
Last updated on 07th Oct 2025| 10235
- Introduction to Big Data
- The Evolution of Apache Hadoop
- Core Components of the Hadoop Framework
- Hadoop Distributed File System (HDFS) Explained
- Understanding MapReduce: Hadoop’s Processing Engine
- Hadoop Ecosystem Tools: The Expanding Universe
- Real-World Applications of the Hadoop Ecosystem
- The Role of Hadoop in Modern Data Architecture
- Conclusion
Introduction to Big Data
We live in a world where data is constantly being generated from social media platforms, e-commerce websites, smart devices, sensors, enterprise applications, and more. This overwhelming surge of data, often referred to as Big Data, is characterized by the three Vs: volume, velocity, and variety. Traditional data storage and processing systems are no longer sufficient to handle such complex and large-scale data efficiently. That’s where Big Data technologies come into play and Apache Hadoop is one of the pioneers in this space Big Data Training . Developed to solve the challenges of handling massive datasets across distributed computing environments, Hadoop has become the foundation of many Big Data strategies across industries. Big Data refers to extremely large and complex datasets that traditional data processing tools cannot handle efficiently. With the rapid growth of digital technologies, data is being generated at an unprecedented rate from sources like social media, sensors, mobile devices, and online transactions.
The Evolution of Apache Hadoop
Apache Hadoop evolved from a 2005 project inspired by Google’s MapReduce and Google File System papers. It became an open-source framework designed to store and process vast amounts of data across distributed clusters. Over time, Hadoop expanded with a rich ecosystem, becoming a cornerstone of big data processing and analytics. Apache Hadoop began as an open-source project inspired by Google’s white paper on the Google File System and the MapReduce programming model. Created by Doug Cutting and Mike Cafarella in 2005, Essential Concepts of Big Data & Hadoop Hadoop was designed to enable distributed processing of large datasets across clusters of computers using simple programming models. Over the years, Hadoop has evolved from a basic storage and batch processing system to a complex ecosystem of data processing tools, analytics frameworks, Hadoop Distributed File System and data ingestion engines. Its scalability, fault tolerance, and ability to handle structured and unstructured data made it an industry standard for building data lakes and performing large-scale analytics.
Do You Want to Learn More About Big Data Analytics? Get Info From Our Big Data Course Training Today!
Core Components of the Hadoop Framework
At the heart of Hadoop are two primary components: HDFS and MapReduce. These form the core architecture of Hadoop, enabling it to store and process big data effectively.
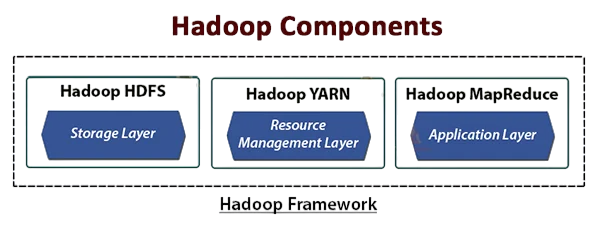
- HDFS (Hadoop Distributed File System): A distributed storage system that divides large files into blocks and distributes them across multiple nodes in a cluster.
- MapReduce: A parallel processing engine that allows computation to be carried out close to the data.
In addition to these, YARN (Yet Another Resource Negotiator) was introduced in Hadoop 2.0 to manage computing resources more effectively, Big Data is Transforming Retail Industry enabling better scalability and supporting newer data processing models like Apache Spark and Tez. Together, these components allow Hadoop to function as a reliable, scalable, and efficient Big Data platform.
Would You Like to Know More About Big Data? Sign Up For Our Big Data Analytics Course Training Now!
Hadoop Distributed File System (HDFS) Explained
- HDFS is the primary storage system of Hadoop, designed to store large datasets across multiple machines.
- It breaks files into blocks and distributes them across a cluster for fault tolerance and scalability.
- Each block is replicated on multiple nodes to ensure data reliability What is Data Pipelining.
- HDFS is optimized for high-throughput data access rather than low latency.
- It consists of a NameNode (master) that manages metadata and DataNodes (workers) that store actual data blocks.
- HDFS supports streaming data access, making it ideal for big data processing tasks.

Understanding MapReduce: Hadoop’s Processing Engine
- MapReduce is a programming model used to process large datasets in parallel across Hadoop clusters.
- It consists of two main phases: Map, which processes and filters data, and Reduce, which aggregates and summarizes results.
- The Map phase transforms input data into key-value pairs.
- Big Data Training The Reduce phase combines these pairs to produce the final output.
- MapReduce enables distributed processing, improving speed and efficiency for big data tasks.
- It automatically handles task scheduling, fault tolerance, and data distribution across nodes.
- Widely used for batch processing in the Hadoop ecosystem.
- A data warehouse infrastructure built on top of Hadoop for querying and analyzing data using SQL-like syntax (HiveQL).
- A high-level platform for creating Big Data Analytics MapReduce programs using a data flow scripting language called Pig Latin.
- A NoSQL database that runs on HDFS, allowing for real-time read/write access to large datasets.
- Used to import and export data between Hadoop and relational databases like MySQL, Oracle, and PostgreSQL.
- Designed for ingesting large volumes of log data from multiple sources into Hadoop Big Data Drives Small and Medium .
- A workflow scheduler that manages Hadoop job orchestration, making it easier to automate complex data pipelines.
- Retail: Analyze customer behavior, predict purchasing patterns, optimize supply chains.
- Healthcare: Manage electronic medical records, monitor patient vitals, and enable predictive diagnostics.
- Finance: Detect fraud, assess credit risk, and monitor stock market movements.
- Telecommunications: Monitor call data records, optimize networks, and reduce churn rates.
- Media: Personalize content recommendations and measure audience engagement.
- Cloud-native storage solutions like Amazon S3 and Google Cloud Storage.
- Real-time processing frameworks such as Apache Kafka, Flink, and Storm.
- Data lakehouse architectures combining the best of Big Data Analytics and data warehouses.
- On-premise data centers where cloud adoption is limited.
- Batch processing pipelines where real-time performance is not a priority.
- Long-term archival of massive historical datasets.
Gain Your Master’s Certification in Big Data Analytics Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Hadoop Ecosystem Tools: The Expanding Universe
Over time, the Hadoop ecosystem has expanded beyond HDFS and MapReduce to include a wide variety of tools for different data processing tasks. Here are some of the most prominent tools:
Apache Hive
Apache Pig
Apache HBase
Apache Sqoop
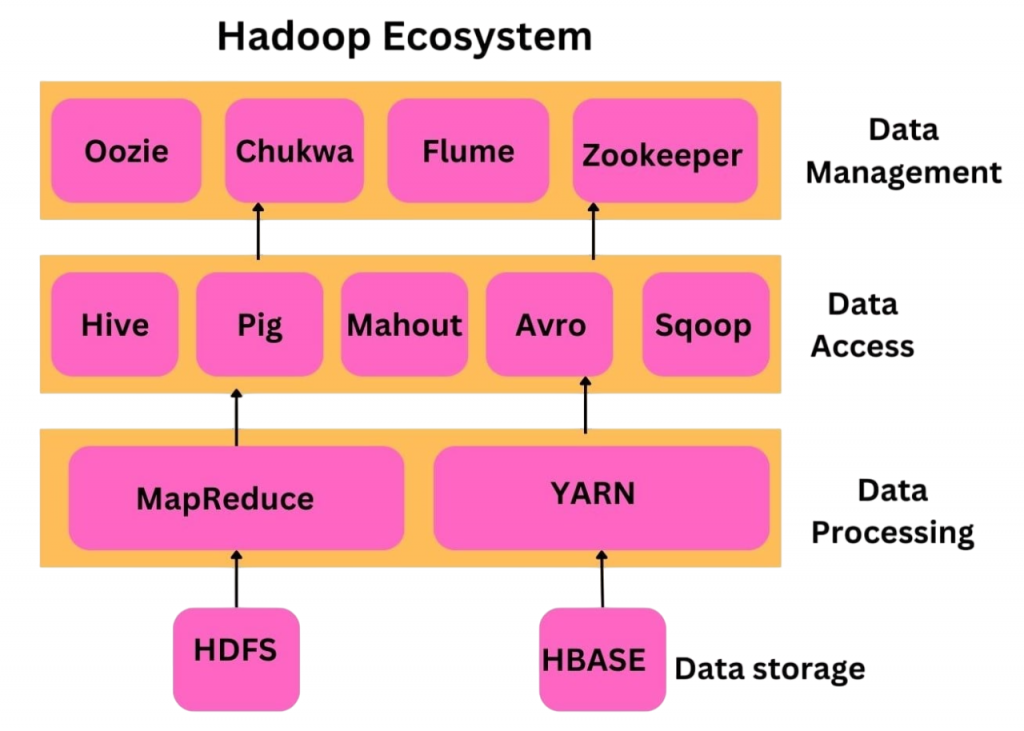
Apache Flume
Apache Oozie
Preparing for Big Data Analytics Job? Have a Look at Our Blog on Big Data Analytics Interview Questions & Answer To Ace Your Interview!
Real-World Applications of the Hadoop Ecosystem
The Hadoop ecosystem is not just a theoretical framework it powers many real-world applications that impact our daily lives.
Examples of Applications:
Organizations like Facebook, Netflix, LinkedIn, Amazon, and Twitter use Hadoop components at scale to process petabytes of data every day Big Data Career Path .
The Role of Hadoop in Modern Data Architecture
While Hadoop was once the centerpiece of Big Data infrastructure, modern architectures have evolved to integrate multiple technologies, including:
Despite this evolution, Hadoop still plays a critical role in:
Hadoop has also adapted to integrate with cloud platforms, enabling hybrid deployments that balance performance and cost.
Conclusion
The Big Data Hadoop universe is vast, complex, and evolving but it remains foundational to how we manage and analyze data at scale. From its core components (HDFS and MapReduce) to its extended ecosystem (Hive, Pig, Spark, Oozie), Hadoop offers a flexible and powerful suite of tools for organizations grappling with massive data challenges. While it’s no longer Big Data Training the sole player in the Big Data world, Hadoop’s design principles of distributed computing, fault tolerance, and scalability have become the blueprint for many modern technologies. Whether you’re a student, Hadoop Distributed File System, an IT professional, Hadoop Ecosystem Tools or a business leader, understanding the Big Data Hadoop universe is key to navigating today’s data-driven world.




