
Last updated on 03rd Jul 2020| 3138
Questions about data manipulation, statistical analysis, and SAS software development are commonly seen in SAS (Statistical Analysis System) interviews. Data stages, procedures, SQL queries, macros, and statistical approaches are common topics. Interviewers may evaluate a candidate’s skill in writing effective and efficient SAS code in addition to their knowledge of data transformation, cleaning, and analysis. It may also be investigated to have experience with reporting software, data visualization, and problem-solving techniques. Questions may also cover applications particular to the sector, real-world problem-solving scenarios, and SAS certification..
1. What is SAS?
Ans:
SAS, which stands for Statistical Analysis System, is a comprehensive software suite for advanced analytics, data management, and business intelligence. It provides various tools for data manipulation, statistical analysis, reporting, and visual visualisation.
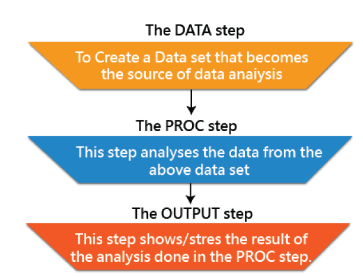
2. Differentiate between the DATA step and PROC step.
Ans:
| Aspect | DATA Step | PROC Step |
|---|---|---|
| Purpose | Data manipulation, creation, transformation | Statistical analyses, reporting, procedures |
| Operations | DATA statements for defining/manipulating datasets | PROC statements for specifying procedures. |
| Tasks | Reading, transforming, creating datasets | Statistical analysis, reporting, procedures |
| Focus | Manipulating the data itself | Higher-level procedures and analyses |
| Examples | Reading from external sources, creating variables | Running descriptive statistics, generating reports |
3. Define a SAS library.
Ans:
- A SAS library is a collection of one or more SAS files (datasets, catalogues, or external files) that are stored and referenced together.
- It is assigned a library reference and is a way of organising SAS datasets. The LIBNAME statement is used to define a SAS library and associate it with a physical location.
4. What is the purpose of the SAS log?
Ans:
The SAS log is a text file that records the details of a SAS session. It contains information about the execution of SAS code, including error messages, warnings, and notes. The SAS log is a valuable tool for debugging code, understanding the sequence of operations, and ensuring the correctness of the program.
5. How is a dataset created in the DATA step?
Ans:
In the DATA step, a dataset is created by using the DATA statement followed by the dataset name. Variables and their attributes are defined using the INPUT statement. The subsequent steps within the DATA step consist of programming statements to read, manipulate, and create observations for the dataset. The process concludes with the RUN statement.
6. Explain the difference between SET and MERGE statements.
Ans:
- The SET statement is used to read an existing dataset and copy its contents to the program data vector. It is primarily used for data manipulation and merging datasets with similar structures.
- On the other hand, the MERGE statement is used to combine two or more datasets based on a standard variable. It creates a merged dataset that includes observations from the input datasets.
7. What is the role of the WHERE statement in the DATA step?
Ans:
- The WHERE statement in the DATA step is used to subset observations based on specified conditions.
- It acts as a filter, allowing you to include only those observations that meet the specified criteria.
- This is useful for extracting or excluding specific subsets of data during data manipulation.
8. Describe the functions of the DROP and KEEP statements.
Ans:
- The DROP statement is used to exclude specific variables from a dataset, effectively removing them. This is useful when you want to work with a subset of variables.
- The KEEP statement is used to include only specific variables in the dataset, excluding all others.
- Both statements are handy for managing the variables in a dataset according to analysis requirements.
9. How do you handle missing values in SAS datasets?
Ans:
There are several methods to handle missing values in SAS datasets. You can use the IF-THEN statements in the DATA step to replace missing values with specific values or perform conditional imputation. Additionally, functions like COALESCE and IFN can be used to handle missing values. PROC SQL and other SAS procedures also provide options for handling missing values during analysis.
10. Explain the basic structure of a SAS program
Ans:
An SAS program consists of a series of steps, organising DATA steps and PROC steps. The DATA step is used for data manipulation, including reading, transforming, and creating datasets. PROC steps are used for statistical analyses, reporting, and other procedures. The program begins with a DATA step, followed by one or more PROC steps, and it ends with a RUN statement.
11. What is the purpose of the PROC PRINT statement?
Ans:
The PROC PRINT statement in SAS is used to display the contents of a dataset in the output window. It provides a detailed and formatted listing of the dataset, including variable names, values, and other information. PROC PRINT is useful for exploring the structure and contents of a dataset during the data exploration phase.
12. Explain the function of the SUM statement in PROCANS.
Ans:
In PROC MEANS, the SUM statement is used to calculate the sum of numeric variables within each group defined by the CLASS statement. It provides a summary statistic, showing the total of the specified variables for each subgroup. This is valuable for obtaining a quick overview of the total values within different categories in the data.
13. How is PROC FREQ used in SAS?
Ans:
PROC FREQ in SAS is used for frequency analysis. It provides counts and percentages of the occurrence of values in categorical variables. It can also produce various statistics, including chi-square tests for independence. PROC FREQ is commonly used to examine the distribution of categorical variables and identify patterns in the data.
14. Describe the purpose of the SORT procedure.
Ans:
The SORT procedure in SAS is used to arrange observations in a dataset in a specified order. It can sort data based on one or more variables in ascending or descending order. Sorting is often a prerequisite for certain analyses, merging datasets, or when creating summary reports. The SORT procedure helps organise efficient processing in subsequent steps.
15. What is the significance of the BY statement in SAS?
Ans:
- The BY statement in SAS is used to specify a grouping variable for observations in the dataset. It is particularly significant when used in conjunction with PROC steps.
- When data is sorted by the BY variable, SAS processes the data by groups defined by the BY variable .
- This is essential for creating summary reports, performing analyses on subsets, and generating statistics for each group.
16. Explain the role of the SUM function.
Ans:
The SUM function in SAS is used to calculate the sum of numeric values. It can be applied in both the DATA step and PROC steps. In the DATA step, it can create a new variable representing the sum of other variables. In PROC steps, especially PROC MEANS, SUM can be used to generate summary statistics, providing the total of specified numeric variables.
17. Differentiate between the functions SUBSTR and SCAN.
Ans:
- The SUBSTR function is used to extract a substring from a character variable based on the starting position and length specified.
- It allows you to manipulate and extract parts of a string. On the other hand, the SCAN function is used to extract words from a character string.
- It is particularly useful when dealing with space-delimited or comma-delimited lists. SCAN allows you to extract a specific word from a string based on its position.
18. What is the purpose of the PUT function?
Ans:
The PUT function in SAS is used to convert numeric values to character values. It is commonly employed in the DATA step to create character variables from numeric variables. PUT allows you to control the format of the output, specifying the appearance of the resulting character string. It is often used in conjunction with other character functions for string manipulation./
19. How do you use the LAG function in SAS?
Ans:
- The LAG function in SAS is used to retrieve the value of a variable from the previous observation.
- It is particularly useful in time-series analysis or whenever you need to compare the current observation with the preceding one.
- To use LAG, you include it in a DATA step, and you can reference it to access the value of a variable in the previous observation.
20. Describe the function of the CAT functions.
Ans:
-
The CAT functions in SAS, such as CAT, CATS, CATT, and CATX, are used for concatenating character strings.
- CAT concatenates without adding spaces between words.
- CATS concatenates with spaces removed between words.
- CATT concatenates with spaces added between words.
- CATX concatenates with a specified delimiter between words. These functions are valuable for creating new variables, labels, or formatting strings in a flexible and customise customizable
21. What is the purpose of formats in SAS?
Ans:
- Formats in SAS are used to control the appearance of data when it is displayed or printed.
- They define how variable values are formatted for output, making data more readable and meaningful.
- Formats are applied during data presentation in procedures like PRINT, REPORT, and FREQ. They help transform raw data into a more interpretable and user-friendly design.
22. Explain the difference between FORMAT and INFORMAT.
Ans:
- FORMAT: In SAS, a FORMAT is used to control the appearance of data when it is displayed or printed. It defines how data values are formatted for output. For example, you can use a format to display a numeric variable as a percentage or with a specific number of decimal places.
- INFORMAT: On the other hand, an INFORMAT is used to inform SAS how to read data from external sources. It is used during input operations to interpret raw data into SAS internal values. For instance, you might use an informant to read a date in a particular format.
23. How do you create a custom format in SAS?
Ans:
You can use the FORMAT procedure or the VALUE statement in the DATA step to create a custom format in SAS. The PROC FORMAT method involves defining the structure and associating it with a range of values.
24. What is the default format for the DATE variable in SAS?
Ans:
The default format for the DATE variable in SAS is DATE9. Format. This format displays the date in ‘ddMMMyyyy’ (e.g., 15DEC2023). If you want to show the date with the day of the week, you can use the WEEKDAY. Format.
25. Define a SAS macro.
Ans:
- A SAS macro is a set of reusable and parameter parameterized is defined once and executed multiple times within a SAS program.
- It allows for the automation of repetitive tasks and the creation of flexible and dynamic code. Macros are defined using the %macro and %mend statements.
26. Explain the difference between %LET and %GLOBAL statements.>
Ans:
- %LET: The %LET statement is used to create a local macro variable within a macro or a DATA step. Local macro variables are only accessible within the scope in which they are created.
- %GLOBAL: The %GLOBAL statement is used to create a global macro variable. Global macro variables have a wider scope and can be accessed from anywhere within the SAS session, even outside the macro or DATA step where they are defined.
27. How do you create a macro variable in SAS?
Ans:
- Macro variables in SAS can be created using the %LET statement.
- This creates a macro variable named my_variable with a value of 42. The macro variable can then be referenced using &my_variable in subsequent code.
28. What is the significance of the %DO loop in macros?
Ans:
- The %DO loop in macros is used to repetitively execute a block of code a specified number of times or based on a condition.
- It is valuable for creating dynamic and flexible code structures, especially when dealing with varying datasets or performing iterative tasks within a macro.
- %DO loops are often used in conjunction with %END to define the scope of the loop.
29. Describe the purpose of the %IF statement in macros.
Ans:
The %IF statement in macros is used for conditional processing. It allows you to include or exclude portions of code based on a specified condition. This is useful for creating flexible and adaptive macros that can handle different scenarios. The %IF statement is often paired with %THEN, %ELSE, and %ENDIF to structure conditional logic in macros.
30. Explain the use of PROC UNIVARIATE.
Ans:
PROC UNIVARIATE in SAS is used for univariate descriptive statistics and exploratory data analysis. It provides measures such as mean, standard deviation, skewness, kurtosis, and percentiles for continuous variables. It also produces graphical displays, including histograms and box plots, to help analyse the analysis of a variable.
Get Comprehensive SAS Training to Build Your Skills & Advance Your Career
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
31. What is the purpose of PROC CORR?
Ans:
PROC CORR in SAS is used for correlation analysis. It computes correlation coefficients between pairs of variables, such as Pearson, Spearman, and Kendall correlations. It helps identify relationships between variables and assess the strength and direction of those relationships.
32. Describe the difference between PROC ANOVA and PROC GLM.
Ans:
Both PROC ANOVA and PROC GLM are used to analyse variance (ANOVA) in SAS, but they differ in flexibility and features.
- PROC ANOVA: Primarily used for simple experimental designs. It’s straightforward to use for fundamental ANOVA analyses.
- PROC GLM (General Linear Model): Offers more flexibility and can handle complex experimental designs. It is an extension of PROC ANOVA, allowing for the inclusion of covariates and factorial methods.
33. How do you perform logistic regression in SAS?
Ans:
Logistic regression in SAS is typically performed using the PROC LOGISTIC procedure. Here’s an example:
- proc logistic data=mydata;
- model outcome_variable(event=’1′) = predictor_variable1 predictor_variable2
- run;
This code fits a logistic regression model where outcome_variable is regressed on predictor_variable1 and predictor_variable2. The event option is used to specify the event of interest (1 for binary outcomes).
34. What is the purpose of the FIRST? And LAST. Variables in SAS?
Ans:
- The FIRST. and LAST. Variables in SAS are automatic variables created in the DATA step when using BY-group processing.
- They help identify the first and last observations within each BY group. The variables take a value of 1 when true and 0 when false.
- These variables are helpful for conditional processing within the DATA step, especially when performing operations on the first or last observation in a group.
35. How do you transpose data in SAS?
Ans:
Transposing data in SAS can be done using the TRANSPOSE procedure or by manually restructuring the data in the DATA step. Here’s an example using PROC TRANSPOSE:
- proc transpose data=mydata out=transposed_data;
- by group_variable;
- var numeric_variable;
- id character_variable;
- run
This code transposes the data in my data by creating new variables for each unique value of character_variable within each group_variable.
36. Explain the use of the RETAIN statement.
Ans:
- The RETAIN statement in SAS is used in the DATA step to persist the value of a variable across iterations of the data step.
- It initialises a variable’s value on the first iteration, and the value is retained and carried forward to subsequent iterations.
- This is useful for accumulating values or maintaining a running total, especially when working with cumulative calculations.
37. Describe the purpose of the EXPAND procedure in SAS.>
Ans:
As of my last knowledge update in January 2022, there is no specific EXPAND procedure in SAS. However, if you’re referring to time series or econometric modelling, there are procedures like PROC EXPAND. PROC EXPAND is used for expanding and contracting time series data. It allows you to aggregate or interpolate time series data to different frequencies, helping to align data with a common time frame for analysis.
38. How do you generate a report in SAS?>
Ans:
In SAS, you can generate reports using various procedures such as PROC PRINT, PROC REPORT, PROC FREQ, and others. These procedures allow you to summarise, analyse, and present your data in a tabular or graphical format. You can customise the appearance and layout of the report using various options and statements within each procedure.
39. Explain the function of the ODS statement.
Ans:
- The Output Delivery System (ODS) statement in SAS is used to control the destination and format of output.
- It allows you to direct your SAS output to different destinations, such as HTML, PDF, RTF, etc. ODS provides a way to generate output in various formats and customise the appearance of the production.
40. What is the difference between LISTING and HTML output in SAS?
Ans:
LISTING is the default output destination in SAS, producing results in a plain text format. On the other hand, HTML output is generated using the ODS HTML statement. It produces results in HTML format, which is suitable for web-based viewing and can include formatting and hyperlinks.
41. How can you customise the appearance of the output in SAS?
Ans:
- You can customise the appearance of the output in SAS using the Output Delivery System (ODS). ODS allows you to choose the destination and format of the work, apply styles, control page layout, and customise titles and footnotes.
- Additionally, many SAS procedures have specific options and statements that allow you to customise the appearance of the output produced by those procedures.
42. How do you use SQL in SAS?
Ans:
SQL (Structured Query Language) can be used in SAS through the SQL procedure. You can write SQL queries within the PROC SQL statement to perform operations on SAS datasets.
43. Explain the difference between INNER JOIN and LEFT JOIN.
Ans:
- INNER JOIN: Returns only the rows where there is a match in both tables based on the specified join condition. Rows from either table without a partner are excluded from the result.
- LEFT JOIN (or LEFT OUTER JOIN): Returns all rows from the left (first) table and the matching rows from the right (second) table. If there is no match in the right table, NULL values are returned for columns from the right table.
44. Describe the purpose of the GROUP BY clause in SQL.
Ans:
The GROUP BY clause in SQL is used to group rows that have the same values in specified columns into summary rows, typically for aggregation purposes. It is often used with aggregate functions (such as SUM, COUNT, AVG) to perform calculations within each group.
45. What is the significance of the HAVING clause in SQL?
Ans:
The HAVING clause in SQL is used to filter the results of a GROUP BY clause. It allows you to specify conditions that must be met by the groups formed by the GROUP BY clause. It is similar to the WHERE clause but is applied after the grouping and aggregation have taken place.

Advance Your Skills with SAS Certification Course From Real-Time Experts
Weekday / Weekend BatchesSee Batch Details46. How do you debug a SAS program?
Ans:
- Debugging in SAS can be done using the PUT statement, DATA step debug options, and the interactive debugger.
- The PUT statement allows you to print variable values to the log. The OPTIONS MPRINT SYMBOLGEN statement can display macro variable and macro statement information.
- The interactive debugger can be activated using the DMDB or DMSAS command in the program editor.
47. Explain the use of the ABORT statement in SAS.
Ans:
The ABORT statement in SAS is used to stop the processing of the DATA step or the procedure immediately. It is often used conditionally within the program to terminate execution based on certain criteria.
48. What is the purpose of the ERRORS= option in the OPTIONS statement?
Ans:
- The ERRORS= option in the OPTIONS statement is used to control the number of errors that SAS will allow before terminating the program.
- For example, OPTIONS ERRORS=1 will cause SAS to stop execution after the first error is encountered.
49. How can you handle warnings in SAS?
Ans:
- Warnings in SAS can be handled by using the NOWARN system option or by selectively ignoring specific warnings using the NOWARN MSG option.
- Additionally, you can use conditional processing, log examination, and SAS options like NOWARN, NONOTES, and NOSOURCE to suppress warnings.
50. What techniques can be used for performance tuning in SAS?
Ans:
Performance tuning in SAS involves optimising code and data access. Techniques include indexing, minimising data movement, using appropriate WHERE statements, reducing unnecessary sorting, parallel processing, optimising joins, and leveraging hardware resources efficiently.
51. Explain the role of indexes in optimising SAS programs.
Ans:
- Indexes in SAS are used to optimise data retrieval performance. An index is a separate structure that stores sorted values of one or more variables.
- When SAS needs to access data based on the indexed variable, it can use the index to locate the relevant rows more quickly, resulting in faster data retrieval.
52. How do you reduce memory usage in SAS?
Ans:
-
To reduce memory usage in SAS, you can:
- Optimise your code to use fewer resources.
- Limit the size of datasets.
- Use compression techniques.
- Avoid unnecessary sorting.
- Optimise your use of BY-group processing.
- Minimise the use of temporary arrays and variables.
53. Describe the purpose of the VERIFY function.
Ans:
The VERIFY function in SAS is used to compare two character strings and determine whether they are identical. It returns the position of the first character that does not match or 0 if the strings are identical. It is often used for data validation and cleaning.
54. What methods can be used for data validation in SAS?
Ans:
Data validation in SAS can be performed using techniques such as:- Proc Compare for comparing datasets.
- Proc Contents for checking metadata.
- Integrity constraints in databases.
- Data cleaning steps like removing duplicates and handling missing values.
- Custom data checks using conditional logic in DATA steps.
55. How can you identify and handle duplicate records in a dataset?
Ans:
Duplicate records can be identified using procedures like PROC SORT and PROC FREQ. You can use the DATA step with the BY-group processing to handle duplicates to delete or modify duplicate records. The NODUPKEY option in PROC SORT can also remove duplicate records based on the specified vital variables.
56. How do you secure sensitive data in SAS?
Ans:
To secure sensitive data in SAS, you can implement measures such as:- Restricting access using SAS access controls.
- Using password protection for SAS datasets.
- Encrypting passwords.
- Applying file-level security.
- Employing secure network protocols.
- Limiting physical access to servers.
57. Explain the use of access controls in SAS.
Ans:
Access controls in SAS involve setting permissions and restrictions on who can access, modify, or execute SAS resources such as datasets, programs, and libraries. This is often done through access control lists (ACLs) or permissions at the file system level.
58. Describe the features of the SAS Enterprise Guide.
Ans:
SAS Enterprise Guide is a point-and-click interface for SAS that provides features such as:- Data exploration and manipulation.
- Visual programming for data analysis.
- Report generation and customization.
- Integration with SAS Studio and SAS programs.
- Metadata-driven design.
- Task automation and scheduling.
59. What is the purpose of password encryption in SAS?>
Ans:
Password encryption in SAS helps protect sensitive information by encrypting passwords stored in SAS metadata. It ensures that even if someone gains access to the metadata, they cannot easily retrieve or misuse diplomatic credentials.
60. How is data imported into the SAS Enterprise Guide?
Ans:
Data can be imported into the SAS Enterprise Guide using the Import Data task. You can connect to various data sources, including databases, Excel files, and CSV files. The Import Data task guides you through selecting a data source, specifying options, and importing the data into SAS.
61. Explain the process of creating a project in the SAS Enterprise Guide.
Ans:
Creating a project in the SAS Enterprise Guide involves:- Opening SAS Enterprise Guide.
- Selecting “File” -> “New” -> “Project.”
- Defining project properties and options.
- Adding data sources, programs, and tasks.
- Organizing and saving the project.
62. What is the role of PROC SQL in SAS?
Ans:
PROC SQL in SAS is used for Structured Query Language operations. It allows you to query, manipulate, and manage data using SQL syntax. PROC SQL can perform tasks like data retrieval, joining tables, creating and modifying tables, and aggregating data.
63. How can you create and use macros in SAS?
Ans:
Macros in SAS are created using the %macro and %mend statements. Macros can be called using %macro_name. Parameters can be passed to macros, and macro variables can be created and referenced using &varname. Macros are typically used for code reusability and automation.
64. Explain the concept of data warehousing in SAS.
Ans:
- Data warehousing in SAS involves the storage and management of large volumes of structured data for reporting and analysis.
- SAS provides tools like SAS Data Integration Studio to design, build, and manage data warehouses.
- Data warehousing facilitates efficient querying and reporting on historical and aggregated data.
65. What is the purpose of the CONTENTS procedure in SAS?
Ans:
The CONTENTS procedure in SAS is used to obtain information about the structure and attributes of a dataset. It provides details such as the number of observations, variables, variable types, formats, and labels. The CONTENTS procedure is useful for data exploration and documentation.
66. How is SAS used in clinical trials?
Ans:
- SAS is extensively used in clinical trials for data management, statistical analysis, and reporting. It helps organise and analyse data, create statistical reports, and ensure regulatory compliance.
- SAS programming is commonly used to generate tables, listings, and figures (TLFs) for clinical study reports.
67. Explain the role of CDISC standards in SAS.
Ans:
CDISC (Clinical Data Interchange Standards Consortium) standards define data structures for clinical research. SAS supports CDISC standards by providing tools to convert raw data to SDTM (Study Data Tabulation Model) and ADaM (Analysis Data Model) formats, ensuring consistency and interoperability in clinical trial data.
68. Describe the purpose of the SDTM and ADaM models.
Ans:
SDTM organizes and standardizes raw data collected in clinical trials, making it easier to share and submit to regulatory agencies. Adam structures data for statistical analysis. Both models enhance efficiency and consistency in clinical trial data management and reporting.
69. How can SAS be used for data mining?
Ans:
SAS offers data mining tools like SAS Enterprise Miner. These tools employ techniques such as decision trees, clustering, neural networks, and regression to uncover patterns and relationships in data. SAS data mining tools are used for predictive modelling, segmentation, and risk assessment.
70. Describe the machine learning capabilities of SAS.
Ans:
- SAS provides machine learning capabilities through tools like SAS Viya.
- SAS supports a wide range of machine learning algorithms for tasks such as classification, regression, clustering, and text analytics.
- SAS Viya facilitates distributed and parallel computing for large-scale machine learning tasks.
71. Explain the use of PROC ARIMA in SAS.
Ans:
PROC ARIMA in SAS is used for time series analysis. It fits autoregressive integrated moving average (ARIMA) models to time series data. It helps analyze trends, seasonality, and autocorrelation in time series data, making it valuable in forecasting and prediction.
72. What are the benefits of obtaining a Base SAS certification?
Ans:
A Base SAS certification demonstrates proficiency in SAS programming essentials. Benefits include improved job prospects, enhanced skills in data manipulation and analysis, recognition of SAS expertise, and increased confidence in using SAS for various tasks.
73. Describe the structure of the Base SAS certification exam.
Ans:
The Base SAS certification exam consists of multiple-choice questions and requires a passing score. Topics include data manipulation, data analysis, data management, and basic programming concepts using SAS.
74. How can you prepare for the Base SAS certification exam?
Ans:
Preparation involves studying SAS programming essentials, data manipulation techniques, and understanding basic statistical concepts. Practising with SAS software, taking sample exams, and reviewing SAS documentation can enhance readiness.
75. How is SAS used in finance and banking?
Ans:
SAS is widely used in finance and banking for risk management, fraud detection, customer analytics, and regulatory compliance. It helps analyse large datasets, build predictive models, and make data-driven decisions to optimise financial processes.
76. How do you integrate SAS with other programming languages?
Ans:
-
SAS can be integrated with other programming languages using techniques like:
- SAS/CONNECT for remote computing.
- SAS Integration Technologies for Web Services.
- Using the X command in SAS to execute orders in other languages.
- Leveraging the SAS Integration Technologies Toolkit for Java and . NET.
77. Describe the applications of SAS in the retail industry.
Ans:
SAS is used in retail for customer segmentation, demand forecasting, inventory management, and marketing analytics. It helps retailers understand consumer behaviour, optimise pricing strategies, and enhance the overall shopping experience.
79. Describe the methods for importing and exporting data in SAS.
Ans:
-
Data can be imported into SAS using:
- PROC IMPORT for various file formats.
- DATA step with INFILE statement for raw data files.
- LIBNAME statement for accessing databases. Data can be exported using:
- PROC EXPORT for various file formats.
- DATA step with FILE statement for raw data files.
- LIBNAME statement for exporting to databases.
78. Explain the role of SAS in the telecommunications sector.
Ans:
In the telecommunications sector, SAS is used for customer churn analysis, network optimization, fraud detection, and personalised marketing. It helps telecom companies leverage data to improve customer satisfaction, network performance, and business operations.
80. What do you think are the future trends in SAS and analytics?
Ans:
-
Future trends in SAS and analytics may include:
- Increased use of AI and machine learning.
- Integration with open-source tools.
- Expansion of cloud-based analytics.
- Enhanced automation and optimization.
- Continued focus on interpretability and explainability.
81. How is SAS adapting to the advancements in artificial intelligence and machine learning?
Ans:
SAS is adapting by incorporating AI and machine learning capabilities into its software. SAS Viya, for example, provides a platform for advanced analytics and machine learning. SAS also supports open-source integration to leverage tools like Python and R.
82. Can you provide an example of a challenging data manipulation task you have encountered and how you resolved it?
Ans:
One challenging task involved merging large datasets with complex relationships. I optimised the process by using appropriate indexing, parallel processing, and optimising the join conditions. Additionally, I used SAS options and features like SORTSIZE to manage memory efficiently.
83. What coding standards do you follow in SAS programming?
Ans:
-
Coding standards include:
- Consistent indentation and formatting.
- Meaningful variable and dataset names.
- Proper use of comments.
- Efficient use of functions and procedures.
- Consistent use of naming conventions.
84. Describe a situation where you optimised a SAS program for better performance.
Ans:
I optimised a program by reducing unnecessary sorting, minimising the use of temporary datasets, and optimising the WHERE statement. I also employed indexing, avoided unnecessary nested loops, and used parallel processing where applicable to enhance overall performance.
85. Explain the importance of documentation in SAS programming.
Ans:
Documentation is crucial for:- Understanding and maintaining code.
- Facilitating collaboration among team members.
- Ensuring code is reproducible.
- Providing a reference for future modifications.
- Enhancing code transparency and auditability.
86. How do you manage version control in SAS programs?
Ans:
Version control in SAS can be managed using external version control systems like Git. SAS Studio also provides basic version control features. Regularly committing changes, maintaining a history, and documenting changes are essential practices.
87. Describe the benefits of using version control systems in SAS development.
Ans:
Benefits include:- Tracking changes and maintaining a history of modifications.
- Enabling collaboration among team members.
- Facilitating code review processes.
- Providing a mechanism for branching and merging.
- Ensuring code integrity and reproducibility.
88. Explain the role of the SGPLOT procedure in creating graphs in SAS.
Ans:
PROC SGPLOT is a versatile procedure for creating a wide range of graphs in SAS. It allows users to create scatter plots, bar charts, line plots, and box plots. It provides extensive customization options for appearance, labels, and annotations.
89. What tools or procedures do you use for data visualisation in SAS?
Ans:
SAS provides various tools for data visualisation, including:- PROC SGPLOT for creating high-quality graphs.
- SAS Visual Analytics for interactive and exploratory visualisations.
- ODS Graphics for customising output appearance.
- Integration with open-source tools like Python’s Matplotlib.
90. How can SAS be integrated with cloud computing platforms?
Ans:
SAS can be integrated with cloud platforms like AWS, Azure, and Google Cloud through:- SAS Viya, a cloud-native analytics platform.
- SAS Cloud Analytics Services for cloud-based analytics.
- Leveraging cloud storage and database connectors in SAS.
91. Describe the advantages of using SAS in a cloud environment.
Ans:
Advantages include:- Scalability for handling large datasets and computing resources.
- Flexibility in terms of on-demand computing.
- Collaboration and accessibility from anywhere.
- Integration with other cloud services.
- Cost-effectiveness in terms of resource usage.
92. How do you collaborate with other team members in a SAS development project?
Ans:
Collaboration involves:- Using version control systems for code sharing.
- Regular communication through meetings and documentation.
- Leveraging collaborative features in SAS environments.
- Sharing and documenting best practices.
- Conducting code reviews for quality assurance.
93. How is licensing managed in SAS deployments?
Ans:
SAS licensing involves obtaining licences for specific products or solutions. Licensing can be managed through SAS License Manager, which allocates and monitors licences based on user access and usage.
94. Explain the role of version control in collaborative SAS projects.
Ans:
Version control is essential for collaborative projects to:- Track changes made by team members.
- Ensure consistency across code versions.
- Facilitate code review processes.
- Enable efficient collaboration and coordination.
- Maintain an audit trail of modifications.
95. What considerations are essential when deploying SAS in an enterprise environment?
Ans:
Considerations include:- Hardware and software requirements.
- Scalability and performance.
- Security and access controls.
- Integration with existing systems.
- Backup and recovery processes.
- Monitoring and maintenance procedures.
96. Describe your experience with SAS communities and forums.
Ans:
SAS communities and forums are valuable for:- Seeking help and solutions for coding challenges.
- Sharing best practices and tips.
- Keeping updated with the latest developments.
- Networking with other SAS professionals.
- Contributing by answering questions and sharing knowledge.
97.How do you stay updated with the latest developments in SAS?
Ans:
Staying updated involves:- Regularly reading SAS documentation and release notes.
- Participating in SAS webinars and training sessions.
- Engaging with SAS communities and forums.
- Attending SAS conferences and events.
- Exploring SAS blogs and publications.
98. Have you attended any SAS conferences or training sessions?
Ans:
Yes, attending SAS conferences and training sessions is valuable for gaining insights into new features, best practices, and networking with other SAS professionals.
99. How do you contribute to the SAS community?
Ans:
Contribution can involve:- Sharing knowledge through forums and blogs.
- Providing solutions to coding challenges.
- Participating in discussions and webinars.
- Writing articles or tutorials.
- Mentoring and assisting other SAS users.
100. How is regression analysis performed in SAS?
Ans:
Regression analysis in SAS is typically performed using the PROC REG procedure.
Here’s a simple example:- proc reg data=mydata;
- model dependent_variable = independent_variable1 independent_variable2;
- run;
This code fits a linear regression model where dependent_variable is regressed on independent_variable1 and independent_variable2. The model statement specifies the variables in the regression equation.




