
Last updated on 12th Nov 2021| 4973
Splunk administrators are responsible for installing, configuring, and managing the platform, ensuring optimal performance and reliability. They handle user access, roles, and permissions and configure data inputs for effective data collection. Admins play a vital role in indexing data and parsing it accurately for efficient searching and reporting. Monitoring system health, optimizing configurations, and troubleshooting issues fall under their purview. Security implementation, backup strategies, and recovery planning are crucial to their responsibilities.
1. Explain the main components of Splunk architecture.
Ans:
Splunk architecture is comprised of five essential components. Forwarders, acting as agents, collect and send machine-generated data to the Indexers. The Indexers receive, index, and store this data, facilitating swift searches. Search Heads provide the user interface for search and visualization, interacting with Indexers to retrieve and display results. The Deployer manages configuration updates, ensuring consistency across Splunk instances. Lastly, the Cluster Master coordinates activities in a Splunk cluster, distributing data and managing failover to enhance system reliability and availability.
2. What is the role of a Splunk indexer?
Ans:
The Splunk indexer plays a crucial role in the Splunk architecture, serving as the component responsible for receiving, indexing, and storing the data sent by forwarders. Here are the key roles and responsibilities of a Splunk indexer:
- Data Reception
- Indexing
- Storage
- Searchable Indexes
- Fault Tolerance
3. How do you configure data inputs in Splunk?
Ans:
Configuring data inputs in Splunk involves specifying the sources from which Splunk should collect data. Splunk supports various data inputs, including files, directories, network streams, etc. The configuration process typically involves using Splunk’s web interface, configuration files, or third-party tools.
4. Explain the concept of source types in Splunk.
Ans:
- In Splunk, a source type is a metadata classification applied to the raw data as it is ingested into the system.
- It represents the structure or format of the data and helps Splunk understand how to process and index it.
- The source type defines how Splunk should parse the incoming data, extract fields, and apply default processing settings.
5. What is a Splunk bucket, and how is it related to indexing?
Ans:
Handling large volumes of data in Splunk requires careful planning, configuration, and optimization to ensure efficient indexing, storage, and search capabilities. Here are several strategies and best practices for managing large volumes of data in Splunk:
- Distributed Deployment
- Indexer Clustering
- Bucket Size and Time Slicing
- Summary Indexing
6. Explain the concept of Splunk roles and capabilities.
Ans:
In Splunk, roles and capabilities are key components of the access control system that governs user permissions within the platform. They manage what users can do and access within the Splunk environment.
7. What is SPL, and how is it used in Splunk?
Ans:
SPL (Search Processing Language) is a domain-specific language developed by Splunk for searching, analyzing, and manipulating data within the Splunk platform. It is the primary language used to interact with Splunk and perform searches, queries, and data analysis. SPL provides a powerful and flexible way to extract insights from machine-generated data.
8. How do you secure communication between Splunk components?
Ans:
- Enable SSL/TLS Encryption
- Use Signed Certificates
- Configure Splunk Web for HTTPS
- Secure Forwarder-to-Indexer Communication
9. How can you secure sensitive information in Splunk configuration files?
Ans:
Securing sensitive information in Splunk configuration files is crucial to protect credentials, API tokens, and confidential data from unauthorized access. Here are some best practices to enhance the security of sensitive information in Splunk configuration files.
- Use Credential Storage
- Encrypted Passwords
- Secure App Deployment
- Restrict Access to Configuration Files
10. What steps would you take to optimize search performance in Splunk?
Ans:
Index-Time Field Extraction: Extract fields at index time whenever possible.
Limit Search Time Range: Narrow the search time range to the minimum required for analysis.
Use Summary Indexing: Employ summary indexing to pre-aggregate data for commonly used searches.
Optimize Search Queries: Write efficient search queries. Use specific keywords, field-value pairs, and filters to narrow down results.
11. How do you troubleshoot issues with Splunk forwarders?
Ans:
Troubleshooting with Splunk forwarders involves diagnosing and resolving problems that may arise in collecting and forwarding data to the Splunk indexers. Here are general steps and strategies to troubleshoot Splunk forwarder issues:
- Check Splunk Logs
- Review Configuration Files
- Test Connectivity
- Verify Forwarder Status
12. What is the differences between Splunk’s ‘stats’ and ‘chart’ commands?
Ans:
| Aspect | ‘stats’ Command | ‘chart’ Command | |
| Summarization |
Numerical summaries in a table |
Graphical representations (charts) | |
| Grouping Data | Groups data for aggregation | Visualizes data trends | |
| Flexibility |
Flexible for numerical analysis |
Highly flexible for diverse charts. |
13. How do you handle large volumes of data in Splunk?
Ans:
Handling large volumes of data in Splunk requires careful planning, configuration, and optimization to ensure efficient indexing, storage, and search capabilities. Here are several strategies and best practices for managing large volumes of data in Splunk:
- Distributed Deployment
- Indexer Clustering
- Bucket Size and Time Slicing
14. Describe the role of a Splunk forwarder.
Ans:
Splunk forwarders collect data from various sources and forward it to the indexers. They play a crucial role in data collection and delivery in a Splunk environment. The primary role of a Splunk forwarder is to efficiently and securely forward data to the central Splunk deployment, where it can be indexed, searched, and analyzed.
15. How can you troubleshoot a Splunk deployment?
Ans:
- Troubleshooting in Splunk involves checking logs, using the Splunkd web interface, reviewing configuration files, and monitoring resource usage.
- Troubleshooting a Splunk deployment involves identifying and resolving issues that may impact the system’s functionality, performance, or reliability.
16. What are summary indexing and data model acceleration in Splunk?
Ans:
Summary indexing involves pre-aggregating data for faster searches, while data model acceleration optimizes searches by creating an accelerated data model. Summary indexing and data model acceleration are advanced features in Splunk that maximize the performance of searches and reporting by pre-calculating and storing aggregated results.
17. Explain the role of a Splunk license.
Ans:
The Splunk license governs how much data you can index and search within your Splunk deployment. Splunk uses this mechanism to manage usage and ensure compliance with licensing terms. Here are the critical aspects of the role of a Splunk license:
- Data Ingestion and Indexing
- Volume-Based Licensing
- License Types
- License Enforcement
18. Explain the components of a Splunk deployment.
Ans:
The splunk deployment includes forwarders, indexers, and search heads. Forwarders collect and send data, indexers store, and index data, and search heads provide the interface for searching and visualizing data. The specific components in a Splunk deployment can vary based on the deployment architecture and the organization’s requirements.
19. How do you backup and restore Splunk configurations and data?
Ans:
Backup involves copying the Splunk configuration files and directories. The restore process includes stopping Splunk, copying the backup files, and restarting Splunk.
Backing up and restoring Splunk configurations and data is a critical aspect of maintaining the integrity and recoverability of your Splunk deployment.
20. Explain the use of the props.conf and transforms.conf files.
Ans:
- Props.conf is used to configure data processing, parsing, and indexing settings.
- Transforms. conf is used for field extractions, data manipulation, and renaming.
21. What is Splunk Search Processing Language (SPL)?
Ans:
SPL is the search and query language used in Splunk for searching, analyzing, and reporting data. It allows users to filter and manipulate data during searches. SPL is specifically designed to interact with the data indexed by Splunk, enabling users to extract meaningful insights and gain visibility into their data.
22. How can you optimize Splunk searches for better performance?
Ans:
- Search optimization in Splunk involves using summary indexing, data model acceleration, and specifying index names in searches.
- Properly configured indexes and distributed searches also contribute to performance optimization.
23. Explain the purpose of the Splunk Deployment Monitor.
Ans:
The Splunk Deployment Monitor app provides insights into the health and performance of your Splunk deployment. It monitors the status of indexers, forwarders, and search heads.It plays a crucial role in maintaining the operational efficiency and reliability of a Splunk environment.
24. Describe the role of a Splunk License Master.
Ans:
A Splunk License Master manages and distributes licenses to all Splunk instances in a deployment. It helps ensure compliance with license limits.
- License Distribution
- Centralized License Management
- License Pooling
- Allocation to Indexers
25. What is a Splunk forwarder, and how is it used?
Ans:
A Splunk forwarder is a lightweight component in the Splunk architecture that is responsible for collecting, forwarding, and indexing log and machine data from various sources to a centralized Splunk deployment. Splunk forwarders play a key role in distributed Splunk environments, allowing organizations to efficiently collect and analyze data from a multitude of sources.
26. How do you manage user access and permissions in Splunk?
Ans:
User access and permissions are managed through role-based access control (RBAC) in Splunk. Admins assign roles to users, and roles define the capabilities and permissions users have within the Splunk environment.Roles define a set of capabilities or permissions, and users are assigned to roles to determine their level of access within the Splunk environment.
27. What is a Splunk search head, and what does it do?
Ans:
- A Splunk search head is a component in the Splunk architecture responsible for coordinating and executing search and reporting operations.
- It serves as the user interface for interacting with and querying the data stored in the Splunk deployment.
28. Explain the concept of Splunk Apps.
Ans:
Splunk Apps are pre-packaged solutions that extend the functionality of Splunk. They can include custom dashboards, reports, and configurations tailored to specific use cases, such as security, IT operations, or application monitoring. These apps are created by Splunk or third-party developers and can be installed on a Splunk instance to add specific features, data inputs, or visualizations tailored for particular use cases or domains.
29. What is the purpose of the Splunk deployment server?
Ans:
- The Splunk deployment server is used to manage configurations across multiple Splunk instances.
- It centralizes configuration files, making it easier to maintain consistency and apply changes to a large number of Splunk instances.
30. How do you monitor the health and performance of a Splunk deployment?
Ans:
Splunk provides various monitoring tools, including the Monitoring Console, to track the health and performance of the deployment. Metrics such as indexing rates, search performance, and resource utilization can be monitored. Splunk provides several tools and features to monitor the health and performance of the entire deployment, including individual components.
31. Explain the purpose of Splunk Bucketing.
Ans:
- Event Organization
- Time-Based Indexing
- Bucket Lifecycle
- Search Performance
- Bucket Types
32. How can you secure Splunk?
Ans:
Splunk security can be enhanced through various measures such as role-based access control (RBAC), SSL encryption, securing communication channels, and implementing proper authentication mechanisms. Regularly updating and monitoring security settings is crucial. Splunk provides a range of security features and best practices that administrators can implement to enhance the security of their Splunk deployment.
33. What is the purpose of Splunk REST API?
Ans:
- Splunk REST API allows users to interact with Splunk programmatically, enabling automation, integration with other tools, and custom application development.
- It provides endpoints for searching, managing configurations, and accessing various Splunk features.
34. Explain the concept of Splunk Knowledge Objects.
Ans:
Splunk Knowledge Objects include fields, tags, event types, and saved searches. They help define and customize how Splunk interprets and displays data. Knowledge Objects are essential for creating meaningful searches and reports. Splunk Knowledge Objects include fields, tags, event types, and saved searches.
35. What is Splunk, and what is its primary use?
Ans:
- Splunk is a real-time platform for searching, monitoring, and analyzing machine-generated data.
- It can process and index log and machine data from various sources, enabling users to gain valuable insights, troubleshoot issues, and monitor the health of their systems.
36. What does “licence violation in Splunk” mean?
Ans:
A license violation in Splunk occurs when the data volume ingested or the number of indexed sources exceeds the limits defined by the purchased license. This violation can result in restricted functionality or the temporary suspension of services until the licensing issue is addressed.
37. Why is the research of machine data done using Splunk administration?
Ans:
Splunk administration is crucial for researching machine data as administrators manage data inputs, configurations, and security. They ensure efficient data collection, index optimization, and user access, providing a well-maintained environment for extracting valuable insights from machine-generated data.
38. How can the existing LDAP settings be found or changed?
Ans:
- Existing LDAP settings in Splunk can be found or modified through the Splunk Web interface.
- Navigate to “Settings,” then “Access controls,” and select “Authentication method.”
- LDAP settings are visible and can be edited as needed to ensure proper authentication and user management.
39. What is Splunk free?
Ans:
Splunk offers a free version known as Splunk Free, which provides basic log search and analysis capabilities. While it has limitations on daily data volume and lacks some advanced features, it serves as an introductory version for users to explore and familiarize themselves with Splunk’s functionality.
40. In Splunk, how many different kinds of search modes are there?
Ans:
Fast Mode: Suitable for quick searches on smaller datasets, prioritizing speed over resource-intensive operations.
Smart Mode: Automatically switches between different search strategies based on the size of the dataset, balancing speed and efficiency for varying search complexities.
41. What is the Splunk Common Information Model (CIM)?
Ans:
The Splunk Common Information Model is a standard for organizing and describing field extractions and tags for data in Splunk. It provides a common framework for data normalization, making correlating data from different sources and apps more accessible.
42. Explain the function of the Splunk KV Store.
Ans:
- Splunk KV Store is a key-value store that allows users to store and retrieve arbitrary data within Splunk.
- It provides a scalable and persistent storage solution for custom application data, enabling efficient data retrieval and sharing across multiple instances.
43. How is data indexed in Splunk?
Ans:
Data is indexed in Splunk using events. An event is a single data record with a timestamp. Splunk extract fields from events during the indexing process.
44. How can you optimize Splunk searches for Better Performance?
Ans:
To optimize Splunk searches:
- Use more specific search terms.
- Limit the time range of the search.
- Optimize regular expressions.
- Use summary indexing for frequently used searches.
45. Explain Splunk indexers and their functions.
Ans:
Splunk indexers store and index the data received from forwarders. They enable efficient and fast search capabilities by creating indexes on the data, making it searchable and accessible. They play a crucial role in the data processing pipeline, enabling efficient searching and analysis of large volumes of data within the Splunk platform.
46. What is the purpose of the Splunk Knowledge Objects?
Ans:
Splunk Knowledge Objects include saved searches, reports, and dashboards. They help organize and visualize data, providing users with predefined views and insights into the data.
- Field Extractions
- Event Types
- Tags
- Lookups

Learn Splunk Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details47. How do you handle data forwarding and receiving between Splunk components?
Ans:
Splunk components communicate using various ports. Forwarders forward data to indexers on port 9997, and indexers receive data on this port. Search heads communicate with indexers on port 8089 to search and retrieve indexed data. This process involves configuring Splunk forwarders to send data to Splunk indexers and ensuring that the indexers can efficiently receive, index, and store the incoming data.
48. Explain setting up user authentication and authorization in Splunk.
Ans:
- Splunk supports various authentication methods, such as local authentication, LDAP, and SAML.
- Authorization is managed through roles, which define the permissions and capabilities of users.
- This process ensures secure and controlled access to Splunk data and functionality.
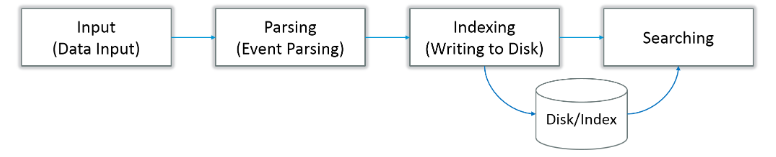
49. How does indexing work in Splunk?
Ans:
Indexing in Splunk involves converting raw data into searchable events and storing them in an index. The index allows for efficient and fast searches. The indexing process involves several key steps, from data input to creating searchable indexes.
50. Explain the concept of Splunk buckets.
Ans:
Splunk buckets are the basic units of storage for indexed data. They organize indexed data into time-based directories; each bucket contains a subset of indexed data. Splunk, a bucket, is a fundamental storage unit containing indexed data. Buckets are used to organize and manage data within the Splunk indexers. They play a crucial role in indexing and are designed to optimize search performance, enable data retention policies, and facilitate efficient data retrieval.
51. Explain the role of a deployment server in Splunk.
Ans:
The deployment server is responsible for distributing configurations to forwarders. The deployment server in Splunk plays a crucial role in managing configurations, distributing apps, and ensuring consistency across multiple Splunk instances in a distributed environment.
52. What is a Splunk Knowledge Object?
Ans:
Splunk Knowledge Objects are configurations and settings that extract, transform, and display data. Examples include fields, event types, tags, and saved searches. Knowledge Object refers to a specific entity created and managed within the Splunk platform to enhance data understanding, categorization, and utilization. Knowledge Objects are instrumental in organizing, enriching, and optimizing data processing within Splunk.
53. What is the purpose of Splunk Apps?
Ans:
- Splunk Apps are pre-packaged collections of dashboards, reports, and configurations tailored for specific use cases or technologies.
- They simplify the process of setting up and using Splunk for particular purposes.
- Splunk Apps are extensions or packages that provide additional functionality, visualizations, and solutions to enhance the core capabilities of the Splunk platform.
54. Explain the process of configuring inputs in Splunk.
Ans:
Configuring inputs involves defining data sources for Splunk to monitor. This can include log files, directories, network ports, etc. Configuration is done through inputs. Conf, where settings like source type, index, and source are specified. Inputs can include log files, network data, performance metrics, and more.
55. How do you optimize indexing performance in Splunk?
Ans:
- Performance can be optimized by adjusting factors such as the number of indexers, the size of the data, and the complexity of search queries.
- Properly tuning of settings like data retention policies and summarization can also help.
56. Describe the actions in the workflow.
Ans:
Actions within the Splunk workflow represent the orchestrated steps or tasks that users perform to derive insights and value from their data. These actions encompass a spectrum of activities, including running searches, creating visualizations, generating reports, and triggering alerts.
57. What is a Splunk dashboard, and how can you create one?
Ans:
- A Splunk dashboard is a visual representation of data that allows users to monitor and analyze information through charts, graphs, and tables.
- Dashboards can be created using the Splunk Web interface by combining search queries and visualizations.
58. How do you troubleshoot and optimize Splunk performance?
Ans:
Troubleshooting and optimizing Splunk performance involve monitoring system resource usage, tuning configurations, and addressing bottlenecks. Standard techniques include adjusting indexing settings, optimizing search queries, and ensuring proper resource allocation.
59. What is the role of a Splunk Universal Forwarder?
Ans:
- The Splunk Universal Forwarder is a lightweight version of Splunk that only forwards data to the Splunk Indexer.
- It doesn’t index data locally and is used to collect and send data from various sources to the central Splunk instance.
- The Splunk Universal Forwarder is designed for minimal resource consumption.
60. How do you troubleshoot performance issues in Splunk?
Ans:
Troubleshooting performance issues involves checking resource utilization, analyzing logs, and optimizing searches. Monitoring index health, disk space, and network latency are also essential. Splunk involves systematically identifying, analyzing, and addressing problems that may affect the efficiency and responsiveness of the Splunk platform.
61. Explain the purpose of the Splunk indexer cluster.
Ans:
The Splunk indexer cluster is a group of Splunk indexers that work together to provide high availability and fault tolerance for indexing and searching. It ensures data availability and prevents loss by replicating indexed data across multiple indexers. The primary purpose of the Splunk indexer cluster is to distribute and manage the indexing workload across multiple nodes, ensuring data availability, search performance, and reliability in large-scale Splunk deployments.

Get JOB Oriented Splunk Training for Beginners By MNC Experts
- Instructor-led Sessions
- Real-life Case Studies
- Assignments
62. How do you secure Splunk in a production environment?
Ans:
Splunk security involves:
- Configuring user roles and permissions.
- Enabling SSL for secure communication.
- Implementing authentication and authorization mechanisms.
- Monitoring and auditing user activities.
63. Explain the use of a summary index in Splunk.
Ans:
A summary index stores summarized or aggregated data to improve search performance. Users can create summary index searches to generate and store outlined data, which can be used for faster reporting and analysis. Using summary indexing can significantly improve the speed of complex or frequently executed searches in Splunk.
64. What is the purpose of indexes in Splunk?
Ans:
Indexes in Splunk are used to organize and store data. They provide a way to control access to data, set data retention policies, and manage the volume of data. Indexes serve as logical containers or repositories for the data ingested by Splunk, allowing users to search, analyze, and retrieve information.
65. How can you recover a deleted index in Splunk?
Ans:
- Restore the index from a backup or use the Splunk _internal index to recover deleted events.
- Recovering a deleted index in Splunk involves restoring the index from a backup.
66. What steps would you take to troubleshoot a Splunk performance issue?
Ans:
Check system resource utilization, review configuration settings, analyze search queries, and monitor indexing rates. Use Splunk’s monitoring tools to identify bottlenecks. Troubleshooting Splunk performance issues involves a systematic approach to identifying and resolving factors affecting the efficiency and responsiveness of the Splunk deployment.
67. How do you install a Splunk Universal Forwarder?
Ans:
Download the Universal Forwarder package, run the installer, and follow the installation wizard. Configure the forwarder to send data to the appropriate Splunk Indexer. Installing a Splunk Universal Forwarder involves several steps to set up and configure the forwarder on a machine that will send data to a central Splunk indexer.
68. What is Splunk Indexer clustering, and why is it used?
Ans:
- Splunk Indexer clustering involves configuring multiple Splunk Indexers to work together.
- It provides high availability, fault tolerance, and load balancing, ensuring continuous data availability and search performance.
- Indexer clustering is used to enhance the performance and reliability of a Splunk deployment, particularly in large-scale and mission-critical environments.
69. Explain the function of the Splunk license master.
Ans:
- License Distribution
- Centralized License Management
- License Quota Enforcement
- Monitoring License Usage
- License Pooling
70. What is a Splunk role and how does it differ from a Splunk user?
Ans:
Splunk, a role is a collection of permissions that determine what actions a user is allowed to perform. Users are assigned to roles, and roles are assigned specific capabilities. A “role” and a “user” are distinct concepts, each serving a specific purpose in the access control and security model of the Splunk platform.
71. Explain the use of the Splunk Deployment Monitor app.
Ans:
- The Splunk Deployment Monitor app is used to monitor and visualize the health and performance of a Splunk deployment.
- It provides insights into the status of forwarders, indexers, search heads, and other components, helping administrators identify and address potential issues.
72. How do you handle and troubleshoot common issues in Splunk?
Ans:
Troubleshooting in Splunk involves checking log files, understanding configuration settings, using the Splunk Web interface for monitoring, and utilizing Splunk commands like ‘splunkd’ and ‘splunk cmd’. Familiarity with Splunk documentation and community resources is also essential.
73. Describe the purpose of the Splunk license file.
Ans:
- The Splunk license file contains information about the amount of data that can be indexed in a given time period.
- It regulates the volume of data that can be processed by the Splunk instance and ensures compliance with the licensing terms.
74. How can you secure a Splunk deployment?
Ans:
- Implementing SSL encryption for data in transit.
- Restricting access to sensitive data and features.
- Monitoring and auditing user activities.
75. What steps would you take to troubleshoot a performance issue in Splunk?
Ans:
Check the health of Indexers, Forwarders, and Search Heads. Review system resource utilization, search query performance, and indexing rates. Analyze logs for errors and review configurations.Splunk involves a systematic approach to identify and resolve factors impacting the efficiency and responsiveness of the Splunk deployment.
76. How can you monitor the status of a Splunk Indexer?
Ans:
- Splunk Monitoring Console
- Splunk Web Interface
- Command Line Interface (CLI)
- REST API
- Log Files
77. Explain Splunk’s role in security information and event management.
Ans:
Splunk is often used as a SIEM tool to collect, index, and analyze log data for security purposes. It helps in detecting and responding to security incidents.Splunk plays a crucial role in Security Information and Event Management (SIEM) by providing a powerful platform for collecting, analyzing, and correlating diverse data sources to identify and respond to security threats.
78. How do you manage user access in Splunk?
Ans:
- Splunk Admins assign users to specific roles, and roles are granted access to specific indexes, searches, and other functionalities.
- Splunk involves configuring authentication, defining roles, and assigning capabilities to users to control their permissions within the Splunk environment.
79. How do you handle data input in Splunk?
Ans:
Splunk supports various input methods like file monitoring, network inputs, scripted inputs, and more. Inputs are configured in the inputs.conf file or through Splunk Web. Handling data inputs in Splunk involves configuring the software to ingest data from various sources, such as log files, databases, APIs, and more.
80. How does data flow in Splunk?
Ans:
Data flows from forwarders to indexers. Forwarders collect and send data, indexers store and index it, and search heads query the indexed data for analysis. The flow of data involves multiple stages, starting with the collection of raw data and ending with its indexing, search, and visualization.
81. How does data get indexed in Splunk?
Ans:
Event Parsing: The raw data is broken into events.
Event Breaking: Events are broken into smaller pieces called raw data.
Time Stamping: Splunk assigns a timestamp to each event.
Indexing: The events are stored in an index for easy retrieval.
82. In Splunk, how does the data age?
Ans:
Data aging in Splunk is a critical aspect of data lifecycle management. It involves the implementation of retention policies that dictate how long specific sets of data are retained within indexes before they undergo archival or are purged. These policies are instrumental in optimizing storage usage, ensuring that only relevant and recent data is readily available for analysis, while older and less pertinent data is appropriately managed.
83. What do Splunk pivots and data models mean?
Ans:
Splunk pivots allow users to interactively explore and analyze data. Data models, on the other hand, define the structure and relationships within your data, providing a framework for faster and more organized searches and analyses.
84. How many different kinds of dashboards does Splunk offer?
Ans:
Splunk offers three main types of dashboards:
Simple XML dashboards, Advanced XML dashboards, and the newer, more customizable Splunk Dashboard Studio introduced in recent versions.
85. Explain what “search factor” and “replication factor” mean.
Ans:
The search factor specifies the number of searchable copies of data, influencing the speed and efficiency of searches. Simultaneously, the replication factor dictates the number of redundant copies maintained for fault tolerance and data resilience.
86. What does Splunk’s Time Zone attribute mean?
Ans:
The Time Zone attribute in Splunk allows you to set the time zone for your data. It ensures consistent and accurate time-based analysis across data from different sources or systems.
87. Which kind of notifications are accessible in Splunk?
Ans:
- Splunk provides various notification mechanisms, including email alerts, scripted alerts, and webhooks.
- These notifications can be configured based on search results or specific events, keeping users informed of important changes.
88. How can I start and stop the Splunk service?
Ans:
The initiation and cessation of the Splunk service are fundamental administrative tasks crucial for maintaining control and efficiency within the Splunk environment. Administrators can employ command-line tools to initiate the Splunk service, as exemplified by the ‘./splunk start’ command on Unix-based systems. Conversely, the ‘./splunk stop’ command gracefully terminates the service, allowing for controlled and systematic management of Splunk processes.
89. Which Splunk search commands are essential?
Ans:
- search
- index
- eval
- stats
- chart
- timechart
90. Explain the disaster recovery options in Splunk.
Ans:
Disaster recovery in Splunk involves planning and implementing strategies to ensure the availability and integrity of your Splunk deployment in the event of a catastrophic failure or data loss. Splunk provides several disaster recovery options to help organizations recover quickly and minimize downtime.




