
Last updated on 11th Dec 2021| 1565
Scikit-learn is the most popular Python machine learning library for creating machine learning algorithms. It was created on top of two Python libraries – NumPy and SciPy. Scikit-learn is a Python library that provides a standard interface for supervised and unsupervised learning techniques.
- Introduction to Python Libraries
- Python libraries used in Machine Learning
- Feature Selection For Machine Learning in Python
- Three Types of Machine Learning
- Why Python is Most Suitable for Machine Learning?
- Machine Learning Technology Trends
- Advantages of Using Python Libraries for Machine Learning
- Conclusion
Introduction to Python Libraries:
Machine learning, because the name suggests, could be a creation by mental acts of science that they will learn from differing kinds of knowledge. A lot of common clarification given by Arthur Samuel is: “Machine learning could be a field of learning that provides computers the flexibility to scan while not having to be clearly organized.” They usually want to solve various sorts of health issues.
In the past, folks wanted to do Machine Learning activities by writing codes for all the algorithms and mathematical formulas. This makes the method long, tedious and inefficient. however these days, it’s a lot easier and a lot more economical than within the previous days with varied python libraries, frameworks, and modules. Today, Python is one in all the foremost standard programming languages in the trade and has replaced multilingualism within the trade, one in all the explanations being its massive assortment of libraries.
Python libraries used in Machine Learning:
Numpy
NumPy could be a very hip python library for big multi-dimensional systems and matrix processes, with the assistance of an outsized assortment of high-level mathematical operations. It’s terribly helpful in basic math calculations for Machine Learning. It’s particularly helpful for line pure mathematics, Fourier rework, and power of random numbers. Advanced libraries like TensorFlow use NumPy internally to trick Tensors.
sciPy
SciPy could be a very hip library among machine learning enthusiasts because it contains varied development modules, line pure mathematics, integration and math. there’s a distinction between the SciPy library and therefore the SciPy stack. SciPy is one in every of the fundamental packages that structure the SciPy stack. SciPy is additionally terribly helpful for changing pictures.
Scikit-read
Scikit-learn is one in every of the foremost common metric capacity unit libraries of the classic metric capacity unit algorithms. it’s engineered on 2 basic Python libraries, namely, NumPy and SciPy. Scikit-learn supports most of the supervised and unattended learning algorithms. Scikit-learn also can be used for data processing and knowledge analysis, creating a good tool for those beginning with metric capacity units.
Theano
We all grasp that Machine Learning is largely math and math. Theano could be a common python library that wants to interpret, check and refine mathematical expressions that embody equivalent members with multiple sides in a good approach. Achieved by rising mainframe and GPU usage. It’s widely used for unit review and validation to discover and measure differing kinds of errors. Theano could be a terribly powerful library that has been used for major science courses for an extended time, however it is easy and accessible enough to be employed by people to hold out their visits.
TensorFlow
TensorFlow could be a common open supply library for prime performance digital enhancements developed by the Google Brain team at Google. Because the name suggests, Tensorflow could be a framework that involves deciphering and applying calculations that embody tensors. It will train and use deep neural networks which will be wont to develop a number of AI applications. TensorFlow is widely utilized in the sector of in-depth reading and application analysis.
Keras
Keras could be a common Python machine reading library. It’s a high-level neural network API which will run on TensorFlow, CNTK, or Theano. It will work seamlessly on each mainframe and GPU. Keras makes it a reality for metric capacity unit beginners to make and style a Neural Network. One of the good things regarding Cameras is that it permits straightforward and quick prototyping.
PyTorch
PyTorch is an Associate in Nursing open supply Python-based Python-based learning resource, that is Associate in Nursing open supply C-machine library in Lua. It’s a large choice of tools and libraries that support pc Vision, language process (NLP) and plenty of different metric capacity unit programs. It permits developers to perform calculations on Tensors with GPU acceleration and additionally helps produce calculation graphs.
Panda
Pandas could be a common Python library for knowledge analysis. It’s indirectly associated with Machine Learning. As we all know the info should be ready before coaching. During this regard, Pandas are useful because they are specially designed for knowledge extraction and process. Provides high-quality knowledge structures and a spread of information analysis tools. Provides several integral strategies for filtering, assembling and filtering knowledge.
Matplotlib
Matplotlib is Python’s most well-liked visual library. Just like the Panda, it’s nothing to do with machine learning. It’s terribly helpful if the editor desires to see patterns within the knowledge. It’s a second editing library that wants to produce second graphs and episodes. The module known as pyplot makes it simple for programmers to edit because it provides management parts for line designs, font options, format axes, etc. Provides different kinds of graphs and knowledge displays, namely, histogram, error charts, bar charts. , etc.,

- # Feature choice and strange Mathematical Tests
- from pandas import read_csv
- from numpy import set_printoptions
- from sklearn.feature_selection import SelectKBest
- from sklearn.feature_selection enter f_classif
- # transfer knowledge
- filename = ‘pima-indians-diabetes.data.csv’
- names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
- dataframe = read_csv (file name, names = names)
- list = dataframe.values
- X = list [:, 0: 8]
- Y = list [:, 8]
- # unharness feature
- test = SelectKBest (score_func = f_classif, k = 4)
- fit = test.fit (X, Y)
- # summarize the scores
- set_printoptions (accuracy = 3)
- print (fit.scores_)
- features = work.transform (X)
- # summarize elite options
- print (features [0: five ,:])
- [39.67 213.162 3.257 4.304 13.281 71.772 23.871 46.141]
- [6. 148. 33.6 50.]
- [1. 85. 26.6 31.]
- [8. 183. 23.3 32.]
- [1. 89. 28.1 21.]
- [0. 137. 43.1 33.]]
- The algorithmic Feature Elimination (or RFE) works by repeatedly removing the attributes and modeling those remaining attributes.
- It uses model accuracy to spot which attributes (and combination of attributes) contribute most to predicting target attributes.
- You can learn additional information regarding the RFE category in scikit-learn texts.
- The example below uses RFE with a slowing algorithmic program to pick out the highest three options. The selection of an algorithmic program suggests that nothing is as long because it is competent and consistent.
- # Retrieval feature
- from pandas import read_csv
- from sklearn.feature_selection for RFE import
- from sklearn.linear_model enter LogisticRegression
- # transfer knowledge
- url = “https://raw.githubusercontent.com/jbrownlee/Datasets/master/pima-indians-diabetes.csv”
- names = [‘preg’, ‘plas’, ‘pres’, ‘skin’, ‘test’, ‘mass’, ‘pedi’, ‘age’, ‘class’]
- dataframe = read_csv (url, names = names)
- list = dataframe.values
- X = list [:, 0: 8]
- Y = list [:, 8]
- # unharness feature
- model = LogisticRegression (solver = ‘lbfgs’)
- rfe = RFE (model, 3)
- fit = rfe.fit (X, Y)
- Print (“Value Features:% d”% work.n_features_)
- Print (“Selected Features:% s”% work.support_)
- Print (“Level Feature:% s”% work.ranking_)
- You can see that RFE has the highest three options like preg, mass and pad.
- Note: Your results might take issue reckoning on the quality algorithmic program or check method, or the distinction in numerical accuracy. think about using the instance many times and compare the typical result.
- These are marked as true within the support list and are marked by choosing “1” within the level_.
- Feature Number: three
- Selected Features: [True False False False True True False]
- Feature level: [1 two three five six one one 4]
Feature Selection For Machine Learning in Python:
Feature choice is the method by which you mechanically choose those options in your knowledge that contribute most to the dynamic predictions or output that you just have an interest in. Having unimportant options in your knowledge will cut back the accuracy of the many models, particularly line algorithms like lineback and movement.
The 3 edges of constructing feature choice before modeling your knowledge are:
Reduce Overload: deficient knowledge suggests that there is less chance to form sound selections.
Improves Accuracy: a touch of dishonest knowledge suggests that model accuracy is improved.
Reduce coaching Time: Less knowledge suggests that algorithms train quicker.
Data set file.
1. versatile selections
Statistical tests may be wont to choose those factors that have the strongest correlations with output variables. The scikit library provides a SelectKBest category which will be used with a group of various mathematical tests to pick out a selected variety of options. Many different mathematical tests may be used with this selection. As an example, the ANOVA F price methodology is appropriate for numerical input and class knowledge, as we have a tendency to see within the Pima information. This may be used with the f_classif () operation. We’ll choose the highest four options to victimize this methodology within the example below.
To facilitate the number of scientific disciplines you’ll be able to use in your knowledge, see the tutorial:
How to opt for a Machine Learning Feature
Note: Your results might take issue reckoning on the quality algorithmic program or check method, or the distinction in numerical accuracy. think about using the instance many times and compare the typical result. You can see points for every attribute and four elite attributes (those with the best scores). Specifically embrace indicators zero (preq), 1 (plas), 5 (mass), and seven (years).

Learn Advanced Machine Learning with Python Certification Training Course to Build Your Skills
Weekday / Weekend BatchesSee Batch Details2. Elimination of the Repetitive Feature
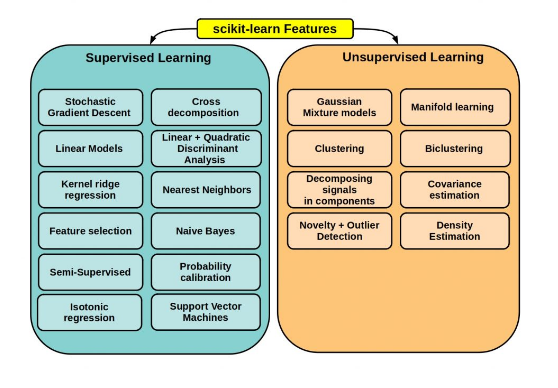
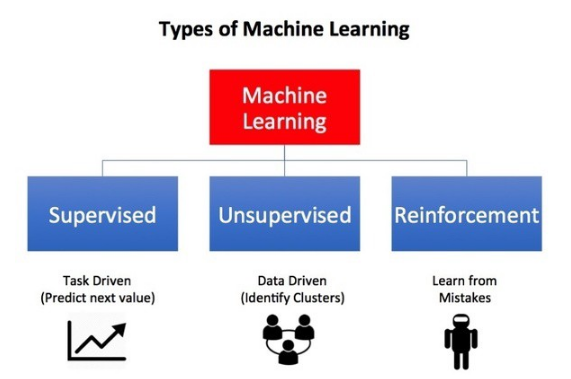
Three Types of Machine Learning:
Machine learning issues will sometimes be divided into 3 varieties. programming and training, conjointly referred to as supervised learning, and supervised learning that within the context of machine learning applications typically visit integration. In the next article, I’ll provide a transient introduction to every of those 3 problems and can embody a walkthrough within the widespread python scikit-learn library.
Supervised Reading: In supervised reading, you’ve got a familiar set of inputs (features) and a familiar set of output (labels). Historically these area units were referred to as X and y. The goal of the rule is to be told the map performs that design of the input input. in order that once given the new X models the machine will accurately predict the corresponding y labels.
Unsupervised Reading: For uncurbed reading, you simply have an associated input set (X) and no matching labels (y). The goal of the rule is to find antecedently unknown patterns in information. Sometimes these algorithms are accustomed to realize logical collections of identical X samples in order that they are literally finding the classes inside the information.
Familiar output (y) area unit wine varieties within the information given the quantity zero, 1 or 2. The way to install a machine library on Python.
Step 1: transfer Eunectes murinus. During this step, we’ll transfer the Eunectes murinus Python package for your platform.
Step 2: Install Eunectes murinus.
Step 3: Update Eunectes murinus.
Step 4: Install CUDA Toolkit & cuDNN.
Step 5: Add cuDNN to the Environmental Path.
Step 6: produce associate Eunectes murinus Place.
Step 7: Install In-depth Reading Libraries.
Why Python is Most Suitable for Machine Learning?:
Machine learning and AI, as a unit, are still evolving however chop-chop is growing in use thanks to the necessity for automation. Computing makes it doable to make new solutions to common issues, like fraud detection, personal assistants, spam filters, search engines, and recommendation programs. The need for sensible solutions to real-world issues needs the necessity to upgrade AI so as to mechanically perform tedious tasks to edit while not AI. Python programming language is taken into account to be the most effective algorithmic program to assist perform such tasks mechanically, and provides greater ease and consistency than different programming languages. In addition, the presence of a democratic python community makes it simple for developers to debate and provide ideas on a way to improve their code.
- Start with user behavior knowledge
- Drag and drop coaching knowledge
- Use the question in easy English
- Rate the results
- Generate a prediction report
Machine Learning Technology Trends:
Uncoded Machine Reading
Although most machine learning is managed and came upon victimization code, this can be not the case. Non-coded learning may be a thanks to organize milliliter applications while not researching long and tough processes of pre-processing, modeling, coming up with algorithms, assembling new knowledge, retraining, deployment, and more. a number of the most edges are:
Quick launch: with no code required to be written or the requirement to get rid of a mistake, most of the time wasted would be to induce results rather than enhancements.
Low cost: As automation eliminates the requirement for semipermanent development, giant knowledge science groups are not any longer required.
Simplicity: No-code milliliter is straightforward} to use thanks to its simple drag and drop format.
Non-coded machine learning uses drag and drop input to change the method as follows:
Advantages of Using Python Libraries for Machine Learning:
1. Independence altogether forums
Because of its ability to use multiple platforms while not needing to change, developers like Python, in contrast to alternative programming languages. Python works on totally different platforms, like Windows, Linux, and macOS, therefore requiring minor or non-existent changes. The platforms are absolutely compatible with the Python artificial language, which suggests that there’s no need for a Python professional to outline a program code.
Easy to use makes it straightforward to distribute packages, permitting freelance packages to be designed and operated by victimization Python. packages are often amended from begin to end victimization in Python because of the solely language. It’s a mix of developers as some coming up with languages need support in alternative languages before the project is often absolutely completed. Python’s independence across all platforms saves time and resources for developers. The World Health Organization might install multiple resources to complete one project.
2. Compatibility and ease
Python is the web site of many package developers trying to find simplicity and consistency in their work. Python code is brief and straightforward to browse, that makes the launch method a lot easier. An Associate in Nursing engineer will simply decipher a code and compare it with alternative programming languages. permits developers to access input from alternative developers within the community to assist improve packages or applications.
The simplicity of the Python language makes it straightforward for beginners to grasp it quickly and with very little effort compared to alternative programming languages. Also, fully fledged engineers notice it easier to make stable and reliable systems, and that they will focus their efforts on raising their ingenuity and resolution real-world issues victimizing machine learning.
3. varied structures and libraries
Libraries and structures are essential in getting ready a perfect setting for coming up with. Python frameworks and libraries offer a reliable environment that greatly reduces package development time. The library essentially includes pre-written code that engineers will use to hurry up secret writing once performing on complicated tests.
Python compiles a machine learning library called PyBrain that provides easy-to-use algorithms for machine learning tasks. The most effective and most reliable secret writing solutions need an explicit structure and tested surroundings, obtainable from Python frames and libraries.
Conclusion
Now, you know that Machine Learning is a form of mechanical training for the tasks the human brain can perform, albeit slower and better than the average person. Today we have seen that machines can beat human champions in games like Chess, AlphaGO, which are considered very complex. You have seen that machines can be trained to perform human tasks in a number of places and can help people to live better lives.
Machine Learning Unattended or Unattended. If you have a small amount of data and data with a clear label label, select Supervised Reading. Unattended reading can often provide better performance and results for larger data sets. If you have a large set of easily accessible data, go for in-depth reading strategies. Re-learn Reinforced Reading and in-depth reinforcement reading. Now you know what Neural Networks are, their operating systems and limitations.
Lastly, when it comes to developing your own learning machine models, you look at the various development language options, IDEs and Platforms. The next thing you need to do is start learning and mastering each machine learning. The story is great, it means there is scope, but if you consider the depth, each article can be read in a few hours. Each topic is independent. You need to think about one topic at a time, read it, train it, and use the algorithm / algorithms in it using the language of your choice. This is the best way to start a learning machine. Familiarizing yourself with one topic at a time, you will soon find the required range in terms of mechanical literacy.




