
Last updated on 10th Oct 2025| 10273
- Introduction to Big Data
- Characteristics of Big Data (5 Vs)
- Challenges in Handling Big Data
- Role of Hadoop in Big Data
- HDFS and Data Storage
- MapReduce for Data Processing
- Tools in Hadoop Ecosystem
- Real-World Applications
- Advantages of Hadoop Over Traditional Databases
- Conclusion
Understanding the Basics of Big Data and the Importance of Hadoop
In the rapidly evolving digital landscape, the term Big Data and Hadoop has gained immense prominence for organizations striving to make sense of massive information flows. Businesses across various industries generate and rely on vast volumes of data to make informed decisions, enhance services, and stay competitive. However, managing such massive, diverse, and fast-moving data is no simple feat. To develop the skills needed to tackle these challenges, explore Data Science Training a hands-on course that equips learners with the tools and techniques to process complex datasets, build predictive models, and drive data-driven innovation. This is where technologies like Apache Hadoop come into the picture, acting as powerful enablers in harnessing the potential of big data. This guide aims to provide a comprehensive understanding of Big Data and Hadoop, focusing on their fundamentals and the pivotal role Hadoop plays in data processing and analysis.
Introduction to Apache Hadoop
Apache Hadoop is an open-source framework developed to support the processing of large data sets in a distributed computing environment. Originally inspired by Google’s MapReduce and Google File System (GFS) papers, Hadoop was created by Doug Cutting and Mike Cafarella and later adopted by the Apache Software Foundation. To understand how Hadoop evolved to support real-time read/write access to large datasets, explore HBase and Its Architecture a technical guide that explains HBase’s column-oriented design, data model, and integration with Hadoop for scalable, low-latency storage. It enables organizations to store massive amounts of structured, semi-structured, and unstructured data and process it efficiently across clusters of computers. Its distributed architecture, fault tolerance, and scalability make it the go-to solution for big data processing.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Characteristics of Big Data (5 Vs)
Big Data is typically defined by the 5 Vs: Volume, Velocity, Variety, Veracity, and Value. To process such vast and diverse datasets efficiently, explore What is Apache Pig a practical guide that explains Pig’s data flow language, execution model, and its role in simplifying complex ETL tasks within the Hadoop ecosystem.
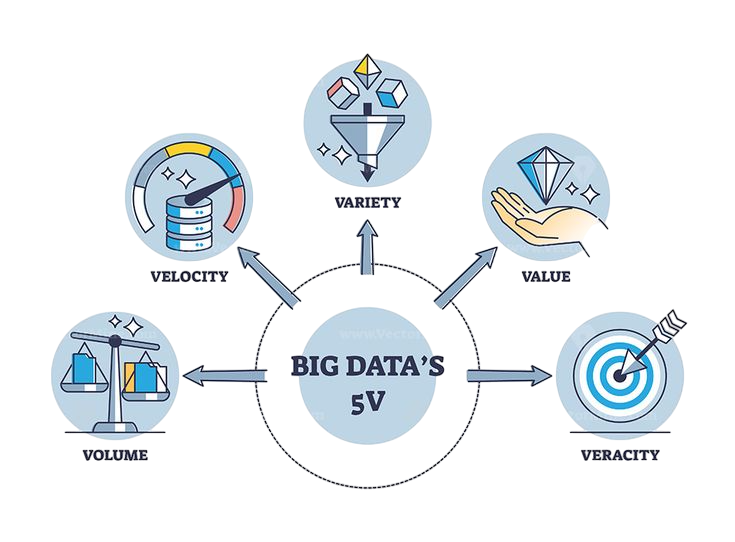
- Volume: Refers to the enormous amounts of data generated daily by users and systems.
- Velocity: Indicates the speed at which this data is created and processed to meet real-time demands.
- Variety: Covers the different types of data formats including text, images, audio, and video.
- Veracity: Refers to the accuracy, quality, and trustworthiness of the data.
- Value: Emphasizes the importance of extracting meaningful insights and business value from the data.
Together, these characteristics explain why traditional data management methods struggle to handle Big Data efficiently.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Challenges in Handling Big Data
While Big Data presents numerous opportunities, it also poses several challenges: from handling complex data structures to ensuring fast, accurate search across massive datasets. To address these intricacies in search and indexing, explore Elasticsearch Nested Mapping a technical guide that explains how nested fields are structured, queried, and optimized within Elasticsearch to support scalable, high-performance analytics.
- Data Storage: Storing petabytes of data economically and reliably.
- Data Processing: Efficiently processing large datasets without high latency.
- Data Integration: Merging data from multiple sources and formats.
- Data Security and Privacy: Ensuring sensitive information is protected.
- Scalability: Being able to scale infrastructure based on fluctuating data volumes.
To address these challenges, specialized frameworks like Apache Hadoop were developed, which revolutionized the way organizations process and analyze large-scale data.

Role of Hadoop in Big Data
Apache Hadoop is an open-source framework that enables the distributed processing of large datasets across clusters of computers using simple programming models. It is designed to scale up from a single server to thousands of machines, offering both reliability and fault tolerance. Hadoop has become synonymous with Big Data processing due to its flexibility, scalability, and ability to handle structured and unstructured data. One of Hadoop’s key strengths lies in its cost-effective architecture. To master these capabilities and apply them in real-world scenarios, explore Data Science Training a hands-on course that covers distributed computing, data modeling, and the tools needed to build scalable analytics solutions. Traditional data processing systems rely heavily on expensive hardware, whereas Hadoop can be deployed on commodity servers, significantly reducing infrastructure costs.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
HDFS and Data Storage
At the core of Hadoop’s strong data management system is the Hadoop Distributed File System (HDFS). This is a powerful storage solution built to manage large datasets across distributed computing environments. HDFS splits files into blocks and replicates them across several cluster nodes. This process ensures high fault tolerance and constant data availability. The system provides quick access that is ideal for large-scale batch processing. To extend these capabilities into cloud-native analytics, explore What is Azure Databricks a detailed guide that explains how this unified platform combines Apache Spark with Azure’s scalability to deliver collaborative, high-performance data science and engineering workflows. It also offers great scalability by allowing easy addition of nodes. One unique feature of HDFS is its smart approach to data locality. This method moves processing closer to where data is stored, which greatly improves overall performance.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
MapReduce for Data Processing
MapReduce is the data processing engine of Hadoop. It allows for the processing of massive datasets in parallel across a distributed cluster. The programming model consists of two main functions:
- Map: Takes a set of data and converts it into key-value pairs.
- Reduce: Merges and aggregates the output from the map phase to produce final results.
The abstraction provided by MapReduce simplifies the development of distributed applications. Developers can focus on business logic, while Hadoop handles the complexities of parallel execution, data distribution, and fault tolerance. However, MapReduce is best suited for batch processing and may not be ideal for real-time analytics. This limitation has led to the emergence of additional tools within the Hadoop ecosystem.
Tools in Hadoop Ecosystem
The power of Hadoop extends beyond just HDFS and MapReduce. Its ecosystem includes a wide range of tools that enable various aspects of big data processing:
- Apache Hive: A data warehouse tool that allows SQL-like queries on large datasets stored in HDFS.
- Apache Pig: A high-level scripting language for data analysis tasks.
- Apache HBase: A NoSQL database that runs on top of HDFS, ideal for real-time read/write access.
- Apache Sqoop: Used for transferring data between Hadoop and relational databases.
- Apache Flume: A tool for ingesting massive volumes of log and event data into Hadoop.
- Apache Oozie: A workflow scheduler for managing Hadoop jobs.
- Apache Spark: A fast and general-purpose engine for large-scale data processing, often used alongside Hadoop for real-time analytics.
Together, these tools form a comprehensive suite for data ingestion, storage, processing, and analytics.
Real-World Applications
Hadoop has become a game-changer for data analytics across many industries. It helps organizations find valuable insights in complex data. In retail, Hadoop supports in-depth analysis of customer behavior and creates personalized recommendations. In healthcare, professionals use its tools to manage electronic health records and forecast disease trends. Financial institutions use Hadoop for fraud detection and managing risk, while telecommunications companies improve network performance and customer service. To understand the mindset that drives these data-centric innovations, explore Data-Driven Culture a strategic guide that explains how organizations foster decision-making, agility, and accountability through data at every level. Government agencies apply the technology for public safety analysis and urban planning. Social media platforms take advantage of its real-time sentiment analysis to boost user engagement. By turning large amounts of raw data into useful information, Hadoop enables organizations to make better decisions that foster innovation and competitiveness in various sectors.
Advantages of Hadoop Over Traditional Databases
Compared to traditional relational database systems (RDBMS), Hadoop offers several distinct advantages: scalability, fault tolerance, and the ability to process diverse data types across distributed environments. To understand how these capabilities are unified across platforms, explore Data Integration a practical guide that explains how disparate data sources are connected, transformed, and synchronized to support real-time analytics and enterprise decision-making.
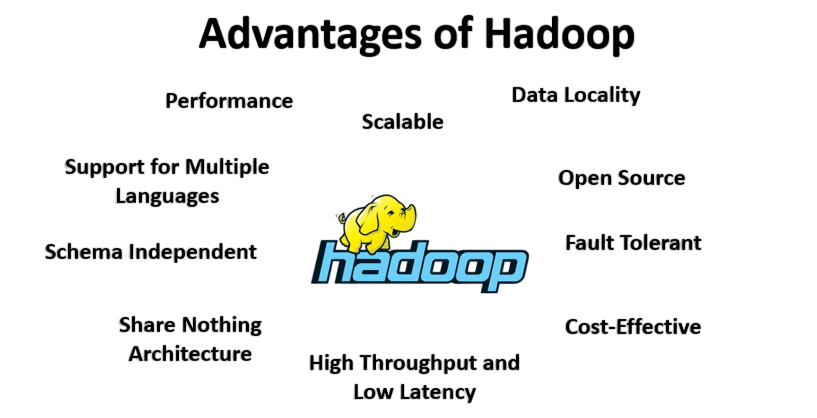
- Scalability: Easily scales to handle petabytes of data by adding inexpensive nodes.
- Cost-effective: Runs on commodity hardware, reducing the cost of deployment.
- Flexibility: Can process any type of data structured, semi-structured, or unstructured.
- Fault tolerance: Automatically replicates data across nodes to ensure data availability.
- High Performance: Parallel processing reduces the time required for large-scale computations.
While RDBMS is efficient for transactional data and structured queries, it struggles with the volume and variety of modern big data, making Hadoop a more suitable alternative for large-scale analytics.
Conclusion
In conclusion, Big Data and Hadoop are reshaping industries by enabling smarter decisions, deeper insights, and improved efficiency. However, managing this data requires powerful tools, and Hadoop has emerged as a cornerstone of modern data infrastructure. Its distributed architecture, vast ecosystem, and scalability make it a vital technology for enterprises seeking to leverage big data. To gain hands-on experience with these technologies and turn data into strategic advantage, explore Data Science Training a comprehensive program that equips learners with the skills to build scalable pipelines, analyze complex datasets, and drive data-first innovation. Whether you’re a developer, analyst, or aspiring data scientist, learning Big Data and Hadoop equips you with valuable skills to thrive in the data-driven world. With the right training, certifications, and hands-on experience, you can unlock a promising career path in big data analytics powered by Hadoop.




