
Last updated on 28th May 2025| 10573
- Introduction to Data Engineering
- Role of a Data Engineer
- Key Skills for Data Engineers
- Data Engineering vs Data Science
- Tools and Technologies
- Building Data Pipelines
- Data Warehousing Concepts
- ETL (Extract, Transform, Load) Process
- Cloud and Big Data Technologies
- Real-world Applications
- Career Path and Salary
- Conclusion
Introduction to Data Engineering
Data engineering is a foundational discipline in the data ecosystem, focused on designing, building, and maintaining the systems and architecture that enable the collection, storage, and processing of large volumes of data. As businesses increasingly rely on data to drive decisions, the role of data engineers has become critical in ensuring that data is clean, accessible, and ready for analysis. Data engineering involves working with databases, data warehouses, data lakes, and ETL (Extract, Transform, Load) pipelines to efficiently move and transform data from various sources into formats suitable for analytics or machine learning. Data Science Training plays a crucial role in equipping professionals with the necessary skills to analyze and interpret data, making it an essential complement to data engineering for driving data-driven decision-making. It requires proficiency in programming languages such as Python, SQL, or Scala, and familiarity with tools and platforms like Apache Spark, Kafka, Airflow, and cloud services such as AWS, Google Cloud, or Azure. Data engineers also ensure data quality, implement data governance practices, and optimize data workflows for performance and scalability. Unlike data scientists, who focus on analysis and modeling, data engineers concentrate on the infrastructure that supports such work. A solid understanding of data modeling, distributed systems, and big data technologies is essential in this field. Overall, data engineering serves as the backbone of any data-driven organization, enabling accurate, timely, and reliable insights through robust data infrastructure.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
Role of a Data Engineer
- Designing Data Architecture: Data engineers are responsible for creating the architecture that supports data generation, flow, and storage, including data lakes, data warehouses, and real-time data pipelines.
- Building ETL Pipelines: They develop and manage ETL (Extract, Transform, Load) processes to efficiently move and transform data from various sources into usable formats for analytics or machine learning.
- Ensuring Data Quality: A key responsibility is maintaining high data quality by implementing validation checks, cleaning raw data, and ensuring consistency, accuracy, and completeness across datasets, which can be further explored in a Python project ideas for beginners guide.
- Managing Databases: Data engineers set up, configure, and optimize relational and non-relational databases, ensuring high performance, security, and reliability of data storage systems.
- Collaborating with Teams:They work closely with data scientists, analysts, and business stakeholders to understand data requirements and ensure the infrastructure supports analytical needs.
- Implementing Data Security and Governance: Ensuring data privacy, compliance, and proper access control by applying data governance standards and security best practices.
- Optimizing Data Workflows: Data engineers constantly monitor and fine-tune data pipelines and systems to enhance performance, scalability, and cost-efficiency.
- Utilizing Big Data Tools and Cloud Services: They leverage big data frameworks like Apache Spark and cloud platforms such as AWS, Azure, or Google Cloud to manage and process large-scale datasets effectively.
Key Skills for Data Engineers
Key skills for data engineers span across programming, data management, system design, and cloud technologies, making them versatile professionals in the data ecosystem. Proficiency in programming languages like Python, SQL, Java, or Scala is essential for building robust data pipelines and processing large datasets. A strong understanding of relational and non-relational databases, including MySQL, PostgreSQL, MongoDB, and Cassandra, enables data engineers to design and manage efficient data storage solutions. Knowledge of ETL (Extract, Transform, Load) processes and tools like Apache Airflow, Talend, or Informatica is crucial for automating and orchestrating data workflows. Familiarity with big data technologies such as Apache Spark, Hadoop, and Kafka allows engineers to handle massive volumes of data in distributed systems, offering valuable insights for understanding What is Data Engineering insights and its importance. Experience with cloud platforms like AWS, Google Cloud, or Azure is increasingly important, as many companies rely on cloud infrastructure for scalability and flexibility. Data engineers must also have a solid grasp of data modeling, data warehousing (e.g., Redshift, Snowflake), and version control systems like Git. Strong problem-solving skills, attention to detail, and the ability to work collaboratively with data scientists and analysts are equally vital. These skills collectively ensure that data engineers can build, optimize, and maintain the complex data architectures that drive modern analytics and decision-making.
Data Engineering vs Data Science
-
Primary Focus:
- Data Engineering focuses on building and maintaining the infrastructure and architecture for data generation, storage, and processing.
- Data Science focuses on analyzing and interpreting data to extract insights, build models, and support decision-making. Key Responsibilities:
- Data Engineers design ETL pipelines, manage databases, and ensure data quality and availability.
- Data Scientists perform statistical analysis, build machine learning models, and create data visualizations. Tools and Technologies:
- Data Engineers use tools like Apache Spark, Hadoop, Kafka, Airflow, SQL, and cloud services (AWS, GCP, Azure).
- Data Scientists work with tools like Python, R, Jupyter Notebooks, Scikit-learn, TensorFlow, and visualization libraries. Programming Skills:
- Data Engineers often code in Python, Java, Scala, or SQL for system and pipeline development.
- Data Scientists use Python or R for data analysis, statistics, and machine learning. End Goals:
- Data Engineers ensure reliable, clean, and accessible data infrastructure.
- Data Scientists use that data to uncover trends, make predictions, and provide actionable insights. Collaboration:
- Data engineers and data scientists work closely together engineers prepare the data, and scientists use it for analysis and modeling. Data Handling:
- Data Engineers work with raw, unstructured data and make it usable.
- Data Scientists work with processed data to extract knowledge and build models. Career Path:
- Data engineering leans more toward software and systems engineering.
- Data science leans more toward statistics, mathematics, and analytical modeling.
Tools and Technologies
In the field of data engineering, a wide range of tools and technologies are used to build, manage, and optimize data infrastructure. Programming languages like Python, SQL, Java, and Scala are fundamental for scripting, querying, and building data pipelines. For data storage, engineers use relational databases such as MySQL and PostgreSQL, and NoSQL databases like MongoDB and Cassandra for handling unstructured data. ETL (Extract, Transform, Load) tools such as Apache Airflow, Talend, and Informatica are essential for designing and automating data workflows. Big data processing is handled using frameworks like Apache Hadoop and Apache Spark, which allow for distributed computing on large datasets. Real-time data streaming tools like Apache Kafka and Flink enable the handling of data in motion. In terms of data warehousing, technologies such as Amazon Redshift, Google BigQuery, and Snowflake are commonly used to store and analyze large volumes of data efficiently. Cloud platforms like AWS, Microsoft Azure, and Google Cloud Platform (GCP) are increasingly central, offering scalable storage, computing power, and integrated data services, playing a crucial role in the future scope of artificial intelligence for innovation and growth. Version control tools like Git are also important for tracking changes in code and collaborating with teams. Together, these technologies form the backbone of modern data engineering practices.

Automation Projects
-
Web Scraping Automation:
- Build a web scraping automation tool to extract data from websites regularly. Automate the collection of product prices, stock data, or news articles and save the extracted data into a database or CSV file for analysis. Email Notification System:
- Create an automated email notification system that sends out alerts based on specific triggers, such as stock price changes, incoming customer queries, or task deadlines, improving communication efficiency. Social Media Post Scheduler:
- Develop an automation project to schedule and post content on social media platforms like Twitter or Instagram. Integrate APIs to automate posts, track engagement metrics, and schedule posts at optimal times. File Organization Automation:
- Build a script to automatically organize files on your computer. This project can automatically sort files based on type, date, or project, and move them to respective folders, saving time on manual organization. Data Backup Automation:
- Automate the process of backing up important files or databases at regular intervals. This ensures data security and minimizes the risk of losing critical information, a project that can align with data science course eligibility for those looking to enhance their skills. Automated Report Generation:
- Create a project to automate the generation of periodic reports from datasets. The automation tool can pull data from multiple sources, perform necessary calculations, and generate reports in formats like PDF or Excel. Task Reminder Automation:
- Build a task reminder system that sends automated notifications for upcoming tasks or appointments, integrating with a calendar or task management tool to ensure timely reminders. Data Entry Automation:
- Automate repetitive data entry tasks by creating scripts that extract information from emails, forms, or documents, and input them into structured databases or spreadsheets without manual intervention.
These automation projects can help improve efficiency, reduce human error, and free up valuable time for more strategic tasks.
Want to Pursue a Data Science Master’s Degree? Enroll For Data Science Masters Course Today!
Building Data Pipelines
-
Data Ingestion:
- The first step involves collecting data from various sources such as APIs, databases, files, or streaming platforms. Tools like Apache Kafka, Flume, or custom scripts are often used for this purpose. Data Extraction:
- Extract data in its raw form from different formats (CSV, JSON, XML, etc.) or platforms. This step ensures that relevant data is pulled for further processing. Data Transformation:
- Clean, format, and transform the data into a usable structure. This includes handling missing values, converting data types, filtering, and aggregating data using tools like Spark, Pandas, or SQL. Data Loading (ETL/ELT):
- Load the transformed data into a data warehouse or data lake (e.g., Snowflake, Redshift, BigQuery) for storage and analysis. Choose between ETL (Transform before Load) or ELT (Load before Transform) based on use case. Workflow Orchestration:
- Use workflow tools like Apache Airflow, Prefect, or Luigi to automate and schedule pipeline tasks, ensuring reliable and repeatable execution. Monitoring and Logging:
- Track pipeline performance, log errors, and send alerts for failures. Monitoring tools help ensure data reliability and pipeline health. Scalability and Optimization:
- Optimize pipelines for large-scale data and ensure they perform well under increasing loads by using distributed processing and efficient data structures. Data Quality and Validation:
- Implement checks to validate data accuracy and completeness at each stage to maintain high-quality outputs.
Data Warehousing Concepts
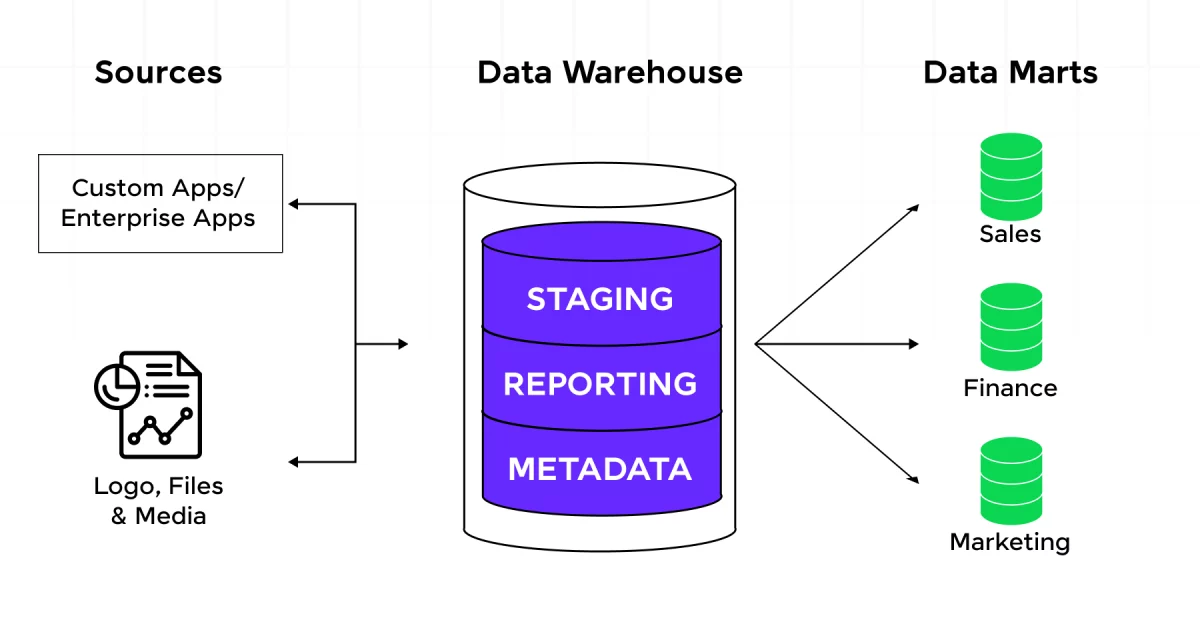
Data warehousing is the process of collecting, storing, and managing large volumes of structured data from various sources in a centralized repository to support analysis and reporting. It involves key processes such as ETL (Extract, Transform, Load), where data is extracted from multiple sources, transformed into a consistent format, and loaded into the warehouse.Data warehousing uses models like the star schema and the snowflake schema to organize data for efficient querying. Data Science Training equips professionals with the skills to effectively analyze and leverage data from these models for deeper insights. OLAP (Online Analytical Processing) allows for multidimensional analysis, enabling users to explore data from various perspectives, such as time, geography, and product categories. Additionally, data marts are specialized subsets of the data warehouse that serve specific business areas or departments. Modern data warehousing increasingly leverages cloud technologies like Amazon Redshift, Google BigQuery, and Snowflake, offering scalable, flexible storage and processing solutions. By consolidating data into a single location, data warehousing supports business intelligence and enables organizations to perform complex analytics and generate insights for better decision-making. It provides the infrastructure for reporting, predictive analytics, and data visualization, making it essential for businesses to harness the full potential of their data.
ETL (Extract, Transform, Load) Process
The ETL (Extract, Transform, Load) process is a critical method used to integrate data from various sources into a centralized data warehouse or data lake, enabling efficient analysis and reporting. It consists of three distinct stages:
- Extract: In the extraction phase, data is collected from multiple sources, which could include databases, spreadsheets, APIs, or external services. The goal is to gather raw data from disparate systems without altering its structure, ensuring that all relevant information is captured for further processing.
- Transform:The transformation phase involves cleaning, filtering, and restructuring the extracted data to match the target system’s requirements. This may include tasks like removing duplicates, converting data types, handling missing values, aggregating information, and performing calculations. The transformation step ensures data consistency, quality, and compatibility with the destination schema, and is valuable for understanding Data Analyst Salary Trends in United States as skills improve.
- Load: In the loading phase, the transformed data is inserted into the target database, data warehouse, or data lake. This stage ensures that data is stored efficiently for querying and analysis. Depending on the needs of the organization, data may be loaded in batch processing or in real-time, allowing for timely access to the information.
The ETL process plays a crucial role in data integration, enabling businesses to consolidate diverse data sources, maintain data quality, and ensure data is ready for actionable insights through analytics and reporting.
Cloud and Big Data Technologies
Cloud and big data technologies have revolutionized the way organizations handle and process vast amounts of data. Cloud computing provides scalable and flexible infrastructure, allowing businesses to store, manage, and process data without the need for on-premises hardware. Services like Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) offer a wide array of tools and resources for data storage, compute power, and analytics, making it easier to scale operations and reduce costs. Big data technologies, such as Apache Hadoop, Apache Spark, and Kafka, enable organizations to process and analyze enormous datasets that traditional systems can’t handle efficiently. These technologies facilitate distributed data processing, storage, and real-time data streaming, allowing for faster and more comprehensive insights, while also helping to develop Essential Data Analyst Skills for effective data management and analysis. For example, Hadoop uses a distributed file system (HDFS) to store data across multiple nodes, while Spark provides in-memory processing capabilities that are much faster than traditional disk-based processing. Combined, cloud platforms and big data technologies allow businesses to leverage powerful data processing capabilities without the complexity of managing infrastructure. This enables organizations to drive innovation, improve decision-making, and gain insights from vast amounts of data, ultimately enhancing operational efficiency and business growth.
Real-world Applications
- E-commerce Personalization: Data engineers build pipelines that collect and process customer data to provide personalized recommendations and improve user experiences in e-commerce platforms.
- Financial Analytics and Fraud Detection: In the finance sector, data engineers design systems that process transaction data in real-time to detect fraudulent activities and generate predictive financial models.
- Healthcare Data Management: Data engineering is used to manage patient data, integrate medical records, and build systems that support predictive models for disease diagnosis and treatment planning.
- Supply Chain Optimization: Data engineers create pipelines to process data from various sources, helping companies optimize inventory, delivery routes, and supplier management for efficient supply chain operations.
- Smart Cities: In urban development, data engineering is used to process data from IoT devices in smart cities to optimize traffic, energy consumption, and public services.
- Social Media Analytics: Data engineers develop systems that handle and process large volumes of social media data, enabling real-time sentiment analysis, trend tracking, and marketing strategy optimization.
- Telecommunications and Network Management: Telecom companies use data engineering to manage network performance, track usage patterns, and optimize routing, enhancing service quality for users.
- Predictive Maintenance in Manufacturing: Data engineers help monitor machinery and sensor data to predict failures and schedule maintenance, reducing downtime and enhancing productivity in manufacturing.
Career Path and Salary
The career path in data engineering offers numerous growth opportunities, with a variety of roles and a strong demand for skilled professionals. Entry-level positions typically include Junior Data Engineer or Data Engineer I, where individuals focus on building foundational skills in data pipelines, SQL, and ETL processes. As experience grows, data engineers can advance to roles such as Senior Data Engineer or Lead Data Engineer. Responsibilities include designing complex data systems, optimizing large-scale data processing, and leading teams, all of which are closely tied to the Future Scope of Artificial Intelligence in driving innovation and efficiency. Data engineers can further specialize in areas like cloud computing, big data technologies, or machine learning engineering, eventually moving into leadership positions like Data Engineering Manager or Director of Data Engineering. In terms of salary, data engineering is a highly rewarding field. Entry-level data engineers in the United States can expect a starting salary ranging from $70,000 to $90,000 annually, depending on the location and company. As professionals gain experience, salaries can rise to $100,000 to $130,000 for mid-level engineers and $140,000 to $170,000 for senior roles. Specialized skills in cloud platforms, big data frameworks, and advanced data processing can increase earning potential. Additionally, data engineers with managerial responsibilities or who work in high-demand industries like finance or healthcare may see even higher compensation packages.
Conclusion
Data engineering is a fast-evolving field that plays a critical role in the modern data ecosystem. As organizations increasingly rely on data-driven insights for decision-making, the demand for skilled data engineers continues to grow. This role requires a unique blend of skills, including software engineering, database management, cloud computing, and big data processing. Data engineers design, build, and maintain the infrastructure that allows data to be collected, stored, and analyzed efficiently. By mastering essential tools and technologies, such as SQL, Python, Hadoop, and cloud platforms, professionals can pave the way for a rewarding career.This career offers competitive salaries and the opportunity to make a significant impact Data Science Training across various industries, from finance and healthcare to e-commerce and technology. Enhances your ability to leverage data for impactful insights, further increasing your value in these sectors. Moreover, with the ongoing advancements in AI, machine learning, and IoT, data engineering is poised to be a foundational element in future innovations. Data engineers will continue to ensure that data is accessible, reliable, and scalable, allowing organizations to leverage it as a powerful asset. As the field continues to evolve, data engineers will be at the forefront of shaping the way industries harness data for growth and development.




