
Last updated on 14th Oct 2025| 10532
- The Origins and Evolution of Hadoop
- Core Features That Make Hadoop Stand Out
- The Hadoop Ecosystem: More Than Just Storage
- Scalability and Cost-Effectiveness: Hadoop’s Economic Advantage
- Hadoop in Real-Time and Batch Processing
- Integration with Modern Technologies and Cloud Platforms
- Use Cases Driving Hadoop’s Continued Relevance
- The Future of Hadoop in a Cloud-First World
The Origins and Evolution of Hadoop
Hadoop was born out of a need to process massive amounts of data at a time when traditional databases were hitting scalability limits. Inspired by Google’s MapReduce and Google File System (GFS), Doug Cutting and Mike Cafarella developed Hadoop under the Apache Foundation. Since its inception, Hadoop has evolved from a niche project into a cornerstone of big data infrastructure. It has undergone multiple updates, improving on speed, Data Science Training usability, fault tolerance, Integration with Modern Technologies, Evolution of Hadoop and ecosystem support. The Hadoop framework quickly gained popularity due to its ability to run on commodity hardware, allowing organizations to scale horizontally without breaking the bank. Over time, commercial distributions like Cloudera, Hortonworks, and MapR helped bring Hadoop into the enterprise mainstream, with additional tools and support layered on top of the core framework.
Core Features That Make Hadoop Stand Out
Hadoop’s continued dominance in big data circles is largely due to its unique architecture and powerful features. At its core, Hadoop consists of two main components: Hadoop Distributed File System (HDFS) and MapReduce. HDFS is designed to handle large files across multiple machines, What is Azure Data Lake ensuring fault tolerance and high availability. MapReduce allows parallel processing of data, breaking down complex tasks into simpler computations distributed across nodes.
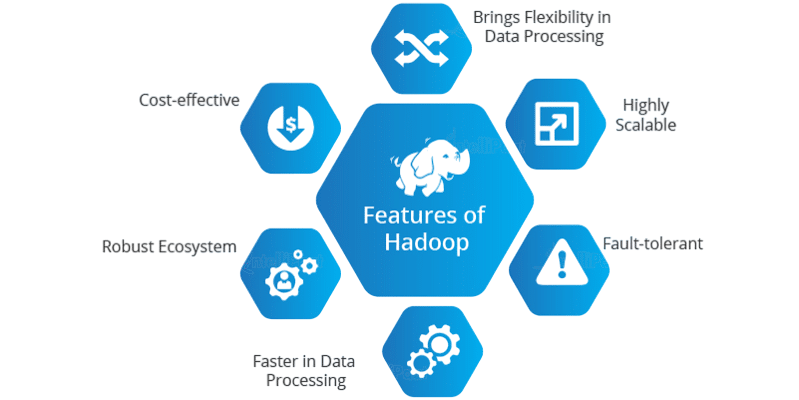
One of Hadoop’s most compelling features is its fault-tolerant design. Data is replicated across nodes in the cluster, so if one node fails, others can take over without any data loss. In addition, Hadoop supports a wide range of programming languages and offers pluggable architecture components that enhance flexibility. Its open-source nature allows developers to customize and adapt it according to specific needs, which makes it ideal for organizations with complex or evolving requirements.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
The Hadoop Ecosystem: More Than Just Storage
One of the most misunderstood aspects of Hadoop is that it’s not just a single tool but a rich ecosystem of interrelated technologies. The Hadoop ecosystem includes powerful tools like Hive (SQL-like querying), Pig (data flow scripting), HBase (NoSQL database), Sqoop (data import/export), Flume (log data collection), and Oozie (workflow scheduling). Each of these tools addresses specific challenges in data processing and management. For example, Hive allows business analysts to write SQL queries on Hadoop What is Splunk Rex , making it accessible to non-programmers. HBase enables real-time read/write access to large datasets, while Oozie allows users to automate data workflows. As big data needs grow more sophisticated, the modularity of the Hadoop ecosystem becomes a significant advantage. Organizations can pick and choose the components that best suit their use case, integrating them into a cohesive solution that grows with the business.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Scalability and Cost-Effectiveness: Hadoop’s Economic Advantage
- Horizontal Scalability – Hadoop can easily scale out by adding more nodes to a cluster, accommodating growing data volumes without major infrastructure changes.
- Cost-Effective Storage – Utilizes commodity hardware and the Hadoop Distributed File System (HDFS) to store massive datasets at a fraction of traditional storage costs.
- Efficient Resource Utilization – Distributes processing and storage across multiple nodes, optimizing hardware usage and minimizing wastage What is Data Pipelining.
- Flexible Data Handling – Handles structured, semi-structured, and unstructured data without expensive database solutions.
- Reduced Total Cost of Ownership (TCO) – Open-source nature and scalable architecture lower licensing fees and maintenance costs.
- Support for Big Data Growth – Enables businesses to manage rapidly expanding data volumes without significant additional investment.

Hadoop in Real-Time and Batch Processing
- Batch Processing with MapReduce – Hadoop efficiently processes large datasets in batches using the MapReduce framework, ideal for historical data analysis.
- Real-Time Processing with Apache Hadoop Ecosystem – Tools like Apache HBase, Apache Kafka, and Apache Spark enable real-time data ingestion and processing on Hadoop clusters.
- Scalable Data Handling – Both real-time and batch processing can scale horizontally across multiple nodes, accommodating growing data volumes.
- Flexibility Across Data Types – Supports structured, semi-structured, and unstructured data in both processing modes Data Science Training.
- Integration with Analytics Tools – Processed data can be used for reporting, dashboards, machine learning, and predictive analytics.
- Optimized Resource Utilization – Hadoop distributes tasks efficiently across nodes, ensuring performance consistency for both batch and real-time workloads.
- Batch Processing with MapReduce – Hadoop efficiently processes large datasets in batches using the MapReduce framework, ideal for historical data analysis.
- Real-Time Processing with Apache Hadoop Ecosystem – Tools like Apache HBase, Apache Kafka, and Apache Spark enable real-time data ingestion and processing on Hadoop clusters.
- Scalable Data Handling – Both real-time and batch processing can scale horizontally across multiple nodes, accommodating growing data volumes Kafka vs RabbitMQ .
- Across Data Types – Supports structured, semi-structured, and unstructured data in both processing modes.
- Integration with Analytics Tools – Processed data can be used for reporting, dashboards, machine learning, and predictive analytics.
- Optimized Resource Utilization – Hadoop distributes tasks efficiently across nodes, ensuring performance consistency for both batch and real-time workloads.
- Cloud Compatibility – Hadoop can be deployed on public, private, or hybrid
- Big Data Tool Integration – Seamlessly works with Apache Spark, Hive, Pig, HBase, and Kafka for enhanced analytics and real-time processing BFSI Sector Big Data Insights .
- Support for AI and Machine Learning – Integrates with frameworks like TensorFlow, PyTorch, and MLlib for predictive analytics and intelligent applications.
- Data Lake Implementation – Hadoop serves as the backbone for modern data lakes, consolidating structured and unstructured data for advanced analytics.
- API and Connector Support – Offers APIs and connectors to integrate with business intelligence tools, SQL engines, and cloud-native services.
- Hybrid Technology Stack – Works alongside modern databases, microservices, and containerized applications to support enterprise digital transformation.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Hadoop in Real-Time and Batch Processing
Integration with Modern Technologies and Cloud Platforms
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Use Cases Driving Hadoop’s Continued Relevance
Hadoop’s adaptability makes it suitable for a wide range of industries and use cases. In finance, Hadoop is used for fraud detection, risk modeling, and compliance analytics. In healthcare, it enables genomic data analysis, predictive diagnostics, and patient record management. In retail, Hadoop helps with customer segmentation, inventory forecasting, and recommendation engines. BFSI Reasons for Moving Into Big Data Career Media companies use Hadoop to analyze audience behavior and optimize content delivery, while government agencies employ it for census data processing, crime prediction, and policy planning. One particularly impactful use case is in cybersecurity. Hadoop’s ability to analyze vast amounts of log data in real-time helps organizations detect anomalies and respond to threats more quickly. Its flexibility ensures that as new use cases emerge, Hadoop can be adapted to meet evolving requirements without requiring a complete overhaul.
The Future of Hadoop in a Cloud-First World
Despite competition from newer tools like Snowflake, Databricks, and cloud-native platforms, Hadoop continues to hold its own particularly in hybrid and on-premise environments. The shift to the cloud has raised questions about Hadoop’s future, but rather than being replaced, Hadoop is being transformed. Many organizations are moving from traditional HDFS clusters to cloud-based object storage solutions like Amazon S3 and Azure Blob Storage, using Hadoop-compatible An ETL Audit Process tools to access data. Hadoop 3.x introduced several cloud-friendly features, including support for erasure coding, containerization, and resource management improvements through YARN. The ecosystem has evolved to support cloud-native operations, ensuring that Hadoop remains a relevant player in a cloud-first world. As data continues to explode in volume and variety, the need for scalable, flexible, and cost-effective big data solutions will only grow. Hadoop, with its mature ecosystem and robust architecture, is well-positioned to meet these demands for years to come.
Conclusion
The Hadoop ecosystem in India has matured significantly, driven by digital transformation, government initiatives, and a vibrant technology landscape. From early adoption in telecom and BFSI to cutting-edge use cases in healthcare and smart cities, Hadoop Ecosystem has become an integral part of India’s data journey. As the country continues to generate and harness vast amounts of information,Data Science Training Hadoop’s role as a scalable and efficient data platform will only grow stronger. With supportive policies, skilled talent, and cloud infrastructure, India is poised to become a global hub for big data innovation powered by Hadoop.




