
Last updated on 02nd Oct 2025| 10026
- Introduction to Random Forest
- Key Features of the Algorithm
- Importance of Data Traits
- Feature Importance and Selection
- Hyperparameter Tuning
- Impact of Data Size and Distribution
- Ensemble Method Advantages
- Accuracy and Bias-Variance Tradeoff
- Conclusion
Introduction to Random Forest
Random Forest Classifiers is a supervised learning algorithm developed by Leo Breiman that combines the concept of bagging (Bootstrap Aggregating) and decision trees. It improves prediction accuracy by creating a collection of de-correlated decision trees and aggregating their predictions. Each tree in the ensemble is built from a sample drawn with replacement (bootstrap sample) from the training set Data Science Training. Moreover, when splitting nodes during tree construction, the algorithm searches for the best split among a random subset of the features, hence the term “Random” in Random Forest. Random Forest helps to reduce overfitting, a common problem in single decision trees, by averaging multiple trees to stabilize the model’s output.
Key Features of the Algorithm
- Ensemble of Decision Trees: The core idea is to combine multiple weak learners (decision trees) to create a strong learner.
- Bootstrapping: Trees are trained on different samples of the data to introduce diversity.
- Random Feature Selection: A random subset of features is considered when splitting a node, which helps in reducing correlation among trees Big Data is Transforming Retail Industry .
- Aggregation: Predictions from all the trees are combined using majority voting (classification) or averaging (regression).
- OOB (Out-of-Bag) Error Estimation: A built-in method to estimate the performance of the model without needing separate cross-validation.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Importance of Data Traits
Random Forest performance significantly depends on the characteristics of the input data. Some of the key traits include:
- Feature Diversity: High variance among features allows better decision boundaries to be drawn.
- Balanced Class Distribution: Class imbalance may lead to biased predictions. Techniques like SMOTE or class weighting can help.
- Missing Data: What is Data Pipelining Though Random Forest can handle missing data to some extent, preprocessing may still be necessary.
- Outliers: Random Forest is relatively robust to outliers due to its averaging nature, but extreme cases might still affect performance.
- Feature Importance: Measures how much each input feature contributes to the model’s predictions.
- Model-Based Methods: Algorithms like Random Forest, XGBoost, and SHAP provide built-in feature importance scores.
- Feature Selection: Reduces the number of input variables to enhance model performance and reduce overfitting Data Science Training.
- Filter Methods: Use statistical techniques (e.g., correlation, chi-square) to select relevant features before modeling.
- Wrapper Methods: Evaluate feature subsets by training models (e.g., Recursive Feature Elimination).
- Embedded Methods: Perform selection during model training (e.g., LASSO, Decision Trees).
- Improves Efficiency: Leads to faster training times and more interpretable models.
- Reduction in Variance: By averaging multiple trees, the model generalizes better.
- Robustness: Resistant to overfitting and noisy data.
- Handling High Dimensionality: Performs well with a large number of features Data Analytics Tools for Big Data Analysis .
- Internal Validation: OOB error provides an unbiased estimate of model performance.
- Low Bias: Multiple trees capture complex relationships in the data.
- Low Variance: Averaging reduces model variance.
- Consistent Performance: Tends to perform reliably across different datasets without extensive tuning.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Feature Importance and Selection

Hyperparameter Tuning
Hyperparameter tuning is a critical step in optimizing machine learning models to achieve the best performance. Unlike model parameters, which are learned during training, hyperparameters are set before the learning process begins and control aspects such as model complexity, learning rate, regularization strength, and tree depth. Choosing the right hyperparameter values can significantly improve accuracy, reduce overfitting, and enhance generalization. Common tuning techniques include grid search, random search, and Bayesian optimization, What is Splunk Rex often combined with cross-validation to evaluate performance reliably. Efficient hyperparameter tuning ensures that the model is well-calibrated to the data, leading to more robust and accurate predictions. Hyperparameter tuning is an essential process in machine learning that involves selecting the optimal set of hyperparameters to improve model performance.
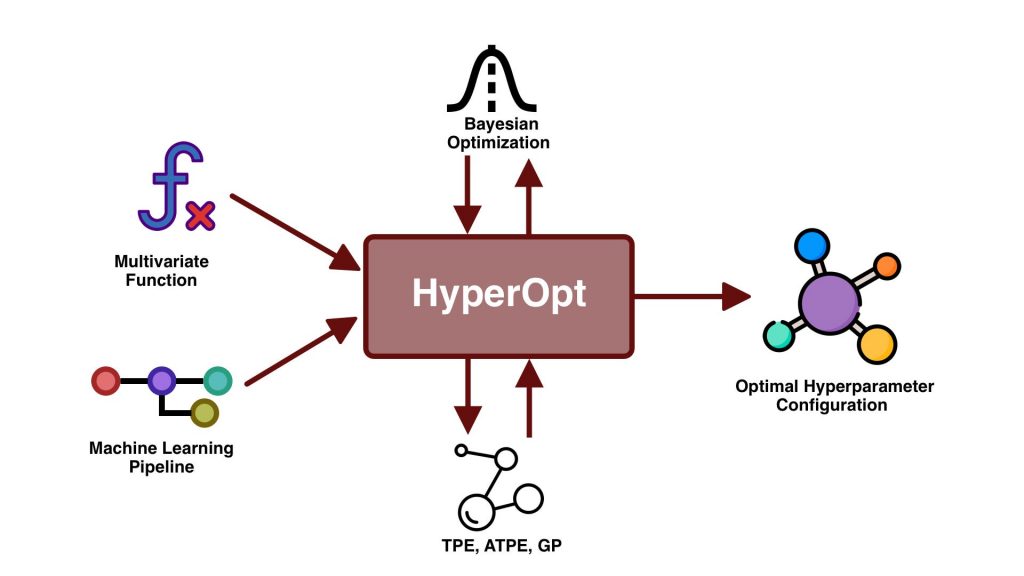
Unlike parameters learned during training, hyperparameters are set before training and influence how the model learns. Examples include learning rate, number of trees, and regularization strength. Proper tuning helps balance bias and variance, enhances accuracy, and reduces overfitting. Common techniques include grid search, random search, and Bayesian optimization, often paired with cross-validation What is Azure Data Lake for reliable evaluation. Effective hyperparameter tuning ensures that models are better adapted to the data, resulting in more accurate and generalizable predictions across different datasets.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Impact of Data Size and Distribution
Random Forest generally performs well on large datasets. However, the quality and representativeness of data are critical. If the training data does not cover the full range of input space, the model might not generalize well. The size and distribution of data play a critical role in the performance and reliability of machine learning models. Larger datasets generally lead to better model accuracy by providing more information for learning patterns and reducing overfitting. However, they also increase computational cost and training time. The distribution of data affects how well a model generalizes; imbalanced or skewed distributions can cause biased predictions, especially in classification tasks. Proper handling of distribution issues such as normalization, stratified sampling, or resampling techniques is essential. Understanding both data size and distribution helps in building robust, fair, Elasticsearch Nested Mapping and efficient machine learning systems. The size and distribution of data play a critical role in the performance and reliability of machine learning models. Larger datasets generally lead to better model accuracy by providing more information for learning patterns and reducing overfitting. However, they also increase computational cost and training time. The distribution of data affects how well a model generalizes; imbalanced or skewed distributions can cause biased predictions, especially in classification tasks. Proper handling of distribution issues—such as normalization, stratified sampling, or resampling techniques—is essential. Understanding both data size and distribution helps in building robust, fair, and efficient machine learning systems.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Ensemble Method Advantages
Random Forest is an ensemble method that offers several advantages over single-model approaches:
Accuracy and Bias-Variance Tradeoff
Random Forest is particularly effective in addressing the bias-variance tradeoff:
Conclusion
Random Forest is a powerful and flexible classification algorithm that excels in handling large, complex datasets with high dimensionality. It balances bias and variance through ensemble learning and provides internal mechanisms to estimate performance and feature importance. By tuning hyperparameters and understanding the impact of data traits, practitioners can significantly boost the accuracy and reliability Data Science Training of Random Forest classifiers. In a world increasingly driven by data, mastering Random Forest opens up numerous opportunities in fields such as finance, healthcare, marketing, and technology. It is a foundational tool in any data scientist’s toolkit and continues to evolve with advancements in computing and machine learning research. Whether you’re analyzing customer churn, detecting fraud, Ensemble Method Advantages or making medical predictions, Random Forest offers a robust, interpretable, and scalable solution that stands the test of real-world applications.




