
Last updated on 23rd Oct 2024| 7080
ETL, or Extract, Transform, Load, is an essential data management process that involves extracting data from multiple sources, transforming it into an appropriate format, and loading it into a target database or data warehouse. This process allows organizations to consolidate and analyze data effectively, maintaining high standards of data quality and integrity. ETL is crucial for supporting business intelligence and decision-making by delivering accurate and timely insights from various data sources.
1. What is ETL, and why is it important in data warehousing?
Ans:
ETL represents the process of pulling information from various origins, transforming it into forms usable for analysis, and then loading it into a data warehouse. It’s very important for the integration of diverse data, for quality and consistency, and also for proper implementation of analysis and reporting. ETL supports data warehousing as the backbone of informed decision-making.
2. What are the differences between ETL and ELT?
Ans:
These ETLs preprocess before loading into the target system, with transformation as the primary focus to ensure the quality and structure of the data. ELT is actually the extraction of data followed by loading it to the target first and then transforming it with the processing power of the target system. It has a greater advantage in cloud based and big-data scenarios.
3. What are the key challenges involved in an ETL process?
Ans:
- Key ETL challenges include ensuring data quality across sources, handling multiple data formats, and managing high volumes.
- Incremental loading and schema changes can be complex. Data governance and security requirements are also major factors in the process.
- Additionally, integrating data from disparate systems while maintaining performance can further complicate the ETL workflow.
4. How is incremental data loading handled in ETL?
Ans:
- Incremental data loading controls changes since the last load, primarily accomplished with timestamps or Change Data Capture (CDC).
- This approach reduces data processing, leading to shorter load times and lower resource usage. Applying a staging area simplifies the tracking and loading of new or modified records.
- Furthermore, it enhances data integrity by allowing validation before final loading into the target system.
5. What does a full load differ from an incremental load?
Ans:
| Aspect | Full Load | Incremental Load |
|---|---|---|
| Definition | Transfers all data from the source to the target system, regardless of previous loads. | Only processes new or changed records since the last load. |
| Data Volume | Typically involves a larger volume of data. | Involves a smaller, manageable volume of data. |
| Frequency | Often used for initial data imports or periodic refreshes. | Conducted regularly to keep data up to date. |
| Performance Impact | Can be resource-intensive and time-consuming. | More efficient, reducing processing time and resources. |
| Historical Data | Does not retain historical changes; only the latest version is loaded. | Preserves historical changes by updating only what has changed. |
6. What is data transformation in ETL? What is its significance?
Ans:
Data transformation converts raw data into a usable format, involving cleaning, aggregating, and standardizing data. This step ensures homogeneity and enhances data quality, making it suitable for analysis. Proper transformation is necessary for deriving accurate insights and supporting effective decision-making. Moreover, well-transformed data facilitates the integration of information from various sources, leading to more comprehensive and reliable analyses.
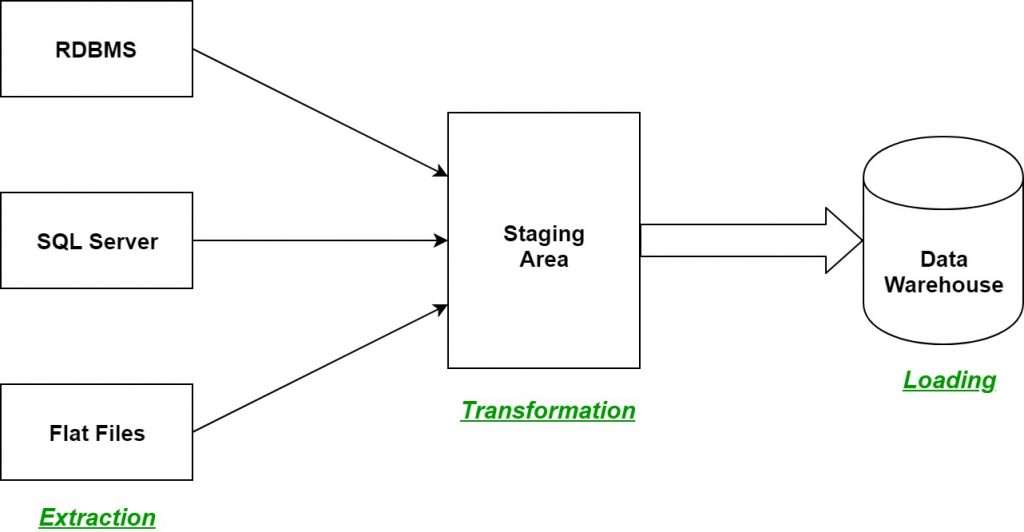
7. Describe the differences between staging, transformation, and target layers in the ETL pipeline.
Ans:
- The staging layer holds the raw data extracted from source systems temporarily for initial processing. It is the transformation layer where the data is cleansed, aggregated, and transformed into a suitable format for analysis.
- The target layer serves as the final destination, such as a data warehouse, where the processed data is stored. This structured approach ensures that data is organized and readily accessible for reporting and analysis, ultimately supporting informed decision-making.
8. What are common ETL techniques for data cleansing?
Ans:
- Common data cleaning techniques include removing duplicates, standardizing formats, correcting errors, and addressing missing values.
- Data profiling helps identify quality issues during the early stages of the ETL process. Validation rules ensure that only high-quality data enters the data warehouse.
- Automated cleaning processes can also enhance efficiency and consistency in maintaining data quality throughout the ETL workflow.
9. What methods handle data inconsistencies in an ETL workflow?
Ans:
The processes involved include validating data using rules to identify erroneous entries, looking up standard tables to support standardization, and implementing transformation logic designed to eliminate inconsistencies. Data profiling helps detect inconsistencies before they impact the ETL process. Regular auditing is the best way to ensure consistent data quality. Moreover, implementing automated monitoring tools can enhance the detection of anomalies, leading to quicker resolutions and improved data integrity.
10. What is a slowly changing dimension (SCD), and how is it managed in ETL?
Ans:
A slowly changing dimension (SCD) is a dimension in a data warehouse that changes infrequently over time rather than undergo frequent updates. Managing SCDs in ETL involves adopting strategies that accurately capture and store these changes while retaining historical data. Common methods include Type 1, which replaces existing data; Type 2, which generates new records to preserve historical accuracy; and Type 3, which records limited history by adding additional columns.
11. What are the different types of slowly changing dimensions?
Ans:
- Type 1: This method overwrites existing data with new values, removing the historical record. It’s suitable for attributes where historical data isn’t important, such as correcting a spelling mistake in a name.
- Type 2: This approach preserves complete historical records by creating new entries for each change. A versioning system is typically used, where a new row is added, and existing rows are marked with effective dates. This allows for thorough historical analysis.
- Type 3: This type tracks a limited history by adding extra columns to the existing record. For instance, it might store the current and previous values in separate columns. This is useful when only a snapshot of recent changes is required.
12. What is the purpose of using surrogate keys in ETL?
Ans:
- Surrogate keys are artificial IDs created to replace natural keys used in data warehousing. This approach reduces joins, speeds up queries, and disengages the data warehouse from operational systems.
- Surrogate keys also facilitate the handling of slowly changing dimensions without reliance on business keys that may become volatile.
- Additionally, surrogate keys enhance data integrity by providing a consistent identifier for records, even as the underlying data changes over time.
13. Describe how data quality can be ensured during ETL processes.
Ans:
- Data quality can also be ensured by implementing validation checks at the extraction and transformation stages, along with rule-driven verification for integrity and consistency checks of the data.
- Techniques such as data profiling can help identify issues early in the ETL process. Regular audits and cleansing methods further enhance the overall quality of data.
- Furthermore, integrating automated monitoring tools can provide real-time alerts for anomalies, enabling timely corrective actions to maintain high data quality standards.
14. How is data validation incorporated into ETL pipelines?
Ans:
Data validation is the validation of data per predefined rules and checks to ensure the integrity and accuracy of ETL data. This kind of validation can be done at the data type level, completeness check, or even at the value level concerning the realization of business rules. To achieve data validation, automated scripts may assist in speeding up the process and providing differences for further review.
15. How the data deduplication process is done in an ETL process?
Ans:
Data deduplication identifies and eliminates duplicate records based on key fields using match algorithms. In ETL processes, filters ensure unique records are loaded into the target system. This practice significantly improves data quality and integrity. Additionally, implementing regular deduplication checks helps maintain a clean dataset over time, reducing the risk of errors in reporting and analysis.
16. What are the best practices for designing effective ETL workflows?
Ans:
- Best practices include setting clear objectives, employing modular designs to enhance maintainability, and implementing robust error-handling mechanisms.
- Transformations can be optimized for performance, and parallel processing can be utilized to increase efficiency. Regular monitoring and performance tuning are essential for ongoing optimization.
- Additionally, comprehensive documentation of ETL processes aids in knowledge transfer and facilitates troubleshooting, ensuring long-term success in data management initiatives.
17. Discuss data recovery plans for failures in ETL.
Ans:
- Data recovery techniques include checkpointing during data loading, saving progress, creating backup copies of source and target data, and implementing tracking for rollbacks in transaction logs.
- ETL design should be idempotent to avoid issues from repeated runs. Additionally, establishing clear protocols for data recovery ensures quick restoration in case of failures, minimizing downtime and maintaining data integrity throughout the ETL process.
18. How are lookup tables used in an ETL process?
Ans:
- Checkpointing during the loading of data.
- Saving progress.
- Creating backup copies of source and target data.
- Implementing tracking for rollbacks in transaction logs.
ETL design should be idempotent to avoid issues from repeated runs. Additionally, establishing clear protocols for data recovery ensures quick restoration in case of failures, minimizing downtime and maintaining data integrity throughout the ETL process.
19. What is data partitioning in ETL, and what are its advantages?
Ans:
Data partitioning is a technique through which big datasets are divided into smaller ones, mainly concerning characteristics that may include date or region. This enhances performance as it improves parallel processing and simplifies data handling. The ability to query data more efficiently leads to overall better ETL performance and process times.
20. What actions can be taken to enhance the performance of the ETL process?
Ans:
- Scalability can be achieved through parallel processing, minimizing data movement via near-source processing, and utilizing bulk loading instead of row-by-row inserts.
- Regular monitoring, profiling, and tuning of ETL processes contribute to performance improvements. Additionally, leveraging cloud-based solutions can enhance scalability by providing on-demand resources to accommodate fluctuating data loads and processing requirements.
21. How to handle different source data formats (JSON, XML, CSV) in ETL?
Ans:
- ETL will process different data formats received from the sources using specific parsers or connectors built for each. JSON and XML would often be delivered along with some extract-and-transformation ETL tools in processing data.
- CSV files are very easy to process using standard file-handling techniques. All cleansing and transformation are performed to yield consistency across formats before final loading into the target system.
22. What is metadata, and how is it used in ETL processes?
Ans:
Metadata describes other data. This context revolves around the structure, origin, and usage of the data. In ETL processes, metadata enables tracing lineage, transformations, and business rules applied to the data. Good metadata management facilitates data governance and compliance, and a better understanding of data flows through the ETL pipeline. It’s an important resource for users and administrators.
23. How does ETL ensure scalability?
Ans:
One achieves scalability in ETL processes by designing modular workflow workflows that support parallel execution and distributed processing across multiple servers. In ETL solutions in a cloud, resources can be scaled dynamically in response to volume and data processing needs. Efficient strategies for data partitioning and incremental loading enhance scalability and lead to a system that maintains its ability to continue scaling as data grows.
24. Explain ETL checkpoints and their purpose.
Ans:
- ETL checkpoints are marks in the ETL process; they track progress and enable recovery in case of failures.
- Checkpoints can save the process’s state at defined intervals, which allows the ETL jobs to resume from the last successful point and not begin again from the very start.
- The process saves on data loss or otherwise takes less processing time and improves the reliability and efficiency of ETL operations.
25. How are ETL jobs scheduled and monitored?
Ans:
- For scheduling ETL jobs, the built-in scheduling features of ETL tools and even job schedulers outside the tool are used. Users can execute jobs automatically at defined times, frequencies, and dependencies.
- Dashboard monitoring of the running jobs is usually done. This displays the status, time, and error rates for a job so that any problems can be identified promptly and addressed accordingly.
- Failures or performance deviations can be set up to alert stakeholders.
26. What is ETL logging, and how does it apply in practice?
Ans:
ETL logging creates information about the running of the ETL process by executing the start time, end time, data loads, transformations, and error messages. It is implemented by configuring logging options in the ETL tool that capture relevant events and write them to log files or databases. This information is critical for troubleshooting, auditing, and optimizing ETL performance over time.
27. Describe how historical data is managed in ETL.
Ans:
The following techniques are used in managing history: Slowly Changing Dimensions (SCD) manages changes in data over time. It can do either of these an ETL process may insert new records for the changes, keep track of previous values, or even create separate historical tables to allow reporting and analysis. Users need both historical and current data to make their decisions.
28. What are common ETL errors and their troubleshooting procedures?
Ans:
- Common ETL errors include type mismatches, connectivity, and transformation. Troubleshooting would require validation checks, cleansing procedures, and incorporating strong error handling in the ETL workflow.
- Errors will be logged so that the source of the problem can be tracked for future tracing. Data quality checks prevent similar issues in future loads. Audits often determine areas for improvement.
29. How to Secure the ETL process?
Ans:
- Secure connections, such as SSL/TLS and data encryption, ensure security in the ETL process.
- Role-based access management only allows certain individuals to view or change sensitive data. Regular auditing ensures that the security policies remain compliant at all times.
- Data masking and anonymization can protect sensitive information during the process. However, continuous monitoring for unauthorized access is required.
30. How does ETL load balancing work at scale?
Ans:
In large-scale environments, ETL load balancing is typically distributed across multiple nodes or servers to optimize resource usage through parallel processing and dynamic allocation based on workload. This approach ensures that no server is overwhelmed by the loads, thereby enhancing the performance and reliability of the entire system. Additionally, implementing automated scaling can further adapt to varying data volumes, ensuring consistent performance during peak times.
31. What ETL tools have been worked on, and what are their main features?
Ans:
Popular ETL tools include Informatica, Talend, and Apache NiFi. The main features of Informatica include rich transformation capabilities, extended connectivity options, and enterprise-level features. Talend is popular for its flexibility in being open-source and friendly user interface along with cloud integration capabilities. Apache NiFi performs effective management for data flow and real-time data ingestion and provides a rich set of processors to handle a variety of data sources.
32. Describe the Informatica PowerCenter platform and its components and how it operates
Ans:
- Informatica PowerCenter is an ETL tool that extracts data from several sources, transforms it, and loads it into target systems.
- Some of its main components are the Repository, which can be termed as the storehouse for metadata; the Designer, which creates the mappings; the Workflow Manager, which is responsible for scheduling and job monitoring; and the Integration Service, which runs the ETL process.
- This architecture supports complex data integration scenarios and facilitates efficient management of data.
33. How does Talend compare with other ETL tools?
Ans:
- Talend is different from the other ETL tools, like Informatica and SSIS. The open-source platform will be due to which flexibility and cost-effectiveness come into the picture.
- Talend has a friendly interface and easy support for drag-and-drop functionality to build a data pipeline. It is great at cloud integration and big data capabilities, but Informatica is quite often the leader in features with an enterprise-level approach to scalability.
- So, the tool to be chosen will depend on the requirements of a particular project and what would serve its organizational needs.
34. How do SQL Server Integration Services work in ETL?
Ans:
SSIS is a Microsoft ETL tool that makes the extraction, transformation, and loading process easy. Users have to represent the workflow graphically as the source, transformations, and destination of the data. SSIS uses special flow, error handling, and logging tasks to present ETL processes as efficient and robust. It is seamlessly integrated with SQL Server for proper data management in the Microsoft environment.
35. How does Informatica handle errors?
Ans:
Informatica also ensures the processing of errors with a session property that users can configure and define how the error should be handled during data loading. Errors may be routed into error tables so that the primary process is not affected and can be reviewed accordingly. Detailed logging captures the error message, enabling the developer to identify and resolve problems. This approach helps avoid data inconsistencies and prevents frequent interruptions in ETL runs.
36. How are reusable transformations created in Talend?
Ans:
- Designing components or subjobs that can be saved in the Talend repository for later use can achieve reusable transformations in Talend.
- Users can define parameters inside these components, which adapt well to various contexts in different jobs. This modular design encourages consistency at the ETL workflow level without causing redundancy.
- Reusable transformations make development tasks much more manageable and improve maintainability.
37. What are the key features of Apache NiFi for ETL processing?
Ans:
- The main Apache NiFi features associated with ETL data processing include managing data flow, real-time data ingest, and tracking data provenance.
- The web-based interface is intuitive, and one can easily create and monitor the data flow. It is capable of processing various data formats and protocols that may be used in data integration scenarios.
- Additionally, built-in processors improve the effectiveness of data transformation and enrichment during processing.
38. What are the fundamental elements of Pentaho Data Integration, also known as Kettle?
Ans:
Pentaho Data Integration, lately known as Kettle, comprises several components, including Spoon, the graphical interface for designing ETL jobs; Kitchen, the command-line tool to execute the jobs; and Pan, which is applied for running transformations. Jobs and transformations are also stored in the Repository, so people can easily manage and share these. Its architecture also supports a wide array of data sources and offers numerous built-in transformations for data processing.
39. Explain how a data flow is created in SSIS.
Ans:
In SSIS, data flow is organized by the Data Flow Task in a control flow. The design surface had droppable components such as sources, transformations, and destinations to configure their configuration. Each element is configured to specify how the data should be extracted, transformed, and loaded. Connections between the components define the data flow, allowing for seamless ETL operations and facilitating effective data integration.
40. How does Informatica schedule jobs?
Ans:
- In Workflow Manager, users define workflows and set start times, frequency, and other dependencies. Informatica offers both time-based and event-based scheduling support.
- This implies that the job can be triggered at certain points in time or by certain events.
- Users can configure alerts and notifications to track the job status and results. Third-party integration with scheduling can also augment Informatica’s scheduling for more complex ETL environments.

Get JOB ETL Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
41. What is the difference between SSIS control and data flow?
Ans:
- Control flow in SSIS governs the execution order of tasks and how they are executed within a package. It includes elements such as containers, precedence constraints, and functions that dictate workflow logic.
- In contrast, data flow refers to the movement and transformation of data between sources and destinations. Data flow components manage data extraction, transformation, and loading (ETL), focusing on data processing rather than task sequencing.
- Thus, control flow manages task execution, while data flow manages data handling.
42. How does Talend Studio handle big data ETL operations?
Ans:
Talend Studio manages big data ETL operations by integrating with Hadoop and Spark frameworks. It provides components specifically designed for processing large datasets, allowing users to create jobs visually. Talend’s architecture enables distributed execution, optimizing performance and scalability. Additionally, it offers connectors for various big data sources, facilitating efficient data retrieval and transformation. This capability makes Talend suitable for handling extensive ETL processes in big data environments.
43. What is a mapping in ETL tools like Informatica?
Ans:
A mapping in ETL tools like Informatica defines how data is transformed from source to target systems. It includes specifying source and target data structures and the transformations applied during the ETL process. Mappings guide the data flow, outlining any business rules or calculations needed for data transformation. They can incorporate transformations such as filters, joins, and aggregations. Effective mappings ensure accurate data integration and processing.
44. Describe how data mapping works in Talend.
Ans:
- In Talend, data mapping involves defining how data from source systems is transformed and loaded into target systems.
- Users create mappings using a graphical interface, dragging and dropping components representing source and target schemas. Transformations can be directly applied within the mapping, allowing for data cleansing, conversion, and enrichment.
- Talend supports the creation of reusable mappings, and its expression language enables the implementation of complex logic. This flexibility enhances data integration capabilities.
45. How is a stored procedure transformation created in Informatica?
Ans:
- To create a stored procedure transformation in Informatica, users add the “Stored Procedure” transformation to a mapping and configure it by selecting the appropriate database connection where the stored procedure resides.
- Parameters for the stored procedure can be defined to enable input and output values. The transformation can be linked to other components in the mapping to facilitate data flow.
- This integration allows users to leverage stored procedures for efficient data processing within their ETL workflows.
46. Describe how connection managers are configured in SSIS.
Ans:
Connection managers in SSIS are configured to establish connections to various data sources and destinations. Users can add connection managers in the SSIS package designer by selecting the type of connection needed, such as SQL Server, OLE DB, or Flat File. Necessary connection properties are specified, such as server name, database name, and authentication details. Once configured, connection managers can be reused across multiple tasks within the package. Proper configuration ensures efficient data flow and access to required data sources.
47. Explain the purpose of an aggregator transformation in Informatica.
Ans:
The aggregator transformation in Informatica performs aggregate calculations on groups of data. It allows users to summarize data using functions like SUM, AVG, COUNT, and others applied to specified groupings. This transformation processes data based on defined groups by columns, enabling the creation of summary reports or metrics. It is essential for generating insights from large datasets, as it efficiently calculates key performance indicators during the ETL process. Proper use of the aggregator transformation streamlines data analysis.
48. How is job orchestration set up in Talend?
Ans:
- Job orchestration in Talend is set up by designing workflows that manage the execution order of various ETL jobs.
- Users create job designs in Talend Studio and can use the Job Conductor or Talend Administration Center (TAC) to schedule and monitor job execution.
- Talend supports defining dependencies between jobs, enabling complex orchestration based on specific conditions. Users can also set alerts and notifications to track job status and performance, ensuring effective management of ETL processes.
49. What is the Data Flow Task in SSIS, and how is it used?
Ans:
- The Data Flow Task in SSIS extracts transforms, and loads (ETL) data from various sources to destinations. It allows users to design a data flow pipeline incorporating components such as sources, transformations, and destinations.
- Users define how data moves and what transformations are applied within this task. The Data Flow Task is crucial for data integration processes, facilitating efficient data movement and processing across different formats and structures.
50. Describe how parallel processing can be implemented in Informatica.
Ans:
Parallel processing in Informatica can be implemented by utilizing multiple sessions and partitioning data. Users can create separate sessions for different tasks, allowing them to run concurrently. Additionally, Informatica supports data partitioning, which divides data into subsets processed simultaneously across multiple nodes. This approach enhances performance and reduces overall processing time. Proper configuration of the Informatica server and workflows ensures efficient resource use during parallel execution.
51. Write a SQL query to remove duplicate records from a table.
Ans:
- DELETE FROM table_name
- WHERE id NOT IN (
- SELECT MIN(id)
- FROM table_name
- GROUP BY column1, column2, column3
- );
This query removes duplicate records based on specified columns, keeping only the record with the minimum ID.
52. What is a join, and what are the different types of joins in SQL?
Ans:
- INNER JOIN: Returns records with matching values in both tables.
- LEFT JOIN (or LEFT OUTER JOIN): Returns all records from the left table and matched records from the right; unmatched records from the right will have NULLs.
- RIGHT JOIN (or RIGHT OUTER JOIN): Returns all records from the right table and matched records from the left; unmatched records from the left will have NULLs.
- FULL JOIN (or FULL OUTER JOIN): Returns all records when there is a match in either left or right table records.
- CROSS JOIN: Returns the Cartesian product of the two tables, combining all rows from both tables.
53. Explain techniques for optimizing SQL queries for performance.
Ans:
- Indexing: Create indexes on frequently queried columns to speed up data retrieval.
- Query restructuring: Rewrite queries to minimize complexity and reduce the number of joins where possible.
- Using WHERE clauses: Filter data early in the query to limit the amount processed.
- Avoiding SELECT *: Specify only necessary columns to reduce the data volume.
- Analyzing execution plans: Use execution plans to identify bottlenecks and optimize performance accordingly.
54. Write a query to perform a full outer join.
Ans:
- SELECT a.*, b.*
- FROM table_a a
- FULL OUTER JOIN table_b b ON a.id = b.id;
This query retrieves all records from ‘table_a’ and ‘table_b’, matching them where possible and returning NULLs for non-matching records.
55. Describe using the ‘GROUP BY’ clause for aggregations in SQL.
Ans:
The ‘GROUP BY’ clause in SQL groups rows with the same values in specified columns into summary rows. It is commonly used with aggregate functions like COUNT, SUM, AVG, MIN, and MAX to perform calculations on grouped data. For example, it calculates total sales per customer or average scores per subject. The ‘GROUP BY’ clause follows the ‘FROM’ clause and precedes the ‘ORDER BY’ clause in a query. Proper use of ‘GROUP BY’ enables effective data summarization.
56. Write a query to fetch the top 5 highest salaries from a table.
Ans:
- SELECT DISTINCT Salary
- FROM employees
- ORDER BY salary DESC
- LIMIT 5;
57. Explain the difference between ‘WHERE’ and ‘HAVING’ clauses in SQL.
Ans:
- The ‘WHERE’ clause filters records before any groupings are made, applying conditions to individual rows in a table. It cannot be used with aggregate functions.
- The ‘HAVING’ clause filters records after groupings have been made, typically with the ‘GROUP BY’ clause, allowing conditions on aggregated data.
- Thus, ‘WHERE’ filters rows while ‘HAVING’ filters groups, making them suitable for different stages of query execution.
58. Write a query to find records present in one table but not another.
Ans:
- SELECT *
- FROM table_a
- WHERE id NOT IN (SELECT id FROM table_b);
This query retrieves all records from ‘table_a’ where the ‘id’ is not present in ‘table_b’, effectively showing the differences between the two tables.
59. Explain how indexing improves query performance in SQL.
Ans:
- A quick lookup mechanism.
- Enabling the database to locate data without scanning every row.
- Thus reducing processing time.
This enhancement significantly speeds up query execution. However, while indexes improve read operations, they can slow down write operations due to the overhead of maintaining them. Properly designed indexes are crucial for optimizing overall query performance.
60. How are NULL values handled in SQL queries?
Ans:
- NULL values in SQL represent missing or unknown data and require special handling. Conditions involving NULL must use ‘IS NULL’ or ‘IS NOT NULL’ operators, as NULL is not equal to anything, including another NULL.
- Functions like ‘COALESCE()’ and ‘IFNULL()’ can replace NULLs with specified values during query execution. Aggregates generally ignore NULLs unless explicitly included.
- Proper management of NULL values is essential for accurate data analysis and reporting.

61. Write a SQL query to get the second-highest value in a column.
Ans:
- SELECT MAX(column_name) AS second_highest
- FROM table_name
- WHERE column_name < (SELECT MAX(column_name) FROM table_name);
This query returns the maximum value less than the maximum value in the column provided, thus returning the second largest value in a computationally efficient manner.
62. Describe how correlated subqueries work in SQL.
Ans:
- Subqueries correlate reference columns from the outer query and are executed once for each row processed by the outer query.
- They are typically used for row-by-row comparisons while filtering results based on related data in other tables, making them highly effective for tasks that require dependent conditions.
- Additionally, their ability to dynamically adjust based on the outer query’s context enhances flexibility in complex data retrieval scenarios.
63. Describe the use of window functions in SQL for ETL operations.
Ans:
Window functions can perform calculations across a group of rows related to the current row without collapsing the result set. Various operations, such as running totals, rankings, and moving averages, can be executed using window functions, which are crucial in ETL for transforming and aggregating data. This capability helps deliver valuable insights from the data. Furthermore, window functions enhance analytical queries by allowing for complex calculations while maintaining the integrity of the original dataset.
64. What is the difference between ‘UNION’ and ‘UNION ALL’ in SQL?
Ans:
‘UNION’ combines result sets from two or more queries and removes duplicate records, ensuring a unique output. In contrast, ‘UNION ALL’ retains duplicates, improving performance by not requiring the removal process. The choice between them depends on whether duplicates are acceptable in the results. Additionally, using ‘UNION ALL’ can be particularly beneficial in scenarios where performance is critical and the data integrity of duplicates is not a concern.
65. Write a query using the ‘CASE’ statement in SQL.
Ans:
- SELECT employee_id,
- salary,
- CASE
- WHEN salary < 50000 THEN 'Low'
- WHEN salary BETWEEN 50000 AND 100000, THEN ‘Medium’
- ELSE ‘High’
- END AS salary_range
- FROM employees;
This query categorizes employee salaries into ranges based on defined thresholds, making it easier to analyze salary distributions.
66. Describe how to pivot rows into columns using SQL.
Ans:
- There are still other ways to transpose rows into columns, such as using the ‘PIVOT’ function or conditional aggregation with ‘CASE’ statements.
- Using conditional aggregation, summary reports can be generated easily by unpivoting row values to be used as column headers. This approach is beneficial for analytical purposes when dealing with structured data.
- Furthermore, leveraging these techniques allows for greater flexibility in data presentation, enabling clearer insights and easier interpretation of complex datasets.
67. What is SQL Common Table Expression (CTE) knowledge?
Ans:
- A common table expression, or CTE, is a temporary result set named in a ‘WITH’ clause and available for later reference within a SQL statement or set of statements.
- CTEs can greatly simplify complex queries by organizing data streams within a query. They are particularly useful when working with recursive queries and hierarchical data.
- Additionally, CTEs enhance the readability and maintainability of SQL code, making it easier for developers to understand and modify complex query logic.
68. Describe how data aggregates and groups in SQL.
Ans:
The SQL tool aggregates data by summing it up through functions like ‘SUM’, ‘AVG’, ‘COUNT’, and ‘MAX’. Data grouping occurs with the ‘GROUP BY’ clause, where common values in rows are combined to create summary rows. This process allows meaningful insights to emerge from large datasets, enabling proper report analysis. Moreover, incorporating the ‘HAVING’ clause provides for filtering grouped data, further refining results based on aggregate conditions.
69. How is large data handled in SQL?
Ans:
Technologies used for handling big data include indexing to optimize query performance, partitioning of tables for better management, and materialized views for fast retrieval of summary data. Queries are also optimized, and old data is archived frequently to maintain efficiency. Monitoring performance is essential for scalability, ensuring systems adapt to growing data volumes. Additionally, leveraging distributed computing frameworks can enhance processing capabilities and allow real-time data analysis.
70. Write an SQL query that deletes orphaned records in a database.
Ans:
- DELETE FROM child_table
- WHERE parent_id NOT IN (SELECT id FROM parent_table);
This query finds and removes orphaned records in ‘child_table’ by finding records in ‘child_table’ with ‘id’s not having corresponding records in ‘parent_table’.
71. What is the difference between a data warehouse and a database?
Ans:
- A data warehouse is designed to optimize querying large datasets to support analytical reporting and data analysis. On the other hand, a database is optimized for transaction processing and real-time data retrieval, focusing on current operational data.
- Data warehouses support historical data analysis, while databases handle current data.
- Additionally, the architecture of a data warehouse allows for integrating data from multiple sources, providing a comprehensive view that aids in strategic decision-making.
72. How do OLAP systems differ from OLTP systems?
Ans:
- OLAP-based systems are optimized for read-heavy queries and complex analysis of large volumes of historical data.
- On the other hand, OLTP is primarily a real-time transaction-processing system that emphasizes speed and data integrity for concurrent user access.
- These two systems address different business requirements and use cases. Furthermore, while OLAP supports strategic decision-making through data analysis, OLTP ensures efficient day-to-day operations and organizational transaction management.
73. How does ETL fit into the data warehouse build process?
Ans:
The extraction, transformation, and loading of data from various sources into the data warehouse, including transforming that data into a meaningful format, is considered vital in consolidating data. The ETL processes enhance the quality of the data, make the data consistent, and integrate it with complete assurance so that effective reporting and analysis can be done. It is considered a very important building block for successful data warehousing.
74. What is a star schema? How does it differ from a snowflake schema?
Ans:
- A star schema is denormalized, consisting of a central fact table surrounded by dimension tables. This maximizes query performance and simplifies access.
- In contrast, a snowflake schema introduces complexities with normalized dimension tables. Star schemas are easier to navigate, while snowflake schemas save storage space.
- Additionally, the choice between these schemas often depends on the organization’s specific analytical needs, balancing performance with storage efficiency and query complexity.
75. How is data modelling performed for a data warehouse?
Ans:
Data modelling involves describing the data warehouse structure and defining facts, dimensions, and their associated relationships. Styles such as entity-relationship and dimensional modelling are employed to build schemas catering to business needs. This process ensures that the warehouse facilitates efficient reporting and analysis. Moreover, effective data modelling is crucial for scalability, allowing the data warehouse to adapt as business requirements evolve and new data sources are integrated.
76. What distinguishes a fact table from a dimension table?
Ans:
A fact table stores numerical data that will be used to facilitate analysis, such as sales amounts or transaction counts. It typically contains foreign keys pointing into dimension tables. A dimension table stores descriptive attributes related to the facts, providing context for analysis, such as product names or customer details. This relationship allows for detailed reporting in data warehouses.
77. How are surrogate keys implemented in a data warehouse?
Ans:
- Surrogate keys are artificial, unique identifiers that replace natural keys in a data warehouse. They simplify joins, speed queries, and decouple the warehouse from operational systems.
- Surrogate keys facilitate managing slowly changing dimensions while maintaining historical integrity and improving data consistency.
- Additionally, using surrogate keys allows for more flexible data modelling, as business logic or operational system changes do not disrupt the underlying data structure.
78. What are the steps involved in data warehouse testing?
Ans:
- Testing a data warehouse involves requirement verification, data validation, performance testing, and regression testing.
- These activities ensure data integrity, consistency, and accuracy between source systems and the warehouse. Additionally, they confirm that ETL processes function correctly and that reporting tools provide accurate results.
- Furthermore, comprehensive testing helps identify potential issues early in the process, reducing the risk of errors in data analysis and decision-making.
79. How is data versioning implemented in a data warehouse?
Ans:
Data versioning applies Slowly Changing Dimensions (SCD) and temporal tables. Methods like these manage historical changes by maintaining records with effective dates for updates to dimension attributes. This approach simplifies querying historical data, tracking time-dependent changes, and viewing change patterns over time. Additionally, it enhances data integrity by providing a clear audit trail of how and when data has evolved, supporting better decision-making based on historical trends.
80. What is the purpose of a data mart in data warehousing?
Ans:
A data mart is an extraction of a subset of data that focuses on an area or department, such as marketing or finance, to allow one to access certain information faster. It is tailored to each department’s needs without flooding the users with information that can overwhelm them in reporting and analysis. Data marts may exist independently or be part of a much larger data warehouse architecture.
81. What is data lineage tracked at a data warehouse?
Ans:
- A data warehouse tracks data lineage by documenting the flow of data through a transformation from an origin into a final destination. This metadata describes transformation processes, integration points, and how data moves from one system to another.
- The data lineage can be explained with the assistance of tools and software, where stakeholders can identify where the data originated, what transformations it may have undergone, and its dependencies.
- Data lineage plays an important role in complying with, auditing, and debugging processes within a data warehouse. It assures transparency and supports data governance efforts.
82. What role does metadata play in a data warehouse?
Ans:
Metadata in a data warehouse acts as “data about data”. It should provide key information about the warehouse’s structure, definitions, and management of stored data. This includes data such as its types, the sources from which it originates, transformation rules, and their inter-relations. Metadata helps users understand the context and meaning of data. In short, metadata helps efficiently retrieve and analyze data.
83. What common data aggregation techniques are used in a data warehouse?
Ans:
- AVG: Calculates an average value of numeric data.
- COUNT: Indicates the number of rows or unique values in a dataset.
- GROUP BY: Summarizes data based on one or more columns, where perform aggrgations.
- ROLLUP and CUBE: Extend GROUP BY to give subtotals and grand totals across several dimensions.
- These methods are important for preparing summary reports and getting insights from a data warehouse.
84. How can data integrity be maintained within a data warehouse?
Ans:
- Data validation: It provides checks to validate the data for correctness and completeness during ETL processes.
- Consistency checks: Ensure that data is consistent with predefined rules and standards.
- Audit trails: Keep data change and transformation log; the data history if there are problems.
- Regular data cleansing: Identifying inaccuracies or inconsistencies in the data and correcting those inaccuracies.
- Referential integrity constraints: Define the relationships between tables to ensure that data is valid and consistent.
85. What are conformed dimensions, and why are they important?
Ans:
Conformed dimensions are those common across more than one fact table in a data warehouse; this means they imply the same meaning and structure. This enables similar reporting and analysis from different businesses or subject areas. Conformed dimensions ensure that users aggregate and compare data correctly based on other data sources. This importance is derived from cross-functional reporting and generating one perspective of data that helps improve decision-making and removes ambiguity incurred with analytics.
86. How does a data warehouse handle slowly changing dimensions (SCDs)?
Ans:
A data warehouse manages slowly changing dimensions (SCDs) using various strategies to track historical data changes. The most common approaches include Type 1, which updates existing data without retaining history, and Type 2, which creates new records to preserve historical accuracy. Type 3 allows a limited history by adding new columns to track changes. These methods enable the warehouse to capture and represent changes in dimension attributes over time effectively.
87. What is dimensional modelling, and how is it applied in data warehousing?
Ans:
Dimensional modelling is an approach for designing data in a data warehouse to support query and reporting activity. It focuses on fact definition, which involves measurable data, and dimension definition, which includes descriptive attributes for a star or snowflake schema. This modelling technique simplifies complex data relations and enhances query performance due to fewer joins needed. Dimensional modelling in data warehousing involves:
- Identifying key business processes.
- Identifying relevant dimensions.
- Designing fact tables that capture pertinent metrics to those processes.
88. Explain how an ETL process is designed for a real-time data warehouse.
Ans:
- An ETL process for a real-time data warehouse is designed to accommodate non-stop data ingestion and transformation.
- It normally utilizes CDC methods to capture real-time changes from source systems and extract data changes based on their occurrence.
- The ETL process usually employs stream or micro-batch processing to load data into the warehouse with minimal latency.
- It also has error handling capability and the validation of the data, thereby ensuring quality data.
89. What are the best practices for ETL design within a data warehouse?
Ans:
Best Practices for ETL Design in a Data Warehouse. The best practices for designing ETL in the Data Warehouse include Modular Design. The ETL procedure is split into numerous reusable, user-friendly modules, which makes it easier to maintain and scalable.
- Performance optimization: Optimize ETL processes to run at speed by reducing data volume, making most transactions in bulk operations, and indexing.
- Data validation: Validate data for accuracy by checking at multiple stages of the ETL process.
- Documentation: Maintain ETL workflows with clarity on changes in transformations and data lineage to build transparency and ensure governance.
90. Describe ways to measure and improve data warehouse performance.
Ans:
Measuring and enhancing data warehouse performance involves various strategies. First, tracking query execution times and resource usage helps pinpoint bottlenecks. Implementing indexing can significantly accelerate data retrieval while partitioning large tables enables more efficient data access and management. Regularly analyzing and optimizing ETL processes ensures that data loading does not hinder performance. Additionally, materialized views can boost response times for complex queries by pre-aggregating data.




