
Last updated on 02nd Oct 2025| 10021
- Introduction to Hadoop Architecture
- Core Hadoop Components
- Required Skills for a Hadoop Architect
- Programming and Scripting Proficiency
- Data Modeling and Storage Design
- System and Data Integration
- Tools to Master (Hive, Pig, Oozie, etc.)
- DevOps and Cloud Integration
- Conclusion
Introduction to Hadoop Architecture
Apache Hadoop is a distributed computing framework that allows for the processing of large datasets across clusters of computers. It comprises several core components: the Hadoop Distributed File System (HDFS) for storage, YARN (Yet Another Resource Negotiator) for resource management, and MapReduce for processing. Additionally, Hadoop’s ecosystem includes tools like Hive, Pig, HBase, and Oozie that enhance its capabilities. The Hadoop architecture is designed for scalability and fault tolerance. It distributes data across multiple nodes, allowing Data Science Training for parallel processing. Each node performs computations on the data stored locally, minimizing data movement and optimizing performance. A Hadoop Architect is responsible for designing these distributed systems, Cloud Integration, ensuring data is stored, managed, and processed effectively. In today’s data-driven world, Big Data technologies have become essential for managing and processing vast amounts of structured and unstructured data. At the heart of this revolution lies Apache Hadoop—an open-source framework that has transformed the way businesses handle big data. The role of a Big Data Hadoop Architect is critical in designing, developing,What is Data Pipelining and maintaining scalable and efficient data processing systems. This comprehensive guide explores the learning path required to become a successful Big Data Hadoop Architect, delving into the necessary skills, tools, certifications, and future opportunities in the field.
Core Hadoop Components
To understand Core Hadoop Components deeply, an architect must master its core components:
- HDFS: It splits large files into blocks and distributes them across nodes. It ensures redundancy and reliability.
- YARN: Manages and schedules resources for various applications running on the cluster.
- MapReduce: Big Data Drives Small and Medium A programming model for processing large datasets using parallel and distributed algorithms.
- Hadoop Common: Shared utilities, libraries, and APIs used across modules.
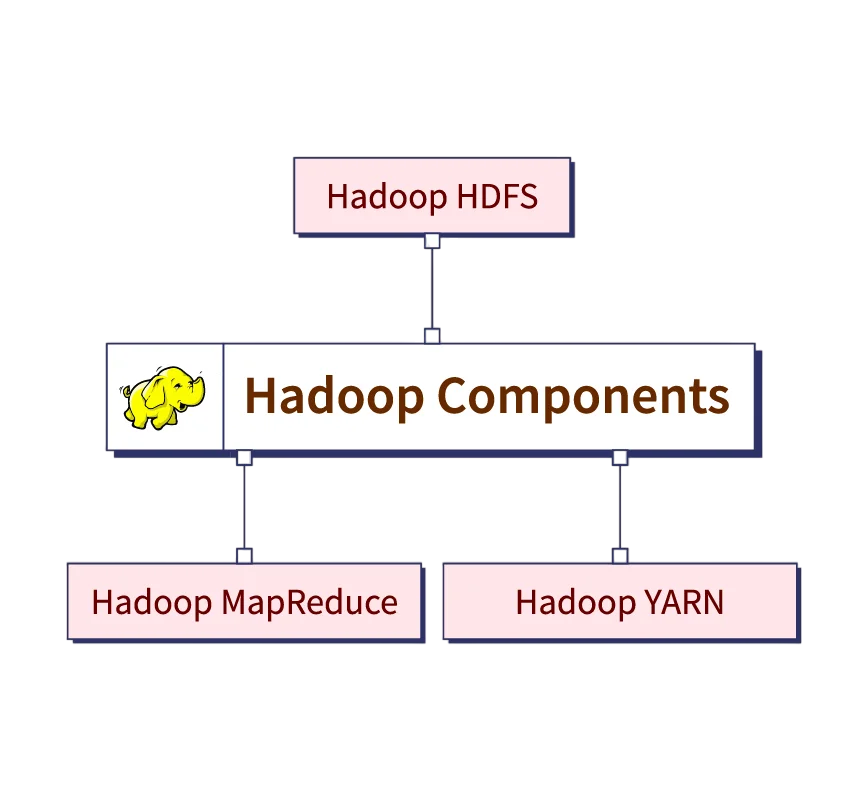
Each of these components must be configured and managed correctly for the system to perform efficiently. A Hadoop Architect must be able to configure clusters, set up fault-tolerant storage, optimize job scheduling, and troubleshoot system bottlenecks.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Required Skills for a Hadoop Architect
Becoming a Hadoop Architect involves gaining expertise in multiple domains. Here are the essential skills:
- Strong Programming Knowledge: Java is the native language of Hadoop, but Python and Scala are also widely used.
- Linux/Unix Proficiency: Since most Hadoop clusters run on Linux, a solid understanding of shell scripting and OS-level operations is essential.
- Database Knowledge: Familiarity with SQL, Big Data Analytics NoSQL databases like HBase and Cassandra, and data modeling is crucial.
- Networking and Security: Understanding firewalls, port management, encryption, and Kerberos authentication.
- Cloud Platforms: Experience with AWS, Azure, or GCP for cloud-based Hadoop implementations.
A Hadoop Architect should also be comfortable with distributed computing concepts, system design, and performance optimization strategies.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Programming and Scripting Proficiency
Programming is at the core of data processing and analytics. For Hadoop, proficiency in Java is essential, especially for writing MapReduce programs. Knowledge of Python and Scala is beneficial when working with tools like PySpark and Apache Flink. Scripting languages such as Bash and Shell are used for automation and managing tasks across nodes. Architects must write scripts to automate data ingestion, run ETL pipelines, and monitor system health. A good grasp of object-oriented programming and algorithm design helps in building efficient data processing solutions. Data architects should also be comfortable with APIs, REST services, and data serialization formats like Avro Data Science Training and Parquet. Programming and scripting skills are essential for a Hadoop Architect to effectively design and manage big data solutions. Proficiency in languages like Java, Python, and Scala enables architects to develop custom data processing applications and extend Hadoop functionalities. Scripting languages such as Shell and Bash are crucial for automating workflows, managing system tasks, and orchestrating data pipelines. Knowledge of SQL and HiveQL is also important for querying and managing data within Hadoop ecosystems. Strong programming and scripting abilities allow Hadoop Architects to optimize performance, troubleshoot issues, and integrate various tools, ensuring scalable and efficient big data environments that meet organizational needs.

Data Modeling and Storage Design
Designing an effective data storage solution requires a clear understanding of the data being processed. Hadoop supports both structured and unstructured data. Architects must decide when to use HDFS, HBase, or Hive based on access patterns Apache Hive vs HBase Guide and latency requirements.
Key data modeling skills include:
- Choosing appropriate file formats and compression techniques.
- Partitioning and bucketing data for performance.
- Designing schemas for Hive tables.
- Using columnar formats like ORC and Parquet for analytics.
An efficient data model minimizes storage costs, enhances query performance, and supports scalability What is Splunk Rex .
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
System and Data Integration
System and data integration involve combining different computing systems and data sources to function as a unified, cohesive whole. In today’s data-driven world, organizations often rely on multiple platforms, databases, and applications that generate vast amounts of data. Integration ensures that these disparate systems communicate effectively, enabling seamless data flow across the enterprise. This process is essential for creating a single source of truth, improving data accuracy, and supporting better decision-making Data Analytics Tools for Big Data Analysis . Techniques such as ETL (Extract, Transform, Load), APIs, middleware, and data pipelines are commonly used to facilitate integration. Proper system and data integration enable organizations to harness their data’s full potential by breaking down silos, enhancing operational efficiency, and enabling real-time analytics. Ultimately, it supports business agility and innovation by providing consistent, timely, and accurate data across all departments and applications.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Tools to Master (Hive, Pig, Oozie, etc.)
The Hadoop ecosystem is rich with tools that enhance its functionality. A Hadoop Architect should gain mastery in the following:
- Apache Hive: A data warehouse infrastructure built on top of Hadoop for querying and managing large datasets using SQL
- Apache Pig: A high-level platform for creating MapReduce programs using a scripting language called Pig Latin.
- Apache Oozie: A workflow scheduler system to manage Hadoop jobs Elasticsearch Nested Mapping .
- Apache HBase: A NoSQL database that runs on top of HDFS.
- Apache Spark: An in-memory data processing engine that works with Hadoop for faster performance.
- Zookeeper: Provides distributed configuration and synchronization services.
Mastery of these tools ensures the architect can design a complete end-to-end data pipeline that supports various business needs.
DevOps and Cloud Integration
Modern Hadoop deployments increasingly occur in the cloud. Architects must be familiar with cloud-based solutions and DevOps tools to ensure scalability, automation, What is Azure Data Lake and resilience.
Key cloud platforms include:
- AWS EMR: Elastic MapReduce for running big data frameworks.
- AAzure HDInsight: A cloud distribution of Hadoop components.
- AGoogle Dataproc: Managed Spark and Hadoop service.
ADevOps tools like Ansible, Docker, Terraform, and Jenkins help automate deployments, configure clusters, and manage system updates. Integration with CI/CD pipelines is also essential to streamline data engineering workflows.
Conclusion
Becoming a Big Data Hadoop Architect is a rewarding journey that requires dedication, continuous learning, and hands-on experience. This role is pivotal in the modern data landscape, where organizations depend on data for decision-making, innovation, and competitive advantage. From mastering Hadoop’s core components and ecosystem tools to ensuring system security, integration, and cloud readiness, the Hadoop Architect plays a central Data Science Training role in data infrastructure development. The learning path involves gaining technical expertise, project experience, and industry-recognized certifications. With the continued growth of big data and cloud technologies, the demand for skilled Hadoop Architects is set to rise. Those who invest in building this skill set will find themselves at the forefront of the data revolution, helping organizations harness the power of big data effectively and efficiently.




