
Last updated on 01st Oct 2025| 11702
- Introduction to Spark SQL
- Components and Architecture
- Spark SQL vs Hive
- DataFrame API
- Using SQL Queries in Spark
- Data Sources Supported
- Performance Optimizations
- Conclusion
Introduction to Spark SQL
Apache Spark SQL is a module within Apache Spark that is designed for structured data processing. It brings the power of relational processing to the big data ecosystem. Spark SQL allows users to run SQL queries alongside data processing programs written in Java, Scala, Python, and R. Its main goal is to bridge the gap between relational databases and Spark’s functional programming API, offering a more seamless and efficient way of handling large-scale data analysis. With Spark SQL, developers can perform data querying using SQL syntax or use the Spark DataFrame and Dataset APIs. This flexibility allows for greater integration with existing data infrastructure and analytics tools, as well as improved performance Database Training through its optimized execution engine. Spark SQL is a powerful module of Apache Spark designed for processing structured and semi-structured data using SQL queries. It combines the familiarity of SQL with the scalability and speed of Spark’s distributed computing engine. Spark SQL supports querying data from various sources like JSON, Hive, Parquet, and JDBC. It provides a programming interface through DataFrames and Datasets, enabling optimized execution plans and seamless integration with Spark’s machine learning and streaming libraries. By bridging traditional SQL and big data processing, Spark SQL allows developers and analysts to efficiently analyze large datasets using both SQL and programming languages like Java, Scala, and Python. Introduced in Apache Spark 1.0, Attributes in DBMS Spark SQL has become one of the most widely used modules in Spark. Its introduction marked a significant milestone by enabling users to interact with Spark using a language they already knew SQL. By supporting both SQL queries and programmatic access through DataFrames and Datasets, Spark SQL became ideal for diverse users from data engineers and data scientists to business analysts.
Components and Architecture
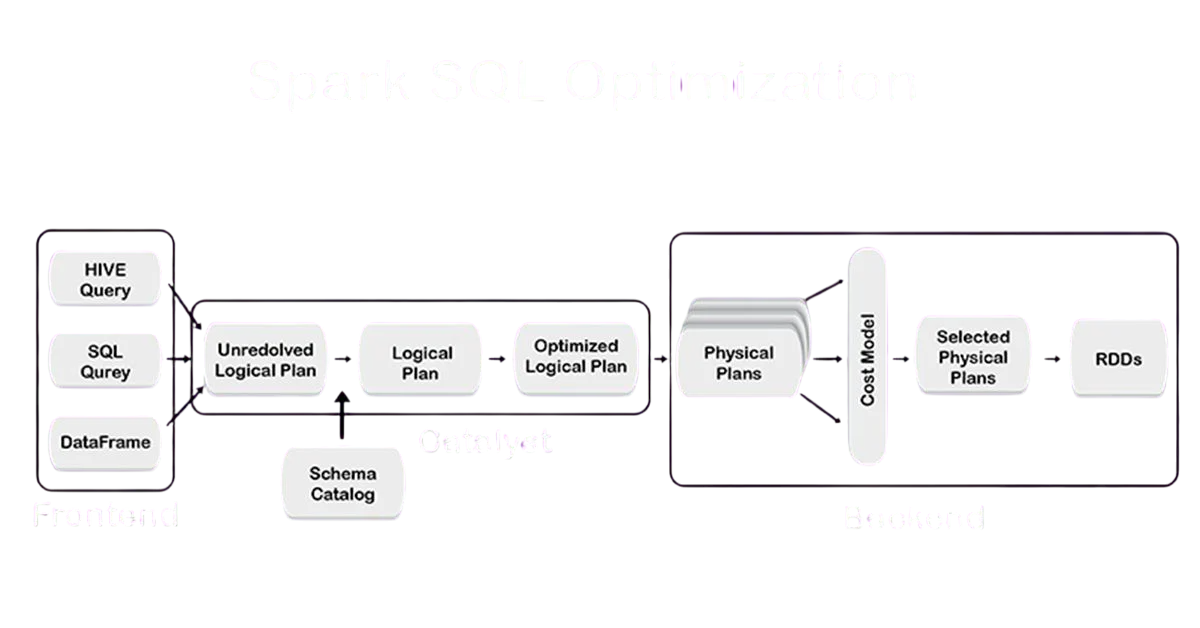
- Catalyst Optimizer: A powerful query optimization engine that parses, analyzes, and optimizes logical plans. It performs tasks such as constant folding, predicate pushdown, and physical plan generation.
- Tungsten Execution Engine: Enhances physical execution performance using whole-stage code generation and in-memory computation Data Architect Salary .
- Data Sources API: Allows Spark SQL to connect with a variety of structured data sources, including Hive, Avro, Parquet, ORC, JSON, JDBC, and more.
- DataFrames and Datasets: Abstract representations of structured data, offering both compile-time type safety (Datasets) and flexibility (DataFrames).
- SQL Parser: Converts SQL statements into logical plans that Spark SQL can optimize and execute.
Spark SQL consists of several critical components:
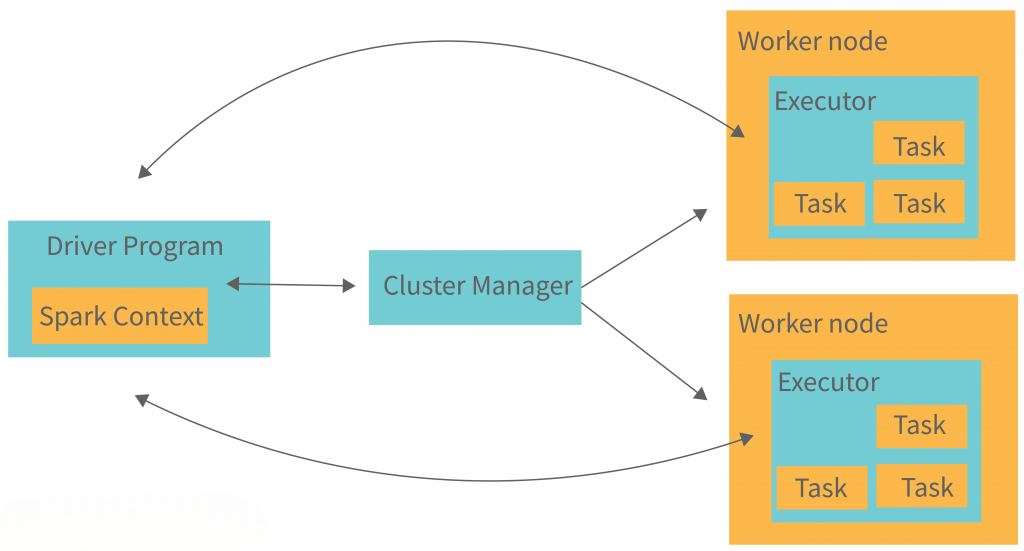
Together, these components allow Spark SQL to handle complex query workloads efficiently and integrate easily with big data systems.
Do You Want to Learn More About Database? Get Info From Our Database Online Training Today!
Spark SQL vs Hive
While both Spark SQL and Apache Hive are used for querying structured data, they differ significantly in performance and usability:
| Feature | Spark SQL | Hive |
|---|---|---|
| Execution Engine | Tungsten, Catalyst | MapReduce or Tez |
| Performance | Faster, in-memory | Slower, disk-based |
| Language Support | SQL, DataFrames, Datasets | HiveQL (SQL-like) |
| Real-Time Support | Yes | Limited |
| Compatibility | Supports Hive metastore, UDFs | HiveQL only |
| Execution Engine | Tungsten, Catalyst | MapReduce or Tez |
Would You Like to Know More About Database? Sign Up For Our Database Online Training Now!
DataFrame API
The DataFrame API is a core component of Apache Spark, designed to provide a high-level abstraction for working with structured and semi-structured data. A DataFrame is essentially a distributed collection of data organized into named columns, similar to a table in a relational database or a data frame in Python’s pandas library. It allows developers to perform complex data manipulations and queries using a concise, expressive, and optimized API. DataFrames can be created from various data sources, including JSON, CSV, Parquet files, Hive tables, and existing RDDs (Resilient Distributed Datasets). The API supports a wide Database Training range of operations such as filtering, aggregation, joining, sorting, and grouping, enabling efficient data exploration and transformation. One of the key advantages of the DataFrame API is its optimization through Spark’s Catalyst query optimizer, which automatically generates efficient execution plans. This means that users get the benefits of distributed computing without needing to manually optimize their code. The API is available in multiple programming languages, including Scala, Java, Python, and R, making it accessible to a broad audience. By combining the ease of use of SQL-like syntax with the power of distributed processing, the DataFrame API has become a preferred tool for big data analysis and machine learning pipelines in Spark.

Using SQL Queries in Spark
Spark SQL allows users to register DataFrames as temporary views and run SQL queries against Cassandra Keyspace them:
Example:
- df.createOrReplaceTempView(“people”)
- sqlDF = spark.sql(“SELECT * FROM people WHERE age > 21”)
- sqlDF.show()
This approach is particularly useful for business analysts who are more familiar with SQL than programming. Spark SQL supports most standard ANSI SQL syntax, including joins, subqueries, window functions, group by, order by, etc.
To Earn Your Database Certification, Gain Insights From Leading Blockchain Experts And Advance Your Career With ACTE’s Database Online Training Today!
Data Sources Supported
Spark SQL can read and write data from a wide variety of data sources:
- JSON: Semi-structured data support
- Parquet: Columnar storage format with efficient compression
- Avro: For serializing data
- ORC: Optimized row columnar format Apache Spark Certification
- Hive: Full support for Hive tables and UDFs
- JDBC: Access relational databases like MySQL, PostgreSQL
- CSV: Read/write CSV files
- Delta Lake: ACID-compliant storage on top of data lakes
This makes Spark SQL a powerful tool for heterogeneous data environments.
Preparing for a Database Job? Have a Look at Our Blog on Database Interview Questions and Answers To Ace Your Interview!
Performance Optimizations
Spark SQL uses multiple optimization techniques:
- Catalyst Optimizer: Analyzes queries and rewrites them for better performance.
- Predicate Pushdown: Pushes filtering operations to the data source level.
- Column Pruning: Reads only required columns Spark SQL .
- Whole-Stage Code Generation: Converts query plans into optimized Java bytecode.
- Broadcast Joins: Efficient joins by broadcasting smaller tables across nodes.
These enhancements help Spark SQL deliver superior performance even with large-scale datasets.
Conclusion
Spark SQL is a powerful module that bridges the gap between traditional SQL-based analytics and big data processing. It supports a wide range of data sources, enables both batch and real-time processing, and integrates well with other Spark components. With its strong optimization engines and flexible APIs, Spark SQL empowers data engineers, analysts, and scientists to extract insights from large-scale structured data efficiently.As organizations increasingly rely on data for strategic decisions, tools like Spark SQL become critical for managing and analyzing information in real time. Its ability to scale, integrate, Database Training and adapt makes it a foundational element in any modern data platform. In conclusion, the DataFrame API in Apache Spark offers a powerful, flexible, data analysis and efficient way to handle large-scale structured data. By providing a high-level, SQL-like interface combined with the benefits of distributed computing, it simplifies complex data processing tasks. Its support across multiple languages and automatic optimization through Spark’s Catalyst engine makes it an essential tool for data engineers and analysts working with big data. Overall, the DataFrame API bridges the gap between ease of use and performance, enabling faster development and insightful analytics on massive datasets.




