
Last updated on 06th Oct 2025| 10303
- The Big Data Challenge
- What is Apache Hadoop?
- The Two Pillars: HDFS and MapReduce
- Deep Dive into HDFS (Hadoop Distributed File System)
- Key Features of HDFS
- Introduction to MapReduce
- How MapReduce Works
- Benefits of Using HDFS and MapReduce Together
- Conclusion
The Big Data Challenge
In today’s digital world, data is being generated at an unprecedented rate from social media interactions and sensor outputs to business transactions and mobile apps. This explosion of data, often referred to as “Big Data,” presents a major challenge: how can we efficiently store, manage, and process such massive volumes of information? Traditional data systems struggle with scalability, speed, and cost Big Data Training. Organizations need robust frameworks that can handle distributed storage and parallel processing. This is where Apache Hadoop enters the picture, offering scalable solutions through its core components HDFS and MapReduce to meet the growing demands of Big Data.
What is Apache Hadoop?
Apache Hadoop is an open-source framework designed to store and process large-scale data across clusters of computers using simple programming models. Developed by the Apache Software Foundation, Hadoop enables distributed storage and parallel processing of big data, Big Data Career Path making it a powerful tool for handling massive datasets that traditional systems cannot efficiently manage.
Hadoop is built to scale from a single server to thousands of machines, each offering local storage and computation. Its architecture is fault-tolerant, meaning it can continue operating smoothly even if some nodes in the cluster fail. The framework is based on two core components: HDFS (Hadoop Distributed File System), which handles storage, and MapReduce, which manages data processing. Together, Big Data Analytics these components enable users to store and analyze large volumes of structured and unstructured data quickly and reliably. Hadoop has become a foundational technology in big data analytics, powering systems used in finance, healthcare, retail, and beyond.
Do You Want to Learn More About Big Data Analytics? Get Info From Our Big Data Course Training Today!
The Two Pillars: HDFS and MapReduce
- HDFS (Hadoop Distributed File System): A distributed storage system that breaks large data files into blocks and stores them across multiple machines in a cluster. It ensures fault tolerance through data replication.
- MapReduce: A programming model for parallel data processing. It divides tasks into two phases—Map (filtering and sorting) and Reduce (aggregating results)—to process large datasets efficiently.
- Complementary Roles: HDFS handles how and where data is stored, while MapReduce focuses on how data is processed, Career in Big Data Analytics enabling scalable and reliable big data operations.
- Built for Scalability and Fault Tolerance: Both components are designed to work seamlessly across hundreds or thousands of nodes, automatically handling failures and data recovery.
- Core to Apache Hadoop: Together, HDFS and MapReduce form the foundation of the Hadoop ecosystem, enabling organizations to harness the power of big data.
- NameNode: The master server that manages the filesystem namespace, keeps metadata about files and directories, and controls access to data.
- DataNode: Slave nodes that store the actual data blocks. They handle read and write requests from clients and regularly report back to the NameNode.
- Secondary NameNode: A helper node that periodically merges the NameNode’s edit logs with the filesystem Big Data Training image to prevent the edit logs from becoming too large. It’s not a backup NameNode.
- Checkpoint Node: Similar to the Secondary NameNode, it creates checkpoints by merging edit logs with the current filesystem state.
- JournalNode: Used in HDFS high-availability setups to maintain a shared edit log for active and standby NameNodes.
- Block: The basic unit of data storage in HDFS, typically 128 MB or 256 MB, replicated across DataNodes for fault tolerance.
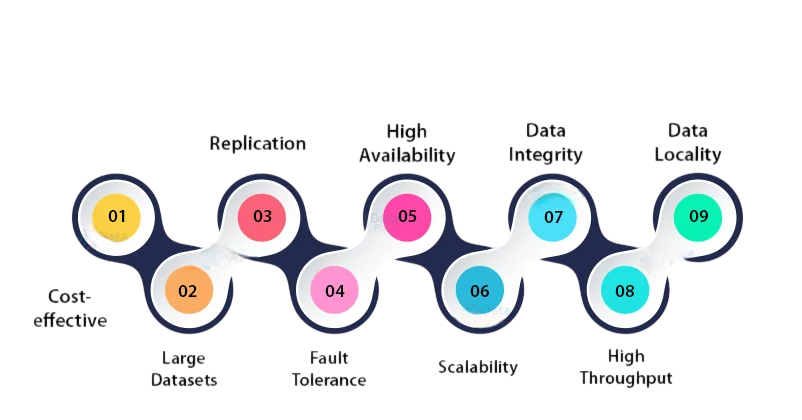
- Distributed Storage: Splits large files into blocks and stores them across multiple nodes in a cluster for scalability and fault tolerance.
- Fault Tolerance: Automatically replicates data blocks (default is 3 copies) across different nodes to prevent data loss in case of hardware failure.
- High Throughput: Optimized for large data sets, Become a Big Data Analyst enabling fast data access and high bandwidth for big data applications.
- Scalability: Easily scales from a few nodes to thousands of nodes without significant performance degradation.
- Write-Once, Read-Many Access Model: Files are typically written once and read multiple times, which simplifies data consistency and management.
- Data Locality: Moves computation closer to where the data resides to reduce network congestion and improve processing speed.
- Fault Detection and Recovery: Continuously monitors the health of DataNodes and automatically re-replicates data when failures are detected.
- Simple Architecture: Uses a master-slave architecture with a single NameNode managing metadata and multiple DataNodes storing actual data.
- Seamless Integration: HDFS provides reliable storage while MapReduce efficiently processes data stored across the cluster, creating a tightly integrated big data solution.
- Scalability: Both components scale horizontally, allowing organizations to handle growing data volumes by simply adding more nodes.
- Fault Tolerance: HDFS replicates data blocks, and MapReduce automatically reruns failed tasks, ensuring data durability and processing reliability.
- Data Locality Optimization: MapReduce schedules tasks on nodes where data blocks reside in HDFS, reducing network congestion Data Analytics Tools for Big Data Analysis and speeding up processing.
- Cost-Effective: Uses commodity hardware to store and process huge datasets, lowering infrastructure costs compared to traditional systems.
- High Throughput: Designed for batch processing of large datasets, enabling fast, parallel processing of vast amounts of data.
- Simplified Programming Model: Abstracts the complexity of distributed computing, making it easier for developers to write scalable data processing applications.
Would You Like to Know More About Big Data? Sign Up For Our Big Data Analytics Course Training Now!
Deep Dive into HDFS (Hadoop Distributed File System)
The Hadoop Distributed File System (HDFS) is the backbone of Apache Hadoop’s storage architecture. It is designed to store vast amounts of data across multiple machines in a distributed manner while ensuring reliability, scalability, and high throughput. HDFS works by breaking large files into fixed-size blocks (typically 128 MB or 256 MB) and BFSI Sector Big Data Insights distributing them across different nodes in the Hadoop cluster. Each block is replicated (by default, three times) to ensure data availability and fault tolerance. If a node fails, the system can automatically access a replica from another node, minimizing the risk of data loss. HDFS follows a master-slave architecture, where the NameNode manages metadata and file system namespace, while DataNodes handle the actual storage. This separation allows efficient data management and scalability across thousands of machines. HDFS is optimized for high-volume, write-once-read-many workloads, making it ideal for big data applications where data is collected and analyzed in bulk.
Components of HDFS:

Key Features of HDFS
Gain Your Master’s Certification in Big Data Analytics Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Introduction to MapReduce
MapReduce is a programming model and processing technique designed to handle large-scale data across distributed computing environments. Developed as part of the Apache Hadoop framework, it simplifies big data processing by breaking down complex tasks into two fundamental phases: Map and Reduce. During the Map phase, input data is divided into smaller chunks and processed in parallel to produce intermediate key-value pairs Essential Concepts of Big Data & Hadoop . In the Reduce phase, these intermediate results are aggregated, filtered, or combined to generate the final output. This approach enables efficient parallel processing across thousands of machines, making it ideal for tasks such as data analysis, indexing, and large-scale computation. By abstracting the complexity of distributed programming, MapReduce empowers developers to write scalable and fault-tolerant applications without worrying about the underlying infrastructure.
Preparing for Big Data Analytics Job? Have a Look at Our Blog on Big Data Analytics Interview Questions & Answer To Ace Your Interview!
How MapReduce Works
MapReduce processes large datasets by breaking the task into two main phases: Map and Reduce. First, the input data is split into smaller chunks, each handled independently by the Map function. During this phase, the data is processed and transformed into intermediate key-value pairs. Next, the framework performs a shuffle and sort step, which groups all values associated with the same key together Big Data is Transforming Retail Industry . Then, the Reduce function aggregates, summarizes, or filters these grouped data to produce the final results. This entire process runs in parallel across multiple nodes, ensuring efficient and scalable data processing. Additionally, MapReduce includes built-in fault tolerance, automatically rerunning failed tasks on other nodes to guarantee reliability.
Benefits of Using HDFS and MapReduce Together
Conclusion
Even with the rise of more modern processing frameworks like Apache Spark and cloud-native tools, HDFS and MapReduce remain foundational technologies in the world of Big Data. They represent the evolution from monolithic, single-node systems to scalable, distributed architectures capable of handling petabytes of data. HDFS solves the problem of data storage and distribution, while MapReduce handles parall Big Data Training. Together, Key Features of HDFS they formed the backbone of many Big Data systems that power some of the world’s largest applications today. For anyone starting out in data engineering or analytics, understanding these core technologies is crucial not only to grasp the historical evolution of Big Data but also to build a strong foundation for modern architectures.




