
Last updated on 07th Oct 2025| 10048
- Introduction
- What is Hadoop?
- Core Components of Hadoop Ecosystem
- Architecture of Hadoop
- Hadoop Distributed File System (HDFS)
- MapReduce: The Processing Power of Hadoop
- YARN: Yet Another Resource Negotiator
- Features and Benefits of Hadoop
- Conclusion
Introduction
Over the past two decades, we have witnessed an unprecedented explosion in data generation. From social media feeds and mobile apps to sensors, IoT devices, and enterprise systems massive volumes of structured, semi-structured, and unstructured data are being generated every second. This explosion is what we term Big Data data that is too large, fast, or complex for traditional systems to handle efficiently. To turn this challenge into opportunity, enrolling in Data Science Training is a strategic move empowering professionals to harness advanced analytics, scalable tools, and machine learning techniques to extract actionable insights from massive datasets. Conventional data storage and processing systems, primarily designed for smaller, structured datasets, struggle with the volume, variety, and velocity of modern data. The challenge isn’t just storing big data, it’s extracting meaningful insights from it, and doing so quickly and cost-effectively. This is precisely where Apache Hadoop comes into play.
What is Hadoop?
Apache Hadoop is an open-source framework that allows for distributed storage and processing of large datasets using a cluster of commodity hardware. It is designed to scale up from a single server to thousands of machines, each offering local computation and storage. Hadoop doesn’t rely on expensive hardware for high availability; instead, it uses software-level fault tolerance and data replication. It breaks data into smaller chunks and processes them in parallel across a distributed network, delivering high throughput and fault resilience. To complement this with scalable NoSQL data modeling, explore Cassandra Keyspace Explained a guide to structuring distributed databases with replication strategies, consistency levels, and logical data separation.
At its core, Hadoop is made up of three main components:
- HDFS (Hadoop Distributed File System): Handles data storage.
- MapReduce: Handles data processing.
- YARN (Yet Another Resource Negotiator): Manages cluster resources and job scheduling.
Together, these components make Hadoop an indispensable tool for large-scale data analytics.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Core Components of Hadoop Ecosystem
While Hadoop Ecosystem started with just HDFS and MapReduce, the ecosystem has expanded into a rich suite of tools and modules that support various data tasks. To understand how these components drive business value, explore Big Data Analytics a discipline that transforms raw data into actionable insights using scalable platforms, predictive models, and real-time processing frameworks.
Primary Components:
- HDFS: Stores massive volumes of data across nodes.
- MapReduce: Processes data in parallel using a divide-and-conquer approach.
- YARN: Allocates resources and manages task execution across the cluster.
Supporting Ecosystem Tools:
- Hive: Data warehousing and SQL-like querying.
- Pig: Scripting platform for analyzing large datasets.
- HBase: NoSQL database that runs on top of HDFS.
- Sqoop: Data transfer between Hadoop and relational databases.
- Flume: Collects and transports streaming log data into Hadoop.
- Oozie: Workflow scheduler for managing Hadoop jobs.
- ZooKeeper: Coordination service for distributed applications.
- Spark: Fast in-memory data processing engine (often integrated with Hadoop).
These components enhance Hadoop’s capabilities, enabling it to serve not just as a storage system, but also as a comprehensive big data processing framework.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Architecture of Hadoop
Architecture of Hadoop is designed for scalability, fault tolerance, and efficiency. It uses a master/slave architecture where roles are assigned to different nodes within the cluster. To translate this technical foundation into professional growth, explore Career in Big Data Analytics a pathway that connects distributed computing expertise with high-demand roles in data engineering, machine learning, and enterprise analytics.
Key Roles:
- Master Node: Runs the NameNode (HDFS metadata) and ResourceManager (YARN).
- Slave Nodes: Run DataNode services (store actual data) and NodeManager (manage execution of tasks).
The Architecture of Hadoop ensures that even if individual nodes fail, data remains safe and computation continues with minimal disruption. This resilience is critical in distributed systems working with petabytes of data.

Hadoop Distributed File System (HDFS)
The Hadoop Distributed File System (HDFS) serves as a reliable and high-performing storage system designed to handle petabyte-scale datasets with great dependability and speed. Its main method is to divide files into large, fixed-size chunks (128MB or 256MB) that are spread across a cluster of standard hardware. This setup enables easier data organization and retrieval. The system’s design rests on strong, self-repairing principles. To build and maintain such resilient architectures, enrolling in Data Science Training is a smart investment equipping professionals with the skills to design fault-tolerant systems, automate recovery workflows, and optimize data access across distributed environments. An automated data redundancy feature creates three copies of every block by default, ensuring continuous availability and protection against node failure. HDFS also uses a data locality approach that moves processing logic closer to the data. This significantly cuts down on network traffic and bottlenecks. Built for easy scaling, HDFS lets businesses grow their storage and computing power by simply adding more machines to the cluster. Its “write-once, read-many” access model is ideal for sequential, large-scale data processing tasks. Together, these features make HDFS an excellent platform for any organization needing a reliable and sturdy infrastructure to process and analyze large amounts of data.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
MapReduce: The Processing Power of Hadoop
As the main programming model in Hadoop, MapReduce caused a major shift in distributed computing by offering a clear method for handling large data challenges. Its process has two stages. First is the “Map” phase, where initial data is split into key-value pairs and processed in parallel by individual functions. Next is the “Reduce” phase, which gathers and combines these separate outputs into one complete result. This flexible framework allows for a wide range of complex data tasks, such as sorting, filtering, aggregating, and analyzing word frequencies and system logs.
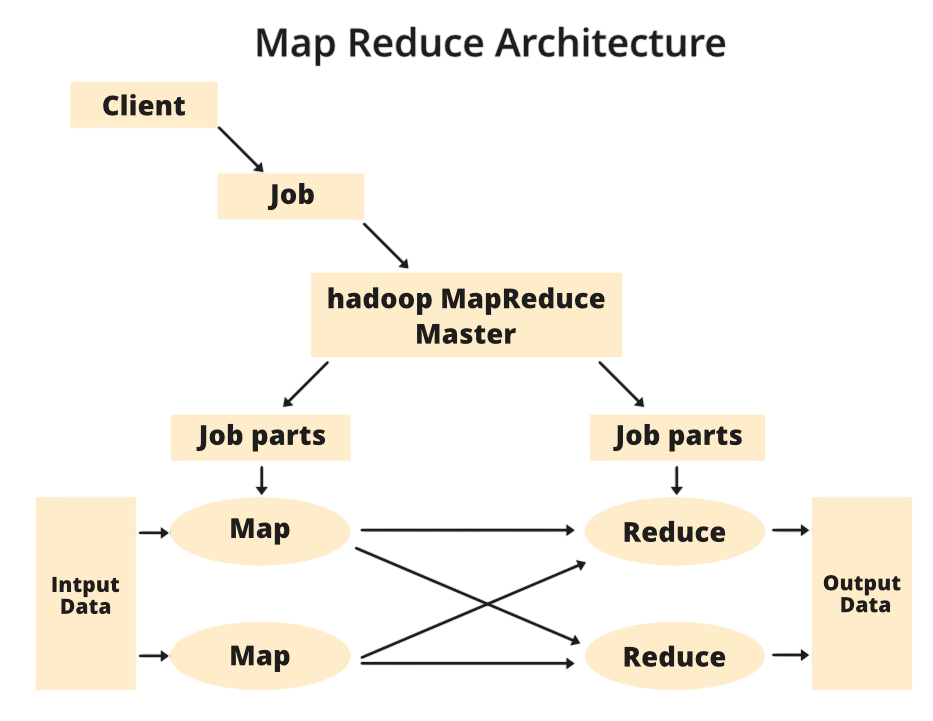
To simplify these operations on Hadoop, explore Apache Pig Explained a high-level scripting platform that streamlines data workflows using Pig Latin, making parallel processing more accessible and efficient. While its impact was groundbreaking, the model’s complexity and lengthy coding needs led to the creation of simpler engines like Spark. Even with this change, MapReduce established the crucial framework for scalable, distributed data processing. By dividing huge problems into smaller, parallel tasks, it remains a key technology that has fundamentally changed how organizations approach big data.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
YARN: Yet Another Resource Negotiator
Introduced in Hadoop 2.0, YARN is the resource management layer that replaced the original JobTracker/TaskTracker mechanism. YARN separates resource management from job scheduling, allowing Hadoop to support multiple processing engines beyond MapReduce. To harness this flexibility for structured data processing, explore Spark SQL and the DataFrame API a powerful abstraction that enables seamless querying, transformation, and analysis of distributed datasets using familiar SQL syntax and optimized execution plans.
YARN Responsibilities:
- ResourceManager: Allocates system resources across all applications.
- NodeManager: Manages resources on a single node and reports to the ResourceManager.
- ApplicationMaster: Manages the execution of individual applications.
YARN enables multi-tenancy, resource sharing, and parallel job execution, making Hadoop more flexible and efficient for modern workloads.
Features and Benefits of Hadoop
Hadoop offers several advantages that have driven its widespread adoption across enterprises. To push these capabilities further into low-latency analytics, explore Spark’s Real-Time Parallel Processing a framework that enables in-memory computation, stream handling, and rapid data transformations across distributed clusters for real-time decision-making.
Key Features:
- Open Source: Backed by Apache, with a large contributor community.
- Cost-Effective: Runs on low-cost commodity hardware.
- Scalable: Easily scales horizontally by adding more nodes.
- Fault-Tolerant: Automatic recovery from node failures.
- High Availability: With NameNode HA, the system avoids single points of failure.
- Extensible Ecosystem: Supports diverse processing tools, engines, and databases.
Benefits:
- Handles structured, semi-structured, and unstructured data.
- Suitable for batch processing, data warehousing, and machine learning.
- Enables data lake architecture by storing raw and refined data in one place.
- Offers integration with cloud platforms like AWS, Azure, and GCP.
These strengths position Hadoop as a cornerstone of big data architectures in many organizations.
Conclusion
Despite the emergence of newer big data frameworks like Apache Spark, Apache Flink, and cloud-native solutions, Hadoop remains a foundational technology in many data infrastructures. It is stable, mature, and has a broad support community. HDFS is still used as a storage layer in many modern architectures, often paired with Spark or Presto for processing. To fully leverage these technologies and architect scalable data solutions, enrolling in Data Science Training is a strategic move empowering professionals to integrate storage, compute, and analytics into cohesive, high-performance data platforms. Hadoop’s ability to scale, handle diverse data types, and work with multiple processing engines continues to make it a valuable asset. For organizations just beginning their big data journey or operating in hybrid/on-prem environments, Hadoop remains a practical and powerful solution.




