
Last updated on 04th Oct 2025| 11157
- Introduction: From Data Lakes to Data Warehouses
- What is Apache Hive?
- Why Was Hive Created?
- How Hive Works in the Hadoop Ecosystem
- Key Features of Apache Hive
- Hive Architecture and Components
- HiveQL: The SQL of Hadoop
- Use Cases and Real-World Applications
- Hive vs Traditional Databases
- Conclusion: The Role of Hive in Big Data Analytics
Introduction: From Data Lakes to Data Warehouses
In the age of big data, businesses collect and store enormous amounts of information from a variety of sources web activity logs, mobile apps, sensors, transactions, social media, and more. Traditional relational databases can no longer keep up with the scale and unstructured nature of this data.Hadoop emerged as a distributed storage and processing solution that could manage such vast volumes, but it came with its own complexities—especially when integrating with evolving fields like Data Science course. While Hadoop was efficient for storage and processing, interacting with it required writing Java-based MapReduce code, which wasn’t accessible for most data analysts. This created a gap between the storage capability of Hadoop and the usability expected by SQL users. To address this, Apache Hive was developed, offering a bridge between the two by enabling SQL-like queries on large datasets stored in Hadoop.
What is Apache Hive?
Apache Hive is an open-source data warehouse software project built on top of Apache Hadoop. It facilitates the reading, writing, and management of large datasets stored in a distributed environment using a SQL-like interface known as HiveQL or HQL—capabilities that are often compared and contrasted in discussions of Data Science vs Data Analytics vs Big Data. Hive simplifies the complexities of Hadoop by allowing users to run queries using familiar SQL syntax.
Under the hood, these queries are converted into a series of low-level operations such as MapReduce jobs, Tez jobs, or Spark tasks, depending on the execution engine in use. The idea is to allow users to work with big data in Hadoop without needing deep knowledge of the intricacies of the Hadoop ecosystem. Whether the data is stored in CSV, ORC, Parquet, Avro, or text files, Hive provides a structured way to analyze it, making it a cornerstone technology in data warehousing over big data platforms.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Why Was Hive Created?
The origin of Hive lies in a practical business need democratizing access to big data within large organizations. Its architecture is optimized for distributed computing, allowing it to handle petabytes of data across clusters efficiently. In the early 2000s, Facebook engineers found themselves building Java-based MapReduce code for every analytics task, which was slow and repetitive.
- As the volume of data grew, it became unmanageable to write complex Java programs just to extract user metrics or generate business reports.
- Business analysts, who were well-versed in SQL but not in Java, were unable to query data directly—highlighting the gap that tools like Hive aimed to bridge, reinforcing the idea that Data Analytics Drives the Best Formula for accessible, data-driven decision-making.
- Hive was created to abstract the complexity of MapReduce and to provide a familiar SQL-like environment to analysts.
- It drastically reduced the time required to run queries and allowed more people to work with data stored in Hadoop.
Over time, Hive evolved into a robust system supporting complex queries, transactions, indexing, and integration with various Hadoop ecosystem tools. By leveraging distributed computing, Apache Hive enables scalable, fault-tolerant data analysis that powers real-world use cases in retail, finance, healthcare, and more.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
How Hive Works in the Hadoop Ecosystem
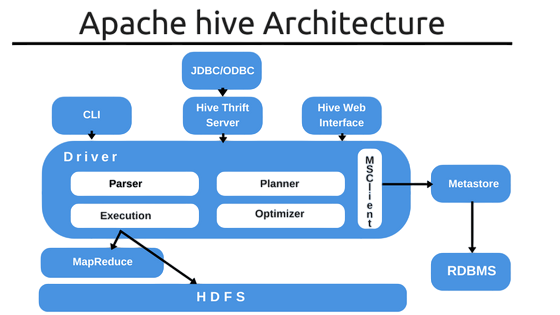
Hive fits seamlessly into the Hadoop ecosystem, functioning as a bridge between user queries and the distributed data infrastructure. Here’s how the typical Hive workflow operates:
- A user submits a HiveQL query using the Hive command-line interface (CLI), Beeline, or JDBC/ODBC client.
- Hive’s driver component parses the query and communicates with the compiler to generate an execution plan.
- The compiler converts the query into a Directed Acyclic Graph (DAG) of stages that are optimized and prepared for execution.
- Based on the execution engine configured—MapReduce, Tez, or Spark—Hive submits jobs to YARN (Yet Another Resource Negotiator), a key component in distributed processing frameworks often discussed alongside technologies like Apache search platforms, prompting questions such as What is Apache SolrCloud?
- Data is fetched from HDFS (Hadoop Distributed File System), processed, and the results are returned to the user.
- Metadata about tables, columns, and partitions is retrieved from the Hive Metastore, which is typically backed by a traditional RDBMS like MySQL or PostgreSQL.
A key component of its architecture is the Hive Metastore, which stores metadata about tables, schemas, partitions, and data types.This architecture allows Hive to scale horizontally across hundreds of nodes, providing reliable performance and flexibility for massive datasets. The Hive Metastore is typically backed by a relational database and plays a crucial role in query planning and optimization.

Key Features of Apache Hive
Apache Hive offers a wide range of features that make it an attractive solution for large-scale data warehousing in Hadoop environments:
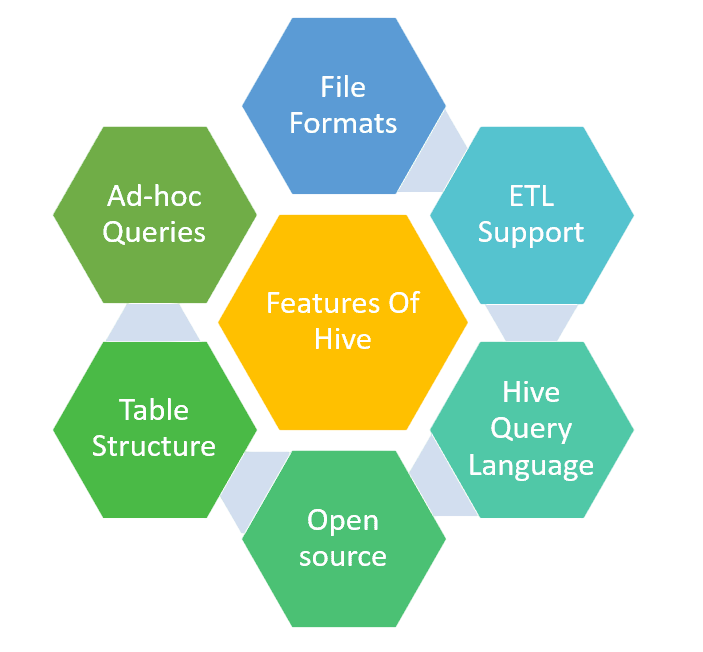
- SQL-Like Language (HiveQL): Enables users to perform queries using familiar SQL syntax, reducing the learning curve.
- Schema-on-Read:Data can be stored in raw form, and structure is applied at the time of querying, offering great flexibility.
- Support for Multiple Storage Formats: Works with text, CSV, JSON, ORC, Parquet, Avro, and more.
- Partitioning and Bucketing: Optimizes query performance by logically dividing large datasets into manageable pieces.
- Extensibility: Supports User-Defined Functions (UDFs), SerDes (Serialization/Deserialization), and custom scripts for advanced processing key concepts often covered in a comprehensive Data Science course.
- Integration with Execution Engines:Compatible with MapReduce, Apache Tez, and Apache Spark, offering flexibility in query execution strategies.
- ACID Transactions: Recent versions of Hive support INSERT, UPDATE, DELETE, and full transactional capabilities.
- Security and Role-Based Access Control: Supports integration with Kerberos, LDAP, and Apache Ranger for access control and auditing.
- Scalability and Fault Tolerance: Built on Hadoop, it naturally supports high-volume, fault-tolerant distributed processing.
These features make Hive not only powerful but also adaptable to a wide variety of analytical and business intelligence needs.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Hive Architecture and Components
Hive’s architecture is modular and designed to work effectively in a distributed Hadoop environment. At the top layer, the user interfaces CLI, Web UI, and Beeline allow users to interact with the system. These interfaces connect to the Hive driver, which receives and manages query sessions. The driver interacts with the compiler to parse HiveQL statements and generate execution plans.The plans are then optimized and handed off to the execution engine, which determines how to run the query using MapReduce, Tez, or Spark—a process similar to large-scale implementations seen in case studies like How PayPal Leverages Big Data Analytics The execution engine is responsible for breaking the query into stages and submitting jobs to the YARN resource manager. Another vital component is the Metastore, which stores metadata about tables, schemas, partitions, and data types. This metadata is crucial for interpreting the structure of datasets stored in HDFS and is usually housed in a relational database. Together, these components enable Hive to transform SQL-like commands into distributed data processing tasks that run across large-scale Hadoop clusters.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
HiveQL: The SQL of Hadoop
HiveQL is the declarative language used to query and manage data in Hive. Designed to closely mimic traditional SQL, it allows users to perform operations such as creating tables, inserting data, querying datasets, and managing partitions.Basic operations include SELECT, JOIN, GROUP BY, and ORDER BY, while advanced functionalities include subqueries, windowing functions, and Common Table Expressions (CTEs)—all essential skills outlined in the Learning Path to Become a Big Data Hadoop Architect HiveQL supports DDL (Data Definition Language) commands to define schema structures and DML (Data Manipulation Language) commands to modify data. It also offers support for custom User Defined Functions, enabling users to extend the language to suit their business logic. HiveQL’s simplicity allows analysts and business intelligence professionals to work with big data without needing to learn the low-level intricacies of Hadoop, making it a powerful tool for democratizing access to large datasets.
Use Cases and Real-World Applications
Apache Hive has found adoption across numerous industries due to its scalability, flexibility, and SQL-like interface. Some common use cases include:
- Retail Analytics: Companies analyze point-of-sale data and customer behavior to generate reports and optimize inventory.
- Telecommunications: Providers use Hive to process massive volumes of call records for usage analytics and fraud detection.
- Financial Services: Banks and insurance firms leverage Hive to process transaction data, detect anomalies, and generate regulatory reports. How PayPal Leverages Big Data Analytics to enhance fraud detection, optimize customer experience, and improve transaction processing demonstrates the power of advanced data technologies in the industry.
- Healthcare: Organizations use Hive to store and analyze patient records, treatment histories, and clinical trial results.
- Digital Media: Streaming platforms and publishers use Hive to analyze user engagement metrics and content consumption trends.
- Log Analysis:IT operations teams utilize Hive to process logs for system monitoring, debugging, and intrusion detection.
In each of these scenarios, Hive serves as a backbone for querying structured data in a scalable and performant manner.
Hive vs Traditional Databases
While Hive and traditional relational databases share similarities in syntax and data modeling, they are fundamentally different in architecture and use cases.
| Criteria | Apache Hive | Traditional RDBMS |
|---|---|---|
| Query Language | HiveQL (SQL-like) | SQL |
| Storage | Hadoop Distributed File System (HDFS) | Disk storage in dedicated DB engine |
| Latency | Higher (batch processing) | Low (real-time transactions) |
| Data Volume | Petabytes | Typically up to terabytes |
| Best Use Case | Analytical workloads, data warehousing | OLTP, real-time transactions |
| Execution Engine | MapReduce / Tez / Spark | Internal DB engine |
| Schema | Schema-on-read | Schema-on-write |
| Transaction Support | Limited (ACID in newer versions) | Full ACID compliance |
Hive is best suited for data warehousing and analytical processing over massive datasets, while RDBMSs are optimal for transaction-oriented tasks.
Conclusion: The Role of Hive in Big Data Analytics
Apache Hive continues to play a central role in modern data architectures by offering a familiar and scalable interface to interact with big data. Its ability to abstract the complexity of Hadoop while enabling SQL-like access to structured data has made it a cornerstone of data warehousing solutions in the big data era topic frequently explored in a Data Science course. As enterprises continue to move toward cloud-native and distributed data platforms, Hive remains relevant due to its strong community support, integration capabilities, and continuous evolution with features like ACID transactions, LLAP for low-latency querying, and compatibility with modern engines like Apache Spark. For organizations looking to extract structured insights from vast, unstructured datasets, Hive offers an effective, powerful, and accessible solution.




