
Last updated on 15th Sep 2025| 14892
- Introduction to Process Synchronization
- What is a Semaphore?
- Types of Semaphores: Binary and Counting
- How Semaphores Work – Basic Mechanism
- wait() and signal() Operations Explained
- Implementing Semaphores in Operating Systems
- Semaphore vs Mutex – Key Differences
- Conclusion
Introduction to Process Synchronization
In a multiprogramming or multiprocessing environment, multiple processes may access shared resources such as memory, files, or I/O devices simultaneously. Without proper coordination, this can lead to inconsistent data, race conditions, or even system crashes. Process synchronization ensures that concurrent processes or threads execute in a manner that preserves data consistency and system integrity. Semaphore in Operating System achieve synchronization through various mechanisms, among which semaphores are one of the most important and widely used tools. Process synchronization is a fundamental concept in operating systems that ensures multiple processes or threads can execute concurrently without interfering with each other’s operations or causing inconsistencies in shared data. When multiple processes access and modify shared resources such as variables, files, or memory, synchronization is necessary to prevent race conditions, deadlocks, and Web Designing & Development Training. Synchronization becomes especially important in multi-core and multi-threaded environments, where concurrent processes may try to read and write to the same resource at the same time. Without proper control mechanisms, the system can produce unpredictable results. To handle these challenges, various synchronization techniques are used, including mutexes (mutual exclusion), semaphores, monitors, and locks. These tools help ensure that only one process accesses a critical section of code at a time, thereby preserving data integrity and ensuring system stability. Process synchronization not only improves the correctness of programs but also enhances efficiency, allowing concurrent systems to work smoothly without unnecessary delays or conflicts. It is a key topic in understanding how operating systems manage processes and is essential knowledge for developers working with concurrent or parallel systems.
To Earn Your Web Developer Certification, Gain Insights From Leading Data Science Experts And Advance Your Career With ACTE’s Web Developer Courses Today!
What is a Semaphore?
A semaphore is a synchronization primitive introduced by Edsger Dijkstra in the 1960s to control access to shared resources in concurrent systems. It is a simple integer variable that is accessed only through two atomic operations: wait() (also called P()) and signal() (also called V()). Semaphores help avoid race conditions and are instrumental in managing the critical section problem, GUI Tkinter Module where multiple processes compete for access to shared data.
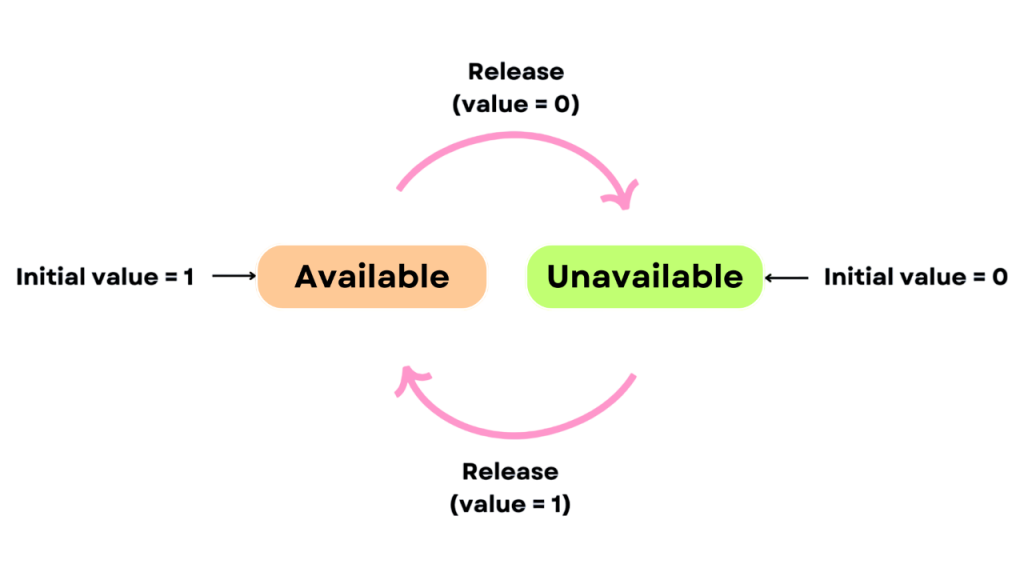
The basic idea is that a semaphore tracks how many units of a resource are available or if a critical section is being used. When a process wants to enter a critical section, it performs a wait operation. If the resource is available, it proceeds; otherwise, it is blocked until a signal is received.There are two main types of semaphores: binary semaphores, which take only two values (0 or 1) and function similarly to a mutex lock; and counting semaphores, which can take non-negative integer values and are useful for managing access to a limited number of identical resources. By using semaphores, operating systems ensure that processes are synchronized effectively, allowing them to share resources safely and efficiently without causing data corruption or unpredictable behavior.
Types of Semaphores: Binary and Counting
Semaphores are generally categorized into two types:
- Binary Semaphore: A binary semaphore can take only two values: 0 and 1. It functions similarly to a mutex (mutual exclusion) and is used to manage access to a single resource or critical section. A value of 1 indicates the resource is free; 0 means it is locked. It is often used to implement mutual exclusion Reverse C++ Vector .
- Counting Semaphore: This type can take non-negative integer values and is useful when multiple instances of a resource are available. For example, if three printers are available, a counting semaphore can be initialized to 3. Each wait() call decreases the count, and each signal() call increases it, allowing up to three processes to access printers concurrently.
These two types of semaphores serve different synchronization needs depending on whether a resource is singular or multiple.
Would You Like to Know More About Web Developer? Sign Up For Our Web Developer Courses Now!
How Semaphores Work – Basic Mechanism
Semaphores operate on a simple mechanism of signaling and waiting:
- Initialization: The semaphore is set to an integer value (e.g., the number of available resources).
- wait(): The process checks the semaphore’s value. If it’s greater than zero, it decrements the value and continues; otherwise, it waits (gets blocked) Data Structures & Algorithms.
- signal(): The semaphore is incremented, and one of the waiting processes (if any) is allowed to proceed.
These operations are atomic, ensuring no two processes can manipulate the semaphore value simultaneously. This atomicity is essential to prevent race conditions.

Develop Your Skills with Web Developer Certification Course
Weekday / Weekend BatchesSee Batch Detailswait() and signal() Operations Explained
The wait() and signal() operations are the core of semaphore functionality:
- while S <= 0:
- S = S – 1
- S = S + 1
wait(S):
signal(S):
In real implementations, blocking and waking up of processes is handled by the OS scheduler. The wait() operation ensures that no process enters the critical section if the semaphore value is 0, maintaining exclusivity Paging in Operating Systems. The signal() operation wakes up one of the blocked processes (if any), allowing it to proceed.
Are You Interested in Learning More About Web Developer? Sign Up For Our Web Developer Courses Today!
Implementing Semaphores in Operating Systems
Implementing semaphores in operating systems is a critical aspect of process synchronization and resource management. Semaphores are typically implemented in the kernel or through system-level libraries to manage access to shared resources such as memory, files, or devices. The core idea is to maintain a counter that reflects the number of available resources or the availability of a critical section. When a process calls the wait() operation, the semaphore checks the counter. If the counter is greater than zero, it is decremented, and the process continues Web Designing & Development Training. If it is zero or less, the process is blocked and added to a waiting queue. When another process calls the signal() operation, the counter is incremented, and if any processes are waiting, one is unblocked. Operating systems must ensure that semaphore operations are atomic meaning they are executed without interruption to prevent race conditions. This is usually achieved using hardware-level instructions such as test-and-set or by disabling interrupts briefly. Semaphores can be either binary or counting, depending on the synchronization needed. They are commonly used in scenarios like managing producer-consumer problems, resource allocation, and handling concurrent processes or threads. Proper implementation ensures system stability, efficiency, and prevents issues like deadlocks and starvation.
Semaphore vs Mutex – Key Differences
While semaphores and mutexes are both synchronization tools, they have key differences:
| Feature | Semaphore | Mutex |
|---|---|---|
| Type | Integer variable | Locking mechanism |
| Ownership | No ownership (any thread can signal) | Owned by the locking thread |
| Types | Binary, Counting | Binary only |
| Usage | Signaling between threads/processes | Exclusive access control |
| Flexibility | Can allow multiple accesses | Only one thread at a time |
Conclusion
A mutex is typically used when only one thread at a time should access a resource, while a semaphore is useful when multiple units of a resource are available or when one thread signals another. Semaphores are low-level synchronization tools used to control access to shared resources in concurrent environments. They come in two main types binary and counting and are controlled via atomic wait() and signal() operations Web Designing & Development Training . Semaphores are powerful enough to solve complex synchronization problems such as producer-consumer and reader-writer but must be used with caution to avoid deadlocks and starvation.Semaphores play a vital role in achieving process synchronization in modern operating systems. By controlling access to shared resources, they help prevent critical issues such as race conditions, deadlocks, and data inconsistency. Whether implemented as binary semaphores for mutual exclusion or counting semaphores for managing multiple instances of a resource, Semaphore in Operating System they provide a robust framework for coordinating concurrent processes and threads. Their atomic nature ensures that only one process can modify the semaphore at a time, maintaining the integrity of the system’s operation. Understanding and correctly implementing semaphores is essential for developers working with multithreaded or parallel systems, where efficient resource management directly impacts performance and stability. From simple synchronization problems like the producer-consumer scenario to more complex task scheduling and inter-process communication, semaphores are a foundational concept in operating system design. In conclusion, semaphores are not just theoretical constructs, they are practical tools that enable smooth and safe multitasking in today’s computing environments. Mastery of this concept is crucial for anyone aiming to build or maintain systems that rely on concurrency, resource sharing, and process coordination.




