
Last updated on 07th Oct 2025| 10819
- Why Apache Spark?
- Applications of Spark in the Financial Sector
- Businesses in the e-commerce Sector Using Spark
- Use Cases for Spark in the E-Commerce Sector
- Use Case 1: Real-Time Data Processing
- Use Case 2: Machine Learning and Data Science Pipelines
- Use Case 3: ETL and Data Warehousing
- Use Case 4: Fraud Detection and Cybersecurity
- Conclusion: The Future of Spark in Modern Enterprises
Why Apache Spark?
Apache Spark has rapidly gained popularity as one of the most powerful engines for big data analytics. Known for its speed, scalability, and flexibility, Spark supports a wide array of applications including real-time stream processing, A Data Science course that covers large-scale machine learning, graph computations, and SQL-based analytics all within a single unified framework.” Its in-memory computing capabilities, combined with support for diverse programming languages like Python, Scala, Java, and R, make Spark a top choice among enterprises and data professionals. Companies operating in industries such as finance, healthcare, e-commerce, and telecommunications are increasingly adopting Spark to unlock insights from massive datasets, make real-time decisions, and build intelligent data-driven products. In this blog, we’ll explore four major real-world use cases of Apache Spark that demonstrate its practical significance and business impact.
Applications of Spark in the Financial Sector
In order to help them make the best business decisions for credit risk assessment, targeted advertising, and customer segmentation, banks are using Spark, a Hadoop alternative, to access and analyse social media profiles, call recordings, complaint logs, emails, forum discussions, etc. This could be credit card fraud of some sort. In order to prevent these types of scams, financial institutions are using big data technologies like Hadoop & Cloudera to determine when and where they are occurring
- They must identify frauds from the very first small inconsistency in order to settle any fraudulent charges as soon as possible.
- The majority of their models are used in batch environments, and they already have models to identify fraudulent transactions.
- Financial institutions can utilise Apache Spark on Hadoop to identify fraudulent transactions in real time by using fraud footprints from the past.
- E-commerce platforms use Spark to analyze user activity on their websites in real time. This helps personalize content, recommend products, and optimize ad placements on the fly.
- Financial institutions use Spark Streaming to monitor transactions for suspicious activity. If a potentially fraudulent pattern is detected, the system can immediately flag or block the transaction.
- Log analytics is another major application where Spark is used to process server logs in real time, enabling DevOps teams to detect anomalies, system failures, or unusual spikes in traffic as they happen.
- Spark provides built-in algorithms for classification, regression, clustering, and recommendation, and can be integrated with tools like Solr and Hadoop for enhanced data processing and search capabilities.
- It can handle feature engineering, pipeline construction, model tuning, and evaluation in a distributed manner.
- Its compatibility with frameworks like TensorFlow, XGBoost, and MLflow enables hybrid workflows. Real-World Applications:
- Healthcare providers use Spark to build models that predict disease risk based on electronic health records, lab results, and patient history.
- Ride-sharing companies leverage Spark MLlib to optimize route recommendations, dynamic pricing, and customer churn prediction.
- Retailers build recommendation engines using Spark to analyze customer behavior and suggest personalized products across multiple touchpoints.
- Spark can read data from various sources (CSV, JSON, Parquet, HDFS, S3, JDBC, etc.)
- It enables complex transformation logic using Spark SQL and DataFrames.
- Once transformed, the data can be written back to data lakes, data warehouses, or cloud storage. Real-World Applications:
- Telecom operators use Spark to aggregate call detail records (CDRs), clean the data, and store it in Hive or HDFS for downstream analytics.
- Media companies rely on Spark to collect and process user engagement data across channels and populate dashboards or OLAP cubes.
- Banking institutions use Spark-based ETL to ingest transactional data from multiple sources, unify them, and make them queryable via modern BI tools.
- Spark ingests real-time data from network traffic, user activity logs, transaction records, and threat feeds.
- It uses anomaly detection algorithms, clustering techniques, and rule-based filters to flag suspicious behavior.
- Spark can combine historical and real-time data to enhance the accuracy of fraud models, a valuable skillset for those pursuing Big Data Careers . Real-World Applications:
- Banks and credit card companies use Spark to detect fraudulent transactions by analyzing deviations from typical user behavior.
- Cloud service providers monitor Spark pipelines for intrusion detection by correlating user access patterns with security rules.
- Online gaming and betting platforms analyze betting behavior using Spark to identify abuse or manipulation.
Every incoming transaction is checked against a database; if it matches, the call centre receives a trigger. Before any fraud can occur, the call centre staff promptly verifies the transaction with the credit card owner.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Businesses in the e-commerce Sector Using Spark
In order to find qualified retailers with whom it could collaborate, Shopify sought to examine the kind of goods its clients were selling. This issue was not resolved by its data warehousing technology, which repeatedly timed out when executing data mining queries on millions of documents.Using Apache Spark as part of their Big Data Analytics strategy, Shopify processed 67 million records in a matter of minutes and successfully produced a list of stores for collaboration.
Personalised Suggestions:Spark improves customer engagement by offering highly customised product recommendations based on an analysis of the user’s browsing and purchasing history.
Better Customer Experience:By analysing customer interactions and transactions, Spark’s machine learning capabilities and quick data processing speed improve the user experience as a whole.
Analytics & Data Mining:Spark facilitates intricate, extensive data mining processes on big datasets gathered from e-commerce websites, allowing companies to glean insightful information and arrive at well-informed judgements.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Use Cases for Spark in the E-Commerce Sector
Algorithms for streaming clustering, such as K-means clustering or alternating least squares (collaborative filtering), can be fed data regarding real-time transactions.To improve customer suggestions based on emerging trends, the findings can be integrated with information from other sources such as social media profiles, forum product evaluations, customer comments, etc. as outlined in A Comprehensive Guide to Hadoop.
Supply Chain Optimisation:By analysing massive datasets to avoid stock shortages or overstocking, Spark assists in forecasting demand, optimising inventory levels, and improving supply chain management.
Targeted Marketing:Using Spark to analyse consumer data enables the development of extremely effective and focused marketing efforts, which raise conversion rates.

Use Case 1: Real-Time Data Processing
In today’s fast-paced world, the value of data decreases rapidly with time. Enterprises no longer have the luxury to analyze data hours or days after it’s been generated. This is where Apache Spark excels with its support for stream processing through Spark Streaming and Structured Streaming, it allows organizations to process and analyze data in real time. This article explores four key Apache Spark use cases: real-time data processing, machine learning pipelines, ETL and data warehousing, and fraud detection. In a Data Science course, Spark’s MLlib library is used to power large-scale machine learning pipelines, enabling predictive analytics in healthcare, finance, and retail.
How It Works:Spark ingests data from live sources such as Apache Kafka, Flume, or socket streams, performs transformation and analytics in memory, and pushes the output to dashboards, storage, or downstream applications.
Spark’s ability to handle high-throughput, low-latency data makes it ideal for building real-time decision systems, ensuring organizations remain agile and responsive.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Use Case 2: Machine Learning and Data Science Pipelines
One of Spark’s most powerful features is its integrated MLlib library, which supports scalable and distributed machine learning. This makes it possible to train large machine learning models on datasets that would otherwise be too large for traditional ML tools.
Why Spark for ML?Spark allows organizations to build complete end-to-end machine learning workflows from data preprocessing to model deployment all at scale.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Use Case 3: ETL and Data Warehousing
Traditionally, Extract, Transform, Load (ETL) processes were performed using batch-based systems that struggled with the growing volume and variety of data. Spark has redefined ETL by allowing data engineers to process massive datasets in parallel, improving speed and flexibility.This article highlights four major Apache Spark use cases: real-time data processing, machine learning pipelines, ETL process, and fraud detection. Spark also revolutionizes the ETL process, allowing for faster, parallel data extraction, transformation, and loading playing a key role in Accelerating Big Data workflows and insights.
How Spark Enhances ETL:By enabling high-performance ETL pipelines, Spark helps organizations maintain clean, current, and queryable data across their enterprise systems.
Use Case 4: Fraud Detection and Cybersecurity
Cyber threats and financial fraud are evolving rapidly, demanding intelligent systems that can analyze patterns, detect anomalies, and react in near real time. Apache Spark is being increasingly adopted in fraud detection and cybersecurity thanks to its ability to handle large volumes of data with low latency.
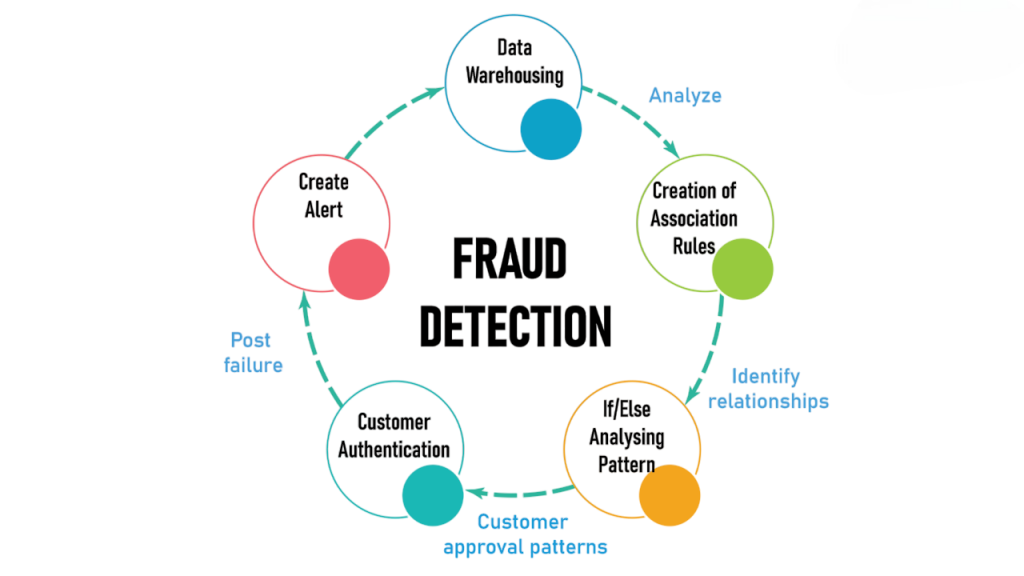
By enabling both batch and streaming analytics, Spark acts as a powerful shield against threats in today’s data-driven environments.
Conclusion: The Future of Spark in Modern Enterprises
Apache Spark is more than just a fast processing engine it’s a versatile platform that supports a broad range of use cases critical to modern enterprises. In a Data Science course, students explore how Spark powers some of the most innovative and mission-critical data applications around the globe from real-time streaming and ETL pipelines to machine learning and fraud detection. Its continuous evolution supporting GPU acceleration, Python-based APIs, and integration with cloud-native services ensures that it remains at the forefront of Big Data analytics. For data engineers, data scientists, and enterprise architects, learning Spark is no longer optional it’s essential for staying competitive in a data-first world.




