
Last updated on 28th May 2024| 4722
System design entails outlining the architecture, components, modules, interfaces, and data management of a system to meet defined criteria. It involves structuring the system, guaranteeing scalability, security, and efficiency, and integrating diverse elements for smooth operation. This phase is essential for developing effective, dependable, and user-centric software or systems.
1. What is system design, and why is it important?
Ans:
System design encompasses the process of outlining the architecture, components, modules, interfaces, and data structure of a system to meet predefined requirements. It’s paramount because it establishes the groundwork for the entire system, ensuring it meets performance, scalability, reliability, and other non-functional requisites while accommodating future expansion and alterations.
2. Explain the difference between high-level and low-level system design.
Ans:
| Aspect | High-Level System Design | Low-Level System Design |
|---|---|---|
| Focus | Defines overall system architecture and major functionalities. | Specifies detailed component designs, algorithms, and interfaces. |
| Level of Detail | Conceptual and abstract. | Specific and detailed. |
| Scope | Addresses system structure, scalability, and major components. | Deals with implementation details, algorithms, and data structures. |
| Abstraction Level | Broad concepts without delving into implementation specifics. | Granular details of how components interact and are implemented. |
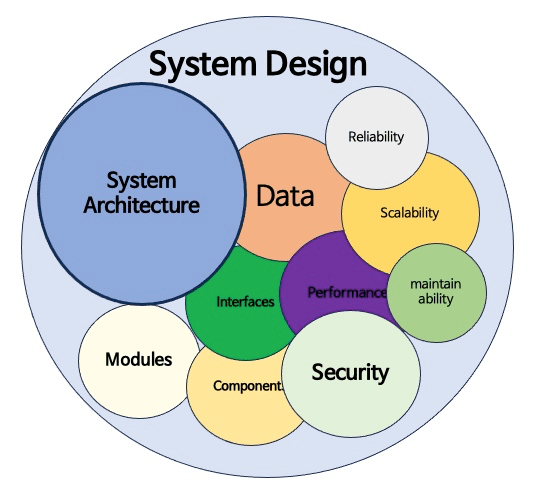
3. What are the main components of a system design?
Ans:
- Architecture: The overall structure and interaction of the system components.
- Data Management: How data is stored, retrieved, and maintained.
- Interfaces: The points of interaction between different system components and users.
- Security: Measures to protect the system and data from unauthorized access and threats.
4. How to approach designing a new system from scratch?
Ans:
- Requirements Analysis: Understand the needs and objectives of the system.
- High-Level Design: Outline the system architecture and major components.
- Detailed Design: Specify component interactions, algorithms, and data structures.
- Iterative Development: Implement, test, and refine the system incrementally to ensure it meets requirements effectively.
5. What is Scalability, and why is it important in system design?
Ans:
Scalability denotes a system’s capability to handle escalating workloads by adding resources or scaling horizontally without impairing performance. It’s pivotal in system design to ensure the system can accommodate growth without compromising performance or availability. This adaptability allows organizations to efficiently respond to increasing user demands and evolving business needs while maintaining optimal operational efficiency.
6. Describe the concept of load balancing.
Ans:
Load balancing is a method employed to distribute incoming requests or traffic across multiple servers or resources to ensure efficient resource utilization, maximal throughput, minimal response time, and prevention of overburdening any single component. Load balancing improves fault tolerance and system resilience by dynamically modifying the request distribution, enabling smooth operation even in the event of server outages.
7. What are the key factors to consider when designing a distributed system?
Ans:
- Fault Tolerance: Ensure resilience to failures of individual components or nodes to maintain system integrity and availability.
- Consistency: Maintain data consistency across distributed nodes to ensure coherence and reliability of information.
- Latency: Minimize communication latency between distributed components to optimize system responsiveness and efficiency.
- Scalability: Design the system to handle increasing workloads by adding resources or scaling horizontally without sacrificing performance or availability.
- Concurrency: Manage concurrent access to shared resources to prevent data corruption and ensure consistency in multi-user environments.
8. How do users handle data consistency in a distributed system?
Ans:
- Ensuring data consistency in distributed systems involves employing various strategies due to the challenges posed by decentralized data storage and processing.
- One common approach is data replication, where copies of data are stored across multiple nodes to ensure fault tolerance and redundancy.
- Consensus algorithms, such as Paxos or Raft, are used to achieve agreement among nodes on the state of shared data, ensuring consistency despite failures or partitions.
- Quorum-based techniques require a certain number of nodes to agree on updates, balancing consistency and fault tolerance.
9. Explain the CAP theorem and its implications for distributed system design.
Ans:
According to the CAP theorem, consistency, availability, and partition tolerance cannot all be attained at the same time in a distributed system. Trade-offs between these qualities are therefore required, and design choices are influenced by particular needs and limitations. The CAP theorem can assist architects in prioritizing the features that are most crucial for their application, enabling them to select the best database and architecture for their use case.
10. What is a microservices architecture, and what are its benefits and drawbacks?
Ans:
Microservices architecture entails structuring an application as a set of loosely coupled, independently deployable services. It offers benefits like enhanced scalability, flexibility, and resilience while introducing challenges such as heightened complexity and operational overhead. By enabling teams to develop, test, and deploy services independently, microservices architecture fosters greater innovation and quicker time-to-market for new features.
11. What sets SQL and NoSQL databases apart?
Ans:
- SQL databases, also known as relational databases, employ structured query language (SQL) to manage and manipulate data.
- They feature predefined schemas and support ACID (Atomicity, Consistency, Isolation, Durability) transactions.
- In contrast, NoSQL databases are non-relational databases that store and retrieve data using alternative formats such as JSON, XML, or key-value pairs.
- They offer flexible schema designs, horizontal scalability, and eventual consistency.
12. How to determine the ideal database type for system design?
Ans:
- Selecting the suitable database type relies on factors like data structure, scalability needs, performance requirements, and development flexibility.
- SQL databases suit structured data, complex queries, and transactional applications, while NoSQL databases are preferred for unstructured or semi-structured data, high scalability, and schema flexibility.
- Evaluating these factors and considering system-specific requirements aids in making an informed decision.
13. Define database normalization.
Ans:
Database normalization involves structuring data in a relational database to minimize redundancy and dependency. It entails breaking down large tables into smaller ones and establishing relationships between them to ensure data integrity and reduce anomalies like insert, update, and delete anomalies. Normalization typically follows a series of standard forms, each addressing specific types of redundancy and dependency within the database schema.
14. What is denormalization, and when is it beneficial?
Ans:
Denormalization entails intentionally introducing redundancy into a database schema to enhance query performance or simplify data retrieval. It may involve merging tables or duplicating data to reduce the need for joins and expedite read operations. Denormalization proves beneficial in scenarios prioritizing read performance, such as data warehousing, reporting, where the trade-off between redundancy and performance is acceptable.
15. How do users devise a database schema for a large-scale application?
Ans:
- Designing a database schema for a large-scale application involves analyzing requirements, data access patterns, scalability needs, and performance goals.
- The schema should optimize data retrieval, storage, and maintenance while ensuring integrity and consistency.
- Techniques like horizontal partitioning, sharding, and distributed databases may be employed to manage large data volumes and scale horizontally.
16. What are the merits and demerits of using relational databases?
Ans:
- Relational databases offer advantages such as data integrity, ACID compliance, support for complex queries, and a mature ecosystem of tools.
- However, they also present limitations such as scalability challenges, rigid schema requirements, and performance bottlenecks under high loads or complex queries.
- Additionally, relational databases may necessitate significant upfront modelling and schema design efforts and may only be suitable for some data types or use cases.
17. How to oversee database sharding?
Ans:
Database sharding involves partitioning a database into smaller, manageable pieces called shards and distributing them across multiple servers or nodes. Sharding typically relies on a sharding key to determine data partitioning and distribution across shards. Selecting the sharding key carefully ensures even data distribution and mitigates hotspots.
18. Define a data warehouse and distinguish it from a transactional database.
Ans:
A data warehouse is a centralized repository for storing and analyzing large volumes of historical and aggregated data from multiple sources. Unlike transactional databases, data warehouses prioritize read-heavy analytics and reporting workloads over transactional processing. They employ denormalized schemas, dimensional modelling, and OLAP techniques to support complex queries, data mining, and business intelligence applications.
19. Explain eventual consistency in NoSQL databases.
Ans:
- Eventual consistency is a consistency model prevalent in distributed systems and NoSQL databases.
- In this model, data updates are propagated asynchronously and may take time to reach all replicas or nodes.
- While temporary divergence among different replicas or nodes may occur, they ultimately converge to a consistent state.
- Eventual consistency prioritizes availability and partition tolerance over strict consistency and is suited for scenarios where real-time consistency is not critical, like caching, social media feeds, or recommendation systems.
20. How to formulate a caching strategy for a database?
Ans:
- Developing a database caching strategy entails identifying frequently accessed or latency-sensitive data and caching it in memory or a dedicated caching layer.
- Key considerations include cache invalidation strategies, eviction policies, consistency mechanisms, and the balance between cache hit rate and coherence.
- Caching may be implemented at various levels, such as application-level caching, database query caching, or distributed caching using tools like Redis or Memcached.
- Monitoring cache usage, performance, and data consistency is crucial to ensuring the efficacy of the caching strategy.
21. What are the different storage system types, and how to choose one?
Ans:
Various storage systems include file storage, block storage, object storage, and database storage. The selection depends on factors like performance needs, scalability, data access patterns, cost, and data durability requirements. For instance, object storage suits unstructured data like images and videos, while block storage is ideal for databases requiring high-performance and low-latency access.
22. How can one design a scalable storage system?
Ans:
Designing a scalable storage system involves considerations such as horizontal scalability, partitioning data across multiple nodes, load balancing, and leveraging distributed file systems or databases. Techniques like sharding, caching, and replication help distribute load and ensure system resilience. Additionally, cloud-based storage solutions and auto-scaling capabilities can enhance scalability.
23. What sets block storage apart from object storage?
Ans:
- Block storage operates at the level of individual data blocks, presenting storage volumes directly to the operating system.
- On the other hand, object storage treats data as discrete objects with associated metadata accessed via unique identifiers.
- While block storage offers low-level access and suits structured data, object storage provides scalable and cost-effective storage for unstructured data like multimedia files and documents.
24. How to manage data backup and recovery in a system design?
Ans:
- A robust backup and recovery strategy involves regular backups of critical data, including full and incremental backups.
- Backup data should be securely stored offsite to guard against disasters.
- Automated backup processes, versioning, and periodic testing of recovery procedures are vital components of a comprehensive data protection plan.
25. What are the best practices for data replication?
Ans:
Best practices for data replication include selecting an appropriate replication strategy (e.g., master-slave or multi-master), ensuring data consistency across replicas, monitoring replication lag, and implementing failover mechanisms to handle replica failures gracefully. Considerations such as network latency, bandwidth constraints, and replication impact on system performance are essential when designing replication solutions.
26. How to ensure data integrity in a storage system?
Ans:
Data integrity maintenance involves implementing measures like checksums, data validation checks, cryptographic hashing, and access controls to prevent unauthorized modifications. Additionally, employing redundancy and error detection/correction mechanisms like RAID enhances data reliability and guards against corruption. These strategies collectively ensure that data remains accurate, consistent, supporting robust decision-making processes.
27. What is RAID, and how is it employed?
Ans:
- RAID is a storage technology that combines multiple physical disks into a single logical unit for improved performance, reliability, and data redundancy.
- RAID levels offer different configurations for striping, mirroring, or parity-based redundancy.
- RAID arrays distribute data across disks, enhancing read/write performance and providing fault tolerance in case of disk failures.
28. How can one manage large file uploads and downloads in a system architecture?
Ans:
- Extensive file transfer management involves techniques like chunking, resumable uploads/downloads, and streaming.
- Using content delivery networks (CDNs), implementing efficient compression algorithms, and optimizing network bandwidth usage can improve transfer speeds and reduce latency.
- Additionally, employing parallel processing and load balancing distributes file transfer loads for enhanced scalability and performance.
29. What are the trade-offs between cloud storage and on-premises storage?
Ans:
Cloud storage offers scalability, flexibility, pay-as-you-go pricing, and offsite data replication benefits. However, it may raise concerns about data security, compliance, vendor lock-in, and network latency. On-premises storage provides greater control over security and compliance but requires upfront investment, ongoing maintenance, and limited scalability compared to cloud options.
30. How to handle data versioning in a storage system?
Ans:
Data versioning entails maintaining multiple data object versions over time to track changes and facilitate rollback or historical analysis. Implementing version control mechanisms, timestamping, and metadata tracking allows users to retrieve and revert to previous versions as needed. Techniques like object immutability and leveraging versioning capabilities provided by storage or version control systems ensure data consistency and integrity across versions.
31. Explain the OSI model and its layers.
Ans:
- The OSI (Open Systems Interconnection) model is a conceptual framework used to standardize and understand communication between computers in a network.
- It consists of seven layers, each responsible for a specific aspect of the communication process.
- These layers are Physical, Data Link, Network, Transport, Session, Presentation, and Application.
- The Physical Layer deals with the physical connection and transmission of raw data. The Data Link Layer ensures reliable data transmission between adjacent nodes.
32. How to design a highly available network architecture?
Ans:
Designing a highly available network architecture involves implementing redundancy, fault tolerance, and load-balancing mechanisms to minimize downtime and ensure continuous operation. This includes deploying redundant network components such as routers, switches, and links to eliminate single points of failure. Automatic routing protocols and failover mechanisms reroute traffic in case of component failure.
33. What is the role of DNS in a system design?
Ans:
- DNS (Domain Name System) translates domain names into IP addresses, enabling users to access websites and services using human-readable names instead of numerical IP addresses.
- In system design, DNS plays a crucial role in resolving domain names to IP addresses, allowing clients to locate and connect to servers hosting web applications or services.
- It also supports load balancing and traffic management by mapping domain names to multiple IP addresses and distributing requests across servers for improved performance and fault tolerance.
34. How to ensure network security in a system design?
Ans:
Ensuring network security in a system design involves implementing various measures to protect data, resources, and communication channels from unauthorized access, interception, and malicious activities. This includes encrypting data using protocols like SSL/TLS to secure communication channels and prevent eavesdropping. Firewalls, intrusion detection/prevention systems, and access control mechanisms are deployed to monitor and restrict network traffic.
35. What are the benefits and challenges of using a content delivery network (CDN)?
Ans:
- A content delivery network (CDN) enhances web performance, reliability, and scalability by caching and distributing content closer to end-users.
- Benefits of using a CDN include improved website speed and performance, enhanced scalability and reliability, and global reach and accessibility.
- However, challenges include complexity and cost associated with CDN setup and management, potential cache consistency issues, and privacy and security concerns related to data handling and compliance.
- Despite these challenges, CDNs offer significant advantages in optimizing content delivery and improving user experience across diverse geographical locations.
36. How do users handle network partitioning in a distributed system?
Ans:
- Handling network partitioning in a distributed system involves implementing strategies to maintain consistency and availability despite network failures or partitions.
- This includes using partition-aware replication and consensus protocols like Raft or Paxos to ensure data consistency and coordination among distributed nodes.
- Quorum-based systems and distributed consensus algorithms are employed to reach agreements on data updates and maintain system integrity.
- Timeouts and failure detection mechanisms detect network partitions and trigger automatic recovery or fallback mechanisms.
37. Explain the concept of network latency and its impact on system performance.
Ans:
Network latency refers to the delay or time taken for data packets to travel from a source to a destination across a network. High network latency can lead to slow application response times, increased time-to-market for real-time applications, and reduced throughput and network efficiency. Reducing network latency involves:
- Optimizing network infrastructure.
- Minimizing packet processing delays.
- Using technologies like caching, compression, and CDNs to mitigate latency-related bottlenecks.
38. What is a virtual private network (VPN), and how does it function?
Ans:
A virtual private network (VPN) extends a private network across a public network, allowing users to securely access and transmit data over the internet as if they were directly connected to a private network. VPNs encrypt data traffic between the user’s device and the VPN server, ensuring confidentiality and privacy. VPNs are commonly used for remote access, secure communication, bypassing geo-restrictions, and ensuring privacy.
39. How to design a system for efficient bandwidth usage?
Ans:
Designing a system for efficient bandwidth usage involves optimizing network resources, minimizing data transfer overhead, and prioritizing critical traffic. Key strategies include compressing data before transmission to reduce file sizes, implementing caching mechanisms to store and serve frequently accessed content locally, and prioritizing traffic using quality of service (QoS) policies.
40. What are the critical considerations for designing a network protocol?
Ans:
Designing a network protocol requires careful consideration of various factors to ensure compatibility, efficiency, and security. Key considerations include:
- Defining the protocol’s purpose.
- Specifying the message format and data encoding method.
- Determining error detection and correction mechanisms.
- Selecting appropriate communication protocols and addressing schemes.

Get JOB System Design Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. What are the fundamental principles in creating a secure system?
Ans:
Designing a secure system hinges on key principles, such as employing defence in depth, where multiple layers of security measures are used to mitigate risks. The principle of least privilege is also crucial, meaning users or systems should only have access to the minimum permissions required for their tasks. Security by design entails integrating security considerations across all stages of the system’s lifecycle.
42. How to manage authentication and authorization within a system?
Ans:
Authentication confirms the identity of users or entities accessing the system using credentials or biometrics. Authorization determines the actions permitted based on authenticated identity and assigned permissions. Effective authentication and authorization often involve techniques like role-based or attribute-based access control and OAuth/OpenID Connect for delegated authorization and single sign-on capabilities.
43. Define the principle of least privilege and its significance.
Ans:
- The principle of least privilege dictates that users, processes, or systems should only have access to the minimal level of permissions necessary for their tasks.
- This principle is crucial as it minimizes the potential impact of security breaches by limiting unauthorized actions.
- By restricting privileges to essentials, organizations mitigate risks associated with data breaches, unauthorized access, and privilege escalation attacks.
44. How to devise a system to thwart DDoS attacks?
Ans:
- Various strategies are employed to counter Distributed Denial of Service (DDoS) attacks.
- These include implementing traffic filtering and rate limiting to block malicious requests and leveraging Content Delivery Networks (CDNs) to distribute and cache content, mitigating DDoS traffic.
- Designing scalable infrastructure, utilizing DDoS protection services, and employing anomaly detection mechanisms further fortify defences against DDoS attacks.
45. Explain the concept of end-to-end encryption.
Ans:
End-to-end encryption (E2EE) ensures data confidentiality by encrypting information at its source and decrypting it only at its intended destination. This method prevents intermediaries from accessing plaintext data during transmission. With E2EE, data is encrypted by the sender and decrypted solely by the recipient using cryptographic keys, protecting it from interception and unauthorized access.
46. How is data privacy maintained in system design?
Ans:
Data privacy in system design involves implementing measures to safeguard personal or sensitive information. These measures include data minimization, access controls, encryption, anonymization, pseudonymization, and proper data lifecycle management. These practices mitigate the risks of data breaches and ensure compliance with privacy regulations while enabling secure data processing and storage.
47. What are the typical security threats in distributed systems?
Ans:
- Common security threats in distributed systems comprise unauthorized access, data breaches, denial-of-service (DoS) attacks, data tampering, man-in-the-middle (MitM) attacks, and insider threats.
- These systems are vulnerable due to their decentralized nature and complexity, requiring robust security measures such as authentication, encryption, access controls, and continuous monitoring to mitigate risks effectively.
48. How to establish secure communication between services?
Ans:
- Securing communication between services involves employing cryptographic protocols such as TLS, mutual authentication, and message-level encryption.
- Additionally, secure APIs and service mesh architectures ensure data confidentiality, integrity, and authenticity during transit.
- By implementing access controls and encrypting communication channels, organizations maintain a safe framework for data exchange.
49. What role does a firewall play in system design?
Ans:
A firewall acts as a network security barrier, controlling incoming and outgoing traffic based on predefined rules. It performs tasks like network segmentation, access control, intrusion prevention, and traffic filtering. By enforcing security policies and blocking unauthorized traffic, firewalls protect network resources, services, and sensitive data from external threats, ensuring a secure infrastructure.
50. How to ensure secure handling of user data within a system?
Ans:
Ensuring secure handling of user data involves implementing comprehensive data protection measures such as encryption, access controls, and data masking. Adhering to privacy regulations and conducting user awareness training further strengthens security. Regular security assessments and incident response planning contribute to maintaining a robust security posture and safeguarding user data from evolving threats.
51. Explain how to architect a system to manage high traffic effectively?
Ans:
- Implementing load balancing evenly distributes incoming traffic across multiple servers, preventing any one server from becoming overloaded.
- Scaling horizontally by adding more servers or instances can increase system capacity. Optimizing database performance, employing caching mechanisms, and processing tasks asynchronously are also effective techniques.
- Monitoring and performance testing ensure the system remains responsive and resilient under high loads.
52. What are the recommended methods for optimizing system performance?
Ans:
Optimizing system performance involves various best practices. These include minimizing network latency by reducing the number of network requests, optimizing database queries and indexing for efficient data retrieval, employing efficient algorithms and data structures, and utilizing caching mechanisms to store frequently accessed data.
53. How to execute horizontal and vertical scaling?
Ans:
Horizontal scaling involves adding more machines or instances to distribute the workload across multiple servers, while vertical scaling entails increasing the resources (such as CPU, memory, or storage) of existing servers. By distributing the workload, horizontal scaling offers better scalability and fault tolerance, while vertical scaling provides immediate performance improvements but is limited by hardware constraints.
54. How to measure and monitor system performance?
Ans:
- Utilizing performance monitoring tools, setting up performance metrics and thresholds, and employing logging and tracing mechanisms help track system behaviour.
- Continuous monitoring of key performance indicators (KPIs) such as response time, throughput, error rates, and resource utilization provides insights into system health and performance.
- Additionally, performance testing, including load testing and stress testing, helps identify performance bottlenecks and potential scalability issues.
55. What constitutes a bottleneck, and how to detect and address it?
Ans:
- A bottleneck occurs when a system component restricts overall performance or throughput.
- Detecting and resolving bottlenecks involves analyzing system metrics, performance logs, and monitoring tools to identify areas of congestion or resource contention.
- Standard techniques for addressing bottlenecks include optimizing code or algorithms, scaling resources vertically or horizontally, improving database performance, caching frequently accessed data, and load-balancing traffic across multiple servers.
56. Explain how designing a system can handle traffic spikes?
Ans:
Designing a system to accommodate traffic spikes requires implementing scalability measures such as autoscaling, which automatically adjusts resource allocation based on demand. Additionally, employing caching mechanisms to alleviate database load, optimizing resource utilization, and utilizing content delivery networks (CDNs) to distribute content and reduce server load are effective strategies.
57. What are the trade-offs between latency and throughput?
Ans:
- The trade-offs between latency (response time) and throughput (rate of processing) depend on system requirements and design considerations.
- Increasing throughput often involves optimizing system resources and parallelizing tasks, which can reduce latency.
- However, minimizing latency may require sacrificing throughput by prioritizing real-time responsiveness over processing speed.
58. How to leverage caching to enhance system performance?
Ans:
Caching improves system performance by storing frequently accessed data or computations in memory for faster retrieval. Employing caching mechanisms such as in-memory caches, content delivery networks (CDNs), and database queries, caching reduces the need to fetch data from slower storage systems, such as disk or network storage.
59. What role does a message queue play in scalable system design?
Ans:
A message queue facilitates asynchronous communication between components in a distributed system by decoupling producers and consumers of messages. By temporarily storing and buffering messages, message queues enable smooth handling of traffic spikes and peak loads. This approach not only enhances system resilience but also improves overall throughput by allowing consumers to process messages at their own pace without losing data.
60. How to ensure the scalability of automated test suites?
Ans:
Ensuring the scalability of automated test suites involves designing tests that can accommodate growing system complexity and size. Utilizing test automation frameworks that support parallel execution, distributed testing, and cloud-based testing environments enables running tests concurrently on multiple machines or instances. Incorporating modular test design and reusable components helps streamline maintenance and allows for quicker adaptation to changes in the system under test.

Develop Your Skills with System Design Certification Training
Weekday / Weekend BatchesSee Batch Details61. How can users structure a system to withstand faults effectively?
Ans:
- Incorporating redundancy by duplicating critical components or services ensures that if one fails, another can seamlessly take over.
- Implementing failover mechanisms enables the system to automatically switch to backup resources or components in case of failure.
- Utilizing health checks and proactive monitoring helps detect and mitigate potential failures before they impact the system.
- Designing for graceful degradation ensures that the system can continue to operate at a reduced capacity or with limited functionality during failures.
62. What practices are advised to ensure system reliability?
Ans:
Ensuring system reliability encompasses various best practices. These include designing for redundancy to eliminate single points of failure, implementing automated testing and continuous integration to detect issues early, establishing disaster recovery plans to mitigate the impact of failures, and continuously monitoring system health and performance.
63. How to integrate redundancy into system design?
Ans:
- Incorporating redundancy into system design involves duplicating critical components, resources, or services to ensure system availability and reliability.
- This redundancy can take various forms, such as deploying redundant servers, utilizing redundant power supplies, establishing mirrored databases, or employing load balancers to distribute traffic across redundant instances.
- Redundancy helps mitigate the risk of single points of failure and ensures uninterrupted operation in the event of component failures or outages.
64. Explain the concept of graceful degradation.
Ans:
- Graceful degradation refers to the ability of a system to maintain essential functionality and provide a degraded but usable experience in the event of component failures or adverse conditions.
- Rather than crashing or becoming unusable, a system designed for graceful degradation continues to operate with reduced performance or functionality.
- This ensures that critical operations can still be performed, allowing users to access essential features even under challenging circumstances.
65. How can users create a system for disaster recovery?
Ans:
Designing a disaster recovery system involves several steps. First, conducting a risk assessment helps identify potential threats and vulnerabilities. Based on this assessment, implementing backup and replication mechanisms ensures data redundancy and availability. Establishing disaster recovery plans that outline procedures for restoring system functionality in the event of a disaster is essential.
66. What separates high availability from fault tolerance?
Ans:
High availability refers to the ability of a system to remain operational and accessible for a high percentage of the time, typically measured as uptime. Achieving high availability involves minimizing downtime through redundancy, failover mechanisms, and proactive maintenance. On the other hand, fault tolerance focuses on a system’s ability to continue operating despite component failures or adverse conditions.
67. How to manage failover in a distributed system?
Ans:
- Managing failover in a distributed system involves implementing mechanisms to detect failures and automatically switch to redundant resources or components.
- This may include deploying load balancers to distribute traffic across healthy instances, and configuring automated failover systems to redirect traffic to backup resources.
- Implementing health checks and proactive monitoring helps detect and mitigate potential issues before they impact system availability.
68. What are the primary considerations for designing a reliable messaging system?
Ans:
- Designing a reliable messaging system requires careful consideration of several factors.
- These include selecting appropriate messaging protocols and technologies that offer guaranteed message delivery, implementing message persistence to ensure messages are not lost in transit, and designing for message durability and fault tolerance.
- Incorporating message acknowledgement mechanisms, dead-letter queues for handling failed messages, and implementing message retries and back-off strategies enhance reliability.
69. How to utilize monitoring and alerting to ensure system reliability?
Ans:
Utilizing monitoring and alerting systems is crucial for ensuring system reliability. Implementing monitoring tools to track system performance, resource utilization, and key performance indicators helps identify potential issues and trends. Configuring alerts based on predefined thresholds or anomalies enables proactive notification of critical events or performance deviations.
70. What is a SLA, and how to design a system to meet it?
Ans:
A service-level agreement (SLA) is a contractual agreement between a service provider and a customer that outlines the expected level of service, including performance metrics, availability targets, and support commitments. Designing a system to meet SLA requirements involves implementing redundancy, failover mechanisms, and performance optimization techniques to ensure system availability, reliability, and performance.
71. What are design patterns, and why are they significant in system design?
Ans:
- Design patterns are established solutions to common software design issues that developers frequently encounter.
- They offer a structured approach to resolving recurring problems, encapsulating best practices and proven solutions.
- Employing design patterns in system design enhances code maintainability, scalability, and reusability by providing standardized solutions to typical design challenges.
72. Explain the Singleton pattern and its application scenarios.
Ans:
- The Singleton pattern guarantees that a class has only one instance and provides a global access point to it.
- This pattern is proper when precisely one class example is required to coordinate actions across the system.
- For instance, it’s commonly applied in scenarios like managing configuration settings, thread pools, or logging mechanisms.
- By limiting instantiation to a single instance, the Singleton pattern enables centralized access to shared resources and ensures consistency throughout the system.
73. What is the Factory pattern, and when is it appropriate?
Ans:
The Factory pattern is a creational design pattern that defines an interface for creating objects but allows subclasses to alter the type of objects that will be instantiated. The Factory pattern provides a centralized mechanism for creating objects, promoting code flexibility and scalability by decoupling the client code from the concrete implementation of objects.
74. Describe the Observer pattern and its practical uses.
Ans:
The Observer pattern is a behavioural design pattern where an object (the subject) maintains a list of its dependents and notifies them of any state changes, usually through a standard interface. It’s extensively used in scenarios where multiple objects need to be informed and updated when the state of another object changes. Practical applications of the Observer pattern include event-driven architectures, GUI components, and distributed systems.
75. What does the Decorator pattern entail, and how is it implemented?
Ans:
- The Decorator pattern is a structural design pattern that allows behaviour to be added to individual objects dynamically without affecting other objects of the same class.
- It’s achieved by creating a set of decorator classes that are used to wrap concrete components and provide additional functionality.
- The Decorator pattern enhances code maintainability by enabling behaviour to be added or removed at runtime, facilitating scalability and flexibility in system design.
76. How is the Strategy pattern implemented in system design?
Ans:
- The Strategy pattern is a behavioural design pattern that defines a family of algorithms, encapsulates each one, and makes them interchangeable.
- It enables clients to select an algorithm from a set of options dynamically without hardcoding dependencies.
- In system design, the Strategy pattern is employed to encapsulate varying behaviour within interchangeable components, promoting code reuse, flexibility, and maintainability.
77. Define the Adapter pattern and its benefits.
Ans:
The Adapter pattern is a structural design pattern that allows incompatible interfaces to work together by converting the interface of one class into another interface that clients expect. It acts as a bridge between two incompatible interfaces, facilitating seamless communication between them. The Adapter pattern promotes code reuse, fosters interoperability between disparate systems, and simplifies system integration by providing a standardized interface.
78. What is the Command pattern, and how is it utilized?
Ans:
The Command pattern is a behavioural design pattern that encapsulates a request as an object, thereby allowing for the parameterization of clients with queues, requests, and operations. It facilitates the decoupling of sender and receiver objects, enabling the parameterization of clients with queues, requests, and operations. In system design, the Command pattern is used to represent actions as objects, allowing for the invocation of actions without knowledge of their implementation or receiver.
79. Explain the usage of the Proxy pattern in system design.
Ans:
- The Proxy pattern is a structural design pattern that provides a surrogate or placeholder for another object to control access to it.
- It’s typically employed to add functionality to an existing object without altering its structure.
- In system design, the Proxy pattern is used to implement lazy initialization, access control, caching, or logging for objects, thereby enhancing performance, security, and maintainability.
80. What role does the Builder pattern play in constructing complex objects?
Ans:
- The Builder pattern is a creational design pattern that separates the construction of a complex object from its representation, allowing the same construction process to create different representations.
- It involves defining an interface for creating complex objects step by step and providing a director class that orchestrates the construction process.
- In system design, the Builder pattern simplifies the creation of complex objects by separating the construction logic from the object’s final representation, promoting code reuse and maintainability.
81. Define designing a URL Shortening Service.
Ans:
To create a URL shortening service, need a system composed of a web server to manage incoming requests, a database to store mappings between short URLs and originals, and a URL shortening algorithm to generate short URLs. The web server would handle requests to shorten or expand URLs, interact with the database for mapping storage, and return appropriate responses to clients.
82. What is Scalable Chat Application?
Ans:
For a scalable chat application, we’d implement a distributed architecture comprising multiple servers to manage client connections and message processing. Each server would manage a subset of users and channels, with inter-server communication to synchronize state and distribute messages. Techniques like sharding and load balancing would distribute traffic evenly, and caching would enhance performance.
83. Define Online Marketplace.
Ans:
- Creating an online marketplace involves establishing a platform where buyers and sellers can transact goods or services.
- The system would encompass user authentication, product listings, search and filter functions, transaction processing, and order management.
- It should support features like ratings, reviews, recommendations, and notifications.
- The architecture typically includes front-end web servers, application servers, databases, and external services for payment and shipping integration.
84. How to Video Streaming Platform.
Ans:
- A video streaming platform requires a robust architecture to deliver high-quality video content across diverse devices and network conditions.
- The system consists of components for video ingestion, transcoding, storage, content delivery, and playback.
- It must support features like adaptive bitrate streaming, content recommendations, user authentication, and subscription management.
- The architecture may involve CDNs for content delivery, distributed databases for scalability, and microservices for flexibility and modularity.
85. What is Real-Time Analytics System?
Ans:
To design a real-time analytics system, need a distributed architecture capable of processing and analyzing vast data volumes in real time. Components for data ingestion, processing, storage, and visualization are essential. Technologies like Apache Kafka for data streaming, Apache Spark or Flink for processing, and databases like Cassandra or Druid for storage are used.
86. Define a Recommendation Engine.
Ans:
A recommendation engine relies on data analysis to generate personalized recommendations based on user behaviour. It requires components for data collection, processing, modelling, and serving recommendations. Machine learning algorithms like collaborative filtering or content-based filtering are employed. The architecture must be scalable and adaptable to changing user preferences and trends.
87. Explain Scalable Search Engine.
Ans:
- Creating a scalable search engine involves building a distributed system capable of indexing and searching large data volumes efficiently.
- Components for data ingestion, indexing, query processing, and relevance ranking are vital.
- Technologies like Lucene or Elasticsearch are used for indexing and search, distributed databases for storage, and caching for optimization.
- The architecture should be fault-tolerant, with mechanisms for replication, sharding, and load balancing.
88. What is Social Media Platform?
Ans:
A social media platform encompasses features like user authentication, content creation, sharing, and interaction. Components for user profiles, news feeds, notifications, and privacy settings are essential. Technologies like relational or NoSQL databases, microservices, and APIs are employed. The architecture prioritizes scalability, security, and user engagement.
89. How to design a Cloud Storage Service?
Ans:
- Creating a cloud storage service involves building a distributed system for securely and reliably storing and retrieving data.
- Components for storage, replication, access control, and synchronization are needed.
- Technologies like distributed file systems, object storage systems, and CDNs are used.
- The architecture supports features like encryption, versioning, and access logging.
90. Define a Ride-Sharing Application.
Ans:
A ride-sharing application facilitates real-time ride bookings, tracking, and payments. Components for user registration, location tracking, ride matching, fare calculation, and payment processing are necessary. Technologies like GPS tracking, real-time messaging, and payment gateways are utilized. The architecture is scalable, with features for peak demand management, driver availability, and passenger safety.




