
Last updated on 04th Oct 2025| 10256
- Introduction to Hadoop and Its Evolution
- Why Hadoop 3.0 Was Needed
- Support for Multiple Standby NameNodes
- Intra-DataNode Balancer
- Erasure Coding for HDFS Storage Efficiency
- YARN Timeline Service v2.0
- Docker Support in Hadoop 3.0
- MapReduce Task-Level Native Optimization
- Conclusion
Introduction to Hadoop and Its Evolution
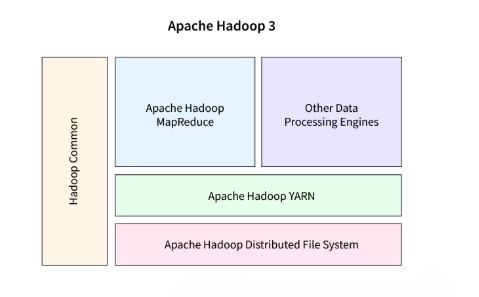
Hadoop is an open-source framework designed to store and process vast amounts of data across distributed clusters of computers. Originally developed by Doug Cutting and Mike Cafarella in 2005, Hadoop revolutionized big data management by enabling scalable, fault-tolerant processing of large datasets using commodity hardware. Its core components HDFS (Hadoop Distributed File System) and MapReduce allow for efficient storage and parallel data processing. Over the years,Data Science Training Hadoop has evolved significantly to meet growing data demands and technological advancements. New features and improvements have been added to enhance performance, reliability, and ease of use. From its early versions focused primarily on batch processing, Hadoop has expanded into a comprehensive ecosystem supporting real-time analytics, resource management, and data integration. This evolution culminates in Hadoop 3.0, which introduces advanced capabilities such as multiple standby NameNodes, erasure coding, and Docker support, further solidifying its role as a foundational technology in the big data landscape.
Why Hadoop 3.0 Was Needed
Hadoop 3.0 was developed to address the limitations and challenges faced by previous versions as data volumes and processing demands grew exponentially. Earlier Hadoop versions had constraints like a single Apache Spark Certification active NameNode, which created a potential single point of failure and limited scalability. Additionally, storage efficiency and resource utilization were not optimal, impacting performance and cost-effectiveness. Hadoop 3.0 introduced multiple standby NameNodes to enhance fault tolerance and high availability, ensuring smoother operations even during failures.
The addition of erasure coding improved storage efficiency by reducing data redundancy without compromising reliability. Features like the intra-datanode balancer and enhanced YARN Timeline Service helped optimize resource management and application tracking. Furthermore, Hadoop 3.0’s support for Docker containers facilitated better application deployment and isolation. These enhancements were critical to meet the evolving needs of big data applications, making Hadoop 3.0 a more robust, scalable, and efficient platform for modern data processing.
Do You Want to Learn More About Data Science? Get Info From Our Data Science Course Training Today!
Support for Multiple Standby NameNodes
- Improved High Availability: Allows multiple standby NameNodes to be configured alongside the active NameNode for better fault tolerance.
- Reduced Single Point of Failure: Eliminates the risk of downtime caused by failure of the primary NameNode.
- Faster Failover: Standby NameNodes can quickly take over in case the active NameNode fails, minimizing service disruption.
- Load Distribution: Enables better load balancing of NameNode operations across multiple nodes, improving performance BFSI Sector Big Data Insights .
- Scalability: Supports larger clusters by managing namespace metadata more efficiently.
- Simplified Management: Administrators can maintain multiple standby nodes without complex manual failover processes.
- Enhanced Reliability: Ensures continuous cluster availability and resilience in critical big data environments.
- Optimizes Storage Within Nodes: Balances data distribution across multiple storage disks inside a single DataNode.
- Prevents Disk Overload: Avoids situations where some disks are full while others have free space.
- Improves Disk Utilization: Maximizes use of available storage capacity on each DataNode.
- Enhances Performance: Become a Big Data Analyst Balanced disks reduce bottlenecks and improve read/write speeds.
- Automated Balancing: Runs automatically to redistribute data as needed without manual intervention.
- Reduces Risk of Disk Failure: Prevents excessive wear on individual disks by distributing data evenly.
- Supports Large Clusters: Helps maintain efficient storage management in complex, multi-disk DataNodes.
- Containerization Integration: Enables running Hadoop components inside Docker containers for better isolation and portability.
- Simplified Deployment: Streamlines setup and management of Hadoop clusters by packaging environments consistently.
- Enhanced Resource Utilization: Essential Concepts of Big Data & Hadoop Allows efficient resource allocation and isolation among multiple containerized applications.
- Improved Scalability: Facilitates rapid scaling of cluster nodes by deploying containerized services quickly.
- Consistent Environments: Reduces environment-related issues by standardizing software configurations across development, testing, and production.
- Supports Modern DevOps Practices: Integrates well with CI/CD pipelines and container orchestration tools like Kubernetes.
- Better Testing and Development: Enables developers to replicate production-like Hadoop environments locally using Docker containers.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Intra-DataNode Balancer

Erasure Coding for HDFS Storage Efficiency
Erasure coding is a significant feature introduced in Hadoop 3.0 to enhance storage efficiency in the Hadoop Distributed File System (HDFS). Traditionally, HDFS uses replication to ensure data reliability, typically storing three copies of each data block. While this approach guarantees fault tolerance, it results in high storage overhead, consuming large amounts of disk space. Erasure coding addresses this by breaking data into fragments, Big Data Can Help You Do Wonders encoding it with redundant pieces, and distributing them across different nodes. This method significantly reduces the amount of extra storage required compared to replication while maintaining data durability and fault tolerance. By enabling more efficient storage utilization, erasure coding helps organizations lower infrastructure costs and manage larger datasets effectively. It is particularly beneficial for storing cold or archival data where access speed is less critical but reliability remains essential. Overall, erasure coding represents a crucial advancement in optimizing HDFS storage for modern big data environments.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Big Data Analytics Master Program Training Course Now!
YARN Timeline Service v2.0
YARN Timeline Service v2.0 is an enhanced feature in Hadoop 3.0 designed to improve the scalability and reliability of tracking application and cluster metadata. It collects and stores detailed information about the lifecycle of applications running on the YARN (Yet Another Resource Negotiator) framework. Compared to its predecessor, Timeline Service v2.0 offers better performance,Data Science Training supports higher data volumes, and provides a more robust architecture with improved fault tolerance.
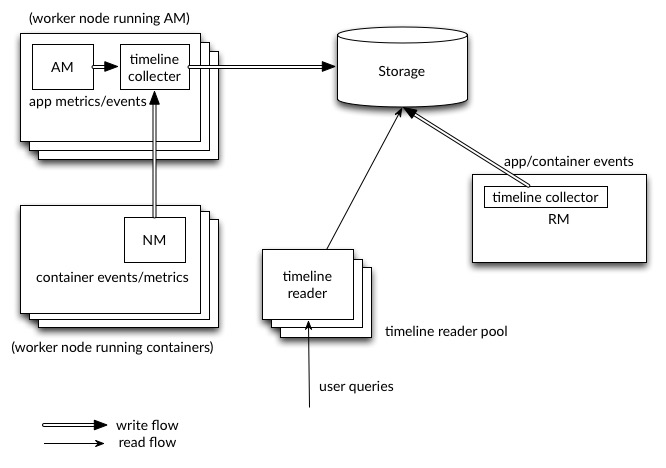
It enables administrators and developers to monitor, analyze, and debug applications more effectively by offering comprehensive insights into resource usage, job progress, and system events. This upgrade is critical for managing large-scale, complex Hadoop clusters, ensuring efficient resource allocation and streamlined operations.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Acte Your Interview!
Docker Support in Hadoop 3.0
MapReduce Task-Level Native Optimization
MapReduce Task-Level Native Optimization in Hadoop 3.0 enhances the efficiency and performance of data processing tasks by leveraging native system-level optimizations. This feature allows individual MapReduce tasks to execute more quickly and with lower resource consumption by utilizing optimized native code instead of relying solely on Java Virtual Machine (JVM) execution. By integrating native libraries for critical operations, such as compression, decompression, and data serialization Big Data is Transforming Retail Industry , Hadoop reduces CPU overhead and improves throughput. This results in faster job completion times and better utilization of cluster resources. Additionally, native optimizations help decrease latency, enabling more responsive data processing workflows. Overall, task-level native optimization contributes significantly to making MapReduce more performant and scalable, aligning Hadoop 3.0 with the growing demands of big data analytics and complex workload processing.
Conclusion
Hadoop 3.0 is a forward-looking release that addresses many of the pain points of its predecessors. With support for multi-standby NameNodes, erasure coding, Docker integration, and YARN enhancements, this version is designed for modern data architectures and enterprise-scale workloads. By embracing cloud-native principles, MapReduce Task-Level Native , Data Science Training supporting containerized execution, and improving fault tolerance and storage efficiency, Hadoop 3.0 ensures that the Hadoop ecosystem remains relevant in a rapidly evolving landscape dominated by AI, real-time analytics, and distributed computing. Organizations upgrading to or starting with Hadoop 3.0 can expect not only improved performance and cost savings but also the ability to innovate with confidence.




