
Last updated on 31st Dec 2021| 5412
A Slowly Changing Dimension (SCD) is a dimension that stores and manages both current and historical data over time in a data warehouse.
- Introduction
- Slowly changing dimension
- Types of Slowly changing dimension
- Conclusion
Slowly changing dimension
In data management and data warehousing, a slowly changing dimension (SCD) is a dimension that consists of relatively static data that can change slowly but unexpectedly, rather than on a regular schedule. [1] Some examples of specific slowly changing dimensions are entities in the form of names of geographic locations, customers or products.
Some scenarios can cause referential integrity issues.
For example, the database may contain a fact table that stores sales records. This fact table will be linked to the dimensions via foreign keys. One of these dimensions can contain data about a company’s salespeople: for example, the regional offices they work in. However, salespeople are sometimes transferred from one regional office to another. Historical sales reporting purposes may require keeping records of the fact that a particular sales person was assigned to a particular regional office at an earlier date, whereas that sales person is now assigned to a different regional office. [clarification needed. ,
Tackling these issues includes SCD management practises referred to as Types 0 to 6. Type 6 SCDs are sometimes called hybrid SCDs.
Type 0: retain original
Type 0 dimension attributes never change and are assigned to attributes that have durable values or are described as ‘native’.Example: date of birth, original credit score. Type 0 applies to most date dimension attributes.
- supplier_key supplier_code supplier_name supplier_state
- 123 ABC Acme Supply Company Ca
- In the above example, supplier_code is the natural key and supplier_key is a surrogate key. Technically, the surrogate key is not necessary, as the row will be unique by the natural key (supplier_code).
- supplier_key supplier_code supplier_name supplier_state
- 123 ABC Acme Supply Company IL
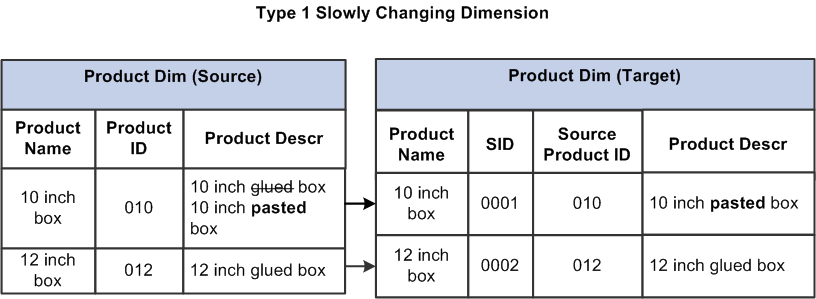
- The disadvantage of the Type 1 method is that there is no history in the data warehouse. However it has the advantage that it is easy to maintain.
- If one has computed an aggregate table summarising facts by supplier state, it will need to be recalculated when supplier_state changes.
Type 1: overwrite
This method overwrites old data with new data, and therefore does not track historical data.
Example of supplier table:
If the supplier moves headquarters to Illinois, the record will be overwritten by:
- supplier_key supplier_code supplier_name supplier_state version
- 123 ABC Acme Supply Company Ca 0
- 124 ABC ACME SUPPLY COMPANY IL 1
- Another way is to add an ‘Effective Date’ column.
- 123 ABC Acme Supply Company CA 2000-01-01T00:00:00 2004-12-22T00:00:00
- 124 ABC ACME SUPPLY COMPANY IL 2004-12-22T00:00:00 NULL
- The start date/time of the second row is equal to the end date/time of the previous row. The null End_Date in line two indicates the current tuple version. Instead a standardised surrogate higher date (such as 9999-12-31) can be used as the end date, so that the field can be included in an index, and so that zero-value replacement is not required when querying Ho.
- supplier_key supplier_code supplier_name supplier_state effective_date current_flag
- 123 ABC Acme Supply Company CA 2000-01-01T00:00:00 N
- 124 ABC ACME SUPPLY COMPANY IL 2004-12-22T00:00:00 Y
- The Current_Flag value of ‘Y’ indicates the current tuple version.
Type 2: add new row
This method tracks historical data by creating multiple records for a given natural key in dimensional tables with different surrogate keys and/or different version numbers. Unlimited history is preserved for each insert.
For example, if the supplier moves to Illinois, the version number will be incremented sequentially:
supplier_key supplier_code supplier_name supplier_state start_date end_date
And the third method uses an effective date and current flag.
Transactions that refer to a particular surrogate key (supplier_key) are then permanently bound to the time slice defined by that row of the slowly changing dimension table. A composite table summarising facts by supplier state showing the historical position, that is, the state the supplier was in at the time of the transaction; No update is required. In order to refer to the entity via the natural key, it is necessary to overcome the unique constraint that makes it impossible by the DBMS.
If changes are made retroactively to the content of the dimension, or if new attributes are added to the dimension (for example the Sales_Rep column) that have different effective dates than those already defined, this may result in the need for existing transactions Updated to reflect new status. This can be an expensive database operation, so a Type 2 SCD is not a good choice if the dimensional model is subject to frequent changes.

Develop Your Skills with Advanced ETL Certification Training
Weekday / Weekend BatchesSee Batch DetailsType 3: add new attribute
This method tracks changes using separate columns and preserves a limited history. Type 3 preserves a limited amount of history because it is limited to the number of columns specified for storing historical data. Type 1 and Type 2 have the same basic table structure but Type 3 adds additional columns. In the following example, an additional column has been added to the table to record the original position of the supplier – only the past history is stored.
Type 4: add history table
The Type 4 method is usually referred to using “history tables”, where one table holds the current data, and an additional table is used to keep a record of some or all of the changes. Both surrogate keys are referenced in the fact table to increase query performance.
Type 5 : Technology build
The Type 5 technology builds on the Type 4 mini-dimension by embedding a “current profile” mini-dimension key in the base dimension which is overwritten as a Type 1 attribute. This approach is called type 5 because 4 + 1 equals 5. Type 5 slowly changing dimensions allows currently assigned mini-dimension attribute values to be accessed with others of the base dimension without being linked via a fact table.
Logically, we usually represent the base dimension and the current mini-dimension profile outrigger as a table in the presentation layer. The outrigger attribute must have distinct column names, such as “current income level”, to distinguish them from the attributes of the mini-dimensions associated with the fact table. Whenever the current mini-dimension changes over time, the ETL team must update/overwrite the Type 1 mini-dimension reference. If the outrigger approach does not provide satisfactory query performance, the mini-dimension attributes can be physically embedded (and updated) in the base dimension.
- 123 1 ABC Acme Supply Company IL CA 2000-01-01T00:00:00 2004-12-22T00:00:00 N
- 123 2 ABC ACME SUPPLY COMPANY IL IL 2004-12-22T00:00:00 9999-12-31T23:59:59 Y
Type 6: combined approach
The type 6 method combines the methods of types 1, 2 and 3 (1 + 2 + 3 = 6). One possible explanation for the origin of the term was that it was coined by Ralph Kimball during a conversation with Stephen Pace of Kaleido [citation needed]. Ralph Kimball in the Data Warehouse Toolkit calls this method “unexpected changes with single-version overlays”.
The supplier table begins with a record for our example supplier: supplier_key row_key supplier_code supplier_name current_state historical_state start_date end date current_flag 123 1 ABC Acme Supply Company CA CA 2000-01-01T00:00:00 9999-12-31T23:59:59 Y Current_state and historical_state are the same. The optional Current_Flag attribute indicates whether this is the current or latest record for this supplier.
When Acme Supply Company moves to Illinois, we add a new record, as in Type 2 processing, although a row key is included to ensure we have a unique key for each row: supplier_key row_key supplier_code supplier_name current_state historical_state start_date end date current_flag
We overwrite the Current_State information in the first record (Row_Key = 1) with the new information, as in type 1 processing. We create a new record to track changes, as in type 2 processing. And we store the history in another state column (Historical_State), which contains type 3 processing.
For example, if the supplier were to be moved again, we would add another record to the supplier dimension, and we would overwrite the contents of the Current_State column:
Type 7: Hybrid[4] – Both surrogate and natural key
An alternative implementation is to place both the surrogate key and the natural key in a fact table. [5] This allows the user to select the appropriate dimension record based on:
the primary effective date on the fact record (above), most recent or current information, Any other date attached to the record of fact.
This method allows for a more flexible link to dimension, even if one used a Type 2 approach rather than a Type 6.
Conclusion
To understand the importance of SCDs, it is best to look at an example. A company that sells cell phones divides devices into 3 categories: high, medium and basic. In this area, technology develops rapidly, so that high-end (for example) terminals may be considered mid-range with the advent of new equipment a few months later.
The company’s ERP transactional system stores the information in a standardised database. On the one hand, we have the “Sales” table, where each transaction is recorded. Another “Products” table contains technical information for the mobile, which includes a field indicating the range.
The marketing department, while loading the data into the data warehouse, needs to know how many cell phones are sold each year in each category. What happens when a cell phone changes range? By modifying this data in the Products table, all your past sales are also changed to the new category, falsifying the information and making it impossible to know this data for sure.




