
Last updated on 10th Oct 2025| 12170
- What is Erwin Data Modeler?
- Key Features and Benefits
- Logical vs Physical Data Models
- Import/Export Features
- Normalization in Erwin
- Model Validation and Reporting
- Collaboration and Version Control
- Forward and Reverse Engineering in Erwin
- Best Practices for Data Modeling in Erwin
- Conclusion
What is Erwin Data Modeler?
Erwin Data Modeler is a powerful and industry-standard data modeling tool developed by Quest Software. It helps database professionals design, visualize, document, and deploy high-quality data architectures. This tool provides a comprehensive solution for developing conceptual, logical, and physical data models, making it highly valuable in Data Science course and database design projects. It facilitates understanding and communication between business and technical stakeholders, ensuring alignment of database systems with organizational needs. Erwin is widely used in industries such as finance, healthcare, education, and government for managing complex data environments, improving data quality, and supporting governance initiatives.
Key Features and Benefits
- Key Features
- Graphical Modeling Environment: Easy-to-use drag-and-drop interface that simplifies model creation.
- Multi-Model Support: Enables creation of logical, physical, and conceptual models within a single environment.
- DBMS Compatibility: Supports various platforms like Oracle, SQL Server, MySQL, PostgreSQL, DB2, and Teradata.
- Metadata Management: Captures and maintains metadata across the enterprise.
- Data Lineage and Impact Analysis: Helps trace data origin and downstream impact.
- Model Integration: Supports integration with BI, ETL, and data governance tools.
- Forward and Reverse Engineering: Generate or extract database structures, which can support use cases like data preparation for topics such as Ridge Regression Explained in analytics workflows.
- Reporting and Visualization Tools: Includes robust templates for diagrams and data dictionaries.
- Version Control and Change Management: Tracks changes and allows for model version comparison.
- Security and Access Controls: Role-based permissions ensure safe collaboration. Benefits
- Accelerates Development: Automates design and deployment workflows, reducing manual coding efforts.
- Promotes Team Collaboration: Centralized models facilitate shared understanding and communication.
- Ensures Regulatory Compliance: Helps maintain audit trails, track lineage, and support data governance frameworks.
- Enhances Business Intelligence: Structured data models contribute to more accurate analytics and reporting.
- Supports Agile Methodologies: Flexible design process supports iterative development cycles.
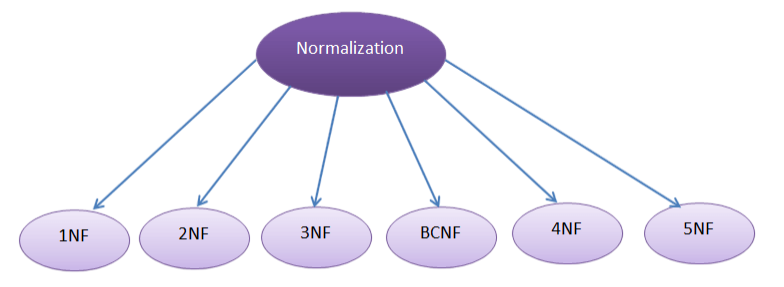
- 1NF: Eliminate repeating groups and arrays.
- 2NF: Remove partial dependencies (non-key attributes depending on part of the composite key).
- 3NF: Remove transitive dependencies (non-key attributes depending on other non-key attributes).
- BCNF: Further refinements to 3NF. How Erwin Helps:
- Bayes Theorem in Machine Learningcan be leveraged to automatically identify normalization issues by modeling the probability of data inconsistencies given observed patterns, enabling more accurate detection and correction during preprocessing.
- Provides normalization wizards to refactor models.
- Allows decomposing tables into multiple related entities.
- Ensures normalized designs with referential integrity.
- Erwin Model Mart: Central repository supporting teamwork.
- Model Locking: Prevents simultaneous editing of the same object.
- Commenting and Notes: Add annotations to model elements.
- Audit Trails: Logs changes and contributor information, which is essential for maintaining transparency and accountability in Data Science training projects.
- Built-in compare/merge functionality.
- Store multiple versions of a model.
- Rollback changes or merge updates from multiple users.
- Integration with source control systems like Git (via plugins).
- This feature minimises implementation problems by ensuring that the logical model and the actual database structure match.
- Conversely, you can extract data models from pre-existing databases by reverse engineering.
- This is very helpful for moving databases, analysing current structures, and documenting legacy systems.
- Both features preserve consistency between models and real database implementations while saving time.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Logical vs Physical Data Models
An extensive introduction to Erwin Data Modeller, a potent tool for designing and managing database structures, is given in this data modeling tutorial. This data modeling tutorial helps you grasp key ideas and recommended practices, regardless of your level of experience. This data modeling tutorial guarantees that you can create accurate, scalable, and efficient database designs with step-by-step explanations.
Logical Data Model:The goal of a logical data model is to capture the meaning of data and business requirements, which is foundational for understanding advanced concepts in AI and machine learning, such as What is Q-Learning? It is devoid of any database management system (DBMS) specifics and describes entities, their properties, and their relationships. Understanding business rules and making sure the data appropriately reflects the actual situation are at the heart of this model.
Physical Data Model:A Physical Data Model, on the other hand, focuses on the actual implementation of the database. It has comprehensive specifications for things like partitions, indexes, data types, constraints, table structures, and performance concerns. For automation and efficiency, this model may incorporate triggers and stored procedures in addition to accounting for storage and DBMS limits.Erwin provides transformation tools to convert logical models into physical models, reducing duplication and ensuring consistency.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Import/Export Features
- Import Options:
A data modelling tool’s import/export features make data integration and interchange simple. For interoperability with UML tools, import options include XMI (XML Metadata Interchange) and Excel or CSV files to import entity and attribute definitions. Models from other modelling programmes, such as IBM InfoSphere and SAP PowerDesigner, or the ERwin Mart Repository, can also be imported for use in Big Data Examples and analytics scenarios.
Export Options:However, export options enable the creation of Excel/CSV reports for data definition sharing and SQL scripts for database setup. Diagrams can be exported as PNG, JPG, or BMP pictures for use in visual presentations, or they can be integrated with business architecture tools using XML/XMI formats. HTML reports also offer browser-viewable interactive documentation, which facilitates sharing with stakeholders and teams.
Normalization in Erwin
Normalization improves database design by minimizing redundancy and dependency.

Model Validation and Reporting
Model Validation:Model Validation helps identify common issues in your data model, such as missing primary keys, unused entities, orphaned attributes, and circular relationships. You can access a summary report using the Tools > Model Validation option in TensorFlow Projects, which often includes auto-suggestions to help you quickly fix detected problems.
Reporting Features:Reporting Features provide built-in templates like Data Dictionaries, Entity/Attribute Listings, and Relationship Matrices to help document your model. You can export reports in various formats, including PDF, HTML, RTF, and Excel. These reports can be customized with headers, footers, and metadata, making them useful for documentation, compliance audits, and sharing with stakeholders.
Collaboration and Version Control
- Collaboration Tools:
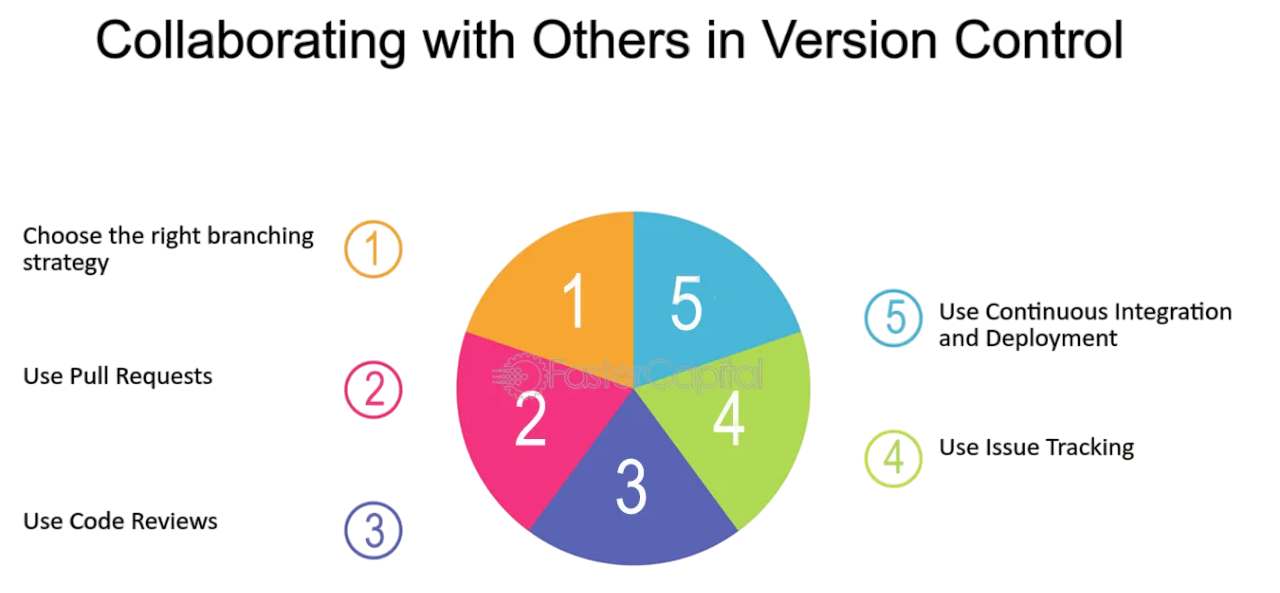
- Version Control:
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Forward and Reverse Engineering in Erwin
To expedite database creation, Erwin Data Modeller facilitates both forward and reverse engineering. By allowing you to create SQL scripts straight from your data models, forward engineering makes it possible to quickly and precisely create databases according to your plan.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Best Practices for Data Modeling in Erwin
It’s critical to adhere to industry best practices in order to maximise Erwin Data Modeler’s functionality. Just as debates like Elon Musk Vs Mark Zuckerberg highlight contrasting approaches to technology, it’s important to explicitly define the business needs prior to modelling to ensure alignment and clarity. To keep things clear, name entities, characteristics, and relationships according to standard conventions. When necessary, normalise your data; however, avoid over-normalizing to the point that performance is negatively impacted. To guarantee quality and accuracy, make use of Erwin’s built-in capabilities, such as version control and model validation. Finally, use Erwin’s reporting features to document everything. This will help with understanding and support governance and compliance initiatives.
Conclusion
Erwin Data Modeler is a feature-rich tool that enables efficient and accurate design of enterprise-level databases. Its powerful capabilities support a wide range of modeling activities from simple logical diagrams to complex physical schema implementations. With tools for automation, governance, collaboration, and documentation, Erwin empowers data professionals to deliver high-quality, future-proof database architectures that align with organizational objectives and support Data Science training initiatives. Mastery of Erwin ensures better data governance, regulatory compliance, and improved business insights through clean and structured data systems.Whether you are starting from scratch or documenting legacy databases, Erwin Data Modeler is a reliable companion in your data modeling journey.




