
Last updated on 09th Oct 2025| 10350
- Getting Started with Hadoop
- Why Data Confidence Matters
- Hadoop as a Big Data Solution
- Understanding HDFS and Data Storage
- Hadoop MapReduce for Processing Data
- Hadoop Security and Best Practices
- Real-World Big Data Applications
- Hands-On Assignments
- Career Benefits of Hadoop Training
- Summary
Getting Started with Hadoop
In today’s data-driven landscape, professionals and organizations are expected to make decisions based on large and complex datasets. However, with data pouring in from diverse sources, managing, storing, and processing this data becomes a monumental task. This is where Hadoop, a powerful, open-source big data framework, steps in often forming a core part of any comprehensive Data Science course. Hadoop training not only equips learners with the skills to handle big data but also builds their confidence in managing data for strategic decisions. Whether you are a beginner looking to understand big data or a professional aiming to transition into data-centric roles, Hadoop training lays a solid foundation. The Hadoop training course equips students with the knowledge and abilities necessary to use Hadoop’s robust environment to manage, process, and analyse big datasets.
Why Data Confidence Matters
“Data confidence” refers to the ability to trust, interpret, and act upon data. This confidence is essential for data scientists, analysts, and business leaders to make informed decisions. Without the necessary tools or understanding, individuals may misinterpret data or hesitate to act on insights leading to lost opportunities or flawed strategies.

Hadoop training helps bridge this gap by teaching how to access, store, clean, process, and analyze large datasets many of which are common topics in Hadoop FAQs . Gaining expertise in Hadoop tools ensures not just technical skills but also the confidence to work with data effectively and responsibly. Pursuing a big data certification equips professionals with the knowledge and practical skills needed to handle vast and complex datasets using tools like Hadoop. A big data certification validates your expertise and gives you a competitive edge in today’s data-centric job market, making it a smart investment for anyone looking to advance their career. Whether you’re upskilling or switching domains, a big data certification is a powerful step forward.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Hadoop as a Big Data Solution
Hadoop was developed by Doug Cutting and Mike Cafarella in 2005 to address the growing need for scalable data processing. Inspired by Google’s MapReduce and Google File System, Hadoop evolved into a robust ecosystem capable of storing and analyzing large volumes of structured and unstructured data.
Key reasons why Hadoop is ideal for big data and frequently included in a Data Science course include:
- Scalability: Hadoop can handle petabytes of data by distributing storage and processing across many computers.
- Cost-efficiency: Uses commodity hardware, reducing infrastructure costs.
- Fault-tolerance: Automatically recovers data in case of node failures.
- Flexibility: Works with all types of data text, images, videos, logs, etc.
Hadoop’s architecture is designed to support both batch processing and, with integrations, real-time analytics, making it a comprehensive big data solution.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Understanding HDFS and Data Storage
At the heart of Hadoop lies the Hadoop Distributed File System (HDFS). It is the foundation for data storage in the Hadoop ecosystem. HDFS breaks down large files into blocks (usually 128MB or 256MB) and distributes them across multiple nodes in a cluster.
Key features of HDFS:
- Replication: Each block is replicated (default is 3 times) to prevent data loss.
- Data locality: Processing tasks are sent to nodes where data resides, minimizing network latency.
- High throughput: Optimized for high-bandwidth data access rather than low latency.
- Map Phase: Transforms input data into key-value pairs.
- Reduce Phase: Aggregates intermediate key-value pairs to produce final results.
- Authentication using Kerberos.
- Authorization with Apache Ranger or Sentry.
- Data Encryption at rest and in transit.
- Auditing user activity to ensure compliance.
- Retail: Analyzing customer behavior, tracking inventory, and personalizing recommendations.
- Healthcare: Managing electronic health records, genomic research, and predicting disease outbreaks.
- Finance: Fraud detection, risk modeling, and regulatory compliance.
- Social Media: Sentiment analysis, trend forecasting, and data mining.
- High Demand: Big data professionals are in demand across banking, healthcare, e-commerce, and more.
- Lucrative Salaries: Hadoop Developers, Data Engineers, and Big Data Architects command high salaries.
- Job Roles: Hadoop Developer, Data Engineer, Hadoop Admin, Business Intelligence Analyst.
- Certification: Training often prepares learners for industry-recognized certifications like Cloudera Certified Associate (CCA) and Hortonworks HDP.
Through training, learners will gain hands-on experience in configuring HDFS, managing nodes, and ensuring data integrity using Hadoop commands and configuration files skills often highlighted in any comprehensive Guide To Big Data . Anyone hoping to deal with large-scale data systems has to build strong Hadoop development abilities. A thorough Hadoop training programme helps students develop the fundamental Hadoop developer skills needed in today’s data-driven companies by giving them practical exposure with HDFS, MapReduce, Hive, and other technologies. Gaining proficiency in Hadoop developer skills can set you up for success in highly sought-after technical fields, regardless of whether you’re moving into big data or improving your present position.

Hadoop MapReduce for Processing Data
MapReduce is Hadoop’s core programming model for processing large data sets in parallel. A key element of the Hadoop ecosystem, MapReduce programming makes it possible to process large datasets across distributed systems in an effective manner. Through Hadoop training, students are exposed to MapReduce programming in a hands-on way, learning how to deconstruct complicated data chores into smaller, more manageable map and reduce processes similar to what is covered in an Introduction to Java MapReduce. Anyone hoping to establish a solid foundation in big data processing and pursue careers in analytics or data engineering must become proficient in MapReduce programming. It simplifies the data processing logic by dividing it into two stages:
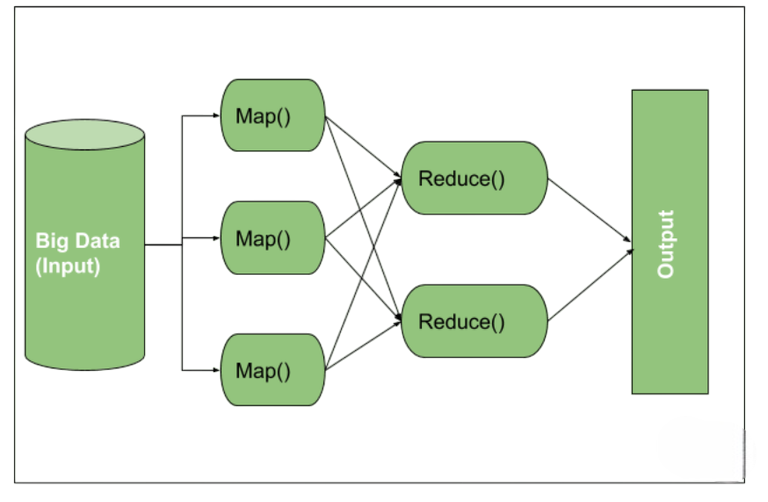
For example, if you wanted to count the frequency of words in a massive document, MapReduce would split the task across multiple nodes, process the data in chunks, and aggregate the word counts efficiently.Though MapReduce has now been supplemented by tools like Spark, understanding it is vital to mastering the Hadoop ecosystem. Hadoop training typically includes writing and deploying MapReduce jobs using Java and other supported languages.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Hadoop Security and Best Practices
As data grows, so does the need for secure data handling. Hadoop training includes crucial modules on security best practices such as:
Security is not just a backend concern it is a key aspect of data governance and a critical topic in Understanding Big Data. Understanding how to secure a Hadoop environment ensures that your data remains protected and trustworthy.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Real-World Big Data Applications
Hadoop is used across industries to solve real-world problems:
During training, learners explore these use cases through hands-on labs and projects, similar to those found in many Trending Analytics Courses. For example, building a clickstream analysis pipeline or customer churn prediction model using Hadoop and associated tools.
Career Benefits of Hadoop Training
Investing in Hadoop training can lead to significant career advancements. Here’s how:
Hadoop knowledge is not just a skill it’s a career enabler. For professionals wishing to move into big data jobs, The Hadoop training course is perfect since it blends theory with practical projects to develop both technical proficiency and data confidence skills essential for thriving in the Future of Big Data. Regardless of your level of experience, this Hadoop training course gives you the skills you need to succeed in the data-driven world of today. Even professionals from testing, ETL, or traditional BI backgrounds can transition into big data with the right training.
Summary
Hadoop continues to be a foundational technology in the big data landscape. From managing large-scale data through HDFS, to processing it with MapReduce, to analyzing it using Hive and Pig Hadoop offers an end-to-end framework for data practitioners. Training in Hadoop, often a key component of a Data Science course, empowers individuals to confidently engage with data, solve business problems, and explore high-paying career opportunities in data engineering and analytics. With virtual and self-paced training options, learning Hadoop has never been more accessible. Whether you’re aiming to boost your resume, transition to a new domain, or enhance your understanding of big data this training is your gateway to becoming truly data-confident.




