
Last updated on 08th Oct 2025| 9990
- Introduction: The Acceleration of Big Data
- Understanding the Hadoop Ecosystem
- What is a Hadoop Processor?
- The Role of Parallel Processing in Hadoop
- MapReduce: The Original Hadoop Processing Engine
- YARN: The Modern Resource Manager
- Hadoop and High-Performance Clusters
- Spark vs MapReduce: Next-Gen Hadoop Processing
- Conclusion
Introduction: The Acceleration of Big Data
As data volumes continue to explode, the demand for faster data processing has never been higher. In industries like healthcare, finance, and e-commerce, real-time insights are crucial for decision-making, forecasting, and automation. At the heart of this revolution is Hadoop a framework that not only stores vast amounts of data but processes it at increasingly higher speeds. The concept of a Hadoop processor plays a pivotal role in this evolution, allowing enterprises to scale their data Data Science Training workloads while maintaining performance. The acceleration of big data has transformed how businesses and organizations operate in the digital age. With the exponential growth of data generated from social media, IoT devices, online transactions, and more, the demand for advanced data processing and analytics has skyrocketed. This surge enables organizations to uncover valuable insights, improve decision-making, and drive innovation. Technologies such as cloud computing, distributed storage, and real-time streaming have played a vital role in managing and analyzing massive datasets efficiently. As big data continues to expand rapidly, mastering its tools and techniques is essential for staying competitive in today’s data-driven world
Understanding the Hadoop Ecosystem
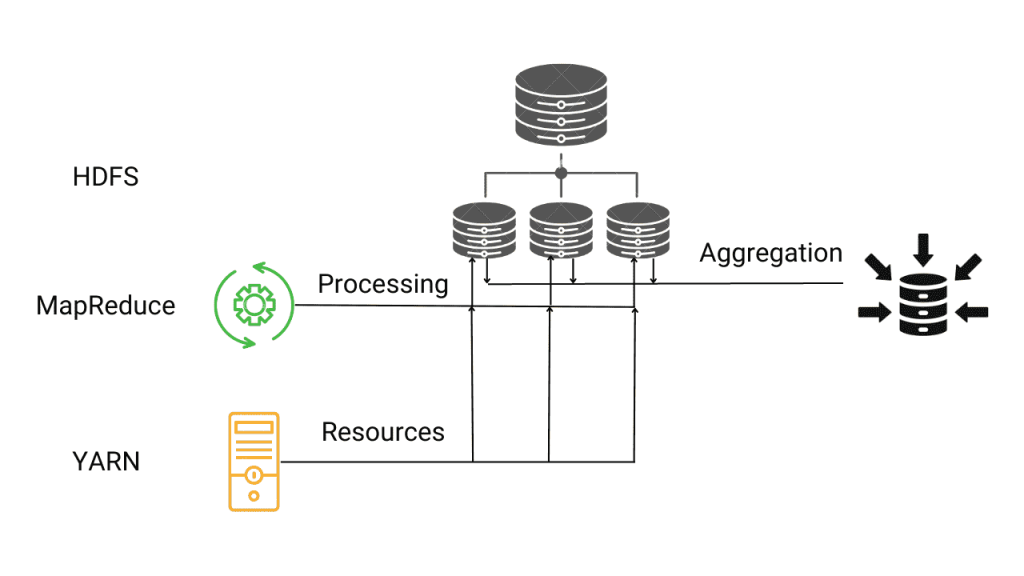
The Hadoop ecosystem is a suite of open-source tools designed to manage, store, and process large datasets across distributed computing clusters. It comprises multiple components such as HDFS (Hadoop Distributed File System), YARN (Yet Another Resource Negotiator), MapReduce, Hive, Pig, and HBase. This ecosystem enables organizations to handle petabyte-scale data by distributing workloads over multiple machines Scala Certification . The Hadoop processor refers specifically to the processing layer within this ecosystem, responsible for executing tasks that transform raw data into actionable output. The Hadoop ecosystem is a powerful suite of open-source tools designed to store, process, and analyze massive volumes of data across distributed computing environments.
At its core is the Hadoop Distributed File System (HDFS), which enables scalable and fault-tolerant storage. Complementing HDFS are processing frameworks like MapReduce and Apache Spark, which facilitate batch and real-time data processing. The ecosystem also includes tools for data ingestion (Apache Flume, Sqoop), resource management (YARN), and querying (Hive, Pig). Together, these components provide a flexible, scalable platform for handling big data challenges in diverse industries and applications.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
What is a Hadoop Processor?
- A Hadoop processor refers to the component or framework responsible for processing data stored in the Hadoop ecosystem.
- It primarily involves MapReduce, the original processing model for Hadoop, which divides tasks into map (filtering and sorting) and reduce (aggregation) phases.
- Modern Hadoop processing also uses Apache Spark, Apache Pig which provides faster, in-memory computation compared to MapReduce.
- Other processors include Apache Flink and Apache Tez, designed for more efficient and flexible data processing.
- Hadoop processors enable batch processing and, in some cases, real-time or near-real-time analytics on large datasets.
- They work in conjunction with HDFS for data storage and YARN for resource management and scheduling.
- Enables scalability: Parallel processing allows Hadoop to split large datasets into smaller chunks processed simultaneously across multiple nodes.
- Improves speed: By processing data in parallel, Hadoop significantly reduces the time required for big data computations.
- MapReduce framework: Uses parallel execution of map and reduce tasks to handle distributed data efficiently Data Science Training.
- Fault tolerance: Parallel tasks run independently, so failures can be isolated and retried without affecting the entire job.
- Resource utilization: Maximizes cluster resource usage by distributing workload evenly across nodes.
- Supports large-scale analytics: Essential for handling massive datasets in industries like finance, healthcare, and social media.
- YARN (Yet Another Resource Negotiator) is Hadoop’s cluster Modern Resource Manager management layer.
- It separates resource management from data processing, improving scalability and flexibility.
- Manages and schedules resources across multiple applications running on a Hadoop cluster.
- Supports various processing engines like MapReduce, Spark, BFSI Reasons for Moving Into Big Data Career and Tez simultaneously.
- Enables better cluster utilization by dynamically allocating CPU, memory, and bandwidth.
- Enhances fault tolerance by monitoring application status and restarting failed tasks.
- Key to Hadoop’s evolution, allowing it to support diverse workloads beyond MapReduce.
- Hadoop leverages distributed computing to run big data workloads across clusters of commodity hardware.
- High-performance clusters (HPC) focus on maximizing processing speed and throughput for complex computations.
- Hadoop clusters use scalable, fault-tolerant architecture, distributing data and tasks across many nodes.
- HPC environments prioritize low-latency interconnects and optimized resource scheduling, which Hadoop can integrate with Essential Concepts of Big Data & Hadoop .
- YARN resource manager enables efficient management of cluster resources, supporting multiple workloads.
- Combining Hadoop with HPC can accelerate data-intensive applications like scientific simulations, machine learning, and analytics.
- Both systems aim to handle massive datasets but differ in hardware setup and workload optimization focus.
- Up to 100x faster for certain workloads
- Built-in libraries for machine learning (MLlib), graph processing (GraphX), and SQL (Spark SQL)
- Real-time stream processing via Spark Streaming Kafka vs RabbitMQ .
- Simplified code development with APIs in Python, Java, Scala, and R
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
The Role of Parallel Processing in Hadoop

MapReduce: The Original Hadoop Processing Engine
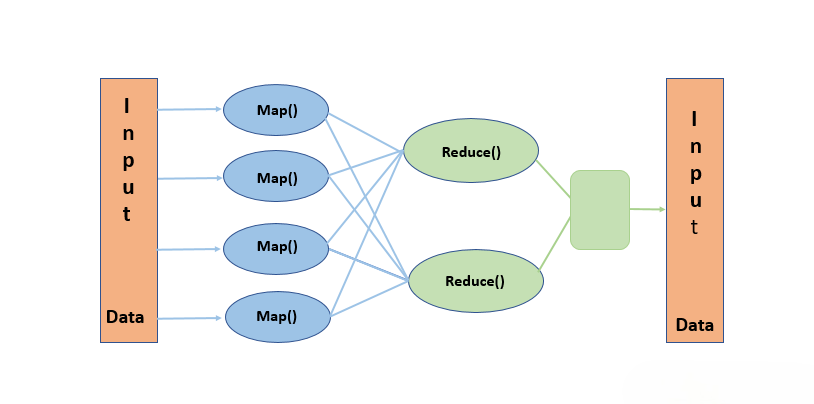
MapReduce is the foundational processing framework of the Hadoop ecosystem, designed to handle large-scale data processing across distributed clusters. It works by breaking down tasks into two phases: the Map phase, which filters and sorts data, and the Reduce phase, which aggregates and summarizes results.
This model enables parallel processing of massive datasets, improving efficiency and fault tolerance. Although newer frameworks like Apache Spark offer faster in-memory An ETL Audit Process processing, MapReduce remains a reliable engine for batch processing tasks, especially where fault tolerance and scalability are critical. It laid the groundwork for modern big data processing solutions.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
YARN: The Modern Resource Manager
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Hadoop and High-Performance Clusters
Spark vs MapReduce: Next-Gen Hadoop Processing
While MapReduce remains important, Apache Spark has rapidly become the preferred Hadoop processor due to its in-memory computation model, which drastically reduces disk I/O and speeds up processing. Unlike MapReduce, which writes intermediate data to disk, Spark keeps data in memory, making it ideal for iterative algorithms and streaming data.
Key benefits of Spark over MapReduce include:
This evolution from MapReduce to Spark showcases how the Hadoop processor landscape has adapted to meet the growing demands for speed, flexibility, and real-time insight.
Conclusion
Despite emerging competitors in the cloud and data processing space, Hadoop remains a foundational technology in Big Data. The evolution of its processing engines from MapReduce to Spark and beyond illustrates the platform’s adaptability and relevance in today’s high-speed data landscape. The concept of a Hadoop processor is no longer limited to batch jobs; it now encompasses real-time processing, AI/ML pipelines, and streaming analytics. As businesses continue to demand faster insights, Hadoop processors will remain at the core of scalable Data Science Training and reliable data architectures. Whether you are an aspiring data engineer or an enterprise IT strategist, understanding how Hadoop processors enhance speed and efficiency will give you a competitive edge in the Big Data arena. In conclusion, the Hadoop ecosystem has revolutionized how organizations store, process, and analyze massive datasets by leveraging distributed computing and parallel processing. Tools like MapReduce, YARN, and newer frameworks such as Spark have expanded the possibilities of big data analytics, enabling faster insights and greater scalability.




