
Last updated on 23rd Apr 2024| 10216
COMPILER DESIGN
Compiler design involves creating software that translates high-level programming languages into machine code that computers can execute. It typically consists of several phases, including lexical analysis, syntax analysis, semantic analysis, code generation, and optimization. Each phase analyzes and transforms the source code into a form that can be executed efficiently by the target machine.
1. What is a compiler?
Ans:
A compiler is a software tool that translates high-level programming language code into low-level machine code or bytecode that a computer can execute. It takes human-readable code written in a high-level programming language like C, Java, or Python. It translates it into instructions that a computer’s processor can understand and execute directly. This translation process involves multiple steps, including lexical analysis, syntax analysis, semantic analysis, optimization, and code generation. The result is an executable file that can be run on a computer without needing the source code.
2. What are the main phases of a compiler?
Ans:
- Lexical Analysis
- Syntax Analysis
- Semantic Analysis
- Intermediate Code Generation
- Code Optimization
- Code Generation
- Symbol Table Management
3. Explain lexical analysis in compiler design.
Ans:
Lexical analysis is the first phase of a compiler. It involves scanning the source code to recognize and categorize the individual tokens (such as keywords, identifiers, constants, and operators) based on the language’s lexical rules. The output of this phase is a stream of tokens. The lexer, or lexical analyzer, reads the input character by character and groups them into tokens according to the language’s syntax rules. This process simplifies the subsequent phases of the compiler, like parsing and semantic analysis.
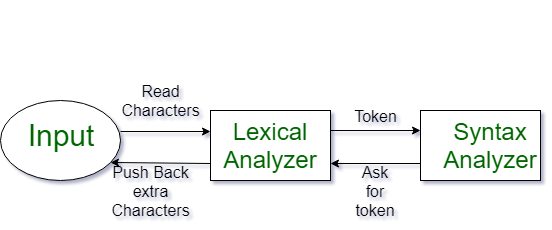
4. Describe syntax analysis in compiler design.
Ans:
- Syntax analysis, also known as parsing, is the second phase of a compiler.
- It involves analyzing the structure of the source code to ensure that it conforms to the grammar rules of the programming language.
- This phase typically produces a parse tree or abstract syntax tree (AST) representing the syntactic structure of the code.
- This structure helps in understanding the relationships and dependencies between different parts of the code.
- If the input does not adhere to the language’s syntax rules, the parser reports errors. Syntax analysis lays the foundation for subsequent phases like semantic analysis and code generation.
5. What is semantic analysis, and why is it important?
Ans:
Semantic analysis is the third phase of a compiler. It involves checking the meaning of the source code beyond its syntax, such as type checking, scope resolution, and detecting semantic errors. This phase ensures that the code behaves correctly according to the language’s semantics. It involves deciphering the intended message, context, and relationships between words to extract useful information. It’s crucial because it helps machines comprehend human language, enabling tasks like sentiment analysis, language translation, and information retrieval.
6. Explain code generation in compiler design.
Ans:
Code generation is the fourth phase of a compiler. It involves translating the high-level intermediate representation (such as AST or intermediate code) into low-level machine code or bytecode that the target platform can execute. Code generation optimizes performance and ensures the generated code behaves correctly according to the semantics of the source language.
7. What is optimization in compiler design?
Ans:
Optimization is the process of improving the efficiency and performance of the generated code without changing its functionality. Compiler optimization techniques include dead code elimination, constant folding, loop optimization, and register allocation. Optimization can be performed at different levels, such as during code generation or as a separate phase after code generation. Some common optimization techniques include loop optimization, constant folding, register allocation, and dead code elimination.
8. Describe the difference between compiler and interpreter.
Ans:
| Aspect | Compiler | Interpreter |
|---|---|---|
| Operation | Translates entire source code into machine code before execution | Translates and executes code line-by-line |
| Performance | Generally produces faster executable code | Typically slower as it interprets code in real-time |
| Error Detection | All errors are detected before execution | Errors are detected during execution |
9. What are the advantages of using an intermediate representation (IR) in compiler design?
Ans:
Using an intermediate representation (IR) simplifies the design of a compiler by separating the front end (analysis phases) from the back end (code generation and optimization phases). It enables modular design, facilitates language-independent optimizations, and makes it easier to target multiple platforms.
10. Explain the concept of register allocation in compiler optimization.
Ans:
Register allocation is the process of assigning variables and temporary values to processor registers to minimize memory accesses and improve execution speed. Compiler optimization techniques such as graph colouring and linear scan are commonly used to allocate registers efficiently.
11. What is a symbol table, and why is it used in compiler design?
Ans:
A symbol table is a data structure used by compilers to store information about identifiers (such as variables, functions, and types) encountered in the source code. It typically stores attributes such as name, type, scope, and memory location and is used during various phases of compilation for symbol resolution and semantic analysis.
12. Explain the concept of lexical scope and dynamic scope in programming languages.
Ans:
Lexical scope, also known as static scope, determines the visibility and accessibility of identifiers based on their lexical context in the source code. Dynamic scope, on the other hand, determines visibility based on the runtime call stack. Most modern programming languages use lexical scope for its predictability and ease of reasoning.
13. What are the different types of errors detected during semantic analysis in compiler design?
Ans:
Semantic analysis commonly identifies the following categories of errors:
- Type Errors: Occur when operations are applied to incompatible data types (e.g., adding a string to an integer).
- Undeclared Variables: This happens when variables or functions are used without being declared.
- Scope Errors: Arise when variables are accessed outside their scope or context.
- Function Signature Mismatches: Occur if a function has incorrect parameters or return types.
- Type Mismatches: Involve discrepancies between expected and actual types in expressions or assignments.
14. Explain the role of a parser generator in compiler design.
Ans:
A parser generator is a tool that automatically creates a parser based on a given grammar. It simplifies implementing the syntax analysis phase of a compiler by generating code that can analyze and parse the source code according to the grammar rules. The source code is then processed further during the compilation process using the parse tree or abstract syntax tree produced by this created parser.
15. What is an abstract syntax tree (AST), and how is it used in compiler design?
Ans:
The abstract syntactic structure of source code is represented as a tree via an abstract syntax tree (AST). Every node in the AST represents a construct or operation in the code, such as expressions, statements, or declarations. In compiler design, the AST is used for:
- Semantic Analysis: To check for semantic errors and ensure correct usage of language constructs.
- Optimization: The process of changing and refining the code.
- Code Generation: Using the high-level source code, produce intermediate or final code.
16. Explain the difference between top-down and bottom-up parsing techniques.
Ans:
- Top-Down Parsing: This technique works its way down to the leaves of the parse tree. Expanding non-terminals from the start symbol attempts to match the input text with the grammar rules. Predictive parsing and recursive descent parsing are standard techniques.
- Bottom-Up Parsing: This method ascends to the parse tree’s root by working from the leaves or input tokens. By grammatical rules, it reduces the input tokens to non-terminals. LR parsing and shift-reduce parsing are examples of standard techniques.
17. What are attribute grammars, and how are they used in compiler design?
Ans:
Attribute grammars extend context-free grammars by attaching attributes to grammar symbols and defining rules for computing these attributes. They are used in compiler design for:
- Semantic Analysis: To evaluate and propagate type checking, variable binding, and scope resolution information.
- Syntax-directed Translation: To generate intermediate code or perform transformations based on the attributes.
18. Explain the concept of code optimization in compiler design.
Ans:
Code optimization involves improving the efficiency of generated code without altering its output. This can include:
- Reducing Execution Time: Optimizing loops, eliminating redundant computations, and enhancing instruction scheduling.
- Minimizing Memory Usage: Through techniques like dead code elimination and loop fusion.
- Enhancing Performance: By applying various transformations to make code run faster and use resources more effectively.
19. What is loop optimization, and why is it important in compiler design?
Ans:
Loop optimization refers to a set of techniques aimed at improving the performance of loops in the generated code. Since loops often account for a significant portion of program execution time, optimizing them can lead to substantial performance gains. Techniques include loop unrolling, loop fusion, loop interchange, and loop-invariant code motion.
20. Explain the concept of data flow analysis in compiler optimization.
Ans:
Data flow analysis is used to gather information about data flow through a program. It involves analyzing how data values move and change across different program parts. This information is used to:
- Optimize Code: By identifying redundant calculations, unused variables, and opportunities for better resource utilization.
- Perform Optimization Tasks, including constant propagation, dead code elimination, and live variable analysis.
21. What is the difference between static and dynamic type checking in programming languages?
Ans:
Static type checking is performed at compile time and ensures that the types of variables and expressions are compatible according to the language’s type system. Dynamic type checking, on the other hand, is performed at runtime and checks the types of values as they are used, often resulting in more flexible but potentially less efficient code.
22. Explain the role of a lexer in compiler design and its relationship with the parser.
Ans:
A lexer, or lexical analyzer, breaks down the source code into tokens, which are the basic building blocks of syntax (such as keywords, operators, and identifiers). The lexer performs a linguistic analysis to identify and classify these tokens. The parser then uses these tokens to build a syntactic structure (like a parse tree or abstract syntax tree) based on the language’s grammar rules. The lexer and parser transform the source code into a structured representation for further processing.
23. What are context-free grammars, and why are they used in compiler design?
Ans:
Context-free grammars (CFGs) are formal representations of programming languages’ syntax rules. They consist of a set of production rules that define how valid sentences (or programs) can be constructed from the language’s terminal and non-terminal symbols. CFGs are used in compiler design to define programming languages’ syntactic structure and guide the parsing process.
24. Explain the concept of leftmost derivation and its relevance in parsing algorithms.
Ans:
The leftmost derivation is a process of applying production rules in a CFG from the start symbol to generate a sentence by replacing the leftmost non-terminal symbol at each step. The leftmost derivation is relevant in parsing algorithms such as LL parsing, where it serves as the basis for constructing parse tables and determining the parsing strategy.
25. What is the difference between syntax-directed translation and semantic analysis in compiler design?
Ans:
Syntax-directed translation is a technique where translation rules are associated with grammar productions to guide the generation of code or intermediate representations during parsing. Semantic analysis, on the other hand, involves checking the meaning of the source code beyond its syntax, such as type checking and scope resolution, to ensure its correctness.
26. Explain the concept of abstract interpretation and its application in compiler optimization.
Ans:
Abstract interpretation is a formal method for analyzing program behaviour by approximating its semantics using abstract domains. In compiler optimization, abstract interpretation can be used to perform static analysis of program properties such as program invariants, reachability analysis, and pointer analysis, which can aid in identifying optimization opportunities.
27. What is the role of a code generator in compiler design, and how does it differ from an interpreter?
Ans:
A code generator is responsible for translating the intermediate representation of a program into executable machine code or bytecode. Unlike an interpreter, which executes the source code directly, a code generator produces machine-executable code that can be executed independently of the compiler or interpreter, resulting in potentially faster execution.
28. Explain the concept of register allocation and spill code in compiler optimization.
Ans:
Register allocation is the process of assigning variables and temporary values to processor registers to minimize memory accesses and improve performance. Spill code refers to code generated by the compiler to store variables in memory when there are not enough available registers for allocation. Compiler optimization techniques such as graph colouring and register allocation heuristics are used to minimize the need for spill code.
29. What are control-flow and data-flow analysis, and how are they used in compiler optimization?
Ans:
Control-flow analysis studies the flow of control within a program, such as loops, conditionals, and function calls, to identify basic blocks and control-flow paths. Data-flow analysis, on the other hand, analyzes how data values propagate through a program to identify dependencies and opportunities for optimization. Both analyses are used in compiler optimization to improve code quality and performance.
30. Explain the concept of loop parallelization in compiler optimization and its benefits.
Ans:
- Loop parallelization is a compiler optimization technique that transforms sequential loops into parallel ones to exploit concurrency and improve performance on multicore processors.
- It involves identifying loops that can be executed concurrently without violating data dependencies or program semantics and generating parallel code to execute them simultaneously.
- Loop parallelization can lead to significant speedups in programs with computationally intensive loops.
31. What is the significance of the Three-Address Code (TAC) representation in compiler design?
Ans:
Three-address code (TAC) is an intermediate representation (IR) used in compiler design to simplify code generation and optimization. It represents instructions with at most three operands, making it easier to analyze and transform during subsequent compiler phases. TAC provides a structured and uniform representation of the program that facilitates optimization and target code generation.
32. Explain the concept of common subexpression elimination in compiler optimization.
Ans:
Common subexpression elimination is a compiler optimization technique aimed at reducing redundant computations by identifying and eliminating repeated expressions that produce the same result within a program. By recognizing and replacing such expressions with a single computation, common subexpression elimination can reduce both execution time and code size.
33. What are the advantages and disadvantages of using static single assignment (SSA) forms in compiler?
Ans:
- Static Single Assignment (SSA) form is an intermediate representation (IR) used in compiler optimization to simplify data-flow analysis and facilitate optimization transformations.
- Its advantages include improved optimization opportunities, simpler analysis algorithms, and better register allocation.
- However, maintaining the SSA form may incur additional memory and compilation overhead, and some transformations may require additional complexity.
34. Explain the concept of loop unrolling in compiler optimization and its impact on performance.
Ans:
Loop unrolling is a compiler optimization technique that replicates loop bodies multiple times to reduce loop overhead and increase instruction-level parallelism. By replacing loop control overhead with additional loop body instructions, loop unrolling can improve instruction pipelining and reduce branch mispredictions, leading to enhanced performance, especially on architectures with deep pipelines.
35. What is function inlining, and how does it contribute to compiler optimization?
Ans:
Function inlining is a compiler optimization technique that replaces a function call with the body of the called function, eliminating the overhead associated with function invocation. By eliminating the call overhead and enabling additional optimization opportunities, such as constant propagation and dead code elimination, function inlining can improve code performance and reduce code size.
36. Explain the concept of loop fusion in compiler optimization and its benefits.
Ans:
Loop fusion is a compiler optimization technique that combines multiple consecutive loops into a single loop to reduce loop overhead and improve memory locality. By merging loop bodies and iterating over multiple loop nests simultaneously, loop fusion can eliminate redundant loop control overhead and enable more efficient memory access patterns, leading to improved performance.
37. What is loop interchange, and how does it contribute to compiler optimization?
Ans:
Loop interchange is a compiler optimization technique that swaps the nesting order of loops to improve data locality and enable other optimization transformations. By reordering loop nests, loop interchange can enhance cache utilization, reduce memory access latency, and facilitate subsequent optimizations such as loop fusion and vectorization.
38. Explain the concept of loop vectorization in compiler optimization and its impact on performance.
Ans:
- Loop vectorization is a compiler optimization technique that transforms scalar loops into vectorized loops to exploit the parallelism offered by SIMD (Single Instruction, Multiple Data) architectures.
- By grouping multiple iterations of a loop into vector operations, loop vectorization can increase instruction-level parallelism and improve performance on architectures with vector processing capabilities.
39. What are loop-invariant code motion and loop-carried dependency, and how do they relate to compiler?
Ans:
Loop-invariant code motion is a compiler optimization technique that hoists loop-invariant computations out of loops to reduce redundant computations and improve performance. Loop-carried dependency refers to dependencies between iterations of a loop that prevent certain optimizations, such as loop vectorization. Loop-invariant code motion can help break loop-carried dependencies by moving invariant computations outside the loop, enabling further optimization transformations.
40. Explain the concept of software pipelining in compiler optimization and its benefits.
Ans:
Software pipelining is a compiler optimization technique that overlaps the execution of loop iterations to exploit instruction-level parallelism and reduce loop overhead. By scheduling loop iterations in a pipeline fashion, software pipelining can minimize loop initiation and termination overhead, increase instruction throughput, and improve performance on pipelined architectures.

Get JOB Compiler design Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. What is loop tiling (loop blocking), and how does it contribute to compiler optimization?
Ans:
Loop tiling, also known as loop blocking, is a compiler optimization technique that partitions loops into smaller tiles or blocks to improve data locality and cache utilization. By processing data in smaller, contiguous chunks, loop tiling reduces memory access latency, enhances cache efficiency, and enables better exploitation of hardware prefetching, resulting in improved performance.
42. Explain the concept of loop nest optimization in compiler optimization and its significance.
Ans:
- Loop nest optimization is a compiler optimization technique that optimizes the execution of nested loops by reordering, transforming, and parallelizing loop nests to improve performance.
- By analyzing loop nests and applying transformations such as loop interchange, loop fusion, and loop distribution, loop nest optimization aims to maximize parallelism, minimize loop overhead, and enhance cache locality, leading to better performance.
43. What are loop bounds and loop trip counts, and why are they important in compiler optimization?
Ans:
Loop bounds and loop trip counts represent the range of loop iterations and the number of times a loop is executed, respectively. They are essential for compiler optimization as they determine loop optimization opportunities, such as loop unrolling, loop vectorization, and loop interchange. Accurate analysis of loop bounds and trip counts enables compilers to apply optimizations effectively and improve program performance.
44. Explain loop induction variable elimination and its role in compiler optimization.
Ans:
Loop induction variable elimination is a compiler optimization technique that eliminates redundant loop counters (induction variables) by replacing them with equivalent expressions derived from other loop variables. By eliminating unnecessary loop variables, loop induction variable elimination simplifies loop structures, reduces register pressure, and enables further optimization transformations, such as loop unrolling and loop fusion.
45. What is loop parallelism, and how does it differ from task parallelism in compiler optimization?
Ans:
Loop parallelism refers to the parallel execution of loop iterations on multiple processing units to exploit parallelism within a single loop. Task parallelism, on the other hand, involves the concurrent execution of independent tasks or functions that may or may not be part of a loop. While loop parallelism focuses on exploiting parallelism within loop bodies, task parallelism targets parallelism at the task level, offering broader parallelization opportunities.
46. Explain the concept of automatic parallelization in compiler optimization and its challenges.
Ans:
Automatic parallelization is a compiler optimization technique that automatically identifies and transforms sequential code into parallel code to exploit multicore and multiprocessor architectures. Challenges in automatic parallelization include:
- Accurately detecting parallelism.
- Handling loop-carried dependencies.
- Ensuring load balance across processing units.
- Minimizing synchronization overhead.
Despite these challenges, automatic parallelization can significantly improve performance on parallel hardware platforms.
47. What is loop trip count estimation, and why is it important in compiler optimization?
Ans:
Loop trip count estimation is the process of predicting the number of iterations a loop will execute at runtime. It is important in compiler optimization for guiding loop optimization decisions, such as loop unrolling, loop vectorization, and loop fusion. Accurate trip count estimation helps compilers generate efficient code and avoid unnecessary optimizations that may degrade performance or increase code size.
48. Explain the concept of loop skewing in compiler optimization and its benefits.
Ans:
Loop skewing is a compiler optimization technique that adjusts the loop iteration space to improve parallelism and data locality. By skewing the loop index variables, loop skewing redistributes loop iterations and changes the loop execution order, enabling better exploitation of parallelism and cache locality, especially in nested loop structures. Loop skewing can lead to improved performance on architectures with irregular memory access patterns or complex dependencies.
49. What is loop reordering, and how does it contribute to compiler optimization?
Ans:
Loop reordering is a compiler optimization technique that changes the order of loop nests or loop iterations to improve data locality, reduce loop overhead, and enhance parallelism. By analyzing loop dependencies and access patterns, loop reordering rearranges loop structures to optimize cache utilization, minimize loop-carried dependencies, and enable more efficient parallel execution, leading to improved performance.
50. Explain the concept of loop interchange in compiler optimization and its benefits.
Ans:
Loop interchange is a compiler optimization technique that swaps the order of nested loops to improve data locality and enable further optimizations. By changing the loop nesting order, loop interchange can enhance cache utilization, reduce memory access latency, and facilitate other transformations such as loop fusion and vectorization. This optimization is particularly beneficial for improving performance on architectures with hierarchical memory systems.
51. What are loop fusion and loop distribution, and how do they contribute to compiler optimization?
Ans:
- Loop fusion combines multiple loops into a single loop to reduce loop overhead and improve memory locality.
- By merging loop bodies, loop fusion eliminates redundant loop control overhead and enables more efficient memory access patterns, leading to improved performance. Loop distribution, on the other hand, splits a loop into multiple loops to enhance parallelism and facilitate vectorization or parallel execution.
- Both techniques contribute to optimizing loop structures and improving program performance.
52. Explain loop unswitching in compiler optimization and its significance.
Ans:
Loop unswitching is a compiler optimization technique that moves conditional expressions outside the loop to eliminate redundant evaluations and improve performance. By hoisting conditional expressions that do not change within the loop outside the loop body, loop unswitching reduces the overhead of conditional branches and enables better compiler optimizations, such as loop invariant code motion and loop vectorization, leading to enhanced performance.
53. What is loop-invariant code motion, and how does it contribute to compiler optimization?
Ans:
Loop-invariant code motion is a compiler optimization technique that moves computations that do not change across loop iterations outside the loop to eliminate redundant computations and improve performance. By identifying loop-invariant expressions and hoisting them outside the loop, loop-invariant code motion reduces computation redundancy, memory access overhead, and register pressure, leading to faster and more efficient code execution.
54. Explain loop blocking (tiling) in compiler optimization and its benefits.
Ans:
- Loop blocking, also known as loop tiling, partitions loops into smaller blocks or tiles to improve cache locality and enhance parallelism.
- By processing data in smaller, contiguous chunks, loop blocking reduces cache misses, improves memory access patterns, and enables better exploitation of parallelism, leading to improved performance on modern architectures with hierarchical memory systems and multiple processing units.
55. What is loop vectorization, and how does it contribute to compiler optimization?
Ans:
Loop vectorization is a compiler optimization technique that transforms scalar loops into vectorized loops to exploit the parallelism offered by SIMD (Single Instruction, Multiple Data) architectures. By grouping multiple loop iterations into vector operations, loop vectorization increases instruction-level parallelism, reduces loop overhead, and improves performance on architectures with vector processing capabilities, such as modern CPUs and GPUs.
56. Explain loop nest optimization and its relevance in compiler optimization.
Ans:
Loop nest optimization is a compiler optimization technique that optimizes the execution of nested loops to improve performance. By analyzing loop nests and applying transformations such as loop interchange, loop fusion, and loop distribution, loop nest optimization aims to maximize parallelism, minimize loop overhead, and enhance cache locality, leading to better performance on modern computer architectures.
57. What are loop fusion and loop fusion barriers, and how do they affect compiler optimization?
Ans:
Loop fusion combines multiple loops into a single loop to reduce loop overhead and improve memory locality. Loop fusion barriers, also known as synchronization points, are statements or operations that prevent the fusion of adjacent loops due to dependencies or control flow constraints. Loop fusion and loop fusion barriers influence compiler optimization by affecting loop structure, data locality, and parallelism, impacting program performance accordingly.
58. Explain loop skewing and its role in compiler optimization.
Ans:
Loop skewing is a compiler optimization technique that adjusts the loop iteration space to improve parallelism and data locality. By skewing the loop index variables, loop skewing redistributes loop iterations and changes the loop execution order, enabling better exploitation of parallelism and cache locality, especially in nested loop structures. Loop skewing plays a crucial role in optimizing loop performance on modern computer architectures.
59. What are loop nest parallelization and loop thread scheduling, and how do they aid in compiler?
Ans:
Loop nest parallelization is a compiler optimization technique that parallelizes nested loops to exploit parallelism within loop nests. Loop thread scheduling, on the other hand, involves scheduling loop iterations onto threads for concurrent execution on multicore or multiprocessor architectures. Both techniques contribute to compiler optimization by maximizing parallelism, reducing loop overhead, and improving performance on parallel hardware platforms.
60. Explain loop fusion in compiler optimization and its impact on performance.
Ans:
Loop fusion is a compiler optimization technique that merges multiple loops with compatible iteration spaces into a single loop. By combining loop bodies, loop fusion reduces loop overhead and improves memory locality, leading to better cache utilization and reduced memory access latency. This optimization can significantly improve performance, especially on architectures with limited cache capacity or high memory access latency.

Develop Your Skills with Compiler Design Certification Training
Weekday / Weekend BatchesSee Batch Details61. What is loop invariant hoisting, and why is it important in compiler optimization?
Ans:
Loop invariant hoisting is a compiler optimization technique that moves computations that produce the same result in every iteration of a loop outside the loop body. By hoisting loop-invariant expressions outside the loop, loop-invariant hoisting eliminates redundant computations, reduces loop overhead, and improves performance. This optimization is important for minimizing computation redundancy and improving code efficiency.
62. Explain loop unrolling in compiler optimization and its benefits.
Ans:
Loop unrolling is a compiler optimization technique that replicates loop bodies multiple times to reduce loop overhead and improve instruction-level parallelism. By expanding loop iterations into multiple copies of the loop body, loop unrolling increases the ratio of computation to loop control overhead improves instruction pipelining, and enhances performance, especially on architectures with deep pipelines or instruction-level parallelism.
63. How does loop blocking (tiling) contribute to improving cache locality?
Ans:
Loop blocking, also known as loop tiling, partitions loops into smaller blocks or tiles to improve cache locality and reduce cache misses. By processing data in smaller, contiguous chunks, loop blocking enhances data reuse, reduces memory access latency, and improves cache utilization. This optimization improves performance by exploiting spatial and temporal locality and minimizing memory access overhead.
64. Explain loop interchange in compiler optimization and its impact on improving memory access patterns.
Ans:
Loop interchange is a compiler optimization technique that swaps the order of nested loops to improve memory access patterns and cache locality. By changing the loop nesting order, loop interchange reorders memory accesses, enhances spatial locality, and reduces memory access latency. This optimization facilitates better cache utilization and more efficient memory access patterns, leading to improved performance.
65. What is loop peeling in compiler optimization, and why is it useful?
Ans:
Loop peeling is a compiler optimization technique that removes a fixed number of iterations from the beginning or end of a loop to handle boundary conditions or special cases more efficiently. By peeling off iterations, loop peeling reduces branch mispredictions, eliminates unnecessary computations, and simplifies loop execution, leading to improved performance, especially in cases where loop overhead dominates execution time.
66. Explain loop induction variable substitution and its significance in compiler optimization.
Ans:
Loop induction variable substitution is a compiler optimization technique that replaces loop index variables with equivalent expressions derived from other loop variables. By substituting loop index variables with loop-invariant expressions or other loop variables, loop induction variable substitution simplifies loop structures, reduces register pressure, and enables further optimization transformations, leading to improved performance.
67. What is loop strength reduction, and how does it contribute to compiler optimization?
Ans:
- Loop strength reduction is a compiler optimization technique that replaces expensive arithmetic expressions inside loops with cheaper equivalents to reduce computational overhead.
- By transforming complex expressions into simpler forms, loop strength reduction reduces the number of arithmetic operations executed per iteration, improves instruction-level parallelism, and enhances performance, especially on architectures with limited computational resources.
68. Explain loop nest fusion in compiler optimization and its impact on performance.
Ans:
Loop nest fusion is a compiler optimization technique that merges multiple nested loops into a single loop to reduce loop overhead and improve memory locality. By combining loop nests, loop nest fusion eliminates redundant loop control overhead, improves cache utilization, and enhances data locality. This leads to improved performance, especially in cases where nested loops dominate execution time.
69. What is loop parallelization, and how does it differ from loop vectorization in compiler optimization?
Ans:
Loop parallelization is a compiler optimization technique that parallelizes loops to exploit parallelism across multiple processing units, such as CPU cores or SIMD units. Loop vectorization, on the other hand, transforms scalar loops into vectorized loops to exploit parallelism within a single processing unit, such as a CPU or GPU. While loop parallelization targets parallelism across multiple loops, loop vectorization focuses on exploiting parallelism within individual loops, offering different optimization opportunities and performance benefits.
70. Explain loop vectorization in compiler optimization and its impact on performance.
Ans:
Loop vectorization is a compiler optimization technique that transforms scalar loops into vectorized loops to exploit the parallelism offered by SIMD (Single Instruction, Multiple Data) architectures. By grouping multiple loop iterations into vector operations, loop vectorization increases instruction-level parallelism, reduces loop overhead, and improves performance on architectures with vector processing capabilities, such as modern CPUs and GPUs.
71. What are loop interchange and loop distribution, and how do they contribute to compiler optimization?
Ans:
- Loop interchange swaps the order of nested loops to improve data locality and enable further optimizations.
- By changing the loop nesting order, loop interchange enhances cache utilization, reduces memory access latency, and facilitates other transformations, such as loop fusion and vectorization.
- Loop distribution splits a loop into multiple loops to enhance parallelism and facilitate vectorization or parallel execution, contributing to optimizing loop structures and improving program performance.
72. Explain loop skewing in compiler optimization and its role in improving performance.
Ans:
Loop skewing is a compiler optimization technique that adjusts the loop iteration space to improve parallelism and data locality. By skewing the loop index variables, loop skewing redistributes loop iterations and changes the loop execution order, enabling better exploitation of parallelism and cache locality, especially in nested loop structures. Loop skewing plays a crucial role in optimizing loop performance on modern computer architectures.
73. What is loop fusion in compiler optimization, and how does it contribute to performance improvement?
Ans:
Loop fusion is a compiler optimization technique that combines multiple loops with compatible iteration spaces into a single loop. By merging loop bodies, loop fusion reduces loop overhead and improves memory locality, leading to better cache utilization and reduced memory access latency. This optimization can significantly improve performance, especially on architectures with limited cache capacity or high memory access latency.
74. Explain loop splitting in compiler optimization and its significance.
Ans:
Loop splitting is a compiler optimization technique that splits a loop into multiple loops to improve parallelism, enhance memory locality, or facilitate other optimizations. By dividing a loop into smaller, more manageable chunks, loop splitting enables better exploitation of parallelism, reduces loop overhead, and simplifies subsequent optimization transformations, leading to improved performance on modern computer architectures.
75. What is loop interchange in compiler optimization, and why is it important?
Ans:
Loop interchange is a compiler optimization technique that swaps the order of nested loops to improve memory access patterns and cache locality. By changing the loop nesting order, loop interchange reorders memory accesses, enhances spatial locality, and reduces memory access latency. This optimization facilitates better cache utilization and more efficient memory access patterns, leading to improved performance.
76. Explain loop peeling in compiler optimization and its benefits.
Ans:
Loop peeling is a compiler optimization technique that removes a fixed number of iterations from the beginning or end of a loop to handle boundary conditions or special cases more efficiently. By peeling off iterations, loop peeling reduces branch mispredictions, eliminates unnecessary computations, and simplifies loop execution, leading to improved performance, especially in cases where loop overhead dominates execution time.
77. What is loop unrolling in compiler optimization, and how does it contribute to improving performance?
Ans:
Loop unrolling is a compiler optimization technique that replicates loop bodies multiple times to reduce loop overhead and improve instruction-level parallelism. By expanding loop iterations into multiple copies of the loop body, loop unrolling increases the ratio of computation to loop control overhead improves instruction pipelining, and enhances performance, especially on architectures with deep pipelines or instruction-level parallelism.
78. Explain loop induction variable substitution in compiler optimization and its significance.
Ans:
Loop induction variable substitution is a compiler optimization technique that replaces loop index variables with equivalent expressions derived from other loop variables. By substituting loop index variables with loop-invariant expressions or other loop variables, loop induction variable substitution simplifies loop structures, reduces register pressure, and enables further optimization transformations, leading to improved performance.
79. How does loop fusion in compiler optimization and how is it enhance memory access patterns?
Ans:
Loop fusion is a compiler optimization technique that merges multiple loops with compatible iteration spaces into a single loop. By combining loop bodies, loop fusion improves memory access patterns by reducing the number of loop overhead instructions and enhancing cache locality. This optimization simplifies memory access patterns, reduces memory access latency, and improves performance on modern computer architectures.
80. Explain loop interchange in compiler optimization and its impact on performance.
Ans:
Loop interchange is a compiler optimization technique that swaps the order of nested loops to improve data locality and enable further optimizations. By changing the loop nesting order, loop interchange enhances cache utilization, reduces memory access latency, and facilitates other transformations, such as loop fusion and vectorization. This optimization can significantly improve performance by optimizing memory access patterns.
81. What is loop induction variable substitution in compiler optimization, and why is it important?
Ans:
Loop induction variable substitution is a compiler optimization technique that replaces loop index variables with equivalent expressions derived from other loop variables. By substituting loop index variables with loop-invariant expressions or other loop variables, loop induction variable substitution simplifies loop structures, reduces register pressure, and enables further optimization transformations, leading to improved performance.
82. Explain loop fusion barriers in compiler optimization and their impact.
Ans:
Loop fusion barriers, also known as synchronization points, are statements or operations that prevent the fusion of adjacent loops due to dependencies or control flow constraints. They influence compiler optimization by affecting loop structure, data locality, and parallelism, impacting program performance accordingly. Identifying and managing loop fusion barriers is crucial for optimizing loop structures and improving performance.
83. How does loop parallelization in compiler optimization boost performance?
Ans:
Loop parallelization is a compiler optimization technique that parallelizes loops to exploit parallelism across multiple processing units, such as CPU cores or SIMD units. By analyzing loop dependencies and scheduling loop iterations onto multiple processing units, loop parallelization maximizes parallelism, reduces loop overhead, and improves performance, especially on architectures with multiple cores or SIMD units.
84. Explain loop skewing in compiler optimization and its role in improving memory access patterns.
Ans:
- Loop skewing is a compiler optimization technique that adjusts the loop iteration space to improve parallelism and data locality.
- By skewing the loop index variables, loop skewing redistributes loop iterations and changes the loop execution order, enabling better exploitation of parallelism and cache locality.
- This optimization improves memory access patterns by enhancing spatial and temporal locality, leading to better cache utilization and reduced memory access latency.
85. Explain loop peeling in compiler optimization and its significance in improving performance.
Ans:
Loop peeling is a compiler optimization technique that removes a fixed number of iterations from the beginning or end of a loop to handle boundary conditions or special cases more efficiently. By peeling off iterations, loop peeling reduces branch mispredictions, eliminates unnecessary computations, and simplifies loop execution, leading to improved performance, especially in cases where loop overhead dominates execution time.
86. What are loop unrolling factors in compiler optimization, and how do they affect performance?
Ans:
Loop unrolling factors determine the number of loop iterations replicated in loop unrolling. Increasing the loop unrolling factor replicates more loop iterations, reducing loop overhead and improving instruction-level parallelism. However, excessively large unrolling factors may increase code size and register pressure, leading to diminishing returns or performance degradation. Optimizing loop unrolling factors is crucial for balancing performance and resource usage.
87. Explain loop vectorization barriers in compiler optimization and their impact.
Ans:
Loop vectorization barriers are constraints that prevent the vectorization of loops due to dependencies, data hazards, or control flow complexity. Identifying and managing loop vectorization barriers are crucial for efficient vectorization and improving performance. Overcoming vectorization barriers often involves restructuring loop bodies, reducing dependencies, or introducing specialized vectorization techniques to enable efficient vector processing and improve performance.
88. Explain loop distribution in compiler optimization and its impact on performance.
Ans:
Loop distribution is a compiler optimization technique that splits a loop into multiple loops to enhance parallelism and facilitate vectorization or parallel execution. By dividing a loop into smaller loops, loop distribution increases the potential for parallel execution, reduces loop overhead, and simplifies subsequent optimization transformations. This leads to improved performance, especially on architectures with multiple processing units.
89. What is loop fusion in compiler optimization, and why is it important?
Ans:
Loop fusion is a compiler optimization technique that combines multiple loops with compatible iteration spaces into a single loop. By merging loop bodies, loop fusion reduces loop overhead and improves memory locality, leading to better cache utilization and reduced memory access latency. This optimization can significantly improve performance, especially on architectures with limited cache capacity or high memory access latency.
90. Explain loop versioning in compiler optimization and its significance.
Ans:
Loop versioning is a compiler optimization technique that generates multiple versions of a loop optimized for different hardware configurations or runtime conditions. By generating specialized loop versions tailored to specific execution contexts, loop versioning improves adaptability, enhances performance across different platforms, and enables better exploitation of hardware resources, leading to improved overall performance.
91. What is loop trip count estimation, and what is its importance in compiler optimization?
Ans:
Loop trip count estimation is the process of predicting the number of iterations a loop will execute at runtime. It is important in compiler optimization for guiding loop optimization decisions, such as loop unrolling, loop vectorization, and loop fusion. Accurate trip count estimation helps compilers generate efficient code and avoid unnecessary optimizations that may degrade performance or increase code size.
92. Explain loop distribution in compiler optimization and its significance.
Ans:
Loop distribution is a compiler optimization technique that splits a loop into multiple loops to enhance parallelism and facilitate vectorization or parallel execution. By dividing a loop into smaller loops, loop distribution increases the potential for parallel execution, reduces loop overhead, and simplifies subsequent optimization transformations. This leads to improved performance, especially on architectures with multiple processing units.




