
Last updated on 18th Sep 2025| 13051
- String Comparison Basics
- Using == and != Operators
- Case Sensitivity in Comparison
- Using str.casefold() and lower()
- Lexicographical Order and >/<
- The cmp() Function (Python 2)
- String Normalization
- Use Cases in Sorting and Matching
- Common Pitfalls
- Examples and Practice Scenarios
- Best Practices
- Summary
String Comparison Basics
String comparison is a fundamental operation in programming, and learning how to Compare Two Strings in Python is an essential skill for developers. In Python, strings can be compared using built-in operators and functions, with support for both simple equality checks and lexicographical ordering. Whether you’re developing a search engine, implementing user authentication, or simply organizing text data, string comparison plays a crucial role. To master these operations across both frontend and backend layers, exploring Full Stack With Python Course reveals how Python’s string handling and comparison logic integrate with React’s dynamic interfaces enabling developers to build secure, efficient, and user-friendly applications with consistent data flow and validation. This guide explores different methods, tools, and best practices to Compare Two Strings in Python effectively. Since Python treats strings as sequences of Unicode characters, comparisons are performed character by character based on Unicode code points.
To Earn Your Full Stack With Python Course Certification, Gain Insights From Leading Web Developer Experts And Advance Your Career With ACTE’s Full Stack With Python Course Today!
Using == and != Operators
The most common way to compare strings in Python is by using the equality (==) and inequality (!=) operators. These operators return Boolean values. To understand how such comparisons fit into broader programming logic, exploring Important Data Structures and Algorithms reveals how string operations interact with lists, trees, and hash maps forming the backbone of search, sort, and validation routines in scalable software development.
- True or False.
- str1 = “Python”
- str2 = “Python”
- str3 = “python”
- print(str1 == str2) # True
- print(str1 != str3) # True
These comparisons are case-sensitive, meaning “Python” and “python” are not equal. These operators are ideal for direct string comparison in conditionals, loops, and logical statements. They are simple to use and preferred when you just want to check for identical content.
Case Sensitivity in Comparison
By default, string comparison in Python is case-sensitive. This means that uppercase and lowercase letters are treated as different. While this behavior is useful in some contexts like password validation or security, it can cause problems when your logic expects a case-insensitive comparison.
- a = “Apple”
- b = “apple”
- print(a == b) # False
To perform a case-insensitive comparison, you need to standardize the case of both strings before comparing them.
Would You Like to Know More About Full Stack With Python Course? Sign Up For Our Full Stack With Python Course Now!
Using str.casefold() and lower()
To deal with case sensitivity, Python provides string methods like lower() and casefold() to convert strings to a uniform case. To understand how such normalization techniques apply to data exchange protocols, exploring Soap vs Rest reveals how REST typically handles text-based payloads with flexible formatting, while SOAP enforces stricter schema validation making case handling and data consistency crucial when designing interoperable APIs.
lower()
- a = “Hello”
- b = “hello”
- print(a.lower() == b.lower()) # True
However, lower() is not suitable for internationalized or accented characters.
casefold()
casefold() is more powerful than lower() and is recommended for international and multilingual text. It’s a more aggressive method of converting characters to lowercase, designed for caseless comparison.
- a = “straße”
- b = “STRASSE”
- print(a.casefold() == b.casefold()) # True
In most practical applications involving user input or multilingual data, using casefold() ensures more accurate results.

Develop Your Skills with Full Stack With Python Course Certification Course
Weekday / Weekend BatchesSee Batch DetailsLexicographical Order and > / < Operators
Low-code and no-code platforms like OutSystems, Mendix, and Bubble are designed to simplify application development, allowing users with minimal coding knowledge to build software using visual interfaces. These platforms are often powered by AI-driven recommendations and automation features. However, while they reduce the need for manual coding in specific use cases (e.g., internal tools, small-scale apps), they are not a substitute for traditional software engineering when it comes to performance, security, and scalability. To build resilient systems that go beyond low-code limitations, exploring Full Stack With Python Course reveals how mastering Python for backend logic and React for frontend design equips developers to create robust, scalable applications that meet enterprise-grade standards = Skilled developers are still needed to extend these platforms or work on more complex custom solutions.
- < (less than)
- > (greater than)
- <= (less than or equal to)
- >= (greater than or equal to)
These comparisons evaluate character by character using Unicode code points.
- print(“apple” < “banana”) # True
- print(“dog” > “cat”) # True
- Note that uppercase letters come before lowercase letters in Unicode, so:
- print(“Zebra” < “apple”) # True
This behavior can cause unexpected results if you don’t normalize case or pre-process strings before comparison. Lexicographical comparison is commonly used in sorting algorithms, filtering operations, and alphabetical ordering.
The cmp() Function (Python 2 Only)
In Python 2, the built-in cmp() function was used to compare strings. To experiment with such legacy functions and modern alternatives, exploring Python IDEs and Code Editors reveals how tools like PyCharm, VS Code, and Thonny provide intelligent suggestions, debugging support, and version compatibility making it easier for developers to write, test, and transition between Python versions with confidence.
- cmp(“a”, “b”) # Returns -1 (a < b)
- cmp(“a”, “a”) # Returns 0 (equal)
- cmp(“b”, “a”) # Returns 1 (b > a)
- def cmp(a, b):
- return (a > b) – (a < b)
However, cmp() is removed in Python 3, as the language design moved toward using comparison operators directly (<, ==, etc.) for clarity and simplicity. While the function is rarely needed in modern Python, it may be useful when porting old Python 2 code or implementing custom sort logic.
Are You Interested in Learning More About Full Stack With Python Course? Sign Up For Our Full Stack With Python Course Today!
String Normalization
When comparing strings that contain accented characters, ligatures, or visually similar Unicode forms, string normalization is essential. Python’s unicodedata module provides tools to normalize Unicode strings into a standard format.
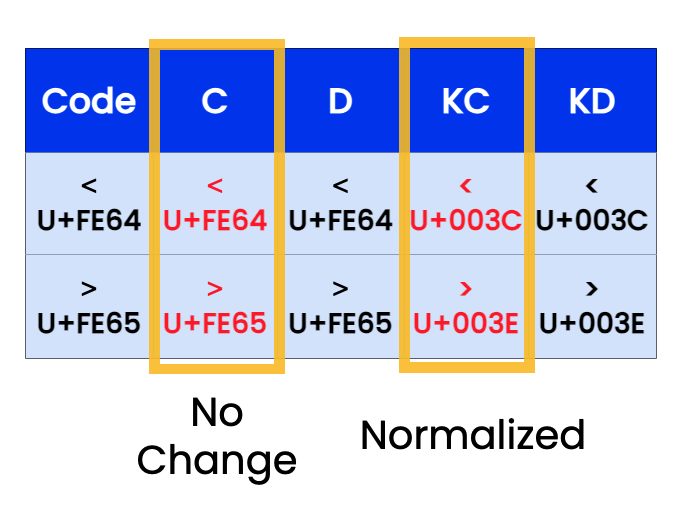
There are four normalization forms: NFC, NFD, NFKC, NFKD. To explore how different languages handle Unicode and text processing, exploring Go Programming Language reveals how Go approaches string comparison with simplicity and performance offering built-in Unicode support and efficient handling of byte-level operations for scalable applications.
- import unicodedata
- s1 = “café”
- s2 = “cafe\u0301” # ‘e’ with an accent as a separate code point
- print(s1 == s2) # False
- # Normalize before comparing
- s1_norm = unicodedata.normalize(‘NFC’, s1)
- s2_norm = unicodedata.normalize(‘NFC’, s2)
- print(s1_norm == s2_norm) # True
Normalization is vital in systems that interact with user data from different languages and character encodings especially databases, APIs, and document management systems.
Preparing for Full Stack With Python Job Interviews? Have a Look at Our Blog on Full Stack With Python Interview Questions and Answers To Ace Your Interview!
Use Cases in Sorting and Matching
Alphabetical Sorting
Python’s sorted() or list.sort() uses lexicographical order. To sort strings case-insensitively, you can pass a key function like str.lower or str.casefold to normalize the case before comparison. To understand how such sorting logic operates within different variable contexts, exploring Python Scopes and Their Built-in Functions reveals how scope rules influence function behavior, variable access, and sorting outcomes empowering developers to write cleaner, context-aware code across modules and functions.
- strings case-insensitively:
- words = [“banana”, “Apple”, “cherry”]
- print(sorted(words)) # Case-sensitive
- print(sorted(words, key=str.casefold)) # Case-insensitive
Matching User Input
- input_user = “ADMIN”
- expected = “admin”
- if input_user.casefold() == expected.casefold():
- print(“Access granted”)
Consider a login system where “Admin”, “ADMIN”, and “admin” should be treated equally:
Search and Filtering
- keyword = “Data”
- documents = [“Big Data”, “Database”, “metadata”, “Machine Learning”]
- matches = [doc for doc in documents if keyword.lower() in doc.lower()]
- print(matches)
Matching patterns with consistent cases helps retrieve more accurate and complete results.
Common Pitfalls
- Ignoring Case Sensitivity: Assuming “Python” == “python” will return True. Always standardize case before comparing user input, file names, or database fields.
- Neglecting Unicode Normalization: Visually identical characters may be stored in different Unicode forms. Normalize strings when handling external or user-generated content.
- Confusion with is Operator: Use == for content comparison. The is operator checks identity (same object in memory), not equality.
- Comparison with Non-Strings: Comparing a string with a non-string type will return False or raise a TypeError when using relational operators.
Examples and Practice Scenarios
Example 1: Case-Insensitive Comparison
- def compare_case_insensitive(a, b):
- return a.casefold() == b.casefold()
- print(compare_case_insensitive(“HELLO”, “hello”)) # True
Example 2: Sorting List Alphabetically
- names = [“Alice”, “bob”, “charlie”, “Bob”]
- sorted_names = sorted(names, key=str.lower)
- print(sorted_names) # [‘Alice’, ‘bob’, ‘Bob’, ‘charlie’]
Example 3: Detecting Duplicates in a List
- words = [“Data”, “data”, “DATA”, “Analytics”]
- unique = set()
- for word in words:
- normalized = word.casefold()
- if normalized in unique:
- print(f”Duplicate: {word}”)
- else:
- unique.add(normalized)
Example 4: Normalized Comparison of Accented Text
- import unicodedata
- def normalize_and_compare(a, b):
- a_norm = unicodedata.normalize(‘NFC’, a)
- b_norm = unicodedata.normalize(‘NFC’, b)
- return a_norm == b_norm
- print(normalize_and_compare(“café”, “cafe\u0301”)) # True
Best Practices
- Use == and != for direct comparison, but remember they are case-sensitive.
- Apply casefold() for robust case-insensitive comparison.
- Normalize Unicode strings when dealing with international text.
- Use sorted() with key=str.casefold for case-insensitive alphabetical sorting.
- Avoid is operator for string comparison, it checks identity, not content.
- Validate input types to ensure you’re not comparing strings with numbers or other types.
- Leverage unicodedata.normalize() in multilingual applications and search engines.
- Encapsulate comparison logic into reusable functions when handling repetitive string checks.
- Log mismatches or debug failures by printing normalized, lowercased, or transformed versions of strings.
- When using user input, sanitize it with trimming, lowercasing, and normalization before any comparison.
Summary
Compare Two Strings in Python is a nuanced task that goes beyond simply using the == operator. From handling case differences with casefold() to normalizing Unicode characters with unicodedata, Python provides robust tools for accurate string comparison. Understanding how relational operators work with lexicographical ordering helps in tasks like sorting and filtering. To apply these string operations in full-stack development, exploring Full Stack With Python Course reveals how Python’s backend capabilities integrate with frontend frameworks like React enabling developers to build responsive applications that rely on precise data handling, efficient filtering, and seamless user interactions. In practice, learning when and how to Compare Two Strings in Python prevents subtle bugs, such as those caused by misusing is, ignoring normalization, or comparing incompatible types. Whether you’re building a chatbot, search engine, or authentication system, efficient and reliable string comparison ensures better user experiences.




