
Last updated on 09th Oct 2025| 10878
- Hadoop Architecture
- Use Cases for Single Node Setup
- System Requirements
- Setting Up NameNode and DataNode
- Formatting HDFS
- Starting Hadoop Services
- Testing the Setup with Sample Data
- Troubleshooting Common Issues
- Best Practices and Next Steps
- Conclusion
Hadoop Architecture
Apache Hadoop is a powerful, open-source framework designed to store and process large-scale datasets using distributed computing. It is built to scale from a single server to thousands of machines, each offering local computation and storage making it an essential foundation in any comprehensive Data Science course. The core components of Hadoop include:
- HDFS (Hadoop Distributed File System) – Ensures reliable, scalable, and fault-tolerant storage. Even when setting up a Hadoop environment with just one node, proper HDFS configuration is an essential step. A well-organized HDFS configuration enhances data integrity, scalability, and dependability. In order to prevent frequent setup problems and guarantee the seamless functioning of Hadoop services, beginners need to pay special attention to HDFS configuration.
- MapReduce – A computational model and software framework for writing applications that process large amounts of data. A MapReduce Job is a core component of the Hadoop ecosystem, used to process large datasets in parallel across distributed systems. In a single-node setup, running a MapReduce Job helps users understand how input data is transformed and output is generated. Successfully executing a MapReduce Job validates that the Hadoop installation, including HDFS and YARN, is functioning correctly—an important step in mastering Big Data Analytics.
- YARN (Yet Another Resource Negotiator) – Manages cluster resources and job scheduling.
In a single-node setup, all these components run on one machine. This mode is especially beneficial for learners and developers to practice and explore Hadoop features without a complex cluster setup.
Use Cases for Single Node Setup
All three of Hadoop’s essential components MapReduce, YARN, and HDFS run on a single system in a single node hadoop. Users can get practical experience with big data tools and workflows by configuring Single Node Hadoop, which also lays the groundwork for understanding concepts like Stream Processing in Big Data . A Single Node Hadoop system is perfect for prototyping and teaching, as it helps close the gap between theory and practical data processing.A single-node Hadoop setup is ideal for:
- Learning and Training – Get hands-on experience with Hadoop components.
- Testing and Debugging – Validate configurations and debug issues locally.
- Prototyping –Develop and validate data processing jobs before deploying to production.
- Educational Demonstrations –Showcase how Hadoop works in classrooms or workshops.
- Operating System: Ubuntu 20.04 LTS or similar Linux distribution.
- Memory: Minimum 4 GB RAM (8 GB recommended).
- Disk Space: Minimum 10 GB of free storage.
- Java Version: Java 8 or newer.
- SSH: Must be installed and configured for local communication.
- sudo mkdir -p /usr/local/hadoop_tmp/hdfs/namenode
- sudo mkdir -p /usr/local/hadoop_tmp/hdfs/datanode
- sudo chown -R $USER:$USER /usr/local/hadoop_tmp SSH Configuration
- sudo apt install openssh-server -y
- ssh-keygen -t rsa -P “”
- cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- chmod 0600 ~/.ssh/authorized_keys
- chmod 0600 ~/.ssh/authorized_keys
- ssh localhost
- Start HDFS and YARN:
- start-dfs.sh
- start-yarn.sh
- Verify running processes:
- jps
- NameNode
- DataNode
- ResourceManager
- NodeManager
- SecondaryNameNode
- hdfs dfs -mkdir /user
- hdfs dfs -mkdir /user/hadoop
- hdfs dfs -put ~/sample.txt /user/hadoop
- hdfs dfs -ls /user/hadoop
- hadoop jar
- $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /user/hadoop /user/hadoop_output
- hdfs dfs -cat /user/hadoop_output/part-r-00000
- JAVA_HOME Not Set: Confirm it’s set in hadoop-env.sh.
- SSH Connection Refused: Ensure ssh is installed and sshd is running.
- Ports Blocked: Free up ports 9000, 50070, and 8088.
- Insufficient Permissions: Verify Hadoop has access to required directories.
- Regularly update your Hadoop installation.
- Keep logs under check; clean older logs.
- Back up configurations before major changes.
- Explore Hive, Pig, and Spark on the same single-node setup.
- Consider pseudo-distributed or real cluster deployment.
Though limited in scale, this setup effectively introduces users to the Hadoop ecosystem.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
System Requirements
Many developers start by learning how to set up a Setup Hadoop cluster in a single-node environment in order to process massive datasets efficiently. An vital tool for learning, testing, and prototyping is a Setup Hadoop Cluster tutorial. Given how much Hadoop depends on Java to function, choosing the right Java version is crucial to a successful Hadoop installation a topic often emphasized in many Trending Analytics Courses. Users must make sure the necessary Java version is installed and set up correctly in environment variables before beginning the setup. Incompatible Java versions might cause issues when Hadoop services like MapReduce and HDFS are being executed. Anyone may setup Hadoop cluster locally and learn useful big data skills by following the correct steps.Ensure your system meets the following prerequisites:
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Setting Up NameNode and DataNode Directories
Create the necessary directories:
Install and configure SSH for Hadoop to run its daemons:

Formatting HDFS
Before starting Hadoop, format the NameNode:
hdfs namenode -format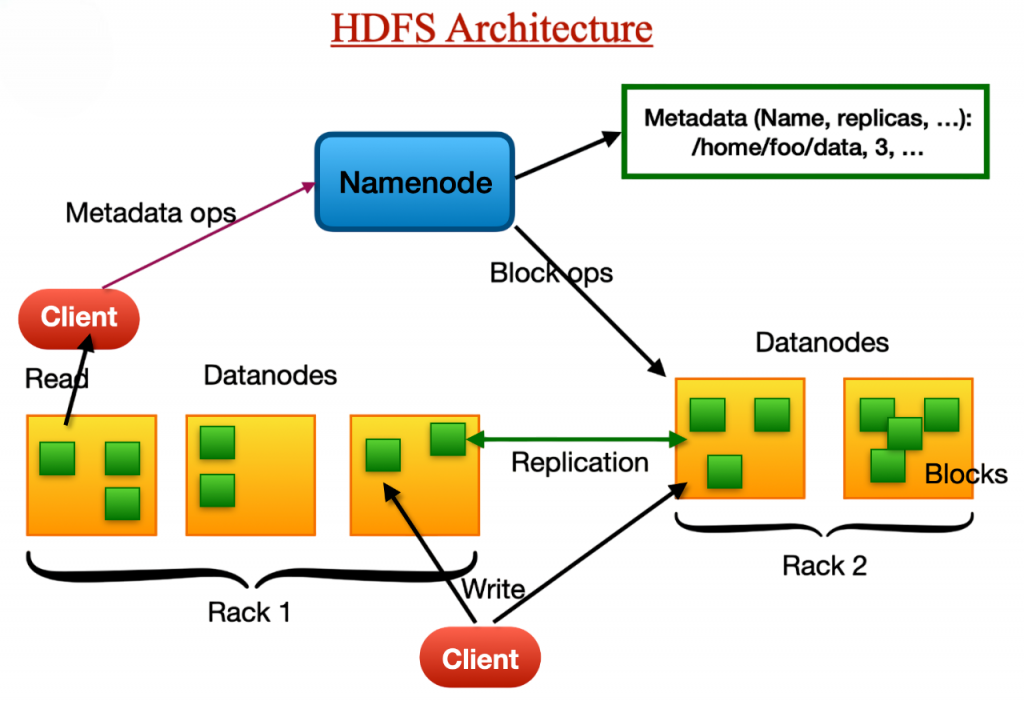
The hdfs namenode -format command must be used to format the NameNode prior to starting Hadoop services. By doing this, the file system is ready for use and the HDFS metadata is initialised. A confirmation message confirming that the storage directory has been correctly initialised should appear after formatting is complete.After formatting, run start-dfs.sh for HDFS and start-yarn.sh for YARN to launch the Hadoop daemons an essential hands-on step often included in a practical Data Science course. Use the jps command to confirm that all required services are operating. NameNode, DataNode, ResourceManager, NodeManager, and SecondaryNameNode are among the important Hadoop processes that should be listed in the expected output, indicating that your single-node Hadoop setup is operational and operating as intended.
Expected output: INFO common.Storage: Storage directory … has been successfully formatted.
Starting Hadoop ServicesExpected:
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Testing the Hadoop Setup
Create and interact with HDFS:
Output should show sample.txt in the HDFS path.Output should show sample.txt in the HDFS path, confirming that the system is correctly set up for Accelerating Big Data workflows and testing.
Run a sample MapReduce job:
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Troubleshooting Common Issues
Users frequently encounter a few reoccurring problems during Hadoop Single Node Setup, which might cause the configuration process to be disrupted issues commonly addressed in any comprehensive Guide To Big Data. Making sure the correct Java version is referenced will fix the JAVA_HOME not set error, which is one of the most frequent and usually arises when the Java path is not properly stated in the hadoop-env.sh file. Refused SSH connections are another common issue that can hinder Hadoop’s ability to properly launch its daemons. Another problem is blocked ports, especially if other programmes are using ports like 8088 (YARN ResourceManager UI), 50070 (HDFS web UI), or 9000 (NameNode); these ports must be released for regular operation.
Best Practices and Next Steps
Conclusion
Setting up a Hadoop single-node cluster is an essential first step in mastering Big Data technologies. It allows learners to understand the foundational workings of HDFS and MapReduce. As users grow familiar with the ecosystem, this environment serves as a stepping stone to more advanced, production-grade multi-node clusters that drive today’s data-driven enterprises skills often introduced in a comprehensive Data Science course. By practicing regularly and experimenting with different tools, one can gain the practical experience necessary to build a successful career in Big Data.




