
Last updated on 04th Jul 2020| 3103
SAP Business Intelligence (BI) is a comprehensive suite of tools and applications designed to enable organizations to extract, analyze, and interpret data from various operational systems. It integrates with SAP’s ERP (Enterprise Resource Planning) systems and other data sources, providing a robust platform for reporting, data analysis, and decision-making.
At its core, SAP BI encompasses various components, such as SAP Business Warehouse (BW) that serves as a centralized data warehouse, SAP HANA for in-memory computing capabilities, and SAP BusinessObjects for reporting and visualization. These components work together to gather, store, process, and analyze vast amounts of structured and unstructured data, supporting both historical reporting and real-time analytics.
Q1. What is SAP BI (Business Intelligence)?
Ans:
SAP BI, which stands for SAP Business Intelligence, is a comprehensive suite of business intelligence tools and applications developed by SAP. It is designed to help organizations collect, process, and analyze data from various sources, enabling data-driven decision-making and improving overall business performance. SAP BI includes tools for data extraction, transformation, loading, reporting, and data visualization, allowing businesses to gain valuable insights from their data.
Q2 . Explain the key components of SAP BI
Ans:
SAP BI comprises several key components, including:
- Data Warehousing: This component stores and manages structured data from various sources, providing a single source of truth for reporting and analysis.
- ETL (Extract, Transform, Load): ETL tools in SAP BI extract data from source systems, transform it to meet business requirements, and load it into the data warehouse.
- Data Modeling: Data modeling involves designing the structure and relationships of data within the data warehouse using InfoObjects, InfoCubes, and DataStore Objects.
- Reporting and Analysis: SAP BI offers various reporting and analysis tools like BEx (Business Explorer), Web Intelligence, Crystal Reports, and SAP Lumira.
- Security and Authorization: SAP BI includes security features to control data access and ensure data integrity.
- Performance Optimization: To ensure efficient data processing and fast query performance.
- Data Governance: Ensuring data quality, consistency, and compliance.
- Integration with Other SAP Modules: SAP BI can integrate with SAP ECC, SAP BW/4HANA, SAP BusinessObjects, and SAP HANA for enhanced functionality.
- Transport and Deployment: Managing the movement of objects and data between development and production environments.
Q3. What is the difference between SAP BW and SAP BI?
Ans:
In the earlier days of SAP, SAP BW (Business Warehouse) was the name for SAP’s business intelligence solution. However, over time, the product evolved and the name was changed to SAP BI (Business Intelligence). Essentially, SAP BW is a part of SAP BI. So, there is no substantial difference between the two terms today. SAP BI encompasses a broader set of tools and functionalities, including data warehousing, ETL, data modeling, reporting, and more, while SAP BW refers specifically to the data warehousing and modeling aspects of SAP BI.
Q4. How does SAP BI contribute to business decision-making?
Ans:
SAP BI plays a pivotal role in supporting business decision-making through the following means:
- Data Consolidation: SAP BI collects data from diverse sources and stores it in a central repository, providing a single source of truth for decision-makers.
- Data Transformation: It transforms raw data into meaningful, structured information, making it suitable for analysis.
- Data Analysis: With reporting and analysis tools, SAP BI allows users to perform in-depth analysis of data, uncovering insights and trends.
- Real-time and Historical Data: Decision-makers can access both real-time and historical data to make informed choices.
- KPI Monitoring: Key performance indicators (KPIs) are monitored through dashboards and reports, enabling users to track business performance.
- Predictive Analytics: SAP BI provides capabilities for predictive analytics, helping organizations anticipate future trends and make proactive decisions.
Q5. What is a Data Warehouse in the context of SAP BI?
Ans:
In SAP BI, a Data Warehouse is a central repository that stores and manages large volumes of structured data from various sources, such as operational systems and external databases. It is designed to support reporting, analysis, and decision-making by providing a unified and historical view of the organization’s data. Data Warehouses in SAP BI are optimized for query performance and typically employ ETL processes to extract, transform, and load data from source systems into a structured format suitable for reporting and analysis.
Q6. Describe the process of data modeling in SAP BI.
Ans:
Data modeling in SAP BI involves designing the structure and relationships of data within the Data Warehouse. It includes defining InfoObjects, InfoCubes, DataStore Objects (DSOs), and other data structures, as well as specifying how data is loaded, transformed, and accessed. The process typically includes requirements analysis, designing data models, creating relationships between data objects, and optimizing data structures for efficient reporting and analysis.
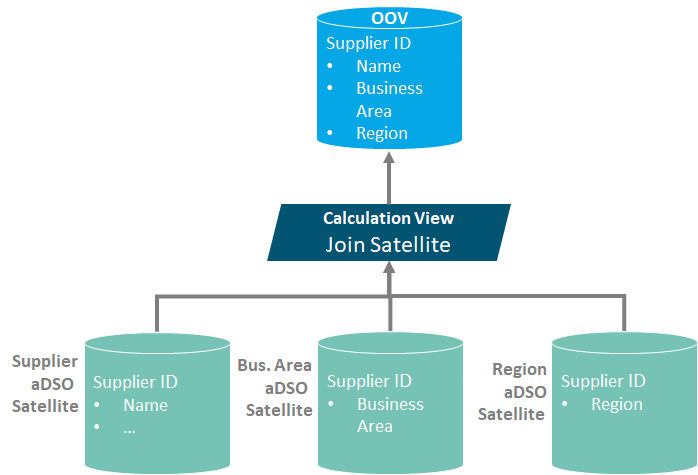
Q7. What are InfoObjects in SAP BI?
Ans:
InfoObjects in SAP BI are fundamental building blocks used in data modeling. They represent characteristics, key figures, and time-related attributes in a Data Warehouse. InfoObjects define the structure and semantics of data elements. There are different types of InfoObjects, including characteristics (master data attributes), key figures (quantitative data), units, and time-related attributes. InfoObjects are essential for creating InfoCubes, DataStore Objects, and other data structures in SAP BI.
Q8. Explain the purpose of DataStore Objects (DSO) in SAP BI.
Ans:
DataStore Objects (DSOs) in SAP BI are used to stage and store data before it is further processed and loaded into InfoCubes or other data targets. They act as a temporary storage area for data in its most granular form. DSOs provide flexibility in data processing, enable data transformation, and support real-time data loading. They are particularly useful for scenarios where data needs to be stored and harmonized before being used for reporting and analysis.
Q9. What is an InfoCube in SAP BI, and how is it different from a DSO?
Ans:
An InfoCube in SAP BI is a data structure that stores data in a multidimensional, highly compressed form, optimized for efficient reporting and analysis. Unlike a DSO, InfoCubes are not meant for data staging or temporary storage. They are used for long-term data storage, aggregations, and query performance. InfoCubes have dimensions (characteristics) and measures (key figures) and are the core data storage objects for reporting.
Q10. What is a MultiProvider in SAP BI, and when is it used?
Ans:
A MultiProvider in SAP BI is a logical container that allows you to combine data from multiple InfoProviders (such as InfoCubes and DSOs) into a single virtual InfoProvider. It is used when you need to provide a unified view of data that is spread across different InfoProviders. MultiProviders simplify data access for reporting and analysis without physically consolidating the data.
Q11. What is a CompositeProvider, and how does it differ from a MultiProvider?
Ans:
A CompositeProvider in SAP BI is an advanced concept that allows you to combine data from multiple InfoProviders, just like a MultiProvider. However, it differs in that it can include complex data transformations and calculations directly within the CompositeProvider itself. This makes it suitable for scenarios where you need to perform complex data operations before presenting the data to end-users.
Q12. How do you create aggregates in SAP BI?
Ans:
Aggregates in SAP BI are created to improve query performance. To create aggregates, you typically follow these steps:
- Identify the InfoCube for which you want to create an aggregate.
- Define the aggregation level by selecting the relevant characteristics and key figures.
- Build the aggregate, which involves summarizing and precalculating data.
- Activate the aggregate for use in queries.
Q13. What are the advantages of using aggregates in SAP BI data modeling?
Ans:
The advantages of using aggregates in SAP BI data modeling include:
- Improved query performance: Aggregates reduce the query response time by precalculating and storing summarized data.
- Lower resource consumption: Aggregates reduce the load on the system, as queries can retrieve data from aggregates rather than processing detailed data.
- Enhanced user experience: Faster query response times lead to a better user experience and increased productivity.
- Scalability: Aggregates can be designed to scale with growing data volumes.
- Efficient reporting: Aggregates support complex reporting needs by providing pre-aggregated data for specific business scenarios.
Q14. What is ETL (Extract, Transform, Load) in the context of SAP BI?
Ans:
ETL, which stands for Extract, Transform, Load, is a crucial process in SAP BI that involves extracting data from source systems, transforming it to meet business requirements, and loading it into the Data Warehouse for analysis and reporting. In the context of SAP BI, ETL tools and processes are used to ensure data consistency, quality, and compatibility with the Data Warehouse structures.
Q15. Describe the different types of data sources in SAP BI.
Ans:
In SAP BI, there are various types of data sources, including:
- Database Systems: These can include relational databases, such as Oracle, SQL Server, or SAP HANA.
- SAP Systems: SAP ERP systems, SAP CRM, SAP SRM, and other SAP applications.
- Flat Files: Files in formats like Excel, CSV, or XML.
- Non-SAP Systems: Data from non-SAP sources, such as external partners, suppliers, or customers.
Q16. What is the purpose of a Data Transfer Process (DTP) in SAP BI?
Ans:
A Data Transfer Process (DTP) in SAP BI is used to move and transform data from a source to a target, typically from staging areas like DataStore Objects (DSO) to InfoProviders. DTPs provide a way to extract data from a source, apply transformations and filters, and load it into a target structure. They are essential for data movement and data quality control within the SAP BI landscape.
Q17. How does SAP BI handle data transformation and mapping?
Ans:
SAP BI handles data transformation and mapping through various ETL processes and tools. Data transformation involves converting, cleaning, and enriching the data to make it suitable for reporting. Data mapping defines the relationships between source and target data objects. SAP BI provides tools like InfoPackages, transformations, and InfoProviders to define and execute these transformations and mappings.
Q18. Explain the significance of Data Transformation in SAP BI.
Ans:
Data transformation is significant in SAP BI because it ensures that raw data from source systems is converted into a format that is consistent, meaningful, and aligned with the business requirements. This process includes tasks like data cleansing, aggregation, derivation, and enrichment. Data transformation is essential for accurate reporting and analysis, as well as for maintaining data quality and consistency.
Q19. What is a Data Source in SAP BI?
Ans:
A Data Source in SAP BI is a structure that represents a connection to a specific source system. It defines how data is extracted from the source and includes information about data fields, keys, and extraction methods. Data Sources are used as templates for creating DataSource objects that enable data extraction from source systems into the SAP BI environment.
Q20. How do you extract data from SAP ERP systems into SAP BI?
Ans:
To extract data from SAP ERP systems into SAP BI, you typically follow these steps:
- Define a DataSource: Create a DataSource in SAP BI that corresponds to the data you want to extract from the SAP ERP system.
- Establish a connection: Configure the connection between SAP BI and the SAP ERP system, specifying the necessary parameters, such as the system and client.
- Create an InfoPackage: Create an InfoPackage to define the extraction settings, such as selection criteria and extraction frequency.
- Execute the InfoPackage: Run the InfoPackage to trigger data extraction from the SAP ERP system into the staging area (e.g., DataStore Object) in SAP BI.
- Perform data transformations: Apply necessary data transformations and mappings using transformations, DTPs, and other ETL processes.
- Load data to InfoProvider: Finally, load the transformed data into the relevant InfoProvider (e.g., InfoCube) for reporting and analysis.
Q21. What is the process of data loading in SAP BI?
Ans:
The data loading process in SAP BI involves the extraction, transformation, and loading of data from source systems into the SAP BI Data Warehouse. It typically follows these steps:
- Data Extraction: Data is extracted from source systems using DataSources or other extraction methods.
- Data Transformation: Extracted data undergoes transformation and mapping to meet business requirements.
- Data Staging: Transformed data is temporarily stored in staging areas, such as DataStore Objects (DSO) or InfoCubes.
- Data Loading: Transformed and staged data is loaded into the Data Warehouse’s InfoProviders, like InfoCubes, DataStore Objects, or MultiProviders.
- Data Activation: The loaded data is activated to make it available for reporting and analysis.
Q22. Explain the concept of data activation in SAP BI.
Ans:
Data activation in SAP BI is the final step in the data loading process. It involves making the loaded data available for reporting and analysis. During activation, the data is optimized for query performance, and indexes are built to speed up data retrieval. Activated data is then accessible to users for creating reports and performing analytics.
Transformation rules: Transformation rules are used to map source fields and target fields. Different rule types can be used for transformation.
Q23. How do you monitor the data load process in SAP BI?
Ans:
You can monitor the data load process in SAP BI through various tools and processes, including:
- Process Chains: Using process chains to schedule and monitor data loading processes.
- Data Load Monitors: These provide detailed information about data load jobs, including status and statistics.
- Data Transfer Process (DTP) Monitors: Monitoring DTPs for data transfer and transformation processes.
- Job Monitoring: Using SAP BW Job Monitoring to track and manage background jobs related to data loading.
Q24. What is the purpose of the Process Chain in SAP BI?
Ans:
A Process Chain in SAP BI is a sequence of data loading and transformation processes that can be scheduled and executed as a single unit. It is used to automate and manage complex data loading scenarios, ensuring data consistency and efficient use of system resources. Process Chains provide a way to orchestrate the flow of data from source systems to InfoProviders, including data extraction, transformation, and activation.
Q25. What is Data Mart and how is it related to SAP BI?
Ans:
A Data Mart is a subset of a Data Warehouse and is designed to serve the specific reporting and analysis needs of a particular business unit, department, or group within an organization. Data Marts are often used to optimize data retrieval and analysis for specific user groups. In the context of SAP BI, Data Marts can be created as a part of the Data Warehouse structure, using InfoCubes or other InfoProviders, to store data that is relevant to a particular business area.
Q26. What is the role of a Data Packet in the SAP BI data loading process?
Ans:
A Data Packet is a subset of data that is extracted, transformed, and loaded into the SAP BI system as part of a data loading process. Data Packets help organize the data loading process and can be used to optimize the load of large datasets. Data Packets are processed in smaller, manageable portions to improve system performance and minimize the impact on other system activities.
Q27. How do you handle delta updates in SAP BI?
Ans:
Delta updates in SAP BI refer to the incremental loading of data changes (i.e., new or modified data) from source systems. To handle delta updates, you typically use delta mechanisms like:
- Delta DataSources: These are DataSources that can extract only the changed data from source systems, reducing the amount of data transferred.
- Delta Queue: Data changes are collected in a delta queue and then extracted incrementally into SAP BI.
- Change Pointers: A mechanism in SAP ERP that identifies changes and updates data in the delta queue.
- Process Chains: Process Chains are used to schedule and automate delta extraction, transformation, and loading processes. Delta updates help keep the Data Warehouse up-to-date with real-time or near-real-time data changes from source systems.
Q28. What is BEx (Business Explorer) in SAP BI?
Ans:
BEx, or Business Explorer, is a set of business intelligence tools and applications within SAP BI that enables users to access, analyze, and present business data. BEx provides a user-friendly interface for creating and running queries, reports, and interactive dashboards, making it easier for business users to access and utilize data for decision-making.
Q29. Explain the different types of BEx tools.
Ans:
BEx tools in SAP BI include:
- BEx Query Designer: Used for creating and modifying queries for data retrieval and analysis.
- BEx Analyzer: Provides a Microsoft Excel-based interface for ad-hoc reporting and analysis.
- BEx Web Application Designer: Allows the creation of interactive web-based applications and reports.
- BEx Report Designer: Used for designing formatted and structured reports for print or export.
- BEx Web Analyzer: A web-based tool for creating and viewing web reports and dashboards.
- BEx Information Broadcaster: Enables the distribution of reports and queries via various channels.
- BEx Mobile: Provides access to BI content on mobile devices.
Q30. What is a BEx Query in SAP BI?
Ans:
A BEx Query in SAP BI is a predefined request for data retrieval and analysis. It is created using the BEx Query Designer and specifies the data sources, key figures, characteristics, filters, and display settings. BEx Queries allow users to extract and present data from the Data Warehouse for reporting and analysis purposes.

Get In-Depth Knowledge in SAP BI Training From Expert Trainers
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
Q31. How do you create and execute BEx queries?
Ans:
To create and execute BEx queries in SAP BI, you typically follow these steps:
- Use the BEx Query Designer to design and create a query by selecting the data sources, key figures, characteristics, and layout settings.
- Save and activate the query.
- Use BEx Analyzer or BEx Web Application Designer to execute the query, input parameters, and retrieve the data.
- Analyze and manipulate the data, and then save or export the results as needed.
Q32. What is a Web Intelligence report in SAP BI?
Ans:
Web Intelligence is a reporting tool in SAP BI that enables users to create interactive, web-based reports. It allows for ad-hoc query and reporting, data exploration, and sharing of reports via the web. Web Intelligence reports can be created and edited in a web-based environment, making it accessible to a wider range of users.
Q33. How is SAP Lumira used for data visualization in SAP BI?
Ans:
SAP Lumira is a data visualization and self-service BI tool that allows users to create interactive and visually appealing data visualizations, such as charts, graphs, and dashboards. It connects to SAP BI and other data sources, making it easier for business users to explore and visualize data, identify patterns, and gain insights.
Q34.Explain the purpose of SAP Crystal Reports in SAP BI.
Ans:
SAP Crystal Reports is a reporting tool used in SAP BI to design and generate formatted, pixel-perfect reports. It is ideal for producing printable reports, such as invoices, financial statements, and operational reports. Crystal Reports allows for precise control over report layouts and formatting, making it suitable for various business reporting needs.
Q35. What is a Dashboard in SAP BI, and how is it created?
Ans:
A dashboard in SAP BI is a visual representation of key performance indicators (KPIs), metrics, and data that provides a consolidated and real-time view of an organization’s performance. Dashboards are created using tools like BEx Web Application Designer or SAP Lumira. They typically consist of charts, graphs, tables, and other visual components, allowing users to monitor and interact with data at a glance. Dashboards are designed to support quick decision-making by presenting critical information in an easily digestible format.
Q36. How does SAP BI handle user authentication and authorization?
Ans:
SAP BI handles user authentication and authorization through its security mechanisms. User authentication verifies the identity of users, typically through user IDs and passwords. Once authenticated, authorization determines the level of access and privileges a user has within the SAP BI environment. Authorization is controlled through roles, profiles, and security settings. SAP BI integrates with various authentication methods, including LDAP, Active Directory, and SAP Logon Tickets, to ensure secure user access.
Q37. Explain the concept of Role-Based Security in SAP BI.
Ans:
Role-Based Security in SAP BI is a security model that assigns users to roles, and roles are associated with specific sets of authorizations. Users inherit the authorizations defined for their assigned roles. By using role-based security, administrators can efficiently manage user access and privileges by controlling access to objects, data, and functions within the SAP BI environment. Roles can be customized to align with different job functions or responsibilities, ensuring that users only have the access they need.
Q38. What are Analysis Authorizations in SAP BI, and why are they important?
Ans:
Analysis Authorizations in SAP BI are a crucial component of role-based security. They are used to control data access within the context of BEx queries and reports. Analysis Authorizations define which data a user or role can access by specifying filters, characteristics, and restrictions. They are essential for ensuring that users can only view and analyze data that is relevant to their roles and responsibilities. Analysis Authorizations help maintain data confidentiality, integrity, and compliance with data privacy regulations.
Q39. How do you restrict access to sensitive data in SAP BI?
Ans:
To restrict access to sensitive data in SAP BI, you can take several measures:
- Role-Based Security: Assign users to roles with restricted authorizations based on their job roles.
- Analysis Authorizations: Create analysis authorizations to limit access to specific data, ensuring that sensitive information is only available to authorized users.
- Data Access Profiles: Use data access profiles to further restrict data access for specific users or groups.
- Data Masking: Implement data masking techniques to obfuscate sensitive data for certain users, allowing them to see only masked or aggregated values.
- Data Archiving and Retention: Establish data archiving and retention policies to ensure that sensitive data is not stored longer than necessary.
- Audit Trails: Set up audit trails and logs to monitor user activities and detect unauthorized access to sensitive data.
- Data Encryption: Implement data encryption techniques to protect data during transmission and storage.
- Regular Security Audits: Conduct regular security audits and assessments to identify and address potential security gaps.
- Data Classification: Classify data based on sensitivity and apply different security measures to different data categories.
Q40. What techniques can be used to optimize query performance in SAP BI?
Ans:
Query performance optimization in SAP BI can be achieved through various techniques, including:
- Creating and maintaining aggregates.
- Using appropriate indexes.
- Limiting the amount of data retrieved in queries.
- Implementing partitioning strategies.
- Utilizing in-memory technology like SAP HANA.
- Monitoring system performance and resource utilization.
- Designing efficient data models.
- Optimizing ETL processes.
- Using query caching mechanisms.
- Ensuring that hardware resources meet system requirements.
Q41. How can you monitor system performance in SAP BI?
Ans:
System performance in SAP BI can be monitored using tools and techniques such as:
- SAP Solution Manager for performance monitoring.
- SAP BW/4HANA cockpit for monitoring BW/4HANA systems.
- Database monitoring tools for database-specific performance analysis.
- SAP EarlyWatch Alert service for system health checks.
- Performance traces and logs.
- SAP BW statistics and monitoring applications.
- Regular performance testing and benchmarking.
Q42. What are aggregates, and how do they improve query performance?
Ans:
Aggregates in SAP BI are summarized datasets derived from detailed data stored in InfoProviders like InfoCubes. Aggregates pre-calculate key figures at different levels of granularity. They improve query performance by reducing the time and resources required for calculations during query execution. Aggregates allow the system to return results more quickly, especially for frequently used queries, by using precomputed values.
Q43. What is Data Governance, and why is it important in SAP BI?
Ans:
Data Governance in SAP BI refers to the processes, policies, and practices that ensure the proper management, quality, and security of data within the BI environment. It is essential for maintaining data accuracy, consistency, and compliance. Data Governance helps organizations make informed decisions based on reliable data, reduces data-related risks, and ensures data remains reliable, accessible, and compliant with regulations.
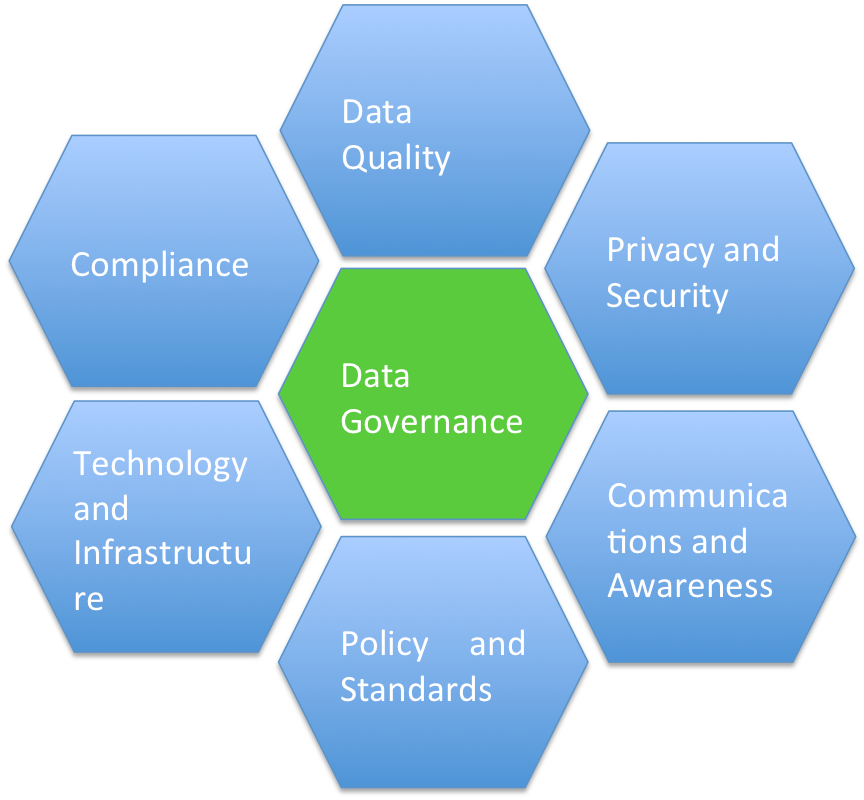
Q44. How can data quality be ensured in SAP BI?
Ans:
Data quality in SAP BI can be ensured through various measures, including:
- Implementing data validation and cleansing routines.
- Using data profiling tools to identify data issues.
- Defining data quality standards and rules.
- Conducting regular data audits and quality checks.
- Data stewardship and ownership.
- Data governance policies and practices.
- Continuous monitoring of data quality.
- Establishing data quality KPIs and metrics.
Q45. What is the purpose of data validation and cleansing in SAP BI?
Ans:
Data validation and cleansing in SAP BI are processes that ensure data accuracy and consistency. Validation checks data for errors and inconsistencies, while cleansing corrects and standardizes data to meet business requirements. The purpose of these processes is to improve data quality, which is critical for reliable reporting and analysis.
Q46. How does SAP BI handle data archiving and retention?
Ans:
SAP BI offers data archiving and retention mechanisms to manage the volume and lifecycle of data. Data archiving involves moving historical or infrequently accessed data to archive storage, reducing the load on the live system. SAP BI uses archiving objects, archive files, and archiving programs to perform archiving tasks. Data retention policies are defined to determine how long data should be retained in the system before it’s archived or deleted. Data archiving and retention are important for maintaining system performance and compliance with data retention regulations.
Q47. How does SAP BI integrate with SAP ECC (Enterprise Central Component)?
Ans:
SAP BI can integrate with SAP ECC by extracting data from SAP ECC systems using SAP-specific extractors and connectors. Data is typically extracted from SAP ECC’s tables and InfoCubes, transformed in SAP BI’s Data Warehouse, and made available for reporting and analysis. This integration allows organizations to consolidate, analyze, and report on their SAP ECC data within the SAP BI environment.
Q48. Explain the integration of SAP BI with SAP BW/4HANA:
Ans:
SAP BW/4HANA is the next-generation data warehouse solution from SAP, designed for advanced analytics and data processing. SAP BI can integrate with SAP BW/4HANA seamlessly. SAP BW/4HANA serves as the data storage and modeling component, while SAP BI tools are used for reporting, analysis, and visualization. This integration enables users to leverage the performance and scalability of SAP BW/4HANA for data warehousing, while utilizing SAP BI tools for business intelligence activities.
Q49. What is SAP BO (BusinessObjects), and how does it relate to SAP BI?
Ans:
SAP BO (BusinessObjects) is a separate suite of business intelligence and reporting tools offered by SAP. It complements SAP BI by providing additional reporting and data visualization capabilities. SAP BO includes tools like Web Intelligence, Crystal Reports, Lumira, and Dashboards. While SAP BI focuses on data extraction, transformation, and modeling, SAP BO emphasizes reporting, ad-hoc analysis, and data visualization. Integration between SAP BI and SAP BO allows users to create comprehensive business intelligence solutions.
Q50. How can SAP BI be integrated with SAP HANA?
Ans:
Integration between SAP BI and SAP HANA is achieved through SAP HANA’s capabilities as an in-memory database and data processing platform. SAP BI can connect to SAP HANA to leverage its speed and performance for data storage and processing. This integration allows SAP BI to work with real-time data, perform complex calculations, and access data stored in HANA views. Data from SAP BI can also be loaded into SAP HANA for high-speed reporting and analysis.

Enroll in SAP BI Certification Course to Build Your Skills & Advance Your Career
Weekday / Weekend BatchesSee Batch DetailsQ51. Describe the transport process in SAP BI.
Ans:
The transport process in SAP BI involves moving objects and data from a development environment to a production environment. This process is crucial for maintaining consistency and ensuring that changes made in development are safely deployed to production. It includes the selection, packaging, and transport of objects using the Transport Organizer in SAP BW/BI.
Q52. What is the role of the Transport Management System (TMS) in SAP BI?
Ans:
The Transport Management System (TMS) in SAP BI is responsible for managing and controlling the transport of objects and changes between different system landscapes (e.g., development, quality, production). TMS ensures that changes, such as InfoObjects, InfoCubes, queries, and transformations, are properly collected, exported, and imported in the correct sequence and without conflicts.
Q53. How do you deploy SAP BI objects from a development environment to a production environment?
Ans:
- Collect and package the objects using the Transport Organizer.
- Release the transport request for export.
- Import the transport request into the target system, which may require approval and scheduling.
- Validate the successful import of objects in the target system.
- Perform testing and quality assurance in the production environment.
- Monitor and document the deployment process.
- Activate the objects in the production system to make them available for use.
Q54. Explain the different methods for data extraction in SAP BI.
Ans:
Data extraction in SAP BI can be performed through various methods, including:
- Generic Extraction: Custom ABAP programs can be developed to extract data from source systems using logical queries.
- Standard DataSources: Predefined data extraction objects for commonly used source systems like SAP ERP.
- Business Content DataSources: Preconfigured data extraction objects provided by SAP for various source systems.
- Flat File Upload: Data can be extracted from flat files, such as Excel or CSV files.
- Real-Time Data Acquisition (RDA): Allows for real-time data extraction and integration.
- ODP (Operational Data Provisioning): A modern, unified framework for data extraction from source systems.
Q55. What is a DataSource in SAP BI, and how is it different from InfoProviders?
Ans:
A DataSource in SAP BI is a data extraction object that defines the structure and extraction logic for specific data from a source system. It provides metadata for data extraction and transformation. In contrast, InfoProviders in SAP BI are data storage objects used for data modeling and reporting. DataSources are used to extract data, while InfoProviders store and manage the extracted data.
Q56. How do you enhance DataSource in SAP BI?
Ans:
DataSources in SAP BI can be enhanced to meet specific data extraction requirements by using custom ABAP code. You can enhance DataSources by creating user exits or implementing Business Add-Ins (BAdIs) in the ABAP code. These enhancements can be used to manipulate data during extraction, filter records, or perform custom logic.
Q57. What is the role of ABAP routines in SAP BI?
Ans:
ABAP routines in SAP BI are used to perform custom data transformations and calculations during the data loading process. They allow you to manipulate data extracted from source systems and apply business-specific logic, such as calculations, conversions, and derivations. ABAP routines are commonly used in transformations, DTPs (Data Transfer Processes), and start routines.
Q58. How do you create transformations using ABAP routines?
Ans:
To create transformations with ABAP routines in SAP BI:
- Define the transformation in the Transformation Designer.
- In the transformation, you can use ABAP routines to define the logic for data mapping and transformations.
- Specify the source fields and target fields and use the ABAP code to transform the data as needed.
- Activate the transformation.
Q59. What is Start Routine, End Routine, and Expert Routine in SAP BI?
Ans:
What is Start Routine, End Routine, and Expert Routine in SAP BI?
- Start Routine: Executed before the actual transformation process. It’s used for any pre-processing required before data transformation.
- End Routine: Executed after the transformation process. It’s used for post-processing or calculations after data transformation.
- Expert Routine: Allows more complex and flexible transformations with direct access to both source and target data. Expert routines provide the highest level of customization.
Q60. Explain the concept of data archiving in SAP BI.
Ans:
Data archiving in SAP BI involves moving historical or infrequently accessed data from the live system to archive storage. Archived data is retained for compliance or reporting purposes but is not actively used in daily operations. Archiving reduces the system’s data volume, improving performance and resource utilization.
Q61. What is data aging in SAP BI, and how does it differ from data archiving?
Ans:
Data aging in SAP BI is a concept where data is marked as “aged” based on specific criteria, but it remains in the live system for reference and query purposes. It differs from data archiving in that the data is not physically moved to archive storage but is still accessible in the system, though flagged as aged.
Q62. Describe the various transport mechanisms available in SAP BI.
Ans:
Transport mechanisms in SAP BI include:
- Change and Transport System (CTS): Manages the transport of objects between system landscapes.
- Transport Organizer: Allows for the selection and packaging of objects for transport.
- Transport Directory: Stores transport requests and logs.
- Import/Export: Moves objects between systems.
- Transport Connection: Establishes a connection to remote systems for transporting objects.
- Consolidation: Merges multiple transports into a single transport.
Q63. What is the purpose of the Change and Transport System (CTS) in SAP BI?
Ans:
The Change and Transport System (CTS) in SAP BI is responsible for managing and controlling the transport of objects and changes between different system landscapes, such as development, quality, and production systems. CTS ensures that changes are moved in a structured and controlled manner, helping to maintain consistency and avoid conflicts between different system environments.Q64. What are Slowly Changing Dimensions (SCD) in data modeling?
Ans:
Slowly Changing Dimensions (SCD) refer to a concept in data modeling where data attributes change over time but at a relatively slow rate. SCDs are used to track historical changes in data, such as customer addresses or product prices. There are different SCD types, including Type 1 (overwrite), Type 2 (add new row), and Type 3 (add new attribute). SCDs help maintain historical data for reporting and analysis.
Q65. Explain the concept of Hierarchies in SAP BI
Ans:
Hierarchies in SAP BI represent structured relationships between characteristics or attributes. They are used to organize data in a way that allows for drilling down from summary levels to detailed levels. Hierarchies provide a structured view of data, making it easier for users to navigate and analyze information. Common examples include time hierarchies (year, quarter, month) or product hierarchies (category, subcategory, product).
Q66.How can you improve the performance of InfoCubes in SAP BI?
Ans:
To improve the performance of InfoCubes in SAP BI, you can consider these measures:
- Creating aggregates to pre-calculate and store summarized data.
- Defining and using appropriate indexes.
- Partitioning InfoCubes for better data management.
- Regularly monitoring and optimizing query performance.
- Ensuring that the design of InfoCubes aligns with business requirements.
- Using SAP HANA for in-memory processing, if available.
Q67. What is the purpose of Partitioning in SAP BI, and how does it improve performance?
Ans:
Partitioning in SAP BI involves dividing large InfoCubes or DSOs into smaller, more manageable units. Partitioning improves performance by reducing the amount of data that needs to be processed during data loads and query execution. It enhances data pruning, which means that only relevant data partitions are processed. This reduces query response times and optimizes data loads, especially for large datasets.
Q68. How do you manage data loads during peak hours in SAP BI?
Ans:
Managing data loads during peak hours in SAP BI can be done by:
- Scheduling data loads during off-peak hours to minimize system impact.
- Using parallel processing to distribute load tasks.
- Monitoring system performance and resource utilization during peak loads.
- Optimizing ETL processes and transformations.
- Implementing data compression techniques to reduce storage requirements.
- Utilizing load balancing and resource scaling for high availability.
Q69. What is the BEx Analyzer, and how is it used for reporting?
Ans:
The BEx Analyzer is a Microsoft Excel-based tool in SAP BI used for ad-hoc reporting and analysis. It allows users to create and run queries directly in Excel, enabling data retrieval, analysis, and the creation of formatted reports. BEx Analyzer provides a familiar interface for business users to access and work with BI data in a spreadsheet environment.
Q70. Explain the difference between BEx Query Designer and BEx Analyzer
Ans:
BEx Query Designer is used to design and create queries, specifying data sources, key figures, characteristics, and layout settings. It is primarily used by developers to design the query structure. BEx Analyzer, on the other hand, is used by end-users for ad-hoc reporting and analysis. It allows users to execute queries, apply filters, and create reports in Microsoft Excel. BEx Query Designer is for query design, while BEx Analyzer is for query execution and analysis.
Q71. How do you enhance data sources in SAP BI to accommodate additional fields?
Ans:
To enhance data sources in SAP BI to accommodate additional fields, you can:
- Modify the DataSource in the source system (e.g., SAP ECC) to include the additional fields.
- Update the DataSource’s extraction structure in SAP BI to reflect the changes in the source system.
- Adjust the transformations and Data Transfer Processes (DTPs) to accommodate the new fields.
- Extend the data modeling and reporting objects to include the new fields, such as InfoObjects or InfoProviders.
- Test and validate the changes to ensure that the additional fields are correctly integrated into the SAP BI environment.
Q72. Describe the process of transporting objects from one environment to another in SAP BI
Ans:
Transporting objects in SAP BI involves creating transport requests that bundle related objects and configurations. These transport requests are then moved from the development environment to testing and, ultimately, to the production environment. The process includes selecting objects, releasing the transport request, and importing it into target systems using the Change and Transport System (CTS).
Q73. What is Data Transfer Process (DTP)?
Ans:
A Data Transfer Process (DTP) in SAP BI is a mechanism used for transferring data from a source object (e.g., DataSource, InfoProvider) to a target object (e.g., InfoCube, DataStore Object) while allowing for data transformations and mappings.
Q74. What is the significance of Delta DTP in SAP BI?
Ans:
Delta DTP is essential for incremental data loading. It extracts only the changed or new data from the source system, reducing the volume of data transferred and improving load performance. It plays a critical role in ensuring that the Data Warehouse stays up-to-date with real-time or near-real-time data changes.
Q75. How do you monitor and troubleshoot DTP issues?
Ans:
DTP issues can be monitored and troubleshooted using various tools and techniques such as DTP monitors, data load monitors, error handling processes, and logs. SAP BI provides a range of options for analyzing DTP execution, identifying issues, and taking corrective actions.
Q76. What is BI Content, and how does it simplify data modeling in SAP BI?
Ans:
BI Content in SAP BI is a pre-defined set of data models, InfoCubes, data sources, and queries provided by SAP. It simplifies data modeling by offering ready-made solutions for various industries and business processes. BI Content accelerates the development process by providing a standardized framework that can be adapted to specific business needs.
Q77. What is Transporting DataSources?
Ans:
DataSources can be transported from one system to another in SAP BI by creating transport requests that bundle DataSources and related objects. These requests are then released and imported into the target system using the Change and Transport System (CTS).
Q78. Explain the types of hierarchies used in SAP BI?
Ans:
There are different types of hierarchies in SAP BI, including:
- Time Hierarchies: Representing time-related data, e.g., year, quarter, month.
- Customer Hierarchies: Organizing customer data based on categories or regions.
- Product Hierarchies: Categorizing products into groups and subgroups.
- Location Hierarchies: Structuring geographical data, e.g., country, region, city.
- Custom Hierarchies: Created to meet specific business requirements.
Q79. How do you create and maintain hierarchies in SAP BI?
Ans:
Hierarchies in SAP BI are created and maintained in the Hierarchy Maintenance Tool. You can define hierarchies by specifying the characteristics and their relationships. Once created, hierarchies can be maintained by adding, removing, or modifying hierarchy nodes and their properties.
Q80. Define OLAP and OLTP, and explain their differences.
Ans:
| Aspect | OLAP (Online Analytical Processing) | OLTP (Online Transaction Processing) | |
| Purpose | Used for complex analytical queries, business intelligence, and decision support. | Primarily designed for transactional operations and data modification. | |
| Function | Analyzes historical data, supports decision-making, and provides insights and trends. | Records day-to-day transactions, manages, and maintains databases. | |
| Database Design | Multidimensional database design to facilitate complex queries and aggregation. | Relational database design optimized for data modifications and fast query processing. | |
| Query Type |
Involves complex queries involving aggregation, grouping, and trend analysis. |
Typically involves simple queries for specific transactions or records. | |
| Data Consistency |
Emphasizes consistency of historical data for analytical purposes. |
Focuses on maintaining immediate data consistency for transactional processing. |
Q81. How does SAP BI support OLAP functionality?
Ans:
SAP BI supports OLAP functionality by providing tools and structures like InfoProviders (e.g., InfoCubes, MultiProviders), hierarchies, and BEx queries that enable multidimensional data modeling and ad-hoc analysis.
Q82. What are the techniques used for data validation in SAP BI?
Ans:
Data validation in SAP BI can be performed using techniques like:
- Data checks and comparisons against predefined rules.
- Data profiling to identify anomalies or inconsistencies.
- Data enrichment and cleansing to improve data quality.
- Automated error handling and data correction mechanisms.
- Data audits and quality assurance processes.
Q83. How does the Data Transfer Process (DTP) differ from the Update Rules in SAP BI?
Ans:
DTPs are used for data transformation and loading, while Update Rules are used to define how data is updated within InfoCubes and DataStore Objects. DTPs handle the extraction, transformation, and loading of data, while Update Rules govern how data is updated within target objects.
Q84. What are the different data load monitors in SAP BI, and how are they used?
Ans:
Data load monitors in SAP BI include the DTP Monitor, the InfoPackage Monitor, and the Process Chain Monitor. These tools are used to track the progress, status, and statistics of data loading processes, ensuring the successful execution of data loads.
Q85. Explain the concept of hierarchical data modeling in SAP BI.
Ans:
Hierarchical data modeling in SAP BI involves structuring data in a hierarchical manner, which is particularly useful for organizing data with a parent-child relationship. Hierarchical data models are created and maintained using hierarchies, which help users navigate and analyze data with a structured view.
Q86. Describe the various types of variables used in BEx queries in SAP BI.
Ans:
Variables in BEx queries allow users to input values or make selections for specific characteristics in reports. There are different types of variables, including:
- Characteristic Variables: Allow users to select values for a characteristic.
- Formula Variables: Use formulas to calculate variable values.
- Text Variables: Display additional descriptive information in reports.
- Replacement Path Variables: Provide dynamic value selections.
- Hierarchy Node Variables: Allow users to select hierarchy nodes.
- User-Defined Variables: Custom variables defined by users.
Q87. How do aggregates improve query performance in SAP BI?
Ans:
Aggregates in SAP BI store pre-calculated and summarized data. When users execute queries, the system can use these pre-aggregated results instead of calculating data on the fly. This significantly improves query performance by reducing processing time and resource usage.
Q88. What are some best practices for effective data modeling in SAP BI?
Ans:
Best practices for data modeling in SAP BI include:
- Understanding business requirements thoroughly.
- Designing efficient data models with the right level of granularity.
- Using appropriate hierarchies and structures.
- Regularly monitoring and optimizing data models.
- Leveraging BI Content for faster development.
- Documenting and maintaining data modeling standards.
Q89. Explain the differences between a Data Mart and a Data Warehouse in SAP BI.
Ans:
| Aspect | Data Mart | Data Warehouse |
| Scope | Subset of a Data Warehouse, focusing on a specific department or business function. | Central repository that integrates data from multiple sources across an entire organization. |
| Purpose | Designed to serve the needs of a particular business unit or specific user group. | Serves the needs of the entire organization or enterprise. |
| Data Size | Contains a smaller amount of data compared to a Data Warehouse. | Contains a vast amount of historical and current data. |
| Data Granularity |
May have higher granularity, catering to detailed and specific needs of a smaller user group. |
Often offers summarized, aggregated, and lower granularity data for broader analysis. |
| Update Frequency |
Generally updated more frequently, potentially in near-real-time for specific departmental needs. |
Typically updated less frequently due to the comprehensive nature of data collection. |
Q90. What advantages does SAP BI offer for informed decision-making in modern businesses?
Ans:
- Data Aggregation: SAP BI aggregates data from various sources, providing a unified view that aids in decision-making.
- Comprehensive Analysis: It offers robust analytical tools, allowing in-depth examination of data to derive insights and trends.
- Real-time Information: SAP BI provides real-time data access, enabling swift decision-making based on the most current information available.
- Visualizations and Reporting: It offers intuitive visualizations and customizable reports for easier interpretation and sharing of insights.
- Predictive Analytics: The platform includes predictive analytics tools, allowing businesses to anticipate trends and future scenarios.
- Improved Efficiency: By streamlining data access and analysis, SAP BI enhances operational efficiency and productivity.
- Strategic Planning: It supports strategic planning by providing valuable insights, helping organizations make informed decisions to drive growth and success.




