
Last updated on 02nd Oct 2025| 10517
- Introduction to Sqoop
- Role in Big Data Ecosystem
- Features and Benefits
- Sqoop Architecture
- Importing from RDBMS to HDFS
- Exporting from HDFS to RDBMS
- Commands and Syntax
- Integration with Hive and HBase
- Conclusion
Introduction to Sqoop
Apache Sqoop (SQL-to-Hadoop) is an open-source tool designed to facilitate the transfer of data between relational databases (such as MySQL, Oracle, or PostgreSQL) and the Hadoop ecosystem. It plays a crucial role in Big Data environments by efficiently importing structured data into Hadoop Distributed File System (HDFS) or exporting processed data back to relational databases. Sqoop automates much of the process, offering connectors for various RDBMS and compatibility with tools like Hive, HBase, and HCatalog. In today’s data-driven world, organizations generate massive volumes of structured data through various transactional systems Data Science Training. To gain insights from this data, it often needs to be processed using Hadoop-based technologies. Sqoop bridges this gap by serving as a robust and scalable solution for data ingestion and export. Apache Sqoop is an open-source tool designed to efficiently transfer bulk data between Hadoop ecosystems and relational databases. It simplifies the process of importing data from structured databases like MySQL, Oracle, or PostgreSQL into Hadoop Distributed File System (HDFS) for big data processing. Similarly, Sqoop can export processed data from Hadoop back into relational databases. By automating these data transfers, Sqoop enables seamless integration between traditional data storage systems and big data platforms, Dedup : Splunk Documentation making it essential for ETL (Extract, Transform, Load) workflows in Hadoop environments. Its ease of use, scalability, and support for various databases make it a popular choice in data engineering.
Role in Big Data Ecosystem
Sqoop holds a central position in Big Data workflows, particularly when integrating traditional RDBMS systems with distributed computing frameworks. Hadoop excels at processing large-scale data sets but often lacks structured data management. Relational databases, on the other hand, handle structured data well but struggle with large-scale analytics. Sqoop provides seamless movement between these environments. This capability is especially critical for ETL (Extract, Transform, Load) workflows. Enterprises can import large amounts of operational data from traditional databases into Hadoop for advanced analytics and later export Kafka vs RabbitMQ the results back to production systems. Sqoop plays a vital role in the big data ecosystem by acting as a bridge between traditional relational databases and big data platforms like Hadoop.
It facilitates the efficient transfer of large volumes of structured data into Hadoop’s distributed storage systems for processing and analysis. This integration enables organizations to leverage existing enterprise data within modern big data workflows. Sqoop also supports exporting processed data back to relational databases, ensuring smooth data movement across systems. By automating these data transfers, Sqoop simplifies ETL processes and helps maintain data consistency, making it a key component in big data pipelines and analytics solutions.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Features and Benefits
Apache Sqoop offers a rich set of features:
- High Performance: Utilizes MapReduce for parallel data transfers.
- Data Import/Export: Supports full and incremental loads.
- Connector Support: Integrates with MySQL, PostgreSQL, Oracle, SQL Server, DB2, and more
- Hive and HBase Integration: Allows automatic population of Hive tables Big Data is Transforming Retail Industry and HBase stores.
- Incremental Loads: Detects new rows or updates in source databases.
- Compression: Supports GZip, BZip2, and other formats to reduce storage usage.
- Security: Supports Kerberos authentication and encrypted passwords.
- Automation: Facilitates scripting and job scheduling.
These features make Sqoop an essential part of any enterprise Big Data architecture.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Sqoop Architecture
The architecture of Sqoop revolves around client interaction with a command-line interface and a MapReduce-based back-end. Here’s how the architecture works:
- Client Interface: Users define import/export jobs using command-line options or saved job configurations.
- Code Generation: Sqoop generates Java classes that represent database records.
- MapReduce Jobs: The engine submits MapReduce jobs to handle parallel import/export operations Data Science Training.
- Data Connectors: JDBC-based connectors communicate with the RDBMS.
- Storage Systems: Imported data is written into HDFS, Hive, or HBase; exported data goes to RDBMS tables.
The use of MapReduce ensures parallelization, fault tolerance, and scalability during data transfers.

Importing from RDBMS to HDFS
Apache Sqoop is widely used to import data from relational database management systems (RDBMS) into the Hadoop Distributed File System (HDFS). It connects to databases like MySQL, Oracle, or PostgreSQL using JDBC drivers and transfers large volumes of structured data efficiently. Sqoop divides the import process into multiple parallel tasks, Essential Concepts of Big Data & Hadoop leveraging Hadoop’s distributed architecture to speed up data transfer. Users can specify entire tables, specific columns, or custom SQL queries to control the data imported.
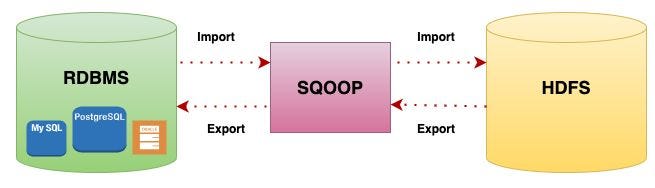
Sqoop also supports incremental imports, allowing the system to fetch only new or updated records since the last import, which optimizes performance for ongoing data synchronization. The imported data can be saved in various formats such as text, Avro, or Parquet, compatible with Hadoop processing tools like Hive, Spark, and MapReduce. This capability enables organizations to integrate traditional enterprise data with big data platforms, facilitating advanced analytics and decision-making.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Exporting from HDFS to RDBMS
Random Forest generally performs well on large datasets. However, the quality and representativeness of data are critical. If the training data does not cover the full range of input space, the model might not generalize well. The size and distribution of data play a critical role in the performance and reliability of machine learning models. Larger datasets generally lead to better model accuracy by providing more information for learning patterns and reducing overfitting. However, they also increase computational cost and training time. The distribution of data affects how well a model generalizes; imbalanced or skewed distributions can cause biased predictions, Big Data Can Help You Do Wonders especially in classification tasks. Proper handling of distribution issues such as normalization, stratified sampling, or resampling techniques is essential. Understanding both data size and distribution helps in building robust, fair, and efficient machine learning systems. The size and distribution of data play a critical role in the performance and reliability of machine learning models. Larger datasets generally lead to better model accuracy by providing more information for learning patterns and reducing overfitting. However, they also increase computational cost and training time. The distribution of data affects how well a model generalizes; imbalanced or skewed distributions can cause biased predictions, especially in classification tasks. Proper handling of distribution issues—such as normalization, stratified sampling, or resampling techniques—is essential. Understanding both data size and distribution helps in building robust, fair, and efficient machine learning systems.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Commands and Syntax
Sqoop commands generally follow a similar structure:
- Import Command: sqoop import for importing data.
- Export Command: sqoop export for exporting data.
- Codegen: Generates Java classes: sqoop codegen Become a Big Data Analyst .
- List Databases/Tables: sqoop list-databases and sqoop list-tables.
- Eval: Run SQL queries: sqoop eval.
Common Syntax:
- sqoop import \
- –connect jdbc:mysql://localhost/db \
- –username user –password pass \
- –table tablename \
- –target-dir /output_dir \
- –m 1
HBase Integration:
- sqoop import \
- –connect jdbc:mysql://localhost/retail \
- –username user –password pass \
- –table orders \
- –hbase-table hbase_orders \
- –column-family data \
- –hbase-row-key order_id
Integration with Hive and HBase
Sqoop supports importing data directly into Hive tables or HBase stores BFSI Sector Big Data Insights :
Hive Integration:
- sqoop import \
- –connect jdbc:mysql://localhost/retail \
- –username user –password pass \
- –table customers \
- –hive-import –create-hive-table \
- –hive-database retail_dw
This command creates the Hive table and loads the data.
Conclusion
Apache Sqoop is an indispensable tool for bridging traditional relational databases with the Hadoop ecosystem. It automates the data import/export process using MapReduce, supports a wide range of RDBMS systems, integrates with Hive and HBase, Role in Big Data Ecosystem and ensures scalability through parallel execution. Despite being a batch-oriented tool, its reliability, performance, and simplicity make it a vital component of modern Big Data architectures. Whether you’re building a data lake, enabling data science workflows, Data Science Training or developing ETL pipelines, Sqoop is a proven solution for structured data migration and integration in a distributed data environment. With proper tuning and integration, Sqoop empowers businesses to leverage the full power of their data assets within Hadoop. Apache Sqoop is an essential tool in the big data ecosystem, enabling efficient and reliable data transfer between relational databases and Hadoop’s distributed storage. Its ability to import data from RDBMS into HDFS and export processed data back to traditional databases bridges the gap between legacy systems and modern big data platforms. By supporting parallel processing, incremental imports, Integration with Hive and HBase and multiple data formats, Sqoop simplifies ETL workflows and ensures seamless integration of enterprise data with big data analytics tools. This makes Sqoop invaluable for organizations looking to harness the power of big data while maintaining consistency across their data environments.




