
Last updated on 12th Aug 2025| 12683
- Introduction to Machine Learning Paradigms
- Overview of Supervised Learning
- Overview of Unsupervised Learning
- Overview of Reinforcement Learning
- Key Differences and Examples
- Use Case Scenarios
- Strengths and Weaknesses
- Algorithms in Each Category
- Conclusion
Introduction to Machine Learning Paradigms
Machine Learning Training (ML) is the science of enabling computers to learn from data and make predictions or decisions without being explicitly programmed. ML has revolutionized industries from healthcare to finance, enabling innovations like self-driving cars, real-time translations, fraud detection, and personalized recommendations. At the core of ML are three main paradigms: Supervised, Unsupervised, and Reinforcement . Each of these paradigms solves different kinds of problems, uses different data types, and has its own set of algorithms, strengths, and limitations. Understanding these paradigms is essential for selecting the appropriate approach to a problem and building effective ML systems.Machine learning paradigms refer to the different approaches and methodologies used to teach computers how to learn from data and make decisions or predictions. The most common paradigms include supervised learning, where models are trained on labeled data; unsupervised learning, which involves finding hidden patterns in unlabeled data; and reinforcement learning, where agents learn by interacting with an environment to maximize cumulative rewards. Each paradigm serves unique purposes and is suited for various tasks, making it essential for practitioners to understand their differences and applications to select the right approach for a given problem.
Ready to Get Certified in Machine Learning? Explore the Program Now Machine Learning Online Training Offered By ACTE Right Now!
Overview of Supervised Learning
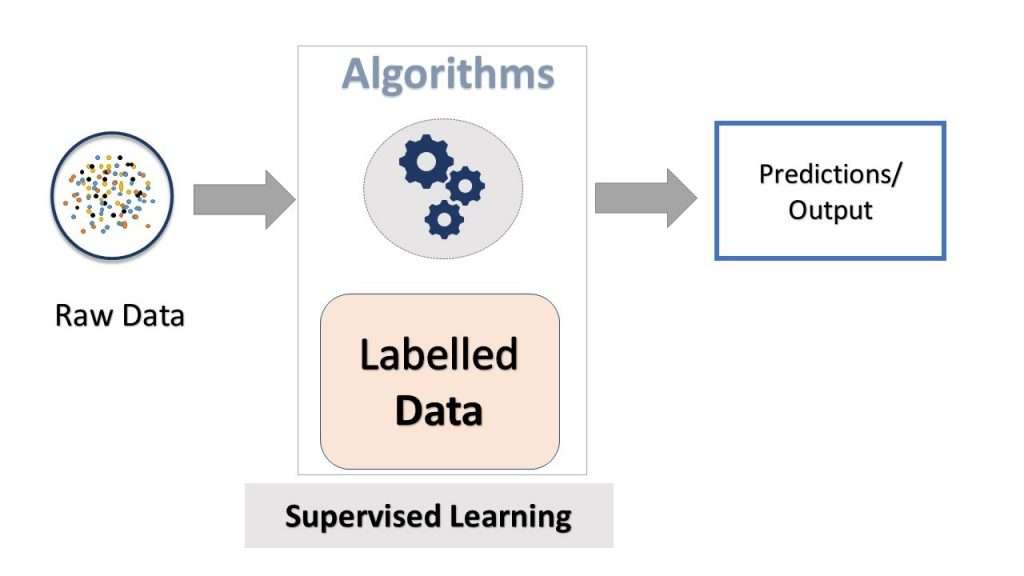
Overview of Supervised learning is the most commonly used ML paradigm insert this line only Decision Trees in Machine Learning. In this setting, the model learns from labeled data, meaning that for each input, the correct output (target) is known.
- Supervised learning involves training a model on a labeled dataset, where each input has a corresponding correct output.
- The goal is for the model to learn a mapping from inputs to outputs to make accurate predictions on new, unseen data.
- Common tasks include classification (categorizing data) and regression (predicting continuous values).
- Examples of algorithms: Decision Trees, Support Vector Machines, and Neural Networks.
- Widely used in applications like spam detection, image recognition, and medical diagnosis.
Overview of Unsupervised Learning
Overview Of Unsupervised learning deals with unlabeled data, where the system attempts to discover hidden patterns or intrinsic structures without predefined targets.
- Unsupervised learning deals with unlabeled data, where the model tries to identify hidden patterns or structures without predefined outputs.
- The main goal is to explore the data and group similar data points or reduce dimensionality.
- Common tasks include clustering (grouping similar items) and dimensionality reduction (simplifying data while preserving important information) Data Science Career Path.
- Popular algorithms: K-Means clustering, Hierarchical clustering, and Principal Component Analysis (PCA).
- Used in applications like customer segmentation, anomaly detection, and data visualization.
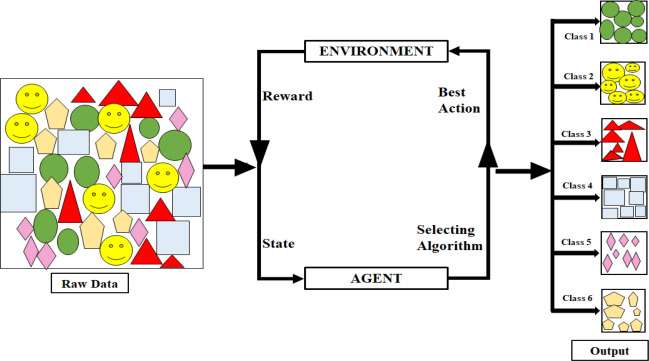
- Reinforcement Learning (RL) is a paradigm where an agent learns to make decisions by interacting with an environment.
- The agent takes actions and receives feedback in the form of rewards or penalties, aiming to maximize cumulative reward over time.
- Unlike Overview of supervised learning, RL learns through trial and error without explicit input-output pairs.
- Key components include the agent, environment, actions, states, and reward signals.
- Common applications: robotics, game playing (e.g., AlphaGo), and autonomous vehicles.
- Healthcare: Predicting disease from symptoms or scans.
- Finance: Credit scoring and risk assessment.
- Marketing: Lead scoring and conversion prediction.
- Retail: Demand forecasting and product recommendation.
- Customer Segmentation: Grouping customers for targeted marketing.
- Document Clustering: Organizing documents by topics.
- Data Compression: Reducing the dimensionality of datasets.
- Anomaly Detection: Identifying unusual transactions in finance.
- Robotics: Learning walking or grasping behaviors.
- Autonomous Vehicles: Navigation and control policies.
- Finance: Algorithmic trading strategies.
- Games: AI playing complex games like Chess and StarCraft.
- High accuracy when data is clean and labeled.
- Extensive theoretical and practical support.
- Easy to evaluate and interpret. Cons
- Requires large volumes of labeled data.
- Prone to overfitting on small datasets.
- Limited to predefined tasks.
- No need for labeled data (cost-effective).
- Reveals hidden patterns and structures.
- Useful for preprocessing and feature engineering. Cons
- Difficult to evaluate performance objectively.
- Results may be less interpretable.
- Sensitive to parameter choices and initial conditions.
- Can learn complex behaviors from simple feedback.
- Effective in dynamic, sequential environments.
- Mimics human learning through experience. Cons
- Sample inefficiency (needs many trials).
- High variance and unstable training.
- Requires well-designed reward functions and environments.
To Explore Machine Learning in Depth, Check Out Our Comprehensive Machine Learning Online Training To Gain Insights From Our Experts!
Overview of Reinforcement Learning
Reinforcement Learning (RL) is a distinct paradigm where an agent learns to take actions in an environment to maximize cumulative reward. Unlike supervised learning,predictions it does not rely on labeled data but on feedback from the environment.

Key Differences and Examples
Key Difference Supervised, Unsupervised, and Reinforcement
| Feature | Supervised Learning | Unsupervised Learning | Reinforcement Learning |
|---|---|---|---|
| Data | Labeled | Unlabeled | No labels; feedback via reward |
| Goal | Predict output | Discover structure | Maximize reward |
| Output | Classes or values | Clusters, reduced dimensions | Action policy |
| Learning Process | Direct from examples | From data features | Trial and error |
Looking to Master Machine Learning? Discover the Machine Learning Expert Masters Program Training Course Available at ACTE Now!
Use Case Scenarios
Supervised Learning Use Cases
Unsupervised Learning Use Cases
Reinforcement Learning Use Cases
Strengths and Weaknesses
Supervised Learning
- Pros
Unsupervised Learning
ProsReinforcement Learning
ProsAlgorithms in Each Category
| Paradigm | Algorithms |
|---|---|
| Supervised | Linear/Logistic Regression, SVM, Random Forest, XGBoost, CNN, RNN |
| Unsupervised | k-Means, Hierarchical Clustering, PCA, Autoencoders, DBSCAN |
| Reinforcement | Q-Learning, DQN, PPO, A3C, REINFORCE, Actor-Critic |
Preparing for Machine Learning Job Interviews? Have a Look at Our Blog on Machine Learning Interview Questions and Answers To Ace Your Interview!
Conclusion
Machine learning paradigms Overview of supervised Learning, unsupervised, and reinforcement learning form the foundation for developing intelligent systems capable of handling a wide range of tasks. Supervised learning excels when labeled data is available, allowing models to learn direct mappings between inputs and desired outputs. This paradigm Supervised, Unsupervised, and Reinforcement is widely applied in classification and regression problems, enabling advancements in fields like predictions healthcare, finance, and image recognition. Unsupervised learning, on the other hand, operates without labeled data, focusing on discovering hidden structures and patterns within datasets. It is particularly useful in clustering, anomaly detection, and dimensionality reduction, helping organizations make sense of vast and complex data. Reinforcement learning introduces a dynamic framework where an agent learns optimal behaviors by interacting with its environment and receiving feedback through rewards or penalties. This trial-and-error approach has powered breakthroughs in robotics, game playing, and autonomous systems. By understanding the strengths and limitations of each paradigm, practitioners can tailor Machine Learning Training solutions to specific challenges and data types. The continual evolution of these paradigms drives innovation across industries, pushing the boundaries of what intelligent machines can achieve. A solid grasp of these core concepts is crucial for anyone looking to harness the power of machine learning effectively.




