
Last updated on 12th Sep 2025| 12293
- Introduction to Compiler Design
- What is Syntax Analysis?
- Role of Syntax Analyzer (Parser)
- Difference Between Syntax and Lexical Analysis
- Types of Parsers: Top-Down and Bottom-Up
- Context-Free Grammars (CFGs) and Parse Trees
- LL(1) Parsing – Theory and Example
- Conclusion
Introduction to Compiler Design
Syntax Analysis in Compiler Design is a fundamental area of computer science that deals with converting high-level programming languages into machine-understandable code. A compiler processes source code through multiple phases such as lexical analysis, syntax analysis, semantic analysis, intermediate code generation, optimization, and final code generation. Among these phases, syntax analysis plays a crucial role in ensuring that the program’s structure aligns with the rules of the language’s grammar. To complement such grammar-driven validation with practical interface design skills, exploring Web Designing & Development Training equips learners with hands-on experience in HTML, CSS, JavaScript, and UI/UX principles empowering them to build visually structured, user-friendly applications that adhere to both design and development standards. Compiler design is a fundamental area of computer science that deals with the translation of high-level programming languages into machine code. A compiler is a specialized software program that reads source code written in languages like C, Java, or Python, and translates it into a lower-level language, typically assembly or machine code, which can be understood and executed by the computer’s hardware. The process of compilation involves several distinct phases: lexical analysis, syntax analysis, semantic analysis, intermediate code generation, optimization, and code generation. Each phase plays a critical role in ensuring that the source code is both syntactically correct and efficient in execution. Understanding compiler design helps developers appreciate how programming languages work under the hood and how code is transformed into something the computer can execute.
To Earn Your Web Developer Certification, Gain Insights From Leading Data Science Experts And Advance Your Career With ACTE’s Web Developer Courses Today!
What is Syntax Analysis?
Syntax Analysis, also known as parsing, is the second phase of the compilation process. After lexical analysis breaks the code into tokens, syntax analysis takes these tokens and organizes them into a hierarchical structure called a parse tree or syntax tree, which represents the grammatical structure of the source program. Syntax Analysis in Compiler Design, also known as parsing, is a critical phase in the compiler design process that checks the structure of the source code based on the grammar of the programming language. To complement such structural validation with process-level reliability, exploring What is Quality Assurance highlights how systematic methodologies, standards, and preventive strategies ensure that software products meet defined quality benchmarks focusing not only on output correctness but also on the integrity of the development lifecycle itself.
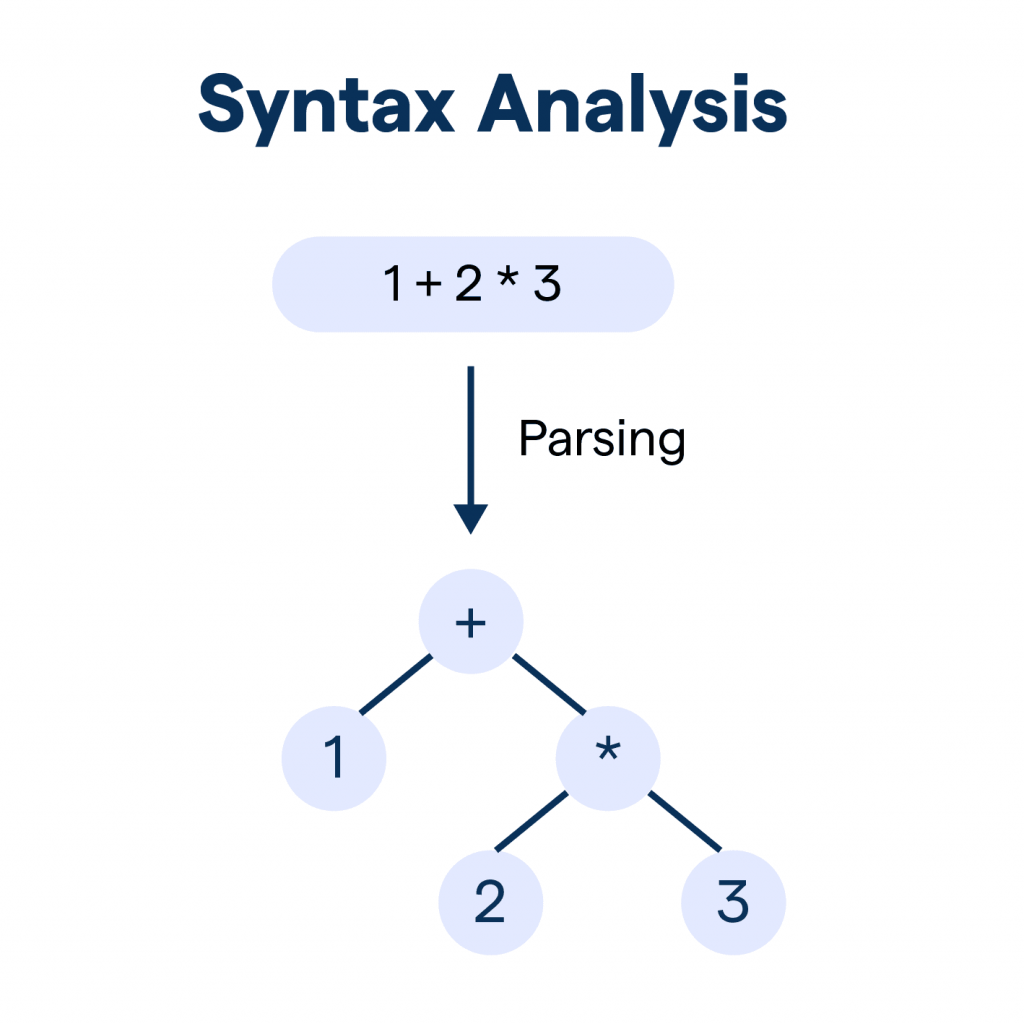
After the lexical analysis phase breaks the code into tokens (such as keywords, identifiers, symbols, etc.), syntax analysis takes these tokens and organizes them into a parse tree or syntax tree. This tree represents the grammatical structure of the program, ensuring that the source code follows the correct syntax rules. The main goal of syntax analysis is to determine whether a given input string (a sequence of tokens) adheres to the grammar of the programming language. If it does, a parse tree is generated; if not, syntax errors are reported.
Role of Syntax Analyzer (Parser)
- Checks the syntactic structure of the source code based on the grammar of the programming language.
- Generates a parse tree or abstract syntax tree (AST) to represent the hierarchical structure of the code.
- Detects and reports syntax errors (e.g., missing semicolons, unmatched parentheses, incorrect nesting).
- Ensures correct order and nesting of tokens produced by the lexical analyzer. To complement such structural validation in compiler design with performance resilience, exploring What is Spike Testing reveals how software systems respond to sudden surges and drops in user load evaluating recovery time, and system stability.
- Provides input to the semantic analyzer for further meaning-based validation of the code.
- Supports error recovery, allowing compilation to continue even after encountering syntax errors.
- Bridges the gap between lexical analysis and semantic analysis, forming a critical middle step in compilation.
- Converts the raw source code into tokens (basic units like keywords, identifiers, symbols).
- Works on the character stream of the source code. To complement such low-level lexical analysis with robust application infrastructure, exploring What is .Net FrameWork reveals how Microsoft’s development platform provides tools, libraries, and runtime support for building secure.
- Detects lexical errors such as invalid characters or unknown tokens.
- Uses techniques like finite automata and regular expressions.
- Outputs a stream of tokens to the syntax analyzer.
- Is the first phase of the compiler.
- Takes tokens from lexical analysis and checks their arrangement according to grammar rules.
- Works on the stream of tokens.
- Detects syntax errors such as incorrect statement structure or misplaced tokens.
- Uses context-free grammars and parsing algorithms (like LL, LR parsing).
- Produces a parse tree or abstract syntax tree (AST) representing the program structure.
- Is the second phase of the compiler.
- starts from the highest-level rule (start symbol) and breaks it down recursively.
- Often implemented using recursive descent parsing or predictive parsing.
- Uses a lookahead token to decide which production rule to apply next (in predictive parsers).
- Simple to implement but may struggle with left-recursive grammars (which cause infinite recursion).
- Suitable for LL(k) grammars, where parsing decisions are made looking ahead k tokens. Errors can be detected early during parsing.
- Start with the input tokens and work towards the start symbol by applying reductions. Use techniques like Shift-Reduce Parsing.
- Common types include LR parsers (Left-to-right scanning, Rightmost derivation in reverse), such as SLR, LALR, and Canonical LR parsers.
- Can handle a larger class of grammars compared to top-down parsers, including left-recursive grammars.
- A Context-Free Grammar is a formal grammar used to define the syntax of programming languages. To complement such structural syntax rules with data persistence techniques, exploring Python Serialization reveals how objects can be converted into storable formats using modules like `pickle`, `json`, and `marshal` enabling seamless data saving, transmission, and reconstruction across sessions and systems.
- It consists of four components: a set of non-terminal symbols, terminal symbols, production rules, and a start symbol.
- Production rules specify how non-terminals can be replaced by sequences of terminals and/or non-terminals.
- CFGs are powerful enough to describe nested and recursive language structures, such as balanced parentheses and conditional statements.
- They form the theoretical basis for most programming language syntax definitions and parsing algorithms.
- A Parse Tree is a tree representation that shows how a string (program code) is derived from a CFG.
- The root of the parse tree is the start symbol of the grammar.
- Internal nodes represent non-terminal symbols, while leaves represent terminal symbols (tokens).
- The tree visually illustrates the hierarchical structure of the source code according to the grammar rules.
- Parse trees are used by compilers during syntax analysis to verify correct program structure and aid in later stages like semantic analysis.
- Construct First and Follow sets.
- Build the parsing table.
- Use a stack and input buffer for derivation.
- cE → TE’
- E’ → +TE’ | ε
- T → FT’
- T’ → *FT’ | ε
- F → (E) | id
Would You Like to Know More About Web Developer? Sign Up For Our Web Developer Courses Now!
Difference Between Syntax and Lexical Analysis
Lexical Analysis:
Syntax Analysis:

Develop Your Skills with Web Developer Certification Course
Weekday / Weekend BatchesSee Batch DetailsTypes of Parsers: Top-Down and Bottom-Up
Parsers are broadly categorized into two types: top-down and bottom-up, each with distinct strategies for analyzing syntax trees. To complement such parsing techniques with practical front-end development skills, exploring Web Designing & Development Training equips learners with hands-on experience in HTML, CSS, JavaScript, and UI/UX design empowering them to build visually structured, standards-compliant web applications that align with both design logic and semantic correctness.
Top-Down Parsers:
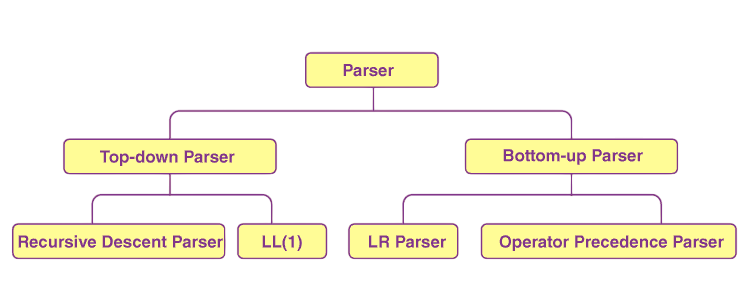
Bottom-Up Parsers:
Are You Interested in Learning More About Web Developer? Sign Up For Our Web Developer Courses Today!
Context-Free Grammars (CFGs) and Parse Trees
Context-Free Grammars
Parse Trees
LL(1) Parsing – Theory and Example
LL(1) Parser is a type of top-down parser that parses input from Left to right and constructs a Leftmost derivation using 1 lookahead symbol. To complement such predictive parsing strategies with clean output generation, exploring Python String Formatting introduces formatting empowering developers to produce readable, dynamic text output that aligns with syntactic structure and runtime data. LL(1) parsing is a top-down parsing technique used to analyze a subset of context-free grammars known as LL(1) grammars. The term “LL(1)” indicates that the parser reads the input from Left to right, produces a Leftmost derivation, and uses 1 lookahead token to decide which production rule to apply.
Steps in LL(1) Parsing:
Example:
LL(1) parsing uses lookahead to decide which production to apply. The parsing table helps direct parsing decisions efficiently.
Conclusion
In conclusion, LL(1) parsing is a fundamental and efficient top-down parsing technique that provides a clear and deterministic method for Syntax Analysis in Compiler Design of suitable grammars. By leveraging a single lookahead token and predictive parsing strategies, Role of Syntax Analyzer enables fast and accurate parsing without backtracking. While its application is limited to grammars free of left recursion and ambiguity, LL(1) parsing remains a popular choice in compiler design due to its simplicity and ease of implementation. To complement such parsing precision with practical interface development, exploring Web Designing & Development Training equips learners with hands-on skills in HTML, CSS, JavaScript, and UI/UX design empowering them to build visually structured, standards-compliant web applications that align with both semantic logic and user experience. Understanding LL(1) parsing lays a strong foundation for exploring more advanced parsing techniques and deepening one’s grasp of compiler construction.




