
Last updated on 27th May 2025| 8757
- Introduction to the Data Science Life Cycle
- Importance of a Structured Data Science Process
- Problem Definition and Business Understanding
- Data Collection and Preprocessing
- Data Exploration and Analysis
- Feature Engineering and Data Transformation
- Model Building and Evaluation
- Model Deployment and Monitoring
- Best Practices for Each Stage of the Data Science Process
- Common Challenges in the Data Science Life Cycle
- Tools Used in Each Stage of Data Science
- Future Enhancements in Data Science Workflows
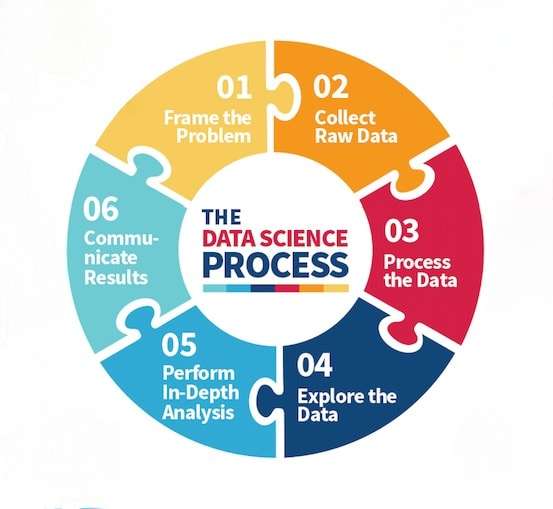
Introduction to the Data Science Life Cycle
The Data Science Life Cycle is a structured framework designed to address data-driven challenges with efficiency, accuracy, and scalability in decision-making. It comprises several key stages, each critical to transforming raw data into meaningful insights and actionable outcomes. This methodical, iterative process allows data scientists to build and refine predictive models based on real-world feedback, ensuring their relevance and effectiveness over time. By integrating statistical analysis, machine learning, and domain knowledge, the life cycle delivers robust solutions to complex problems. For professionals aiming to succeed in this evolving field, a strong grasp of the entire life cycle is essential. Engaging in Data Science Training can provide the foundational understanding and practical expertise needed to navigate these stages effectively and drive impactful business results, ultimately enabling organizations to harness the full potential of their data.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Importance of a Structured Data Science Process
A structured data science process ensures that projects remain organized and efficient. Without a clear framework, projects can become chaotic, leading to inaccurate predictions and wasted resources. Here are some key reasons why a structured data science process is important:
- Improves Collaboration: Teams can work cohesively when they follow a standardized approach.
- Enhances Accuracy: A systematic process reduces errors and ensures high-quality models.
- Optimizes Resource Utilization: A well-defined workflow helps in effectively managing time and computational resources.
- Facilitates Model Scalability: A structured process ensures that models can be easily updated and deployed.
Problem Definition and Business Understanding
Before any data is collected or analyzed, it is crucial to develop a thorough understanding of the business problem. This foundational step sets the direction for the entire data science project and ensures that all efforts are aligned with the organization’s goals. The process starts by defining project objectives and identifying key performance indicators (KPIs) to serve as measurable metrics for success, providing clarity and focus throughout the initiative. Key activities include identifying relevant stakeholders and understanding their unique needs and expectations to ensure alignment. A well-defined problem statement is also essential, as it clearly outlines the issue to be solved and sets the scope for the project. For many considering the field, understanding this strategic phase underscores why Data Science a Good Career choice it involves not only technical skill but also impactful decision-making aligned with business value. Establishing success criteria helps evaluate the effectiveness of the solution and ensures alignment with broader objectives. It’s also important to recognize constraints such as budget, timelines, and data availability early in the process, as these influence the selection of tools and methods. With a comprehensive grasp of the business problem, stakeholder expectations, and operational limitations, teams are better positioned to make informed decisions and drive meaningful outcomes throughout the data science project.
Data Collection and Preprocessing
Data collection is the foundation of any data science project. In this step, relevant data is gathered from various sources, including databases, APIs, and third-party datasets. Common data sources include:
- Structured data from relational databases
- Unstructured data from social media, images, and text documents
- Real-time data from sensors and IoT devices
- Handling missing values
- Removing duplicates
- Normalizing and standardizing data
- Encoding categorical variables
Once the data is collected, preprocessing is performed to clean and transform it into a usable format. Key preprocessing tasks include:
Data Exploration and Analysis
Exploratory Data Analysis (EDA) is a vital step in the data science process where data scientists delve into datasets to uncover hidden patterns, trends, and anomalies that may not be immediately visible. This phase is crucial for developing a deeper understanding of the data and shaping the direction of subsequent analytical steps. A key part of EDA involves visualizing variable distributions using tools like histograms, box plots, and scatter plots, which help illustrate data spread, central tendencies, and relationships. In addition to visual exploration, identifying correlations between variables enables more informed decisions around feature selection and model development. As data scientists perform these tasks, they often reflect on broader academic and career comparisons, such as Data Science vs Computer Science to better understand the unique focus and skill sets required in each domain. Detecting outliers and anomalies is another essential component, as these irregularities can distort results and affect model performance. EDA also includes summarizing statistical metrics like mean, median, and standard deviation to highlight key characteristics of the data. By applying these techniques, EDA equips data scientists to engineer and select meaningful features and choose suitable models, ensuring more accurate, insightful, and effective analysis.

Feature Engineering and Data Transformation
Feature engineering involves selecting and transforming variables to improve model performance. This process includes:
- Creating new features based on domain knowledge
- Transforming variables using logarithmic scaling, polynomial transformations, or binning
- Reducing dimensionality using techniques like Principal Component Analysis (PCA)
- Encoding categorical variables with one-hot encoding or label encoding
High-quality features significantly impact the accuracy of machine learning models.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Model Building and Evaluation
Model building is the heart of the data science life cycle, where data scientists select suitable algorithms, train models, and evaluate their performance to generate meaningful results. The process begins by splitting the dataset into training and testing sets, ensuring the model is trained on one subset and validated on an unseen subset to promote generalization and avoid overfitting. Once the data is prepared, the next step is choosing the most appropriate machine learning models for the task, which could include decision trees, neural networks, or support vector machines depending on the problem. Gaining a solid understanding of these techniques and their practical application is often achieved through Data Science Training which equips professionals with the skills needed to navigate each stage effectively. After selecting a model, it is trained using the training data to identify patterns and relationships, followed by performance evaluation using metrics such as accuracy, precision, recall, and F1-score. To further refine the model, hyperparameter tuning methods like grid search and random search are applied, ultimately ensuring the final solution is both effective and optimized for the task at hand.
Model Deployment and Monitoring
Once a model is trained and evaluated, it is deployed into a production environment. Deployment involves:
- Packaging models as APIs
- Integrating models into web applications or cloud platforms
- Automating model inference with real-time data
Monitoring is essential to ensure that models perform well in a real-world environment. Performance metrics are tracked, and models are retrained as necessary to maintain accuracy.
Best Practices for Each Stage of the Data Science Process
Defining clear objectives is the first and most crucial step in the data science process. Before diving into data collection or analysis, it’s essential to develop a thorough understanding of the business problem to establish a clear project direction and identify relevant goals and success metrics. Once objectives are set, working with high-quality data becomes critical. The data must be meticulously cleaned and preprocessed to eliminate noise and inconsistencies that could compromise model accuracy. Reliable data forms the foundation for meaningful analysis. Following this, Exploratory Data Analysis (EDA) helps uncover patterns, relationships, and anomalies that inform the modeling approach. At this stage, feature selection becomes essential, as focusing on the most relevant variables can enhance model accuracy and reduce complexity. While navigating these steps, many professionals often explore topics like Data Mining vs Data Science to understand the distinctions and overlaps between these related fields, particularly in terms of methods and applications. Once a model is selected, hyperparameter tuning using techniques like grid search or random search further optimizes performance. Continuous monitoring after deployment is equally important, ensuring that any decline in model accuracy is promptly addressed through retraining with updated data, thus keeping the model aligned with evolving business goals.
Common Challenges in the Data Science Life Cycle
Data science projects often face challenges such as:
- Data Availability Issues: Lack of sufficient data can hinder model training.
- Data Quality Problems: Noisy, incomplete, or inconsistent data can impact model accuracy.
- Computational Limitations: Processing large datasets requires powerful infrastructure.
- Model Interpretability: Complex models like deep learning lack transparency.
- Ethical Concerns: Bias in data can lead to unfair predictions.
Tools Used in Each Stage of Data Science
A wide range of tools and technologies are employed throughout the data science workflow to streamline and optimize each phase of the process. In the data collection phase, tools like SQL, APIs, and web scraping libraries such as BeautifulSoup and Scrapy are commonly used to gather raw data from databases, external services, or websites. Once the data is collected, preprocessing is carried out using tools like Pandas and NumPy for manipulation and analysis, along with OpenRefine for cleaning and transforming data into a usable format. The next step, Exploratory Data Analysis (EDA), involves visualization tools such as Matplotlib, Seaborn, and Plotly to uncover patterns and anomalies within the data. For feature engineering, libraries like Scikit-learn and Featuretools help create and select the most impactful features to boost model performance. As model building begins, frameworks such as Scikit-learn, TensorFlow, and PyTorch are used to develop and train a wide range of machine learning models. Amidst these advancements, many professionals explore the Data Science Scope in India recognizing the growing demand for skilled experts and the expanding opportunities across industries. Following model training, deployment tools like Flask, FastAPI, Docker, and Kubernetes are used to bring models into real-world applications with scalability and reliability. Finally, monitoring tools such as MLflow, Airflow, and Prometheus ensure ongoing performance tracking, enabling teams to detect drifts or issues and make timely updates to maintain accuracy and effectiveness.
Future Enhancements in Data Science Workflows
The field of data science is evolving at an accelerated pace, with emerging trends significantly shaping future workflows and driving innovation. One of the key developments is Automated Machine Learning (AutoML), with tools such as Google AutoML and H2O.ai simplifying the model-building process, enabling both experts and non-experts to create machine learning models with greater ease. Federated Learning is another rising trend, offering a distributed approach that enhances privacy by allowing models to be trained across decentralized data sources without transferring sensitive data. At the same time, Explainable AI (XAI) is gaining momentum by improving the transparency and interpretability of AI systems, helping stakeholders understand and trust the decisions made by these models. Edge AI is also making headway, allowing real-time processing and decision-making directly on devices like smartphones and IoT gadgets, eliminating the dependency on cloud infrastructure. In parallel, increased emphasis on AI Ethics and Bias Reduction is driving initiatives to ensure fairness, transparency, and accountability in AI applications. For professionals and organizations aiming to stay ahead of these transformative changes, pursuing Data Science Training can provide the essential skills and knowledge needed to effectively adapt and contribute to the future of data-driven innovation.



