
Last updated on 04th Oct 2025| 10284
- Introduction: The Need for Real-Time Data
- What is Apache Kafka?
- Origins and Evolution of Kafka
- How Kafka Works
- Core Components of Apache Kafka
- Kafka Use Cases in the Real World
- Kafka vs Traditional Messaging Systems
- Key Features of Apache Kafka
- Kafka Ecosystem and Tooling
- Conclusion: Why Kafka Matters in Modern Data Architecture
Introduction: The Need for Real-Time Data
In the digital age, data is no longer just something stored for analysis at the end of the day it flows continuously, generated by users, machines, applications, sensors, and systems every second. Organizations now operate in environments where the ability to collect, process, and react to data in real time defines competitiveness. Apache Kafka is a powerful platform designed for real-time data processing, enabling organizations to handle massive data streams efficiently. With its distributed architecture, Kafka supports real-time data processing at scale, ensuring fault tolerance and high throughput, making it an essential tool in any Data Science course This makes Kafka an essential tool for businesses looking to build robust real-time data processing pipelines and gain instant insights from their data. From fraud detection in banking to personalized recommendations in e-commerce, the requirement for fast, fault-tolerant, scalable, and efficient data pipelines is growing rapidly. This shift has led to the rise of real-time data plat forms systems capable of handling high-throughput data streams efficiently. Among them, Apache Kafka stands out as one of the most powerful and widely adopted distributed messaging systems, enabling companies to manage and process streaming data at scale.
What is Apache Kafka?
Apache Kafka is an open-source distributed event streaming platform designed for building real-time data pipelines and streaming applications. At its core, Kafka is a publish-subscribe messaging system that enables data producers to send messages to topics, and consumers to read those messages in near real time. Unlike traditional messaging queues, Kafka is built for horizontal scalability, fault tolerance, and high-throughput streaming.
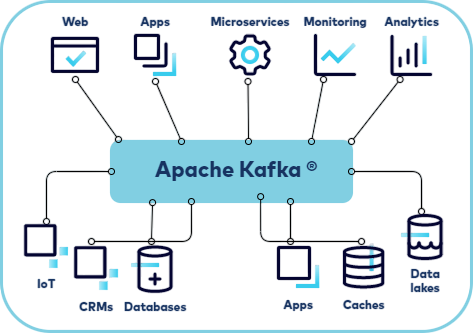
- It acts as a central nervous system for data, allowing multiple systems to communicate with each other asynchronously using a common message bus a great reason to ask,It acts as a central nervous system for data, allowing multiple systems to communicate with each other asynchronously using a common message bus a great reason to ask, Why Learn R Programming? for effective data handling.
- Apache Kafka is a leading platform for distributed event streaming, allowing organizations to process and analyze data across multiple systems seamlessly.
- Its architecture is built around distributed event streaming, which ensures scalability, fault tolerance, and high performance.
- Existing messaging systems such as RabbitMQ or ActiveMQ, while capable, didn’t scale easily for LinkedIn’s needs, particularly when it came to handling millions of events per second.
- This led to the creation of Kafka in 2011, designed to handle log aggregation, streaming data ingestion, and message distribution with a focus on speed and fault tolerance, complementing tools like the Guide to Apache Ambari for Hadoop Administration.
- A producer sends a record to a Kafka topic.
- Kafka stores this record in a partition associated with the topic.
- The record is persisted to disk and replicated across brokers for durability.
- A consumer reads the record from the partition, processes it, and maintains an offset to track its position in the stream.
- Consumers can be grouped into consumer groups, where each group reads a unique subset of partitions, allowing parallelism and fault tolerance.
- Topics: Named channels to which records are published. Each topic can have multiple partitions.
- Partitions: Each topic is split into partitions, which are logs of records ordered by time and ID. Partitions enable Kafka’s parallelism.
- Producers: Applications that write data to Kafka topics. They are asynchronous and can send records with keys to influence partitioning.
- Consumers: Applications that read data from topics. They can be part of a consumer group to distribute load. For more insights, check out Tips to Successfully R Integration with Hadoop
- Brokers: Kafka servers that manage data storage and handle client requests. A Kafka cluster is composed of multiple brokers.
- ZooKeeper: Used by Kafka for distributed coordination, leader election, and cluster metadata. (Note: Kafka is moving toward removing the need for ZooKeeper.)
- Consumer Groups : Allow multiple consumers to share the load of reading from a topic’s partitions.
- Data Retention: Kafka retains data for a configurable period (e.g., 7 days or forever), whereas traditional queues typically delete messages once consumed.
- Pull vs Push Model: Kafka consumers pull data at their own pace, enabling backpressure handling. Traditional brokers often push data, which can overwhelm consumers.
- Scalability: Kafka’s partitioned log model allows for seamless horizontal scaling across brokers. Many traditional systems struggle beyond a certain throughput.
- Performance: Kafka can handle millions of messages per second with low latency due to its optimized disk I/O and zero-copy mechanics.
- Message Ordering: Kafka guarantees message ordering within a partition, while traditional brokers may not.
- Replayability: Kafka allows consumers to replay old messages by resetting offsets useful for debugging or reprocessing data. Traditional queues don’t retain messages after acknowledgment.
- High Throughput: Kafka handles millions of messages per second, making it ideal for large-scale event processing.
- Durability: Messages are written to disk and replicated across brokers to ensure data persistence even in the event of failure.
- Fault Tolerance: Kafka can tolerate broker failures and recover seamlessly without data loss.
- Scalability: Kafka scales horizontally by adding more brokers and partitions to handle increasing loads, demonstrating principles discussed in Algorithms: The Essential Backbone Driving Data Analytics
- Real-Time Processing: With tools like Kafka Streams and ksqlDB, Kafka supports complex event processing directly within the pipeline.
- Flexible Integration: Kafka integrates easily with popular systems like Hadoop, Spark, Flink, Elasticsearch, MongoDB, and relational databases.
- Exactly-Once Semantics: Newer Kafka versions offer exactly-once processing guarantees for critical workflows.
- Security: Kafka supports SSL encryption, SASL authentication, and access control via ACLs.
- Stream Processing API: Kafka Streams allows you to build event-driven applications that process records directly from Kafka topics.
- Kafka Connect: A framework for integrating Kafka with external data sources such as databases, cloud storage, and monitoring tools. It comes with many ready-to-use connectors.
- Kafka Streams: A lightweight Java library for building applications that process and analyze data directly from Kafka topics in real time.
- ksqlDB: An interactive SQL-like engine for stream processing that allows you to write SQL queries on Kafka topics — but if you’re curious about search capabilities, you might also ask, ‘ What is Apache SolrCloud?
- Schema Registry: Often used with Avro-encoded messages, it stores and enforces data schemas to ensure compatibility between producers and consumers.
- Kafka Manager / Cruise Control / Confluent Control Center: Tools for monitoring, managing, and auto-scaling Kafka clusters.
By leveraging distributed event streaming, Kafka enables real-time data integration and processing, making it essential for modern data-driven applications. Originally developed by LinkedIn and later open-sourced as part of the Apache Software Foundation, Kafka has become the de facto standard for real-time event streaming in modern data infrastructures. Whether you’re logging events, ingesting data into a data lake, processing transactions, or monitoring sensors, Kafka provides a powerful foundation for integrating and orchestrating event-driven systems.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Origins and Evolution of Kafka
Kafka was born out of necessity at LinkedIn, where engineers struggled with the limitations of existing data integration tools. They needed a system that could handle real-time feeds from various applications and systems, process logs efficiently, and do so with high durability and scalability.
Since its inception, Kafka has evolved from a simple message broker to a full-fledged streaming platform that supports not only publishing and subscribing to data streams, but also storing, processing, and connecting them with external systems. Its widespread adoption by companies like Netflix, Uber, Airbnb, Spotify, and Goldman Sachs is a testament to its strength and versatility.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
How Kafka Works
At a high level, Kafka works as a distributed commit log. Producers send records (also called events or messages) to a Kafka topic, which acts as a logical channel for data. These records are distributed across partitions, allowing Kafka to scale horizontally. Consumers subscribe to one or more topics and pull messages at their own pace, enabling asynchronous processing without loss of data, which is a key concept covered in a Data Science course.
Here’s how a basic data flow in Kafka operates:
Kafka’s storage layer allows it to retain data for a configurable amount of time, which means consumers can rewind and re-read messages if needed something traditional message queues often can’t do.

Core Components of Apache Kafka
Apache Kafka consists of several key components that work together to provide its distributed streaming capabilities:
These components create a flexible and resilient architecture capable of handling diverse and demanding streaming workloads.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Kafka Use Cases in the Real World
Kafka’s versatility makes it suitable for a wide range of industry use cases. In finance, Kafka is used to process and analyze stock trades, detect fraud in real time, and feed transaction logs to downstream systems. E-commerce companies leverage Kafka to track user activity, deliver product recommendations, and maintain inventory levels across multiple systems. In the telecommunications sector, Kafka helps monitor call records, network health, and user behavior to improve service quality, making skills like those gained through Cloudera Certification for High-paying Big Data Jobs highly valuable. In healthcare, it enables the secure, real-time exchange of medical records and patient monitoring data. Social media platforms use Kafka to track interactions like likes, shares, and comments and deliver real-time analytics to users and advertisers. Furthermore, Kafka is commonly used for log aggregation, allowing companies to centralize application and system logs from various sources, and for event sourcing, where business events are stored and replayed to maintain system state or audit trails. These examples illustrate how Kafka serves as the backbone for real-time applications and services across diverse domains.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Kafka vs Traditional Messaging Systems
Kafka differs significantly from traditional message brokers in terms of performance, scalability, and design philosophy.
Here’s a comparative breakdown:
These differences have made Kafka the go-to solution for modern, distributed, high-throughput messaging systems, a topic often covered in Tricks to Crack Hadoop Developer Interviews The Kafka messaging system is a robust solution for handling large-scale data streams with high throughput and fault tolerance. As a Kafka messaging system, it enables seamless communication between distributed applications through efficient message publishing and consumption. The Kafka messaging system’s design supports real-time data processing, making it a cornerstone for modern event-driven architectures.
Key Features of Apache Kafka
Kafka’s design incorporates a host of features that make it robust and reliable for enterprise-scale systems:
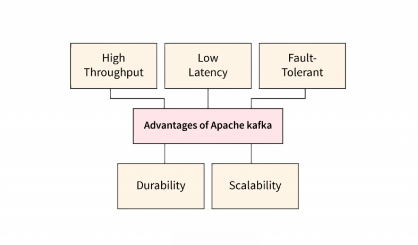
These features make Kafka suitable for building fault-tolerant, real-time, event-driven systems across industries.
Kafka Ecosystem and Tooling
Apache Kafka is more than a messaging system; it is a full-fledged ecosystem for stream data processing and integration.
Key tools in the Kafka ecosystem include:
This rich ecosystem extends Kafka’s capabilities beyond messaging, enabling the development of sophisticated, end-to-end streaming data platforms.
Conclusion: Why Kafka Matters in Modern Data Architecture
Apache Kafka has fundamentally transformed how organizations think about data movement and processing. By enabling the flow of data in real time across systems, departments, and geographies, Kafka has become the central nervous system of modern data architectures.Its ability to handle high-throughput data ingestion, maintain message durability, ensure fault tolerance, and support real-time processing makes it indispensable in today’s digital enterprises and an important topic in any Data Science course. Whether used as a data backbone in microservices, a pipeline for machine learning features, or the messaging layer for IoT applications, Kafka offers unmatched performance, flexibility, and reliability. As the demand for real-time insights continues to grow, Kafka’s role will only become more prominent in powering the future of event-driven and streaming systems.




