
Last updated on 13th Oct 2025| 10431
- What is Data Modeling?
- Importance of Data Modeling in DBMS
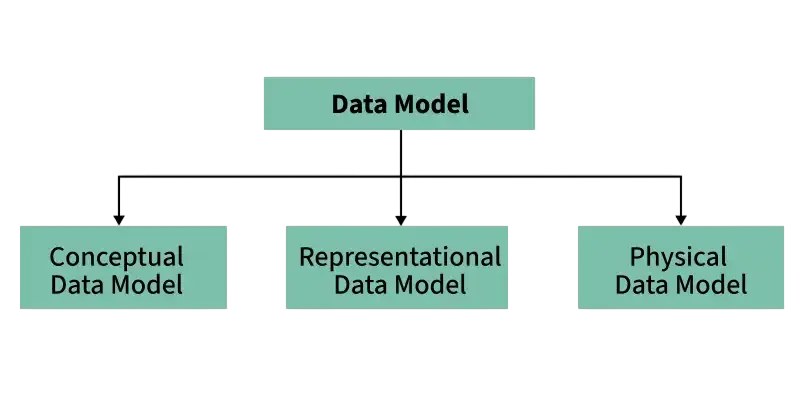
- Types of Data Models
- Conceptual vs Logical vs Physical Models
- Entity-Relationship Diagram (ERD)
- Attributes and Relationships
- Normalization Techniques
- Data Modeling Tools Overview
- Real-World Data Modeling Example
- Data Modeling for NoSQL Databases
- Final Tips and Resources
What is Data Modeling?
Data modeling is the process of visually and conceptually organizing data elements and their relationships. It provides a framework for describing data structures and defining how data is stored, connected, and accessed. It serves as the foundation for database design, making it easier to manage, maintain, and query data. To build on this foundation with advanced analytical capabilities, explore Data Science Training a hands-on program that empowers learners to work with structured datasets, apply machine learning techniques, and extract actionable insights for real-world decision-making. In software development, data modeling ensures that data elements are structured correctly and consistently. It simplifies communication between stakeholders like business analysts, developers, and database administrators. The primary goals are data accuracy, integrity, efficiency, and clarity.
Importance of Data Modeling in DBMS
Data modeling is critical in any DBMS (Database Management System) project. Here’s why: it defines how data is structured, accessed, and maintained across systems. To understand how real-time data flows impact these models, explore Stream Processing in Big Data a hands-on guide that explains how tools like Kafka and Storm enable continuous ingestion, transformation, and delivery of high-velocity data streams.
- Enhanced Clarity: Provides a visual representation of data requirements, making it easier to understand the structure.
- Efficient Design: Promotes logical and efficient schema design, reducing duplication.
- Performance Optimization: Allows architects to fine-tune databases by planning indexes, partitions, and relationships.
- Improved Communication: Bridges the gap between non-technical and technical stakeholders.
- Data Consistency: Ensures consistent data definitions and usage across applications.
- Business Alignment: Aligns database structures with real-world business rules and requirements.
- Facilitates Maintenance: Easier to identify and fix issues in a well-modeled system.
- Reduces Redundancy: Normalization reduces duplication, optimizing storage and performance.
Interested in Obtaining Your Data Science Certificate? View The Data Science Online Training Offered By ACTE Right Now!
Types of Data Models
- Conceptual Data Model: High-level abstraction. Focuses on defining entities, attributes, and relationships without technical details. Useful during requirement gathering.
- Logical Data Model: Translates conceptual models into detailed structures. Includes keys, data types, and normalization without considering physical implementation.
- Physical Data Model: Implements the logical model into a DBMS. Contains indexing, partitioning, constraints, and storage details.
Additional Types:
- Hierarchical Model: Data is structured like a tree. Parent-child relationships. Rarely used today.
- Network Model: A more flexible model allowing multiple parent-child relationships.
- Relational Model: Most common. Uses tables and relationships via keys.
- Object-Oriented Model: Integrates object-oriented principles like inheritance, encapsulation into data modeling.
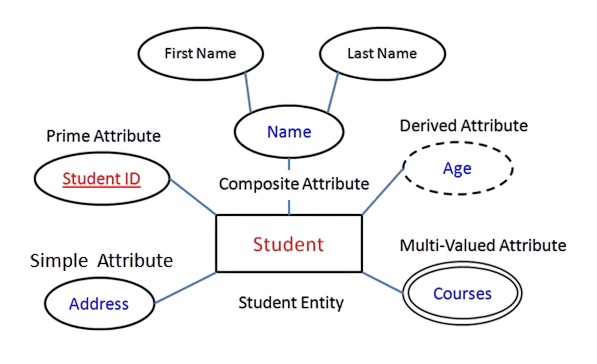
- Simple (Atomic): Cannot be divided. E.g. Age.
- Composite: Can be split. E.g. FullName into First and Last Name.
- Derived: Calculated from other data. E.g. Age from DOB.
- Multivalued: May have multiple values. E.g. Phone Numbers.
- 1:1: One employee has one office.
- 1:N: One department has many employees.
- M:N: Students enroll in multiple courses, and courses have many students.
- ER/Studio: Enterprise-grade tool for large projects.
- dbdiagram.io: Lightweight, code-based ER diagramming.
- Lucidchart: Cloud-based, great for collaboration.
- Toad Data Modeler: Comprehensive modeling with reverse engineering.
- Oracle SQL Developer Data Modeler: Tailored for Oracle DB.
- Draw.io: Free and flexible general-purpose diagramming.
- Microsoft Visio: Professional diagramming for businesses.
- Document-Oriented (e.g., MongoDB): JSON-like documents. Suited for hierarchical, nested data.
- Key-Value Stores (e.g., Redis): Pairs of keys and values. Simple and fast.
- Column-Family (e.g., Cassandra): Wide rows, similar to relational tables but optimized for speed.
- Graph (e.g., Neo4j): Nodes and edges for complex relationships (e.g., social networks).
- Model based on access patterns: Not just normalization.
- Denormalize when required: To improve read performance.
- Embed data: If frequently accessed together.
- Avoid joins and complex transactions: To maintain performance and scalability.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Online Training To Gain Insights From Our Experts!
Conceptual vs Logical vs Physical Models
| Feature | Conceptual Model | Logical Model | Physical Model |
|---|---|---|---|
| Focus | Business entities & rules | Entity relationships, keys | Implementation details |
| Audience | Stakeholders | Developers, analysts | DBAs |
| Level of Detail | High-level | Moderate detail | Full technical specification |
| Technology Specific | No | No | Yes |
| Key Features | Entities, relationships | Attributes, constraints | Indexes, data types, storage |

Entity-Relationship Diagram (ERD)
An Entity-Relationship Diagram (ERD) is a useful visual tool that shows the entities within a system and the connections between them. In an ERD, entities represent distinct objects like Customers and Orders. Each entity has specific attributes that give more details; for example, a Customer might have attributes such as Name and Email. To uniquely identify each entry in these entities, we use primary keys that ensure every record stays distinct. Foreign keys help establish relationships between different entities, showing how they interact. To apply these relational concepts in real-world analytics, explore Data Science Training a hands-on program that integrates database theory with data modeling, machine learning, and business intelligence for end-to-end analytical proficiency. For instance, a relationship could demonstrate that a Customer places an Order. The benefits of using an ERD are many. It improves our understanding of the overall database structure, making it easier to see how data points relate to one another. It also helps identify any missing data or potential issues that could affect data quality. By providing a clear visual representation, an ERD serves as a key foundation for database implementation and normalization.
Attributes and Relationships
Attributes:
Relationships:
Cardinality and participation constraints define how entities interact, influencing schema design and performance. To understand how these relationships scale in distributed environments, explore How to Deploy and Manage a technical walkthrough that covers cluster setup, configuration, and monitoring using Ambari for efficient Hadoop deployment.
Gain Your Master’s Certification in Data Science Training by Enrolling in Our Data Science Master Program Training Course Now!
Normalization Techniques
Normalization is a key process in database design that reduces redundancy and ensures data integrity. The first step, known as First Normal Form (1NF), focuses on eliminating repeating groups and ensuring that all columns contain atomic values. Once that is established, we move to Second Normal Form (2NF), which removes partial dependencies, ensuring that non-key fields depend entirely on the primary key. Next, Third Normal Form (3NF) addresses transitive dependencies, where non-key fields depend on other non-key fields. To understand how these normalization principles scale in high-velocity environments, explore Accelerating Big Data a technical guide that explains how Hadoop and distributed processing frameworks handle structured data at speed and scale. Beyond that, Boyce-Codd Normal Form (BCNF) requires that every determinant in the database is a candidate key, providing an even stricter level of normalization. For more complex relationships, Fourth Normal Form (4NF) and Fifth Normal Form (5NF) manage multivalued and join dependencies, respectively. The benefits of normalization are significant. It improves data consistency, simplifies database maintenance, reduces the chances of update anomalies, and optimizes storage space.
Data Modeling Tools Overview
Modern tools simplify and automate data modeling: enabling faster schema design, validation, and integration across platforms. To see how these capabilities are transforming property markets, explore Big Data in Real Estate a strategic overview of how analytics, geospatial data, and predictive modeling are reshaping investment, valuation, and urban planning decisions.
These tools offer version control, collaboration, and integration with various databases and systems.
Are You Preparing for Data Science Jobs? Check Out ACTE’s Data Science Interview Questions and Answers to Boost Your Preparation!
Real-World Data Modeling Example: E-Commerce System
In this project, we are designing a comprehensive data model to manage customer orders and product inventory efficiently. The model includes several key entities: Customers, Products, Orders, OrderItems, and Payments. Each customer has a unique identifier along with their name and email address, allowing us to store essential information for communication and marketing. The Products entity consists of unique product IDs, names, and prices, providing necessary details for inventory management. To understand how these entities scale across distributed systems, explore Exploring the Big Data a foundational guide to Hadoop’s architecture, data handling capabilities, and its role in managing massive datasets across industries. The Orders entity tracks each order’s unique ID and ordering date and associates them with the corresponding customer using a foreign key (Order.CustomerID → Customer.CustomerID). Each order can include multiple products, which we handle through the OrderItem entity. This entity features a composite key made up of OrderID and ProductID, enabling us to manage the many-to-many relationship between orders and products effectively.
Data Modeling for NoSQL Databases
Types of NoSQL Models:
Modeling Guidelines:
Final Tips and Resources
Data modeling is a key skill for anyone working with data. When starting a data modeling project, it’s important to think about the business side and consider scalability from the beginning. Choose the right model type based on the project’s goals to ensure it meets the desired results. Validating your models with sample data and queries is an important step. To master these modeling techniques with hands-on guidance, explore Data Science Training a structured program that teaches learners how to select, test, and optimize models for predictive accuracy and business impact. This helps catch potential issues early and improves the model’s performance. Always keep security and compliance in mind, such as GDPR, to protect sensitive information and follow legal guidelines. For those looking to expand their knowledge, many resources are helpful. Books like “Data Modeling Made Simple” by Steve Hoberman and “The Data Warehouse Toolkit” by Ralph Kimball offer strong foundations.




