
Last updated on 21st Apr 2026| 7336
Data Structures And Algorithms (DSA) play a major role in Google technical interviews for freshers. Google focuses on problem-solving ability, logical thinking, coding efficiency, and optimization techniques. Freshers preparing for Google interviews should have strong knowledge of arrays, linked lists, stacks, queues, trees, graphs, recursion, sorting, searching, and dynamic programming. Interview questions are designed to test coding skills, analytical thinking, and time complexity understanding. Practicing DSA regularly helps candidates improve accuracy and confidence during coding rounds. A good understanding of algorithms and real-time problem solving increases the chances of cracking Google interviews successfully.
1. What is Data Structure?
Ans:
Data structure is a method of organizing and storing data efficiently in computer memory. It helps in easy access, modification, and management of data during program execution. It improves the performance of algorithms by organizing data in a structured way. Common types include arrays, linked lists, stacks, queues, trees, and graphs. Each data structure is designed for specific problem-solving requirements. It is a core concept in computer science and programming. Choosing the right data structure improves both time and space efficiency.
2. What is Algorithm?
Ans:
An algorithm is a step-by-step procedure used to solve a specific problem efficiently. It takes input data, processes it through defined steps, and produces the required output.It must be finite, correct, and optimized for performance. Algorithms are widely used in searching, sorting, and optimization problems. Their efficiency is measured using time and space complexity. Good algorithms improve system speed and scalability. It is essential for coding interviews and real-world software development.
3. What is Array?
Ans:
An array is a linear data structure that stores elements of the same type in contiguous memory locations. Each element in an array is accessed using an index value. It provides fast access to elements due to direct indexing. However, insertion and deletion operations are slower compared to other structures. The size of an array is usually fixed in most programming languages. Arrays are widely used in programming for storing and processing data. It is one of the simplest and most important data structures.
4. What is Linked List?
Ans:
A linked list is a linear data structure made up of nodes where each node contains data and a pointer to the next node. It allows dynamic memory allocation, unlike arrays. Insertion and deletion operations are easier and more efficient compared to arrays. However, traversal is sequential and slower than arrays. It uses extra memory for storing pointers. Linked lists are commonly used in implementing stacks, queues, and graphs. It is useful when frequent data modifications are required.
5..What is Binary Search Tree?
Ans:
A binary search tree is a special type of binary tree with ordering properties. The left subtree contains values smaller than the root node. The right subtree contains values greater than the root node. It supports fast searching, insertion, and deletion operations. Its average time complexity is O(log n). It is widely used in indexing and database systems. It is a key topic in coding interviews.
6. What is Stack?
Ans:
A stack is a linear data structure that follows the LIFO (Last In First Out) principle. In a stack, insertion is called push and deletion is called pop. Only the top element of the stack is accessible at any time. It is used in function calls, recursion, and expression evaluation. Stack operations are simple and efficient. It plays an important role in backtracking and memory management. It is widely used in programming and system processes.
7. What is Queue?
Ans:
- A queue is a linear data structure that follows the FIFO (First In First Out) principle. Insertion happens at the rear end and deletion happens at the front end.
- It is commonly used in scheduling and buffering systems. Types of queues include simple queue, circular queue, and priority queue.
- It models real-life waiting systems like ticket counters. It ensures fair processing of tasks in order. It is widely used in operating systems and networking.
8. What is Binary Search?
Ans:
Binary search is an efficient searching algorithm used on sorted arrays. It works by repeatedly dividing the array into two halves. It compares the middle element with the target value. If the element is found, the search ends successfully. Otherwise, it continues in the left or right half. Its time complexity is O(log n), making it very fast. It uses the divide and conquer technique.
9. What is Linear Search?
Ans:
Linear search is a simple searching technique that checks each element one by one. It works on both sorted and unsorted data. The search starts from the first element and moves sequentially. If the element is found, the process stops immediately. Its time complexity is O(n), which is slower for large datasets. It does not require sorting of data. It is useful for small or unsorted datasets.
10. What is Recursion?
Ans:
Recursion is a programming technique where a function calls itself to solve smaller subproblems. It breaks a complex problem into simpler parts. Every recursive function must have a base condition to stop execution. Without a base case, it leads to infinite recursion. It uses stack memory for function calls. It is widely used in tree and graph problems. It simplifies problem-solving in many cases.
11. What is Time Complexity?
Ans:
Time complexity measures the amount of time an algorithm takes to complete execution. It is expressed using Big-O notation. It depends on the size of input data. Common complexities include O(1), O(n), O(log n), and O(n²). Lower time complexity indicates better performance. It helps compare different algorithms. It is very important in coding interviews. It helps in selecting the most efficient solution. It is a key factor in optimization problems.
12. What is Space Complexity?
Ans:
Space complexity measures the total memory used by an algorithm. It includes input space and auxiliary space. It is expressed using Big-O notation. Efficient algorithms use less memory while processing data. It is important for large-scale applications and systems. It affects system performance and scalability. It balances memory usage and execution efficiency. It helps in designing memory-efficient programs. It is crucial in system design and optimization.
13. What is Sorting?
Ans:
Sorting is the process of arranging data in a particular order. It can be ascending or descending. Common sorting algorithms include bubble sort, merge sort, and quick sort. Sorting improves searching and data analysis operations. Different algorithms have different performance levels. It is widely used in real-world applications. It is a fundamental concept in DSA. It helps in efficient data processing. It is essential for database and algorithm optimization.
14. What is Bubble Sort?
Ans:
- Bubble sort is a simple comparison-based sorting algorithm. It repeatedly swaps adjacent elements if they are in the wrong order.
- After each pass, the largest element moves to the end. Its time complexity is O(n²), making it inefficient for large data. It is easy to understand and implement.
- It is mainly used for learning purposes. It is not suitable for real-world large dataset. It helps beginners understand sorting logic. It demonstrates basic algorithm design clearly.
15. Check if a number is even or odd?
Ans:
A number is even if it is divisible by 2, otherwise it is odd. We use the modulus operator (%) to check the remainder when dividing by 2. If num % 2 == 0, the number is even; otherwise, it is odd. This helps beginners understand conditions and operators. It is a basic logical problem in interviews. It runs in O(1) time complexity. It is widely used in beginner coding tests.
- num = int(input(“Enter number: “))
- if num % 2 == 0:
- print(“Even”)
- else:
- print(“Odd”)
16. What is Quick Sort?
Ans:
Quick sort is a divide and conquer sorting algorithm. It selects a pivot element and partitions the array around it. Smaller elements go to the left and larger elements to the right. It recursively sorts the subarrays. Its average time complexity is O(n log n). In the worst case, it becomes O(n²). It is widely used due to its efficiency
17. What is Hashing?
Ans:
Hashing is a technique used to map data into fixed-size values using a hash function. It enables fast data retrieval using hash tables. The average time complexity is O(1) for search operations. However, collisions can occur when two keys map to the same value. These collisions are handled using chaining or probing techniques. It is widely used in databases and caching systems. It improves performance significantly.
18. What is Tree Data Structure?
Ans:
A tree is a hierarchical data structure consisting of nodes connected by edges. The topmost node is called the root node. Each node can have multiple child nodes. A binary tree allows at most two children per node. Trees are used in file systems and databases. They help in efficient searching and sorting. It is an important concept in DSA.
19. What is Binary Tree?
Ans:
A binary tree is a tree data structure where each node has at most two children. These children are called the left child and right child. It is commonly used in expression evaluation and hierarchical data representation. Traversal methods include inorder, preorder, and postorder. It forms the base for binary search trees. It is widely used in interview problems. It helps in organizing data efficiently.
20. Difference between Array and Linked List?
Ans:
| Feature | Array | Linked List |
|---|---|---|
| Memory Structure | Stores elements in contiguous memory locations | Stores elements in non-contiguous memory locations |
| Size | Fixed size (in most languages | Dynamic size (can grow or shrink) |
| Access Time | Fast random access using index O(1) | Sequential access O(n) |
| Insertion | Slow (requires shifting elements) | SFast (just pointer changes) |
21. What is Graph?
Ans:
A graph is a non-linear data structure consisting of vertices (nodes) and edges that connect them. It is used to represent relationships between objects such as social networks, maps, and web links. Graphs can be either directed or undirected depending on the direction of edges. They are useful for solving complex real-world problems involving connections. Common traversal techniques include BFS and DFS. Graphs help in modeling networks and relationships efficiently. They are widely used in computer science applications.
22. What is BFS?
Ans:
Breadth First Search (BFS) is a graph traversal algorithm used to explore nodes level by level. It starts from a source node and visits all its neighbors before moving deeper. It uses a queue data structure for processing nodes. BFS is commonly used to find the shortest path in unweighted graphs. Its time complexity is O(V+E), where V is vertices and E is edges. It is widely used in networking and AI applications. It ensures systematic exploration of a graph.
23. What is DFS?
Ans:
Depth First Search (DFS) is a graph traversal technique that explores as far as possible along each branch before backtracking. It uses recursion or a stack data structure for implementation. DFS starts from a source node and explores deep paths first. It is useful in cycle detection, path finding, and topological sorting. Its time complexity is O(V+E). It is commonly used in maze solving and puzzle problems. It helps in exploring all possible paths in a graph
24. What is Heap?
Ans:
A heap is a special tree-based data structure that satisfies the heap property. In a max heap, the parent node is greater than its children, while in a min heap, it is smaller. It is commonly used to implement priority queues. Heaps are typically implemented using arrays for efficiency. Insertion and deletion operations are optimized. It is widely used in scheduling and sorting algorithms like heap sort. It ensures quick access to the highest or lowest priority element.
25. What is Priority Queue?
Ans:
A priority queue is an abstract data structure where each element is assigned a priority. Elements with higher priority are served before lower priority ones. It is commonly implemented using a heap data structure. Unlike a normal queue, it does not follow FIFO strictly. It is used in operating systems for task scheduling. It is also used in network routing algorithms. It improves efficiency in managing prioritized tasks.
26. What is Hash Table?
Ans:
A hash table is a data structure that stores key-value pairs using a hash function. It maps keys to specific indices for fast data retrieval. The average time complexity for search, insert, and delete operations is O(1). It is widely used in databases, caching, and dictionaries. Collisions may occur when two keys map to the same index. These are handled using techniques like chaining or open addressing. It is an efficient structure for fast lookups.
27. What is Collision in Hashing?
Ans:
- Collision in hashing occurs when two different keys generate the same hash index. This creates a conflict in storing values in a hash table.
- It reduces performance if not handled properly. Common collision handling techniques include chaining and open addressing.
- Good hash functions help reduce the chances of collisions. It is a fundamental issue in hash table design. Proper handling ensures efficient data retrieval.
28. What is Stack Overflow?
Ans:
Stack overflow is an error that occurs when the stack memory limit is exceeded. It usually happens due to infinite or very deep recursion. It can crash the program or system. Each function call consumes stack memory. Without a proper base condition, recursion may cause overflow. It is a common runtime error in programming. Proper design of recursion helps prevent it.
29. What is Queue Overflow?
Ans:
Queue overflow occurs when an attempt is made to insert an element into a full queue. It commonly happens in fixed-size queue implementations using arrays. When no space is left, new insertions are not possible. Dynamic queues can help avoid this issue. It is a memory limitation problem in data structures. Proper management of queue size prevents overflow. It ensures stable program execution.
30. What is Circular Queue?
Ans:
A circular queue is a linear data structure where the last position is connected back to the first. It efficiently utilizes memory by reusing empty spaces. It follows the FIFO (First In First Out) principle. It avoids the problem of wasted space in a simple queue. It is commonly used in CPU scheduling and memory management. Insertion and deletion operations are efficient. It improves overall queue performance.
31. What is Deque?
Ans:
A deque (double-ended queue) is a data structure where insertion and deletion can occur at both ends. It is more flexible than a standard queue or stack. It supports operations of both FIFO and LIFO. It is used in sliding window and scheduling problems. It can be implemented using arrays or linked lists. It provides efficient insertion and deletion operations. It is useful in advanced algorithmic problems.
32. What is AVL Tree?
Ans:
An AVL tree is a self-balancing binary search tree. It maintains a balance factor to ensure height differences are minimal. If imbalance occurs, rotations are used to restore balance. This ensures O(log n) time complexity for operations. It is used in databases and indexing systems. It improves search efficiency compared to normal BST. It ensures balanced tree structure at all times.
33. What is Red-Black Tree?
Ans:
A red-black tree is a self-balancing binary search tree with color properties. Each node is colored either red or black. It ensures that the tree remains approximately balanced. It guarantees O(log n) time complexity for operations. It is used in libraries like STL maps and sets. It reduces tree height for efficient operations. It is widely used in real-world applications.
34. Find the largest element in an array?
Ans:
To find the largest element, we traverse the array and compare each element with a maximum variable. Initially, assume the first element is the largest. Then update it whenever a larger value is found. At the end, the maximum variable contains the largest number. This approach ensures one full traversal of the array. It works in O(n) time complexity. It is commonly asked in interviews.
- arr = [10, 5, 20, 8]
- max_val = arr[0]
- for i in arr:
- if i > max_val:
- max_val = i
- print(“Largest element:”, max_val)
35. What is Dynamic Programming?
Ans:
Dynamic programming is an optimization technique used to solve complex problems. It breaks problems into smaller overlapping subproblems. It stores results to avoid recomputation. It uses memoization or tabulation techniques. It is used in problems like knapsack and Fibonacci sequence. It significantly improves time efficiency. It is a key topic in coding interviews.
36. What is Greedy Algorithm?
Ans:
A greedy algorithm makes the best possible choice at each step. It aims to achieve a globally optimal solution. It does not reconsider previous decisions. It is simple and efficient to implement. It is used in problems like minimum spanning tree and scheduling. However, it may not always give the optimal solution. It is useful for optimization problems.
37. What is Backtracking?
Ans:
Backtracking is a problem-solving technique that tries all possible solutions. It abandons paths that do not lead to a valid solution. It uses recursion to explore possibilities. It is used in problems like permutations and puzzles. It reduces unnecessary computation by pruning invalid paths. It is widely used in constraint-based problems. It helps solve complex combinatorial problems.
38. What is Memoization?
Ans:
Memoization is an optimization technique used in dynamic programming. It stores results of expensive function calls. It avoids repeated calculations for the same inputs. It uses a top-down approach with recursion. It improves performance significantly. It requires extra memory for storing results. It is commonly used in recursive algorithms.
39. What is Tabulation?
Ans:
Tabulation is a bottom-up dynamic programming approach. It solves problems by filling a table iteratively. It avoids recursion completely. It starts from base cases and builds solutions step by step. It is more efficient in terms of function call overhead. It is used in optimization problems. It is widely used in DP-based coding problems.
40. How does Reverse a string?
Ans:
Reversing a string means changing the order of characters from last to first. We can use slicing or two-pointer technique. Each character is rearranged in reverse order. This helps understand string manipulation. It is useful in palindrome problems. It runs in O(n) time complexity. It is a basic interview question.
- s = “hello”
- reversed_s = “”
- for i in s:
- reversed_s = i + reversed_s
- print(“Reversed string:”, reversed_s)

Enroll in DSA Certification Course and UPGRADE Your Skills
Weekday / Weekend BatchesSee Batch Details41. What is Subsequence?
Ans:
- A subsequence is a sequence derived from an array by deleting some or no elements without changing order. It does not require elements to be contiguous.
- For example, from [1,2,3], [1,3] is a subsequence. It is widely used in dynamic programming problems. Unlike subarrays, continuity is not required. It is important in LCS problems. It is a key concept in string and array problems
- Subsequence problems help in understanding DP relationships. They are useful in pattern matching problems. They form the basis of many optimization problems.
42. What is Sliding Window Technique?
Ans:
Sliding window is an algorithm used to solve array and string problems efficiently. It maintains a window of elements and slides it across input. It reduces time complexity compared to brute force. It is used in maximum sum subarray problems. It can be fixed or variable size. It improves performance significantly. It is widely used in coding interviews. It helps reduce nested loop complexity. It is useful in real-time stream processing. It is important for optimization problems.
43. What is Two Pointer Technique?
Ans:
Two pointer technique uses two pointers to traverse data efficiently. One pointer starts from beginning and other from end or same direction. It reduces nested loops and improves performance. It is used in sorting and searching problems. It is useful in arrays and linked lists. It helps in solving pair problems efficiently. It is common in interview questions. It reduces time complexity significantly. It is widely used in string problems. It simplifies complex array operations.
44. What is Kadane’s Algorithm?
Ans:
Kadane’s algorithm finds maximum subarray sum efficiently. It uses dynamic programming approach. It keeps track of current and maximum sum. It runs in O(n) time complexity. It avoids brute force nested loops. It is used in array problems. It is very important for interviews. It handles both positive and negative numbers. It is optimal for subarray sum problems. It is widely used in coding challenges.
45. What is Greedy Choice Property?
Ans:
Greedy choice property means making the best choice at each step. It assumes local optimum leads to global optimum. It is used in optimization problems. It does not reconsider previous decisions. It is used in scheduling and graph problems. It is simple and fast approach. It may not always guarantee correct solution. It is used in many approximation algorithms. It works well for structured problems. It reduces computation complexity.
46. What is Minimum Spanning Tree?
Ans:
A minimum spanning tree connects all vertices with minimum edge weight. It is used in weighted graphs. It contains no cycles. It uses algorithms like Prim’s and Kruskal’s. It reduces total connection cost. It is widely used in networking. It is an important graph concept. It ensures minimal connection cost. It is useful in infrastructure design. It is key in graph optimization problems.
47. What is Prim’s Algorithm?
Ans:
Prim’s algorithm finds minimum spanning tree in a graph. It starts from a single vertex. It adds the smallest edge connecting visited and unvisited nodes. It uses a priority queue for efficiency. It ensures no cycles are formed. It is used in network design. It runs in O(E log V). It grows the tree step by step. It is efficient for dense graphs. It is widely used in graph problems.
48. What is Kruskal’s Algorithm?
Ans:
Kruskal’s algorithm builds minimum spanning tree using edges. It sorts all edges by weight. It adds smallest edges without forming cycles. It uses disjoint set (union-find). It is efficient for sparse graphs. It is used in clustering and networking. It ensures minimum cost connection. It processes edges greedily. It is easy to implement. It is widely used in MST problems.
49. What is Dijkstra’s Algorithm?
Ans:
Dijkstra’s algorithm finds shortest path in a weighted graph. It works for non-negative edge weights. It uses a priority queue. It updates shortest distance step by step. It is widely used in maps and GPS systems. It runs in O(E log V). It is an important graph algorithm. It finds optimal paths efficiently. It is used in routing systems. It is a key interview topic.
50. What is Floyd Warshall Algorithm?
Ans:
Floyd Warshall finds shortest paths between all pairs of nodes. It uses dynamic programming approach. It works for weighted graphs. It handles negative edges but not negative cycles. It uses a matrix for storage. Time complexity is O(n³). It is used in dense graphs. It is simple to implement. It computes all-pairs shortest paths. It is useful in network analysis.
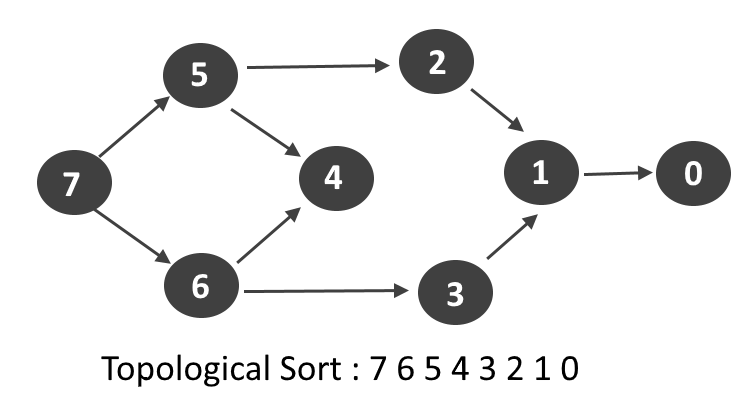
51. What is Topological Sorting?
Ans:
Topological sorting is ordering of vertices in a directed acyclic graph. It ensures dependencies are respected. It is used in task scheduling. It is only possible in DAGs. It uses DFS or Kahn’s algorithm. It is important in project planning. It defines execution order. It ensures dependency resolution. It is widely used in build systems. It is important in compiler design.
52. What is Disjoint Set (Union-Find)?
Ans:
Disjoint set is a data structure that tracks elements in sets. It supports union and find operations. It is used to detect cycles in graphs. It uses path compression for efficiency. It is used in Kruskal’s algorithm. It helps manage connected components. It is very efficient. It merges sets dynamically. It optimizes graph processing. It is widely used in algorithms.
53. What is Segment Tree?
Ans:
Segment tree is a binary tree used for range queries. It allows fast updates and queries. It is used in sum, min, max problems. It works in O(log n) time. It is built from an array. It is used in competitive programming. It improves query efficiency. It handles range operations. It is useful for dynamic arrays. It is important in advanced DSA.
54. What is Fenwick Tree?
Ans:
Fenwick tree is used for prefix sum queries. It is also called Binary Indexed Tree. It allows fast updates and queries. It uses O(log n) time complexity. It is space efficient. It is used in frequency counting. It simplifies range sum problems. It supports cumulative operations. It is easier than segment tree. It is widely used in contests.
55. What is String?
Ans:
A string is a sequence of characters. It is used to represent text data. Strings are immutable in many languages. They support various operations like concatenation and comparison. It is widely used in programming. String problems are common in interviews. It is fundamental data type. It is essential in text processing. It is used in parsing and search. It is core to programming.
56. What is String Matching?
Ans:
String matching finds occurrence of a pattern in text. It is used in search engines. Algorithms include KMP and Rabin-Karp. It improves search efficiency. It reduces brute force comparisons. It is used in text processing. It is important in coding interviews. It optimizes pattern searching. It is used in data analysis. It is essential for text algorithms.
57. Check if a string is a palindrome?
Ans:
A string is a palindrome if it reads the same forward and backward. We compare characters from both ends moving toward the center. If all pairs match, it is a palindrome. Otherwise, it is not. This problem uses the two-pointer technique. It runs in O(n) time complexity. It is frequently asked in interviews.
- s = “madam”
- if s == s[::-1]:
- print(“Palindrome”)
- else:
- print(“Not Palindrome”)
58. What is Rabin-Karp Algorithm?
Ans:
Rabin-Karp uses hashing for string matching. It compares hash values of substrings. It reduces unnecessary comparisons. It works efficiently for multiple patterns. Worst case is O(nm). It is used in plagiarism detection. It is useful in search systems. It uses rolling hash technique. It is effective for multiple searches. It is used in text analysis.
59. What is Brute Force Algorithm?
Ans:
Brute force tries all possible solutions. It is simple but inefficient. It guarantees correct result. It is used as baseline approach. It has high time complexity. It is used when input size is small. It is easy to implement. It checks all possibilities. It is not optimized. It is used for learning concepts.
60. Difference between Stack and Queue?
Ans:
| Feature | Stack | Queue |
|---|---|---|
| Principle | LIFO | FIFO |
| Operation | Push/Pop | Enqueue/Dequeue |
| Access | Top element only | Front & rear |
| Usage | UsageRecursion, backtracking | Scheduling, buffering |

Learn DSA Training with Advanced Concepts By Industry Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
61. What is Back Edge in Graph?
Ans:
Back edge is an edge that connects node to its ancestor in DFS tree. It indicates cycle in graph. It is used in cycle detection. It occurs in directed graphs. It is identified during DFS traversal. It is important in graph theory. It helps detect loops. It shows recursion in graph. It is used in DAG validation. It is important in DFS analysis. It helps identify cyclic dependencies. It is widely used in graph algorithms.
62. What is Forward Edge?
Ans:
Forward edge connects node to its descendant in DFS tree. It is found in directed graphs. It is not part of tree edges. It represents extra connections. It is used in graph analysis. It helps in understanding structure. It is less common than back edges. It shows additional paths. It appears in DFS classification. It is important in graph study. It helps analyze graph connectivity. It improves structural understanding of graphs.
63. What is Tree Traversal?
Ans:
Tree traversal is visiting all nodes in a tree. Methods include inorder, preorder, and postorder. It is used in binary trees. It helps process hierarchical data. It is implemented using recursion. It is important in coding problems. It helps in data extraction. It processes tree systematically. It is fundamental in DSA. It is used in many applications. It helps in searching and updating tree data. It is widely used in real-world systems.
64. What is Inorder Traversal?
Ans:
Inorder traversal visits left, root, then right. It is used in binary search trees. It gives sorted order of elements. It is implemented using recursion. It is widely used in BST operations. It is important in interview problems. It is simple traversal method. It produces ordered output. It is used in expression trees. It is a key traversal technique. It helps retrieve data in sorted form. It is essential in tree-based problems.
65. What is Preorder Traversal?
Ans:
Preorder traversal visits root, left, then right. It is used in tree copying. It processes root first. It is used in expression trees. It is implemented using recursion. It is useful in structure cloning. It is a basic traversal method. It is used in serialization. It is helpful in tree reconstruction. It is important in DSA. It helps in saving tree structure. It is widely used in parsing problems.
66. What is Postorder Traversal?
Ans:
Postorder traversal visits left, right, then root. It is used in deletion operations. It processes children before parent. It is used in expression evaluation. It is implemented recursively. It is useful in tree cleanup. It is important traversal method. It deletes nodes safely. It is used in compilers. It is essential traversal type. It helps in safe memory deletion. It is widely used in recursion-based problems.
67. What is Height of Tree?
Ans:
- Height of tree is longest path from root to leaf. It measures depth of tree. It is important in balancing. It affects performance of operations.
- It is calculated recursively. It is used in AVL trees. It defines tree structure. It shows tree complexity. It impacts efficiency.
- It is key metric in trees. It helps determine tree balance. It is important in performance optimization.
68. What is Depth of Node?
Ans:
- Depth of node is distance from root to that node. It increases as we move down the tree. It is used in tree operations. It helps in level calculations.
- It is important in BFS. It is different from height. It measures node position. It defines node level. It is useful in tree traversal.
- It is basic tree concept. It helps in hierarchy understanding. It is widely used in level-based processing.
69. Find factorial of a number?
Ans:
Factorial of a number is the product of all numbers from 1 to n. It can be calculated using loop or recursion. For example, 5! = 120. If n is 0 or 1, result is 1. This helps understand recursion and iteration. It is a fundamental DSA problem. It runs in O(n) time complexity
- n = 5
- fact = 1
- for i in range(1, n+1):
- fact *= i
- print(“Factorial:”, fact)
70. What is Internal Node?
Ans:
Internal node is a node with at least one child. It is not a leaf node. It connects other nodes in tree. It is important in structure. It helps in traversal operations. It is part of tree hierarchy. It supports data organization. It forms tree backbone. It is used in tree processing. It is important structural node.
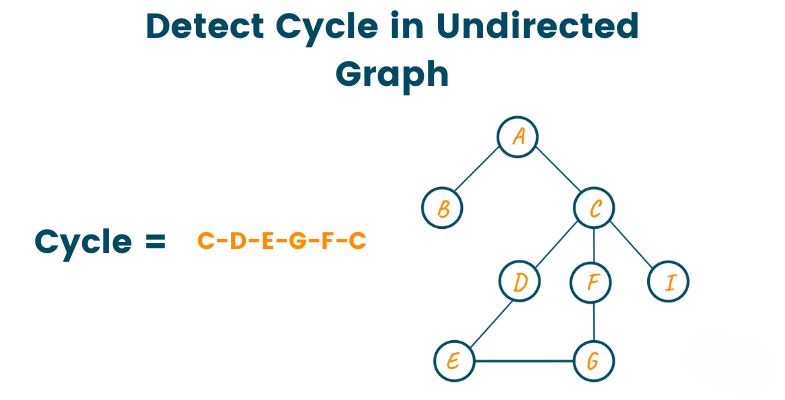
71. What is Cycle Detection in Graph?
Ans:
Cycle detection is the process of finding whether a graph contains a cycle. It is important in both directed and undirected graphs. DFS is commonly used to detect cycles. In directed graphs, back edges indicate cycles. In undirected graphs, visited tracking is used. It helps prevent infinite loops in processing. It is used in dependency resolution systems. Cycle detection ensures graph validity. It is important in scheduling problems. It is widely used in compilers and OS design.
72. What is Strongly Connected Component (SCC)?
Ans:
A strongly connected component is a subgraph where every vertex is reachable from every other vertex. It exists only in directed graphs. Algorithms like Kosaraju and Tarjan are used to find SCCs. SCCs help break graphs into manageable parts. They are used in network analysis. They help detect tightly connected groups. SCCs are important in social networks. They simplify complex graph structures. They are used in dependency analysis. They are key in advanced graph theory.
73. What is Bipartite Graph?
Ans:
A bipartite graph is a graph whose vertices can be divided into two sets. No two vertices within the same set are connected. It is used in matching problems. BFS or DFS is used to check bipartiteness. It is useful in scheduling problems. It helps in job assignment problems. It is widely used in real-world modeling. It is important in graph theory. It is used in network flow problems. It is a key interview topic.
74. What is Union by Rank?
Ans:
Union by rank is an optimization technique in Disjoint Set Union. It attaches smaller tree under larger tree. It reduces tree height. It improves efficiency of union-find operations. It works along with path compression. It ensures nearly constant time complexity. It is used in Kruskal’s algorithm. It avoids deep trees. It improves graph processing speed. It is essential in DSU optimization.
75. What is Path Compression?
Ans:
- Path compression is an optimization in Disjoint Set Union. It flattens the structure of the tree during find operation. It directly connects nodes to root.
- It reduces time complexity significantly. It is used in union-find operations. It works with union by rank. It improves performance of graph algorithms.
- It speeds up repeated queries. It ensures efficient DSU operations. It is widely used in competitive programming.
76. What is Heap Sort?
Ans:
Heap sort is a comparison-based sorting algorithm. It uses a heap data structure. First, a heap is built from input data. Then largest element is repeatedly extracted. It has O(n log n) time complexity. It is not a stable sort. It works in-place. It is used in system-level applications. It is efficient for large datasets. It is based on binary heap.
77. Find a Fibonacci series generation?
Ans:
Fibonacci series is a sequence where each number is sum of previous two numbers. It starts with 0 and 1. We generate values using iteration or recursion. It is widely used in dynamic programming. Recursive approach is slow, iterative is efficient. Time complexity is O(n). It is common in coding interviews.
- n = 10
- a, b = 0, 1
- for i in range(n):
- print(a, end=” “)
- a, b = b, a + b
78. What is Counting Sort?
Ans:
Counting sort is a non-comparison-based sorting algorithm. It counts frequency of each element. It works for integer range data. It has O(n + k) time complexity. It is very efficient for small ranges. It is stable sorting algorithm. It is used in radix sort. It requires extra memory. It is not suitable for large ranges. It is simple and fast.
79. What is Bit Manipulation?
Ans:
Bit manipulation involves operations on binary bits. It uses AND, OR, XOR, NOT operators. It is used for optimization problems. It is very fast and efficient. It is used in cryptography. It is useful in low-level programming. It reduces memory usage. It solves problems like subsets. It is important in competitive programming. It improves performance.
80. What is XOR Property?
Ans:
XOR is a bitwise operator with special properties. A XOR A equals zero. A XOR 0 equals A. It is used in finding unique elements. It is used in swapping numbers. It is efficient in coding problems. It helps in detecting duplicates. It is widely used in algorithms. It simplifies bit manipulation tasks. It is important in interviews.
81. What is Prefix Sum?
Ans:
Prefix sum is a technique used to preprocess array sums. It stores cumulative sum of elements. It helps answer range sum queries efficiently. It reduces time complexity. It is used in array problems. It is useful in sliding window problems. It is simple to implement. It avoids repeated calculations. It is widely used in competitive programming. It improves query efficiency.
82. What is Suffix Sum?
Ans:
- Suffix sum stores cumulative sum from end of array. It is opposite of prefix sum. It helps in range query problems. It reduces computation time.
- It is useful in optimization problems. It is used in DP problems. It simplifies array processing. It improves efficiency. It is important in coding interviews.
- It is easy to implement. It is useful for reverse range calculations. It helps in fast query answering problems.
83. What is Matrix Traversal?
Ans:
Matrix traversal means visiting all elements in a matrix. It can be row-wise or column-wise. It is used in image processing. BFS and DFS are used in grid problems. It is important in path finding. It is used in maze problems. It is widely used in DSA. It helps in grid-based problems. It is important for interviews. It is fundamental concept. It helps in exploring 2D structures. It is used in many real-world applications.
84. What is Spiral Traversal?
Ans:
Spiral traversal visits matrix elements in spiral order. It starts from outer layer. It moves inward layer by layer. It is used in matrix problems. It requires boundary tracking. It is used in coding interviews. It is slightly complex traversal. It helps in pattern-based problems. It is important in arrays. It improves problem-solving skills. It helps in understanding boundary conditions. It is useful in matrix manipulation problems.
85. What is Submatrix?
Ans:
A submatrix is a smaller matrix within a larger matrix. It contains contiguous rows and columns. It is used in matrix problems. It is similar to subarray in arrays. It is used in DP problems. It helps in image processing. It is important in grid problems. It is used in optimization problems. It is widely used in interviews. It is key concept in matrices. It helps in region-based calculations. It is useful in advanced matrix problems.
86. What is Backtracking in N-Queens?
Ans:
- N-Queens is a backtracking problem. It places queens on chessboard safely. No two queens attack each other. It uses recursion and pruning.
- It explores all configurations. It backtracks on invalid placements. It is classic interview problem. It demonstrates recursion power.
- It is important in combinatorics. It improves problem-solving skills. It helps in constraint satisfaction problems. It is widely used in competitive programming.
87.Find missing number in array (1 to n)
Ans:
We are given numbers from 1 to n with one missing element. We use sum formula n(n+1)/2 to find expected sum. Then subtract actual array sum. The difference is missing number. This is an efficient mathematical approach. It avoids extra space usage. It runs in O(n) time complexity.
- arr = [1, 2, 4, 5]
- n = 5
- expected_sum = n * (n + 1) // 2
- actual_sum = sum(arr)
- missing = expected_sum – actual_sum
- print(“Missing number:”, missing)
88. What is Sudoku Solver?
Ans:
Sudoku solver uses backtracking technique. It fills empty cells with valid numbers. It ensures row, column, and grid rules. It tries all possibilities. It backtracks if invalid. It is classic constraint problem. It uses recursion. It is used in puzzles. It is important interview problem. It demonstrates backtracking well.
89. What is Permutation?
Ans:
Permutation is arrangement of elements in different orders. It is used in combinatorics. It generates all possible arrangements. It uses recursion and backtracking. It is important in DP problems. It is used in string problems. It is widely used in interviews. It helps in problem-solving. It is fundamental concept. It is useful in mathematics.
90. What is Combination?
Ans:
Combination is selection of elements without order. It differs from permutation. It is used in subset problems. It uses recursion. It is important in probability. It is widely used in coding interviews. It generates subsets. It is used in mathematical problems. It is key concept in DSA. It helps in decision problems.
91. What is Subset?
Ans:
A subset is any set formed from original set elements. It may include empty set. It includes all possible combinations. It is used in recursion problems. It is important in DP. It is widely used in interviews. It helps in combinatorics. It is fundamental concept. It is used in bit manipulation. It is key in problem solving. It helps in generating all possible solutions. It is widely used in backtracking problems.
92. What is Bit Masking?
Ans:
Bit masking is technique using bits to represent data. It is used for subsets. It improves efficiency. It uses binary representation. It is fast and memory efficient. It is used in DP problems. It is used in optimization. It is widely used in contests. It simplifies subset generation. It is important in advanced DSA. It helps in state representation. It is useful in combinatorial problems.
93. What is Floyd Cycle Detection?
Ans:
Floyd cycle detection finds cycle in linked list. It uses slow and fast pointers. Fast moves two steps, slow moves one step. If they meet, cycle exists. It is efficient algorithm. It uses O(1) space. It is used in linked lists. It is important interview question. It is also called tortoise and hare. It is widely used. It helps detect loops efficiently. It is used in many pointer problems.
94. What is LRU Cache?
Ans:
LRU cache removes least recently used items. It uses hashmap and doubly linked list. It supports fast operations. It is used in memory management. It improves performance. It has O(1) operations. It is used in operating systems. It is important system design topic. It is widely asked in interviews. It optimizes caching systems. It improves access speed. It is used in real-time applications.
95. What is Stack Using Queue?
Ans:
- Stack using queue implements stack behavior using queues. It simulates LIFO using FIFO. It uses two queues. It is used for learning data structures.
- It supports push and pop operations. It is inefficient compared to stack. It is used in interview questions. It improves conceptual understanding.
- It is important DSA topic. It shows data structure transformation. It helps understand internal mechanics. It is useful for academic learning.
96. What is Queue Using Stack?
Ans:
Queue using stack implements queue using stacks. It simulates FIFO using LIFO. It uses two stacks. It is used in coding interviews. It supports enqueue and dequeue operations. It is less efficient than queue. It helps understand stack behavior. It is important concept. It improves problem-solving skills. It is widely asked question. It helps in understanding reversals. It is used in implementation-based problems.
97. What is Monotonic Stack?
Ans:
- Monotonic stack maintains increasing or decreasing order. It is used in next greater element problems. It helps optimize solutions.
- It uses stack data structure. It reduces time complexity. It is used in histogram problems. It is important in arrays. It is widely used in interviews.
- It simplifies comparison problems. It is efficient technique. It helps in range-based optimizations. It is widely used in stack problems.
98. What is Next Greater Element?
Ans:
- Next greater element finds next larger value for each element. It uses monotonic stack. It processes array efficiently. It avoids nested loops.
- It is used in stock span problems. It is important in arrays. It runs in O(n) time. It is common interview question.
- It improves problem-solving skills. It is widely used technique. It helps in nearest greater queries. It is used in optimization problems.
99. What is Stock Span Problem?
Ans:
Stock span problem finds consecutive smaller prices before current day. It uses stack data structure. It is used in financial analysis. It calculates stock trends. It is solved using monotonic stack. It reduces time complexity. It is important interview problem. It is widely asked in coding rounds. It helps in real-world applications. It is efficient algorithm. It helps analyze market trends. It is used in financial prediction systems.
100. What is Interview Strategy for DSA?
Ans:
DSA interview strategy involves understanding fundamentals clearly. Practice arrays, strings, trees, and graphs regularly. Focus on time and space complexity. Learn common patterns like sliding window and DP. Solve coding problems daily. Revise important algorithms frequently. Stay consistent with practice. Focus on problem-solving approach. Communicate logic clearly in interviews. Practice mock interviews for confidence.




