
Last updated on 19th Oct 2024| 6687
C is a powerful, high-level programming language known for its efficiency and control over system resources. It provides low-level access to memory through pointers, making it ideal for system programming and embedded systems. Data structures in C, such as arrays, linked lists, stacks, queues, and trees, allow developers to organize and manage data effectively. Mastering C and its data structures is essential for building efficient algorithms and software applications.
1. What properties should a good hash function have?
Ans:
A good hashing function will have keys spread out of the hash table uniformly, to reduce collisions. Its output for a given input must always be the same-this is called determinism. This function should be efficient; it should calculate the hash in as little time as possible. It must also handle diverse types of input-there are integers and strings, among others. A good hash function should further avoid clustering; namely, the same location is mapped to multiple keys that degrade its performance.
2. What are some common types of collision resolution techniques in hashing?
Ans:
Collision resolution techniques are strategies to handle the instances where multiple keys hashed into the same index. Chaining involves keeping an index that is a linked list at each index which holds more than one key. Open addressing begins probing for an alternative index according to some probing sequence – for instance, linear probing, quadratic probing, or double hashing. Another method is bucket hashing, where each index has a bucket which is made to store multiple keys.
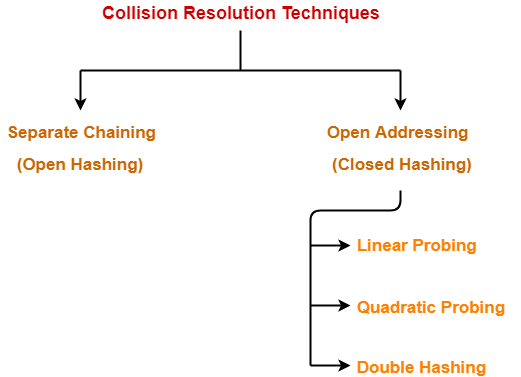
3. How do chains work for hash tables?
Ans:
- In chaining, every hash table slot here points to a linked list containing every entry that hashes to the same index.
- So, if a new key-value pair is to be inserted, the corresponding index would be determined by hashing, and the pair of key-value would be appended to the appropriate linked list.
- During search, the index is returned by the hash function; then, the linked list is traversed to identify the entry of interest.
4. What are the Advantages and Disadvantages of open addressing?
Ans:
| Aspect | Advantages | Disadvantages |
|---|---|---|
| Space Efficiency | Requires less memory overhead since all elements are stored within the hash table itself. | Can lead to clustering, resulting in longer search times due to sequences of filled slots. |
| Implementation Complexity | Relatively straightforward to implement as it does not require additional data structures like linked lists. | Performance can degrade significantly as the load factor increases, making operations slower. |
| Cache Performance | Generally offers better cache performance due to contiguous memory allocation. | Deleting elements can be complex and may require special handling to maintain probe sequences. |
| Memory Access Patterns | Provides predictable memory access patterns, which can enhance performance. | The hash table size must be carefully managed, as exceeding capacity can increase the likelihood of collisions. |
5. How does the load factor affect hash table performance?
Ans:
The load factor, a ratio of entries number to size of the table, significantly determines the performance of a hash table. In general, a low load factor, for example, <0.7, reduces the collisions and therefore the search time would also tend to be faster. On the other hand, the higher load factor only contributes to the chances of collisions which degrades the performance further as more elements fall in the same index.
6. Which sorting algorithms from the list below are stable, and which are unstable?
Ans:
Stable sorting algorithms maintain the ordering of equal-valued records, something that may be quite significant in certain applications. Some examples of stable sorting algorithms are merge sort, bubble sort, and insertion sort. None of the following are ever stable: quick sort, heap sort, and selection sort. In some cases, the algorithm selected depends on whether the property of being stable is desired for the data that will be sorted.
7. What is the time complexity of quicksort on average and in the worst case?
Ans:
- The average-case time complexity of quicksort is O(nlogn), in case the elements selected as pivots divide the list into nearly equal halves.
- This is usually while the smallest or largest element is always chosen as the pivot, for instance, when sorting already sorted data.
- Such a worst case may be avoided with the use of randomized pivot selection or the median-of-three rule to optimize performance.
- Overall, quicksort is preferred because it generally has low overhead and average efficiency.
8. What are the characteristics of a comparison-based sorting algorithm?
Ans:
- The order of comparison-based sorting algorithms is determined by a number of comparisons between pairs on the nature of the input data, which could be partially sorted or randomly distributed.
- In general, their worst-case time complexity stands at or above O(nlogn), following the comparison-based lower bound.
- For the last point, the use of auxiliary space may differ from algorithm to algorithm, as each algorithm may consume extra memory for temporary storage.
9. How does merge sort ensure its stability with regard to ordering?
Ans:
- The input array is recursively broken down to smaller arrays in such a way that each of them will have elements as individual elements as possible.
- When these subarrays merge into the bigger one, they merge respecting their original order the one which was firstly in the original array will firstly appear in the merged array.
- This advantage comes in handy during the sort of a record that contains several fields as this preserves their original relations at the end of sorting.
10. What is the difference between in-place and out-of-place sorting?
Ans:
In-place sorting algorithms are those that sort data without requiring significant memory aside from that originally used to hold the data; thus, they work in place. Examples include quicksort and insertion sort. Out-of-place sorting algorithms are those that take additional memory to hold copies of the data before or in the process of sorting. Merge sort is one of the common out-of-place algorithms that require extra space for temporary arrays, though an in-place algorithm.
11. How does a counting sort algorithm work?
Ans:
Counting sort is another effective sorting algorithm concerning integers or objects whose keys have a finite, limited range. It works by counting occurrences of distinct values in the array, then storing those counts in the “count array.” The algorithm then determines the final position of each key in the sorted output by computing cumulative counts. It is a highly efficient algorithm, particularly when the size of input values (k) isn’t much more than the number of elements (n). Its time complexity is O(n+k), and it’s very efficient for some cases.
12. What is radix sort and when is it helpful?
Ans:
Radix is a comparison less sorting algorithm that sorts numbers on the basis of individual digits and generally from the least significant digit to most significant. It uses a stable sort algorithm, such as counting sort, to sort numbers based on their value at each digit. Radix sort is particularly useful for sorting large sets of integers or fixed-length strings where the number of digits is sufficiently smaller than the total number of items. It achieves a time complexity of, O(n⋅k), where n is the number of elements and k is the number of digits in the largest number.
13. What is the volatility of variables in programming?
Ans:
- In programming, volatility refers to a behavior whereby the value of a variable changes when it is not expected, usually as a consequence of some kind of controlling authority outside the program or concurrent process.
- That is, the compiler should not optimize access to those variables so that the program always reads the most up-to-date value.
- It is very important for interrupt-handling code, memory-mapped I/O, and multithreaded programs.
- The use of the volatile keyword helps avoid certain bugs because without it, the compiler will optimize away necessary reads and writes; thus, the code can act correctly both in real-time systems and under concurrency.
14. How does the volatile keyword impact compiler optimizations?
Ans:
- The volatile keyword in C and C++ instructs the compiler that a variable’s value might change unpredictably, and so the compiler cannot apply various optimizations of values that are known to remain constant.
- Hence every read or write to a volatile variable may lead to actual access to memory, rather than using a cached or optimized value.
- This means volatile guarantees that the program will always fetch the most recent value, which is crucial for applications using hardware registers or shared variables between multiple threads.
- Without a volatile keyword, the compiler may optimize away repeated accesses, using instead some inconsistent or outdated value.
15. What are volatile variable memory barriers?
Ans:
- Memory barriers or memory fences are constructs that will prevent compiler and CPU optimizations of specific varieties such that memory operations are ordered correctly.
- In volatile variables, memory barriers ensure that reads and writes of volatile variables occur in a particular order.
- Memory barriers are the essentials in lower-level programming that involves working with shared data in multithreaded environments.
- Normally, the two are used together with volatile so that changes made to any shared variables are immediately reflected across different threads or cores.
- The proper use of the memory barriers plays a critical role in both integrity and synchronization of data in concurrent applications.
16. What is the difference between exit() and return in main?
Ans:
There are two different functions between exit() and return statement in C or C++. Using return exits the main() function and returns an integer status code to the operating system, usually indicating success (0) or failure (non-zero). In this case, exit() is a library function that gets an abnormal termination in the running of the program (exit() calls regardless of where it is); it also allows to speciy a status code. It’s also worth noting that return can be used only within a function, whereas exit() may be called from anywhere of the program.
17. What are possible values of an lvalue?
Ans:
An lvalue, short for “locator value,” is an expression that locates a memory location and therefore may appear on the left side of an assignment. Lvalues, on the other hand, are temporary values that do not occupy a permanent place in memory; this includes literals or the value produced by an expression. Because lvalues refer to identifiable storage, they can also be assigned a new value. For example in the expression x = 5, x is an lvalue, while 5 is an rvalue.
18. How is the goto statement related to structured programming?
Ans:
The goto statement enables going to an arbitrary point in the code, a design pattern which can lead to what has been called “spaghetti code”, because of its ability to also produce very complicated and unstructured control flows. But goto still permits the implementation of structured programming notwithstanding its free-form jumps-a feature that makes tracing the flow of the program design-the very soul of a structured design-difficult.
19. What are longjmp() and setjmp() used for?
Ans:
- C’s setjmp() and longjmp() functions are the basics of implementing non-local jumps that allow breaking out of a deep stack within a program. The `setjmp()` function sets a jump point in the program and saves its environment for later use.
- This mechanism often proves useful in situations of exceptional processing, especially upon recovery from fatal errors or under unexpected conditions, without needing to return through every function of a call chain.
- However, their use can easily result in hard-to-read and maintain code, so they should be used with restraint. Most modern languages provide structured exception handling, which can be more appropriate than setjmp() and longjmp().
20. How does an XOR linked list save memory?
Ans:
- The result of this clever design is that it eliminates the need to maintain two pointers for previous and next nodes.
- This cuts down memory overhead by half as compared with a regular linked list where storing both pointers is quite necessary.
- It is easy to traverse the list because they can determine at any time either the previous or next node using the address of the current node and the XORed value.
- They are especially useful for memory-constrained environments but complexity makes them slightly harder to implement and understand.
- This is the key to deciding whether to use an XOR linked list in practice-trade-off between memory saving and complexity.
21. What is the advantage of a trie over a hash table for string storage?
Ans:
- A trie is yet another type of prefix tree. It’s an efficient way to store and retrieve strings, which is significantly useful for big datasets such as lists of words.
- Searching for a string in tries takes time proportional to the length of the string, but not the number of entries.
- Tries can be especially efficient with dynamic sets of strings, with insertions and deletions, keeping order.
- They never suffer from the collision problem that plagues hash tables-the same strings hash to different values.
- On all these accounts, tries excel search situations when one needs prefix matching, for dictionaries and autocomplete systems.
22. How does a Splay Tree self balance?
Ans:
A Splay Tree is another type of binary search tree that has the property of self balancing. That is, it is a self-adjusting binary search tree where the tree keeps itself balanced by a process called splaying. Accessing any node is considered when a node is to be inserted, deleted or searched for and the tree does its rotations so that it eventually brings that node to the root. There are three types of rotations in the process: zig, zig-zag and zig-zig that depend on how a node accessed compares with its parent and grandparent to update the tree structure.
23. What applications can users think of for treaps?
Ans:
A treap is a combination of the two previous best friends: it’s a BST and it’s a heap, too. This makes treaps a good fit for applications where a dynamic set of ordered keys is to be maintained and must support an efficient search, insert, and possibly delete operation, all with average-case time complexity of O(logn). It finds useful applications where randomness benefits, for example, randomized algorithms as well as concurrent programming, because the randomized nature of it helps balance.
24. What is eviction policy in the context of an LRU caching scheme?
Ans:
The LRU eviction policy removes the least recently accessed items when there reaches a full capacity for items in the cache. The least recently accessed items are those not likely to be accessed in the near future, as they have gone unaccessed the longest time. When the cache is filled, on adding a new item, the LRU policy always identifies and evicts the item that has not been accessed for the longest period. This mechanism helps optimize the utilization of caches by keeping most frequently accessed data available and, hence, improves the overall performance.
25. What data structures may be used to implement LRU cache?
Ans:
- An LRU cache could be very efficiently implemented as a combination of a hash map and a doubly linked list.
- The hash map would ensure O(1) time access for the items that are cached with their keys. Therefore, whenever an item is accessed or added, it will be shifted to the front of the list, meaning it’s most recently used.
- Then, the least recently accessed item can be easily determined and cleared from the list as well as the hash map when the cache is full.
- There may be other data structures using ordered dictionaries or even trees, yet the most common combination, due to its intrinsic simplicity and efficiency, is a hash map combined with a doubly linked list.
26. How to perform an in-order traversal on a BST?
Ans:
- In-order is one of the traversal ways of a binary search tree; two possible sequences describe it: first, the left subtree is visited and then the current node.
- The traversal can be implemented iteratively by using a stack to manage the nodes or recursively.
- The function calls itself for the left child followed by processing the current node and then, similarly, calls itself for the right child for a recursive approach.
- In-order traversal is used primarily in applications that require a sorted data output or if one requires to convert a BST into a sorted list.
27. Time Complexity for search in Balanced BST?
Ans:
- Time required to find any element in a balanced binary search tree is O(log n) where n is the number of nodes.
- This logarithmic time complexity follows the property that a balanced BST maintains its height proportional to the logarithm of the number of nodes each comparison cuts down the search space about in half.
- Two common implementations of such self-balancing BSTs are AVL trees and red-black trees whose aim is to balance at each insertion or deletion through rotations.
- This search capability makes balanced BSTs suitable for applications requiring frequent lookups, such as in databases, and in-memory data structures.
28. What is the difference between breadth-first search and depth-first search?
Ans:
Breadth-first search (BFS) and depth-first search (DFS) are two fundamental graph- and tree-traversal algorithms, having two distinct approaches. BFS visits all neighbor nodes at the current depth before going to nodes at next level depth. Generally, BFS is implemented using a queue while visiting nodes. This ensures that the shortest path will be determined for unweighted graphs. BFS typically performs better in finding the shortest path, whereas DFS is more efficient in memory usage for a certain application.
29. How do red-black trees balance?
Ans:
Red-black trees balance the tree by a set of properties which ensure that during insertion and deletion of elements the tree remains at least approximately balanced. Given a node, give it a color. Colours could be red or black; the tree must satisfy some properties; the root must be colored black; a red node can’t have red children; every path from node u down to one of its descendant leaves must contain the same number of black nodes; new nodes are always inserted as red.
30. What is a priority queue?
Ans:
It is an abstract data type, which extends the normal queue but associates each element with a priority. The priority queue dequeues elements according to their priority rather than their order in the queue. Higher-priority items are always processed before a lower-priority one, regardless of whether they arrived first or later. This data structure is beneficial in those situations where certain operations need to be performed before the other one, like scheduling algorithms graph algorithms.
31. How can a priority queue be implemented using a binary heap?
Ans:
- A priority queue can be implemented quite efficiently with a binary heap, which is a complete binary tree that satisfies the heap property.
- In a max-heap, each parent node value is higher than or equal to its children; therefore, the highest-priority element is always at the root.
- A new element is added at the end of the heap and “bubbled up” for preserving the heap property. The operations for insertion and deletion can be carried out within O(logn) time due to the tree’s height.
- Deletion, particularly deletion of the highest priority element, substitutes the root with the last element and then “bubbled down” to preserve the heap structure.
32. Whats the difference between stack and queue?
Ans:
- A stack and a queue are two abstract data types for storing collections of elements, but they work differently. A stack follows the LIFO principle that means the last element added is the first to be removed.
- A queue, on the other hand, operates on a First In, First Out basis, where the first element added is the first to be removed.
- The common queue operations include enqueue – to add an element and dequeue – to remove the front element.
- Stack vs Queue Depending on the type of problem the program needs to solve, whether it need to maintain or reverse the order used for insertion, a decision between using a stack and a queue is required.
33. Which applications to use a deque?
Ans:
- A deque is a double-ended queue that can be both inserted and deleted at the ends, thus it forms a very useful data structure.
- It can be used to implement functionality similar to both stacks and queues, enabling efficient access to both the front and rear of the collection.
- Deques are commonly utilized in algorithms requiring sliding window computations, such as finding the maximum or minimum in a window of elements.
- They prove useful in implementations of breadth-first search (BFS) when keeping track of the order in which nodes shall be explored.
34. How does a hash map perform its dynamic resizing?
Ans:
Hash maps dynamically resize to maintain good performance with a changing number of entries. This is often done when the load factor goes above some pre-set threshold. All the existing key-value pairs are then rehashed and inserted into this new array. Their positions are recalculated according to the newly allocated size. Resizing could be expensive, sometimes requiring Time O(n) to recopy everything, but it guarantees that average-case operations are O(1).
35. What are the trade-offs of using linked lists versus arrays?
Ans:
Both linked lists and arrays are used to store collections with different advantages and trade-offs between the two approaches. Arrays support O(1) access to the elements by index but have fixed sizes. If need to increase the size of an array to hold more elements, it would be inefficient because it involves coping elements into a new array. On the other hand, linked lists can dynamically allocate memory, meaning that they can grow and shrink as necessary.
36. What is the purpose of the sizeof operator?
Ans:
The sizeof operator of C shall calculate the size, expressed in bytes, of any data object. It may be used in their entirety for all those primitive variables like int, float or char and user defined data types which are structs and arrays. The value returned by sizeof is a constant that is determined at compile time, so that the programmer can allocate appropriate quantities of memory dynamically. Notice that sizeof returns the size of the type itself, not the size of the variable it references.
37. How does the strlen function calculate the length of a string?
Ans:
- The strlen function in C calculates the length of a null terminated string by moving through the characters in the string from the left until it meets a null character (‘\\0’).
- This is the end of the string. It keeps an initialization counter to 0 and then increments for every character encountered in this traversal.
- Time complexity of strlen is O(n) where n is the length of the string. It is checked each time for every character it has in the string.
- This function is mainly used for string value manipulation and processing to determine how many characters exist within a given string.
38. What are some potential issues with pointer arithmetic?
Ans:
- There are many potential issues with pointer arithmetic that should not be abused. A very large portion of the issues will occur as a result of accessing memory outside the valid bounds of that memory.
- This causes undefined behavior, crashes, or worse: data corruption. It also needs to be handled the increment and decrement of pointers this ensures that they stay within the bounds allocated.
- Correctly manage memory and ensure pointer arithmetic stays within the bounds of allocated memory to program effectively and safely in C.
39. What is the distinction between static and dynamic memory allocation?
Ans:
- It is variables that usually define functions or are global constants and which have a lifetime equal to the execution of the program, and which are controlled automatically by the compiler.
- Dynamic memory allocation is managed at run time using the functions malloc, calloc, or realloc in C, enabling flexible, adjustabled memory sizes.
- As with dynamic memory, all the dynamically allocated memory has to be released manually, which is the only way the memory leak doesn’t happen, as dynamic memory exists in the process until it’s explicitly released.
- While static allocation provides fewer overhead and seems easier, dynamic allocation allows programs to respond better to changing data sizes at runtime. It is up to the needs and restrictions of an application to decide when to use one over the other.
40. What is garbage collection and how does it work in managed languages?
Ans:
- Garbage collection is the mechanism in managed languages to automatically identify and reclaim memory that is no longer being used in order to prevent memory leaks.
- Periodically, the garbage collector scans through the heap for reachable objects from the root references of the applications, which include global variables etc.
- Once unreachable objects are identified, the garbage collector frees the allocated memory that would be available for future allocations.
- There are several kinds of garbage collection algorithms: mark-and-sweep, generational, and reference counting.

Get JOB C & Data Structure Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. What does the const keyword of C/C++ do?
Ans:
The const keyword in C and C++ is used to state that the value of a variable cannot be altered after initialization. In this way, they guard the data from unwanted changes, thus improving safety and readability in code. When used with pointers, const can be applied between the declaration of the pointer and its target: whether the pointer itself and/or the data it points to shall be constant. For instance, const int* p indicates the integer value pointed to by p may not be changed, whereas int* const p indicates the pointer itself p may not be moved to point to some other address.
42. What are inline functions?
Ans:
Advantages of inline functions Inline functions in C and C++ are those functions that expand in line when invoked rather than being invoked through usual function call mechanisms. The key advantage of inline functions is their ability to enhance the performance of a program if the overhead of function calls is high due to the call of small, highly frequent functions. This can result in an improvement in execution time, especially in tight loops or in performance-critical code.
43. How can function overloading make code more readable?
Ans:
With function overloading, a programmer can declare multiple functions with the same name but with varying parameters and their numbers or types. The code is more intuitive and easier to read since it will use descriptive names for the operations with the common function name. This will improve the clarity of the code. For example, a print function could be overloaded to accept different data types and therefore print out the type one wishes to output.
44. What is deep copy, and how does it compare to shallow copy?
Ans:
- Which again means that for both, the original as well as the copy, they are referring to the same locations in the memory for mutable objects.
- A deep copy creates a new object and recursively copies all the members of the original object, allocating different memory to a different address for each.
- In this way, changes in the copied object do not have any effects propagating back to the original.
- Deep copy is important for performance-critical operations with complex data structures or resource-managing objects a shallow copy could be less expensive for simple data types.
45. What are template classes in C++ and how do they work?
Ans:
- The possibility to define a class with type parameters enables the programmer to instantiate the class with specific types, ensuring that the code is reused without this causing a neglect of type-safety.
- By default, upon instantiation of the class, the compiler automatically generates appropriate code for the given type.
- Templates also support type independence, so algorithms may be written in a way which is insensitive to the types.
- Still they lead to increased compile times and sometimes code bloat because of instantiations over many compilation units.
46. What is a virtual function and how does the virtual function relate to the pattern of polymorphism?
Ans:
- A virtual function in C++ is a member function declared in a base class, which can be overridden in derived classes.
- It supports runtime polymorphism, where the program determines the function to call by runtime type, not type of the pointer, whether the pointer points to a base class or an actual type.
- When a virtual function is invoked via a pointer to a base class, if the object is actually of some derived type, then it is derived class’s overridden function that gets executed.
- This is the basic need for the use of features like interfaces and abstract classes wherein specific behaviors may change for specific types of derived classes keep the code flexible and the management easier in complex systems and hierarchies.
47. How does dynamic binding work in object-oriented programming?
Ans:
Dynamic binding, known as late binding, is the time at which the function call is determined at run time rather than at compile time. This mechanism is mainly used with virtual functions in C++. It gives polymorphic behavior in object-oriented programming. When a pointer of the base class holds the address of an object of a derived class, dynamic binding ensures that when such a function is invoked using the base class interface then the overridden function in the derived class is called.
48. What are smart pointers, and why do they have an edge over raw pointers?
Ans:
Smart pointers are wrapper classes that govern the lifetime of dynamically allocated objects in C++. They provide automatic memory management but prevent common issues linked with raw pointers. Such issues range from memory leaks and dangling pointers. The common types of smart pointers include std::unique_ptr, std::shared_ptr, and std::weak_ptr. The std::unique_ptr guarantees that at any given time, a certain resource can be owned only by one pointer.
49. How have exceptions improved error handling in programming?
Ans:
Exceptions offer a structured and efficient way of handling errors and exceptional conditions in programming. Instead of the old error codes and checks sprinkled around the code, exceptions enable developers to separate the logic behind handling errors from normal flow. When an exception is encountered, it gets sent out, and control passes to a suitable catch block which will know how to handle it properly, thus helping code be cleaner and more readable.
50. In object-oriented design, what is the purpose of an interface?
Ans:
- One of the important roles of interfaces in object-oriented design is that they define a contract to which classes adhere but leave open the implementation question.
- An interface defines which methods implementing classes must provide but leaves it to them as to how they do so, providing looser coupling and polymorphism.
- This abstraction makes classes implement different ways of the very same interface, which facilitates flexibility and interoperability.
- Interfaces promote code reuse and make the testing and maintenance of code easier, as implementation details are decoupled from their usage.
- Interfaces are also employed to achieve design patterns such as dependency injection, and they support multiple inheritance in languages which allow for it, such as C++.
51. Whats the difference between method overriding and method overloading?
Ans:
- Method Overriding Derived class specifies the exact implementation of the function already given in its base class.
- For runtime polymorphism, the signature of the overriding method has to be the same as the base class method.
- Overloading allows several functions to bear the same name but have different parameter lists within the same scope (either by type or number).
- The overloading is resolved at compile time, while the overriding is resolved at runtime. Overriding helps in dynamic behavior, and overloading enhances flexibility in the use of the function.
52. What is the main purpose of the main routine in C program?
Ans:
- The main routine is where the operating system transfers control when the program starts executing. It is simply the entry point for execution in a C program.
- There must exist at least one main routine in any C program. The return type for the function is preferably an integer, and it returns an integer value, mostly to indicate whether program execution was a success (0) or not (non-zero).
- The main function can also accept command-line arguments. This way, input can be passed directly to the program through the command line when running the program.
- Secondly, it decides about the context of its execution and is very important for a control flow within a program. A program which fails to correctly define a main function cannot compile or run.
53. How do header files enhance the structuring of code?
Ans:
C and C++ header files help identify declarations of interfaces as opposed to implementations, keeping code cleanly organized and readable. Header files can include function prototypes, type definitions, and macro definitions that enable declarations to be shared over more than one source file without being defined in more than one place. For instance, that makes managing enormous code bases easier because there are only function prototypes to change in one place.
54. What is the difference between C and C++?
Ans:
C and C++ are two distinct programming languages, and they have almost the same syntax, but they differ in their distinctive features and paradigms. C is a procedural language and is based on function and structured programming. On the contrary, C++ is a multi-paradigm language or even especially a procedural and object-oriented programming one. C++ introduced classes, inheritance, polymorphism, and encapsulation to programmers so that they can design complex data structures better and develop relationships between those more effectively.
55. What are the benefits of modular programming?
Ans:
Modular programming divides a program into smaller manageable sections or modules, such that each module may be assigned specific functionalities. This is one of the ways code can be organized, thus promoting maintainability in the sense that developers can concentrate on one module at a time. A modular program also promotes reuse whereby the same module is used in different projects without requiring any changes. Such separation of concerns makes the collaboration among colleagues easier because several developers may work on different modules.
56. What is the difference between an abstract class and a concrete class?
Ans:
- They may be permitted to include pure virtual functions, declared but not defined in the abstract class derived classes are then constrained to provide a definition.
- Concrete classes may be instantiated and normally hold complete implementations for all their member functions.
- Abstract classes can implement polymorphism, and they can be used to define a common interface for classes of related classes and make code design much more flexible.
- They suggest a design pattern where common behavior is set in an abstract class and special behavior in derived classes.
57. What is the Singleton pattern?
Ans:
- Singleton pattern is the creational pattern that limits instantiation of a class to only one object and provides a global access point to that instance.
- The creation logic is encapsulated; thus resource management is eased, and the potential duplication of an unintended creation of objects is reduced.
- It also facilitates the management of various parts of an application that need to access a shared resource.
- However, great caution needs to be exercised when using multi-threading because the singleton instance needs to be constructed in a thread-safe way.
58. What is recursion and how is it used?
Ans:
- Recursion is the technique whereby a function invokes itself to solve smaller instances of the same problem.
- This type typically implies the existence of a base case which must terminate the recursion, while the recursive cases split the problem into smaller subproblems.
- Recursion is particularly effective for problems that have some natural recursive structure to them, for example, tree traversals, or computing the Fibonacci sequence.
- It makes the code much cleaner, as it expresses complex algorithms in a straightforward way with no explicit loops.
- In reality, recursion uses more memory due to the call stack and will likely lead to stack overflow if the recursion depth is too deep.
59. What are the drawbacks of using recursion?
Ans:
Recursion is an effective technique but has several drawbacks that every developer must remember. One of the main limitations of recursion is that, in deep recursion or heavily recursive operations, the depth of recursion can exceed the capacity of the call stack. Also, recursive functions could be less efficient than their iterative equivalents due to the extra overhead from function calls, and every recursion needs extra memory for the corresponding stack frame. This means that while building critical applications where time is taken into account.
60. What is memoization and how does it optimize recursive functions?
Ans:
Memoization is an optimization technique which improves the performance of recursive functions by storing or caching results already computed. It functions by caching its result in some data structure such as a hash map, improving performance. When called with given parameters, if it has been called previously, then it returns the cached results otherwise, it calculates and caches the result so that next time it can return without having to recalculate.

Develop Your Skills with C & Data Structure Certification Training
Weekday / Weekend BatchesSee Batch Details61. How are graphs different than trees?
Ans:
Graphs and Trees are both abstract data structures representing some relationship between elements but differ in some aspects of their characteristics: A tree can be precisely defined as a special case of graph by the structure that contains a root node, and all child nodes are distinct such that every node has exactly one parent. Trees contain no loops, and between any two nodes there is just one way of going from one to the other. This versatility makes graphs appropriate to describe more complicated interrelations like social and transport networks.
62. What is a Directed Acyclic Graph (DAG)?
Ans:
- This structure is particularly helpful to represent dependencies between tasks where there is a direct dependence from one task to another.
- For instance, in scheduling and project management, where a schedule can not be considered earlier unless the previous schedule is completed.
- DAGs are very instrumental in applications such as topological sort algorithms that order vertices in a linear sequence based on their dependences.
- Due to the acyclic nature of the graphs, applications requiring clear precedence without any circular dependencies take DAGs as ideal for application.
63. Which graph traversal algorithm(s) is best?
Ans:
- The best known graph traversal algorithm are two Depth-First Search (DFS) and Breadth-First Search (BFS). Before turning around, DFS travels as far down each branch as it can.
- The alternative way is to try all the neighbors of a node before it moves on to the next level. These include two very fundamental traversal methods used in graph algorithms finding connected components, performing pathfinding.
- Both algorithms are made for different use cases and performance, and while DFS is more memory-efficient on sparse graphs, BFS is guaranteed to find the shortest path in an unweighted graph.
64. How to find cycles in a graph?
Ans:
- Cycles in a graph can be found using any of a number of algorithms depending on the nature of the graph being directed or undirected.
- For a directed graph, one common technique is to use a Depth First Search with the recursion stack and keep track of nodes visited.
- In undirected graphs, can detect cycles by checking whether or not a visited node is encountered that is not the immediate parent of the current node during DFS.
- Can also make use of Union-Find algorithm for detection of cycles in undirected graphs by checking connected components.
65. What is dynamic programming?
Ans:
Dynamic programming is an optimization technique that solves complex problems by breaking it into simpler subproblems. This is highly useful for problems that have overlapping subproblems and which satisfy the optimal substructure property, meaning there is some way of constructing an optimal solution from optimal solutions to its subproblems. Dynamic programming in this way avoids calculating unnecessary things either by keeping the results of the subproblems in a table (memoization) or by solving them iteratively (tabulation).
66. What represents dynamic programming for Knapsack problem?
Ans:
The 0/1 Knapsack problem is actually one of the most often used problems in dynamic programming. This case shall give an overview of how 0/1 Knapsack works whereby each item will positively be either picked up or declined, causing the case to have overlapping sub-problems in the solving process. By iteratively building up such a solution and reusing previously computed values, dynamic programming can turn an exponential-time problem into a polynomial-time solution.
67. What would users identify as the qualities of a good password?
Ans:
A good password normally has many qualitative features that improve its security. The most important feature of this quality would be its length: at least 12 to 16 characters long. In the second case, it should be a mix of capital and small letters, numbers, and special characters so that it is made less likely to be guessed or cracked. Using different passwords for any other accounts increases the security even more because if a password gets leaked, then exposure is restricted to one account only.
68. How does encryption and decryption function as it relates to data protection?
Ans:
- Encryption is a process used to change plain text information into a cipher text format unreadable by any algorithm with a secret key.
- The encryption ensures that original data will only be accessed by the holder of the correct decryption key. It is used extensively in secure communications, financial transactions, and data protection.
- Decryption is its reverse process, which means, ciphertext is reconverted into the plaintext by using the right key.
- There are two most important kinds of encryption which are symmetric requires using the same kind of key for decryption and encryption asymmetric uses a pair of keys like public and private.
69. What is buffer overflow and risk associated with it?
Ans:
- Buffer overflow is a kind of program function flaw where writing more data into a buffer than it can handle cause it to overwrite the adjacent memory.
- Some of the risks of buffer overflow include the possibility of a program crash, data corruption, and what’s even worse – allowance of undesirable actors to perform arbitrary code run.
- Some of these dangers can be offset by employing secure coding techniques, employing languages that have built-in bounds checking, and employing security features like stack canaries and address space layout randomization (ASLR).
70. What is the difference between network security and application security?
Ans:
- Network security and application security constitute two independent areas that comprise the wider domain of cybersecurity.
- Each focuses on a separate domain concerned with system and data protection. Network security protects data integrity, confidentiality, and availability while being transmitted over a network.
- Firewalls, intrusion detection systems, and encryption are some mechanisms protecting data while in transport and preventing unauthorized access to network resources.
- They include the practice of secure coding, application and periodic security testing, and proper management of vulnerabilities. Both relate to overall security but belong to two different layers of protection, have different strategies and tools.
71. Why is software testing important in the development process?
Ans:
Software testing is very important because it gives quality assurance that the software will have at any given time before it hits the user’s hand. It is one form of examining for defects or bugs early so as to provide correction in timely steps before releasing to avoid costly postrelease issues. For a given set of requirements, it ensures that the system behaves in an expected manner under many such conditions. It further helps the user gain confidence in the software because it can make people perceive the software as more stable and secure if it has been properly tested.
72. What is the difference between unit testing and integration testing?
Ans:
Unit testing tests individual parts or functions of software to ensure that they work correctly. Here, each test targets small units of code, usually consisting of one function or method, and verifies behavior against expected outcomes. To then make sure several components or systems also work as required, integration testing takes place. Unit tests fix problems to a specific section of code, but integration tests reveal problems that can happen when parts of an application interoperate.
73. What are some common design patterns that could be used in software engineering?
Ans:
Standard solutions to recurring problems are standard designs in software engineering, meaning common patterns that create templates for more efficient building of software. The most common ones are the Singleton, enforcing one single instance of a class, the Factory, which allows instantiating objects without defining the concrete class, and the Observer, which enables an object to notify other objects regarding changes in state.
74. What are some of the most popular techniques that one may use to create hash functions?
Ans:
- Hash functions can be implemented using different techniques, including mathematical algorithms, bit manipulation, and cryptographic methods.
- Some of the common methods are Division method It divides the key with the help of a prime number. Multiplication Method Multiply a constant number by the key and use only the fraction part of that number.
- Such complex cryptographic hash functions like SHA-256 as well as MD5 require complex transformations that safeguard against security as well as collision resistance.
- More advanced methods include randomization techniques or a combination of multiple hashing algorithms to achieve better performance and distribution.
75. What can be reasons for which the file cannot be sorted efficiently?
Ans:
- There might be several factors that may affect the efficiency of file sorting. Some of these can be data size and a chosen algorithm for sorting.
- High-size datasets lead to inefficient disk I/O operations, due to which the process becomes slow.
- Other factors include the data’s input distribution especially when the data is nearly sorted, some algorithms are suboptimal. And then there are external factors like system load and limitations of hardware.
76. What is volatile keyword?
Ans:
- The volatile keyword, in C and C++, is used wherever a variable value may change unexpectedly, normally outside of the program’s control.
- Volatile is very helpful in multithreaded programming and hardware interfacing where the variables are being changed asynchronously by different threads.
- It prevents optimizations and thus ensures consistency and accuracy of the value of the variable across the program.
- Generally, volatile is crucial for reliable interaction with hardware and concurrent programming.
77. Write a C program without using semicolon to print ‘Hello world’.
Ans:
Here is a simple C program that prints “Hello world” without using a semicolon:
- #include
- int main() {
- if (printf(“Hello world\n”)) { }
- return 0;
- }
In this program, the printf function outputs “Hello world” and returns a non-zero value, allowing the if statement to execute without needing a semicolon. This approach demonstrates an unconventional way to control flow in C.
78. What is the difference between size of operator and strlen function?
Ans:
The sizeof operator in C and C++ is a compile time operator that returns the size, in bytes, of a variable or data type. This size operator is applied to all kinds of data types, such as primitive types, structures, and arrays of structures, returning an absolute memory size allocated. On the other hand, the strlen function is a runtime function meant specifically for the strings in the form of null terminated character arrays to determine the number of characters in a string excluding the NULL terminator.
79. What are the advantages of using version control systems in software development?
Ans:
- Collaboration: VCS enables multiple developers to work on the same project simultaneously without overwriting each other’s changes.
- History and Audit Trail: VCS maintains a complete history of changes, allowing developers to review previous versions of files,and trace the introduction of bugs or features.
- Branching and Merging: Developers can create branches to work on new features or fixes without affecting the main codebase.
- Backup and Recovery: A VCS acts as a backup, as it stores copies of the codebase at various points in time.
- Code Quality and Review: Many VCS support code review processes, where changes can be reviewed before merging into the main branch.
80. When does the compiler not automatically generate the address of the first element in an array?
Ans:
In many contexts, especially when the array is passed to a function as an argument, the compiler does not produce the address of the first element of an array. In this case, the array decays into its address that points at its first element hence, a pointer instead of the array is passed to the function. Furthermore, for instance, if the array is considered as a full type (for example, at sizeof when the size of the array is taken), then the address is automatically generated.
81. What is exit() equivalent to return?
Ans:
exit() and return are two completely different things in a program. exit() is an ordinary standard library function that instantly stops the whole program wherever it is called, with the ability to pass on an exit status to the operating system. In contrast, return is used for exiting from a function and returning control to the calling function. Though both are used to stop a program, the former exits a program in controlled way and allows destructors and cleanup code to be executed, whereas the latter does not.
82. What is lvalue?
Ans:
An lvalue is an expression which designates an object so modifying it changes its address too. It is a thing that occupies identifiable locations in memory, hence it possesses an address that needs to be modified. Examples include variables, array elements, and dereferenced pointers since they may appear on the left side of an assignment statement. Proper handling of memory and pointer operations can be achieved only if the difference between lvalue and rvalue is known in programming.
83. What are goto, longjmp() and setjmp?
Ans:
- goto, longjmp() and setjmp() are control flow statements but they differ in their operation. goto is a statement that unconditionally transfers control to another line of the same function, thus making code harder to read and maintain because of the potential jumps in logic.
- setjmp saves the current execution context – that is, the state of the stack and the contents of the program counter, etc- in a jump buffer, while longjmp restores that context, thus jumping back to the point saved by setjmp.
- This pairing allows non-local jumps between functions, which is useful for error-handling, but it also introduces some complications in control flow. In brief, goto is a simple local jump within the function, whereas setjmp() and longjmp() offer more sophisticated non-local control.
84. What is XOR linked list?
Ans:
- XOR linked list is a type of data structure that uses bitwise XOR operations to save memory by storing only one pointer per node instead of two.
- Such a structure allows to traverse the pointers in both directions forward goes by XORing the pointer at the current node with the address of the previous node; backward goes by XORing with the next node.
- Such an approach saves the overhead associated with using two pointers per node. However, it makes pointer arithmetic harder and is probably less intuitive to the average user than a conventional list.
85. What is ‘trie’ in data structure?
Ans:
- A unique kind of tree data structure called a trie, or prefix tree, is used to hold a dynamic set of strings where the keys are typically strings.
- A unique kind of tree data structure called a trie, or prefix tree, is used to hold a dynamic set of strings where the keys are typically strings.
- Every node in a trie represents a character of the string. Paths down the tree represent the prefixes of the stored strings.
- Tries are efficient for prefix searching, autocomplete features, and spell-checking since it allows for fast querying of stored strings.
86. What to understand by splay tree?
Ans:
A splay tree is a kind of self-adjusting binary search tree. It makes frequently accessed elements appear closer to the root improving their access times. Accessing a node performs a sequence of tree rotations-also known as splaying-that brings the accessed node to the root, optimizing subsequent operations. Splay trees thus are not strictly balanced but ensure amortized time complexity of O(log n) for search, insertion, and deletion operations.
87. What is Treap?
Ans:
A treap is a randomized binary search tree that satisfies both BST and heap properties simultaneously. In treap, each node has a key and a priority. The priorities are assigned randomly, so the treap remains approximately balanced in combination with these operations, insertion, deletion, and search have time complexity O(log n). Random priorities prevent worst-case scenarios that otherwise could happen in other tree structures.
88. How to implement a simple LRU caching scheme?
Ans:
- To implement an LRU (Least Recently Used) caching scheme, a hash map combined with a doubly linked list is very frequently used.
- The hash map is used to store key-value pairs so that they are accessible with a close-to-constant-time complexity, whereas the doubly linked list is essential to keep track of the order in which elements are used.
- If the number of objects within the cache fills up the cache, then it uses eviction where the least recently accessed object is removed, represented by the tail of the list.
- That way, it would maintain O(1) time complexity for both access and eviction operations, making it efficient for caching applications where quick retrieval and management of storage are of great importance.
89. What are the key differences between synchronous and asynchronous programming?
Ans:
This results in a blocking behavior where the program waits for tasks, such as I/O operations, to complete; this can sometimes result in decreased responsiveness. In asynchronous programming, on the other hand, tasks are allowed to run in parallel the program initiates an operation and proceeds to execute other code while waiting for that task to complete. Asynchronous code usually refers to the use of callbacks, promises, or async/await patterns to specify when operations are complete.
90. How many stacks need to implement a Queue?
Ans:
Can implement a queue using two stacks. For the enqueue operation, one uses a stack, and for the dequeue operation, another stack is used. If one wants to add an element it is pushed onto the first stack. But to get rid of an element, if the second stack is empty, then all elements from the first stack are popped and pushed onto the second stack, thus reversing the order of elements so that oldest is on top of the second stack for quick removal.




