch as one full training cycle creates strong understanding immediately. It explains how data is processed. This simplifies the concept.
- Explaining repeated learning over many epochs improves technical clarity significantly. It shows gradual improvement of models. This builds understanding.
- Mentioning underfitting and overfitting relation adds practical value effectively. It explains impact of training duration. This improves depth.
- Using classroom revision analogy helps memory naturally. It makes learning relatable. This improves retention.
86. What is batch size?
Ans:
Batch size is the number of training samples processed before updating model parameters. Small batches may train noisily but often generalize well in practice. Large batches may train faster using hardware resources more efficiently. Choosing the right batch size balances speed, memory, and learning stability. Batch size is frequently discussed in interviews.
87. What are the key concepts of Batch Size?
Ans:
- Learning batch size as samples per update creates immediate clarity strongly. It explains how training data is processed. This simplifies the idea.
- Understanding small versus large batch tradeoffs improves technical maturity significantly. It shows impact on training performance. This improves depth.
- Studying memory usage impact adds practical interview relevance effectively. It explains hardware considerations. This strengthens understanding.
- Revising connection with epochs strengthens retention naturally. It connects related concepts. This improves clarity.
88. What is Natural Language Processing?
Ans:
Natural Language Processing is a field of AI focused on understanding human language data. It enables machines to process text, speech, and language meaning effectively. Applications include chatbots, translation systems, sentiment analysis, and voice assistants. NLP combines linguistics, machine learning, and deep learning techniques together. NLP basics are valuable for fresher interviews.
89. What are the key concepts of Natural Language Processing?
Ans:
- Learning text processing goals creates strong understanding of language AI systems quickly. It explains how machines handle language. This builds foundation.
- Studying examples like chatbots and translation improves practical relevance significantly. It connects theory with real applications. This improves explanation.
- Understanding tokens, stemming, and sentiment analysis adds technical depth effectively. These are core NLP techniques. This strengthens knowledge.
- Revising real-world use cases strengthens interview confidence naturally. It helps explain concepts clearly. This improves performance.
90. What are final success tips for TCS AI/ML beginner interviews?
Ans:
Strong success depends on clear fundamentals, steady revision, and confident communication throughout preparation. Candidates should understand algorithms, metrics, preprocessing, and real-world applications thoroughly. Explaining concepts simply often creates better impressions than memorized complexity alone. Mini projects and examples help demonstrate practical awareness significantly during interviews. Consistent preparation gives the best chance of fresher selection success.




