
Last updated on 13th Oct 2025| 10378
- Introduction to Hadoop MapReduce
- What Is MapReduce?
- Core Concepts of MapReduce
- Hadoop MapReduce Architecture
- How Hadoop MapReduce Works: Step-by-Step
- Key Advantages of Using MapReduce
- Common Use Cases for Hadoop MapReduce
- Challenges and Limitations of MapReduce
- Future of MapReduce in the Big Data Ecosystem
Introduction to Hadoop MapReduce
The world of big data has created a need for powerful frameworks capable of processing vast amounts of data in a distributed fashion. Apache Hadoop is one such framework that has revolutionized the way organizations handle large datasets. A key component of Hadoop is MapReduce, a programming model and processing engine that enables parallel processing of Data Science Training massive data sets across clusters of computers. MapReduce is a core component of the Hadoop ecosystem and is essential for efficiently processing big data in a scalable manner. As organizations strive to turn data into valuable insights, MapReduce has become a popular choice for those needing to process, analyze, and mine large data sets. In this blog, we’ll explore the key concepts behind Hadoop MapReduce, how it works, and examine several use cases that highlight its power in tackling real-world data challenges.
What Is MapReduce?
At its core, MapReduce is a programming model and processing technique that divides large tasks into smaller sub-tasks, processes them in parallel, and then aggregates the results. It was originally developed by Google to handle large-scale data processing across multiple machines. In the context of Hadoop, MapReduce is the engine that allows data to be processed in parallel across multiple nodes in An ETL Audit Process a Hadoop cluster, making it ideal for handling huge datasets that traditional systems cannot process efficiently.
The model is split into two primary phases:
- Map phase: During this phase, input data is broken into smaller, manageable pieces, and each piece is processed in parallel by the map function. This stage is responsible for filtering and sorting the data.
- Reduce phase: After the map phase has processed the data, the output is shuffled and sorted, and the reduce function is applied to aggregate or summarize the results. This phase combines the data into a final, unified output.
MapReduce’s inherent parallelism and distributed nature make it highly scalable, allowing it to process data sets that are terabytes or even petabytes in size BFSI Reasons for Moving Into Big Data Career .
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Core Concepts of MapReduce
To understand how Hadoop MapReduce works, it’s crucial to familiarize oneself with several key concepts that underpin the model:
- Input Data: In a MapReduce job, data is typically stored in the Hadoop Distributed File System (HDFS). This data can be in various formats BFSI Sector Big Data Insights like text, CSV, JSON, or even complex formats like Parquet. The data is split into smaller chunks, called splits, which are processed independently across different nodes in the cluster.
- Map Function: The Map function processes the input data in parallel. It takes a set of data, applies a specific operation or transformation, Big Data Ecosystem and outputs a collection of key-value pairs. The key-value pairs produced by the Map function are then sorted and shuffled for the next phase. For example, in word count problems, the map function might take a text file and break it down into individual words, emitting each word paired with the value “1” (indicating its occurrence).
- Shuffle and Sort: After the map phase, a process called shuffle and sort occurs. This phase redistributes the data across nodes so that all occurrences of the same key are grouped together. Data Science Training Essentially, all key-value pairs with the same key are sorted and sent to the appropriate reducer.
- Reduce Function: The Reduce function takes the grouped key-value pairs and performs some operation on them, such as summing the values or finding the average. The result is then written to an output file. The reduce function handles the final aggregation and processing of the data. In the word count example, the reduce function would receive each word and a list of all occurrences (e.g., “apple, apple, orange”). The function would then count how many times each word appears.
- Output Data: The final output of a MapReduce job is written back to the HDFS, where it can be used by other processes or applications for further analysis or visualization.
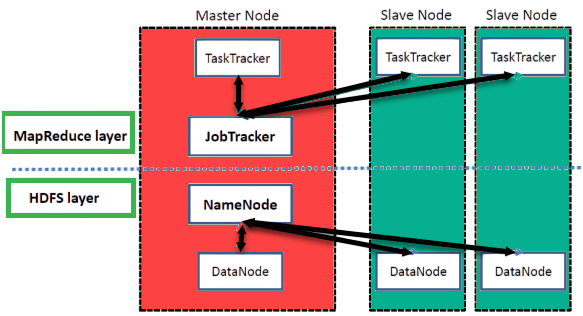
- JobTracker: The JobTracker is the master daemon responsible for managing MapReduce jobs in Hadoop. It coordinates the execution of jobs by dividing them into tasks, scheduling them across worker nodes (task trackers), Kafka vs RabbitMQ and monitoring their progress. It also handles job failure recovery by rescheduling tasks on different nodes if necessary.
- TaskTracker: The TaskTracker is a slave daemon that runs on each node in the cluster. Each TaskTracker executes a set of tasks (map and reduce tasks) as directed by the JobTracker. It also reports the status of the tasks back to the JobTracker, ensuring efficient task execution.
- HDFS: The Hadoop Distributed File System (HDFS) is the underlying storage system for Hadoop. Data is split into blocks and distributed across the cluster for fault tolerance and parallel access. HDFS provides high throughput and scalability, making it well-suited for storing large datasets.
- MapReduce Framework: The MapReduce Framework in Hadoop is responsible for the execution of Map and Reduce tasks. It includes the logic for splitting the input data, assigning tasks to TaskTrackers, performing the shuffle and sort process, and aggregating the results into the final output.
- YARN (Yet Another Resource Negotiator): In more recent versions of Hadoop, YARN (introduced in Hadoop 2.0) manages resource allocation for MapReduce jobs. YARN allows multiple applications Dedup : Splunk Documentation to run concurrently on the Hadoop cluster and improves cluster resource utilization.
- The input data is stored in HDFS, where it is divided into blocks (typically 128MB each) and distributed across the cluster.
- The input data is processed by the Map function, which emits key-value pairs as intermediate output. Each mapper Data Science Training processes a chunk of data independently and outputs key-value pairs to the local disk.
- Once all mappers have finished processing, the output data is shuffled and sorted. This ensures that all values associated with the same key are grouped together before they are passed to the reduce function.
- The Reduce function takes the sorted output from the shuffle phase and aggregates the data. The reducer might sum values, calculate averages, or apply other aggregation functions, depending on the specific problem being solved.
- The final result is written back to HDFS, making it available for further processing or analysis.
- High Latency for Small Tasks – MapReduce is optimized for large-scale data, making it inefficient for smaller datasets.
- Complex Programming Model – Writing MapReduce jobs requires understanding of Java or other frameworks, which can be challenging for beginners.
- Limited Real-Time Processing – It is primarily designed for batch processing and struggles with real-time or streaming data needs What is Azure Data Lake .
- Inefficient for Iterative Algorithms – Algorithms like machine learning or graph processing often require multiple iterations, which MapReduce handles poorly.
- Debugging and Monitoring Complexity – Troubleshooting distributed jobs across clusters can be time-consuming and complex.
- Storage Dependency – Heavy reliance on Hadoop Distributed File System (HDFS) can be a bottleneck in some scenarios.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Hadoop MapReduce Architecture
The architecture of Hadoop MapReduce is designed to process massive amounts of data in parallel across distributed systems. It follows a master-slave architecture with a few key components:

How Hadoop MapReduce Works: Step-by-Step
Let’s walk through a basic MapReduce job to see how the process works:
Step 1: Data Ingestion
Step 2: Map Phase
Step 3: Shuffle and Sort
Step 4: Reduce Phase
Step 5: Output Data
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
Common Use Cases for Hadoop MapReduce
Hadoop MapReduce is widely used for processing and analyzing massive datasets across various industries. In e-commerce, it helps analyze customer behavior, recommend products, and optimize pricing strategies. In finance, What is Splunk Rex MapReduce supports fraud detection, risk analysis, and large-scale transaction processing. The telecommunications sector leverages it to monitor network performance, detect anomalies, and predict maintenance needs.
MapReduce is also essential in healthcare, enabling genomic analysis, patient data processing, and medical research at scale. Additionally, social media and web analytics use MapReduce to process clickstreams, user interactions, and sentiment analysis. Its ability to distribute large computational tasks across multiple nodes makes it a reliable solution for big data analytics, providing scalability, fault tolerance, and efficient processing for diverse real-world applications.By analyzing vast amounts of unstructured social data, companies can gain valuable insights into customer opinions and behaviors.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Challenges and Limitations of MapReduce
Future of MapReduce in the Big Data Ecosystem
While MapReduce has been a fundamental part of the big data landscape for years, newer technologies like Apache Spark are gaining traction due to their faster processing capabilities and ease of use. Spark, for instance, Key Advantages of Using MapReduce performs in-memory processing, which is much faster than the traditional disk-based MapReduce processing. However, Hadoop MapReduce still remains highly relevant for batch processing tasks where high throughput and fault tolerance are crucial Data Science Training. Additionally, Hadoop’s compatibility with other big data tools and its integration into the broader ecosystem ensures that MapReduce will continue to play a significant role in processing large-scale data for the foreseeable future. In conclusion, while newer technologies may complement or replace certain aspects of MapReduce, its distributed nature, Big Data Ecosystem,fault tolerance, and scalability continue to make it a valuable tool for handling massive data processing tasks in industries worldwide.




