
Last updated on 01st Oct 2025| 10269
- Introduction to Real-Time Data Processing
- Spark Execution Model
- Spark Core and RDDs
- Spark Streaming Architecture
- DStreams and Structured Streaming
- Parallelism in Spark
- Resource Management with YARN/Mesos
- Latency and Throughput
- Conclusion
Introduction to Real-Time Data Processing
Real-time data processing involves analyzing and acting on data as it is created or received. Unlike batch processing, where data is collected, stored, and processed at a later time, real-time processing demands low latency and high responsiveness. In the era of big data and the Internet of Things (IoT), real-time processing is essential for applications such as fraud detection, recommendation engines, social media feeds, and real-time analytics. Apache Spark is a powerful, open-source distributed computing system known for its ability Data Science Training to process large volumes of data quickly. It supports both batch and real-time data processing, making it a versatile tool for big data applications. Real-time data processing involves capturing, analyzing, and acting on data as it is generated or received, enabling immediate insights and responses. Unlike batch processing, which handles data in large chunks after collection, real-time processing works continuously with minimal latency. This approach is essential for applications requiring instant decision-making, such as fraud detection, online recommendations, and monitoring systems. Technologies like Apache Spark, Apache Kafka, and Apache Flink are commonly used to manage streaming data efficiently. Real-time data processing helps organizations improve responsiveness, optimize operations, and deliver better user experiences by leveraging up-to-the-minute information.
Spark Execution Model
Spark uses a master-slave architecture consisting of a driver and multiple executors. The driver coordinates the execution of tasks, maintains information about the Spark application, and communicates with the cluster manager. Executors run on worker nodes and execute tasks assigned by the driver. The Spark application is divided into jobs, which are further divided into stages, and each stage contains tasks that are distributed across executor nodes for parallel execution. This model allows Spark to efficiently manage distributed resources and perform parallel computation Cassandra Keyspace. The Spark Execution Model defines how Apache Spark processes data across a distributed cluster. It starts with a user submitting a job, which Spark breaks into smaller tasks.
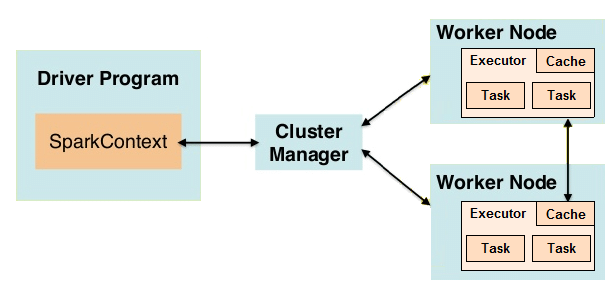
These tasks are organized into stages based on data shuffling needs. Spark uses Resilient Distributed Datasets (RDDs) or DataFrames as core abstractions for distributed data. The DAG (Directed Acyclic Graph) scheduler creates an execution plan optimizing task execution and fault tolerance. Tasks run in parallel on worker nodes, with Spark managing data partitioning and resource allocation. This model enables fast, scalable, and fault-tolerant processing of large-scale data workloads.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Spark Core and RDDs
The foundation of Spark lies in its core component and the Resilient Distributed Dataset (RDD). RDDs are immutable, fault-tolerant collections of objects distributed across nodes. They allow developers to perform transformations and actions in a distributed manner Big Data Analytics . Spark Core handles task scheduling, memory management, fault recovery, and interaction with storage systems.
RDDs support two types of operations:
- Transformations: Lazy operations like map, filter, and reduceByKey that define a new RDD.
- Actions:Operations like collect, count, and saveAsTextFile that trigger execution.
This lazy evaluation model allows Spark to optimize query execution through DAG (Directed Acyclic Graph) optimization.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Spark Streaming Architecture
Spark Streaming extends the Spark API to process streaming data in real-time. It divides the data stream into small batches using micro-batch processing. Each batch is treated as an RDD and processed Spark SQL using the standard Spark API.
The high-level flow includes:
- Receiving real-time data from sources like Kafka, Flume, or sockets.
- Dividing the stream into batches.
- Processing each batch using Spark transformations.
- Outputting results to storage systems or dashboards.
This model offers high throughput and fault tolerance while leveraging Spark’s existing ecosystem.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
DStreams and Structured Streaming
- DStreams (Discretized Streams): The original abstraction in Spark Streaming. DStreams represent continuous streams of data as a sequence of RDDs. Operations are performed on each RDD to process the stream. DStreams (Discretized Streams) are a core abstraction in Apache Spark Streaming used to process real-time data. They represent continuous data streams as a series of small, discrete batches called micro-batches. Each batch is processed using Spark’s batch processing engine, allowing Spark Streaming to handle live data efficiently with fault tolerance and scalability. DStreams support various transformations like map, reduce, and window operations, enabling complex analytics Data Science Training on streaming data. Though effective, DStreams have been largely succeeded by Structured Streaming in newer Spark versions, which offers a more unified and optimized approach to stream processing.
- Structured Streaming: Structured Streaming is a modern stream processing engine built on top of Apache Spark’s Spark SQL engine. It allows developers to process real-time data streams using high-level APIs like DataFrames and Datasets, enabling seamless integration with batch and interactive workloads. Unlike older models like DStreams, Structured Streaming treats streaming data as an unbounded table, allowing continuous query execution with incremental updates. It supports exactly-once fault tolerance, event-time processing, and windowed aggregations. With its ease of use, scalability, and integration with various data sources and sinks, Structured Streaming is widely adopted for building reliable, scalable, and efficient real-time data processing applications.
Structured Streaming improves usability, performance, and integration with batch processing. It also supports event-time processing, watermarking, and output modes like append, update, and complete.

Parallelism in Spark
- Data Partitioning: Spark divides large datasets into smaller partitions distributed across cluster nodes for parallel processing.
- Task Scheduling: Each partition is processed as a separate task that runs concurrently on different executors.
- RDD and DataFrame Operations: Transformations and actions on RDDs/DataFrames are executed in parallel across partitions Scala Certification .
- Stage and Task Parallelism: Jobs are split into stages; each stage contains multiple tasks that execute in parallel.
- Parallel Execution: Enables efficient use of cluster resources, reducing processing time for big data workloads.
- Custom Parallelism Control: Developers can specify the number of partitions to optimize parallelism based on workload and cluster size.
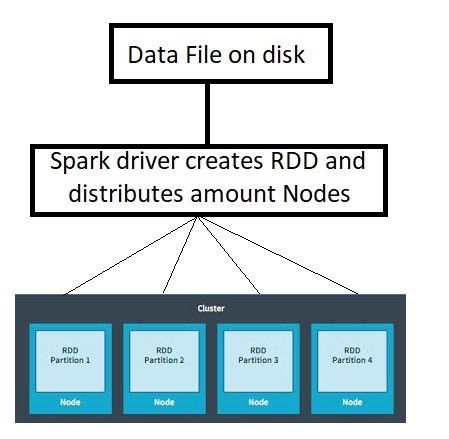
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Ace Your Interview!
Resource Management with YARN/Mesos
- Cluster Resource Allocation: YARN and Mesos manage and allocate CPU, memory, and storage resources across multiple applications in a cluster.
- Job Scheduling: Both systems schedule Spark jobs efficiently, ensuring fair resource distribution and prioritization.
- Scalability: Enable dynamic scaling by allocating resources based on workload demands and cluster availability Apache Spark Certification.
- Fault Tolerance: Detect node failures and reallocate resources to maintain job execution without data loss.
- Multi-Tenancy Support: Allow multiple users and applications to share cluster resources securely and efficiently.
- Integration with Spark: Spark runs as an application on YARN or Mesos, leveraging their resource management capabilities for optimized execution.
Latency and Throughput
Latency and throughput are two critical performance metrics in real-time data processing systems like Apache Spark. Latency refers to the time it takes for a system to process a single unit of data or a batch from input to output. Low latency is essential for applications that require immediate or near-instant responses, such as fraud detection or live monitoring systems. On the other hand, throughput measures the amount of data a system can process within a given time frame, typically expressed as records per second or bytes per second. High throughput ensures that large volumes of data can be handled efficiently Data Architect Salary , which is vital for big data applications dealing with continuous data streams. Balancing latency and throughput often involves trade-offs. For example, increasing batch size in Spark Streaming can improve throughput by processing more data at once but may increase latency as data waits longer before processing. Conversely, smaller batches reduce latency but may lower throughput due to overhead in task management. Optimizing these metrics depends on the specific use case and system requirements. Spark offers several configuration options and architectural features to tune latency and throughput, such as adjusting batch intervals, leveraging structured streaming, and optimizing resource allocation. Understanding and managing latency and throughput effectively enables organizations to build real-time data processing systems that are both fast and scalable.
Conclusion
Apache Spark provides a powerful framework for real-time parallel data processing through its flexible architecture, high-level APIs, and integration with cluster resource managers. With Spark Streaming and Structured Streaming, it supports real-time applications across domains such as IoT, Data Science Training Resource Management with YARN/Mesos, finance, healthcare, and social media. Its parallel execution model, fault-tolerant mechanisms, and scalable design make it a leading choice for developers building modern data pipelines and analytics solutions. As the demand for real-time insights continues to grow, Spark’s capabilities will remain at the forefront of big data innovation.




