
Last updated on 06th Nov 2025| 10690
- What is Apache Storm?
- Real-time vs Batch Processing
- Storm Architecture Overview
- Setting Up Storm Cluster
- Topologies, Spouts, and Bolts
- Writing a Simple Storm Application
- Tuple and Stream Concepts
- Reliability and Fault Tolerance
- Integration with Kafka and HDFS
- Performance Tuning
- Storm Trident for High-Level API
- Conclusion
What is Apache Storm?
Apache Storm is a powerful, open-source distributed real-time computation system designed to process unbounded data streams with low latency. Originally created by BackType and later acquired by Twitter, it is now an Apache top-level project, often used in real-time analytics and Data Science Training. Storm allows developers to process continuous streams of data in real time, offering capabilities comparable to batch-processing systems like Hadoop, but for real-time needs. Storm is a versatile option for managing massive streaming data since it can be integrated with a number of data sources and messaging platforms, including Kafka, RabbitMQ, and Kestrel. Real-time analytics, fraud detection, log processing, monitoring, and recommendation systems are typical use cases. It is a well-liked solution for businesses that require immediate insights from continuously created data because of its capacity to analyse millions of tuples per second per node.
Real-Time vs Batch Processing
Batch Processing processes large volumes of data accumulated over time. This model is efficient for jobs that do not require immediate results, like generating reports or running complex analytics on historical data. Tools like Apache Hadoop and Apache Spark (in batch mode) operate in this domain, providing a useful basis for Comparative Analysis of batch versus real-time processing systems. Real-Time Processing, by contrast, processes data immediately upon arrival. Apache Storm falls into this category. It’s ideal for use cases like fraud detection, real-time analytics, live monitoring systems, and social media trend analysis, where immediate feedback or response is crucial. Batch processing systems are inherently simpler to scale and manage, but they can’t offer the low-latency decision-making that real-time systems provide. In many modern applications, both are used together in a Lambda architecture batch for completeness and real-time for low latency.
Storm Architecture Overview
Apache Storm’s architecture is built around several key components that work together to enable real-time stream processing. As the master node, the Nimbus is in charge of allocating tasks to worker nodes, distributing code, and keeping an eye out for any system malfunctions. The worker processes that carry out the actual computation activities are managed by the supervisors, who work on the worker nodes.
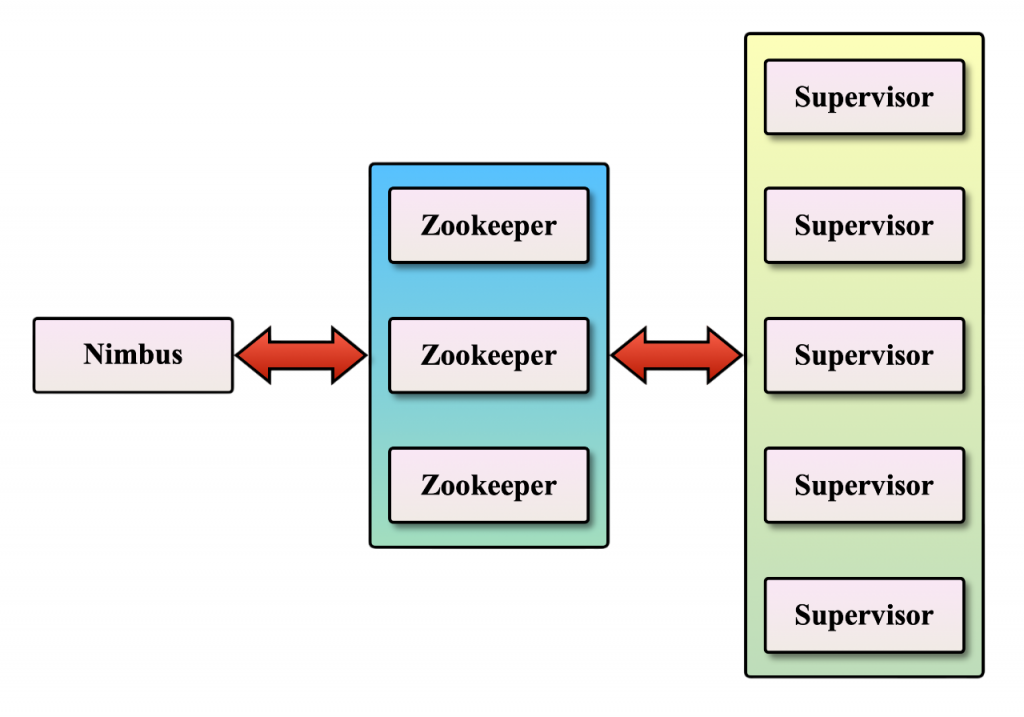
Zookeeper serves as a communication backbone that tracks cluster states and guarantees fault tolerance in order to maintain coordination and synchronisation throughout the distributed cluster. Spouts and Bolts, the fundamental processing components that manage data input and transformation, are run by Worker Processes within the worker nodes, making Apache Storm a practical example in the Best Data Science Course. Storm is able to efficiently parallelize computation because each worker process has one or more Executors doing many Tasks. Nimbus and Supervisors work together to ensure that the topology is correctly deployed and running. Zookeeper handles the communication between components, ensuring fault tolerance and coordination.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Setting Up a Storm Cluster
Installing the necessary prerequisites, such as Java (JDK 8 or later) and Apache Zookeeper, which is used for cluster component coordination, is the initial step in setting up an Apache Storm cluster. Once these conditions are satisfied, visit the official Apache Storm website to download and unzip the most recent version of Storm. Configure the storm.yaml file after that. Set the nimbus.host field in this configuration file to the IP address of the Nimbus-running machine to indicate the Nimbus host, following practices used in IBM Big Data InfoSphere deployments. Next, use supervisor.slots.ports to specify the port slots for the supervisors and list every Zookeeper server under storm.zookeeper.servers. Start the required services in the following order after the configuration is finished: Start Zookeeper first, then use the command bin/storm nimbus to start the Nimbus service, and then use bin/storm supervisor to start the Supervisor service. Lastly, use bin/storm ui to launch the Storm UI. The Storm UI is an easily accessible web-based interface that lets you follow operating topologies, keep an eye on the cluster’s performance, and troubleshoot any problems in real time after all services are operational.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Topologies, Spouts, and Bolts
- Topology: Defines the workflow of computation. It is a DAG where nodes are Spouts or Bolts.
- Spout: A data source component that emits streams of tuples into the topology.
- Bolt: A processing component that receives, processes, and emits tuples.
Topologies run continuously until terminated. Spouts typically connect to external sources like Kafka, while Bolts may filter, aggregate, or join data, demonstrating why The New Black Now Is Hadoop in modern big data ecosystems.
Writing a Simple Storm Application
To build a simple word count Storm topology:
- Create a Spout to emit words.
- Create a Normalizer Bolt to standardize the words.
- Create a Counter Bolt to count occurrences.
- Assemble the topology using TopologyBuilder.
- TopologyBuilder builder = new TopologyBuilder();
- builder.setSpout(“word-reader”, new WordReaderSpout());
- builder.setBolt(“word-normalizer”, new
- WordNormalizerBolt()).shuffleGrouping(“word-reader”);
- builder.setBolt(“word-counter”, new
- WordCounterBolt()).fieldsGrouping(“word-normalizer”, new Fields(“word”));
- Config conf = new Config();
- conf.setDebug(true);
- StormSubmitter.submitTopology(“WordCountTopology”, conf,
- builder.createTopology());
Determining an architecture that links data sources and processing components is a necessary step in creating a basic Apache Storm application. Bolts analyze the data, such as normalizing words or counting occurrences, while Spouts are designed to broadcast data streams, giving you practical insights that you can Learn About Spotfire in real-time analytics. The TopologyBuilder class is used to connect these elements. The topology operates continuously, processing data in real time until it is stopped, after it has been configured and uploaded. This configuration shows how Storm uses a combination of spouts, bolts, and real-time computing to manage live data streams.

Reliability and Fault Tolerance
Storm guarantees at-least-once message processing through:
- Anchoring: Tracks tuple lineage from spout to final bolt.
- Acknowledgement: Bolts acknowledge successful processing. If not acknowledged in time, the tuple is replayed.
- Retries: Storm handles automatic retries for failed tuples.
- Fault Tolerance:Nimbus and Supervisor restart automatically, and tasks are reassigned as needed. Zookeeper ensures consistent cluster state, highlighting the Importantce of Hadoop In Big Data for reliable distributed processing.
Tuple and Stream Concepts
The basic data unit that moves through Apache Storm is called a tuple. Each field in the tuple has a unique name and associated value, much like a row in a database table. These tuples travel as streams continuous data flows through the processing components. Spouts, which serve as data sources, emit streams; bolts, which analyse incoming data and may create new output streams, can also produce streams.
Storm provides a number of grouping techniques to control data flow between components, making it a valuable tool for practical applications in Data Science Training. To fairly disperse the weight, shuffle grouping divides tuples among bolts at random. Field grouping ensures that tuples containing the same word are directed to the same bolt for consistent processing by routeing tuples based on the value of a certain field. In contrast, all grouping allows every bolt to receive a copy of the same data by broadcasting every tuple to every bolt.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Integration with Kafka and HDFS
- Kafka Integration: Use KafkaSpout to consume real-time streams from Kafka topics.
- HDFS Integration: Use HdfsBolt to persist processed data to Hadoop’s HDFS for offline storage or batch analytics.
- KafkaSpout kafkaSpout = new KafkaSpout(kafkaConfig);
- builder.setSpout(“kafka-stream”, kafkaSpout);
- builder.setBolt(“process”, new
- ProcessingBolt()).shuffleGrouping(“kafka-stream”);
Kafka and HDFS may be easily integrated with Apache Storm to manage batch and real-time data. While HdfsBolt makes it possible to save processed data in HDFS for offline analytics or long-term storage, KafkaSpout enables Storm to receive live data streams from Kafka topics, providing practical experience relevant to Cassandra Online Training FOR Next Gen Computing. Storm can effectively handle both persistent data storage and real-time processing thanks to this integration.
Performance Tuning
For optimal performance, consider:
- Parallelism: Increase executors and tasks for spouts and bolts.
- Worker JVM Tuning: Set appropriate heap size and garbage collection strategy.
- Buffer Size Configs: Tweak topology.executor.receive.buffer.size and topology.transfer.buffer.size.
- Backpressure: Prevent overload by enabling backpressure.
- Batching and Acknowledgement: Use batching and fine-tuned acking to reduce communication overhead.
- Stats Monitoring: Use Storm UI and logs to monitor tuple processing time, failure rates, and throughput.
Increasing executors and jobs, modifying worker JVM settings, establishing buffer sizes, and turning on backpressure to avoid overload are all part of optimising Apache Storm, which is also widely applied in Market Basket Analysis for real-time insights. By tracking throughput, latency, and errors, monitoring via the Storm UI ensures dependable and effective real-time processing.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Storm Trident for High-Level API
Trident provides a high-level abstraction with batch-like semantics on top of Storm:
- Offers exactly-once processing.
- Supports stateful operations.
- Simplifies joins, aggregations, and grouping. Example Trident usage:
- Stream stream = topology.newStream(“spout1”, new FixedBatchSpout(…));
- stream.each(new Fields(“word”), new WordCountFunction(), new
- Fields(“count”))
- .groupBy(new Fields(“word”))
- .persistentAggregate(new MemoryMapState.Factory(), new Count(), new
- Fields(“total”));
Trident is ideal for applications needing higher-level logic with state persistence.
Conclusion
Apache Storm is a battle-hardened, real-time stream processing system capable of handling high-volume data with low latency. Its architecture supports scalability, fault tolerance, and flexible integration with systems like Kafka and HDFS. With Trident offering exactly-once semantics and state management, Storm can serve diverse real-time use cases across industries, making it an essential tool in Data Science Training. Mastering spouts, bolts, topologies, and performance tuning unlocks the full potential of Apache Storm in building modern, responsive data pipelines. Organisations can obtain instant insights from ongoing data streams by utilising its potent capabilities, facilitating quicker decision-making and more intelligent business operations. Learning Apache Storm provides a solid basis for jobs in big data and real-time analytics for both novices and experts.




