
Last updated on 23rd May 2025| 10128
- Introduction to Data Engineer Role
- Key Responsibilities of a Data Engineer
- Data Engineer vs. Data Scientist
- ETL and Data Pipeline Development
- Data Modeling and Warehousing Duties
- Database Management and Optimization
- Cloud Infrastructure Management
- Troubleshooting and Performance Tuning
Introduction to Data Engineer Role
In today’s fast-paced world, data is at the core of every business decision. As organizations increasingly rely on data to drive growth, data engineers are playing a critical role in managing, optimizing, and building the systems that allow data to flow freely, be accessible, and be used for decision-making. A data engineer is responsible for creating the architecture that enables the efficient collection, storage, processing, and use of data across the organization. Unlike data scientists or analysts, data engineers are more focused on the plumbing of data, designing and maintaining the infrastructure that supports data-driven processes, which is a critical foundation often covered in Data Science Training. They ensure that data is correctly ingested, transformed, stored, and made accessible for others to analyze and act upon. This position demands deep technical knowledge as well as a solid understanding of business needs. Data engineers work in all industries, from finance to healthcare, retail, and technology. For instance, in the tech industry, a data engineer might work on creating and maintaining the infrastructure for processing real-time data from millions of connected devices. In healthcare, they might build secure systems to store and manage sensitive patient data.
Interested in Obtaining Your Data Science Certificate? View The Data Science Course Training Offered By ACTE Right Now!
Key Responsibilities of a Data Engineer
Data engineers play a crucial role in designing and building data pipelines that facilitate the smooth flow of data from multiple sources such as databases, APIs, or third-party services to data warehouses or storage systems. These pipelines handle both batch and real-time streaming data, requiring engineers to ensure they are scalable and resilient. They integrate data from diverse sources, transforming raw data into consistent, usable formats by cleaning, filtering, and restructuring it for analysis, which is a key aspect of Data Analyst Roles. This process helps eliminate data silos and provides a unified data system for the organization. Data engineers are also responsible for managing databases and storage solutions by designing schemas, indexing data for fast access, and implementing backup strategies to prevent data loss. Ensuring data quality is another key responsibility, involving validation checks to maintain data accuracy and consistency.
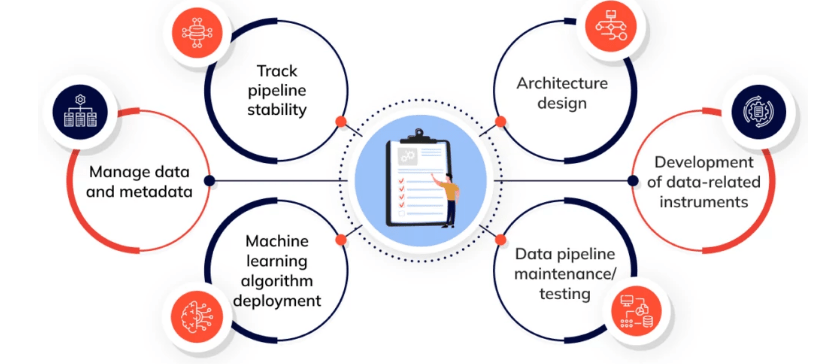
They automate repetitive tasks and optimize workflows to reduce errors and increase efficiency. Collaboration with data scientists and analysts is vital, as data engineers ensure that the data used for insights is clean and accessible, while also troubleshooting system issues. Additionally, data engineers enforce security protocols and regulatory compliance by encrypting data, controlling access, and maintaining audit trails. Continuous monitoring and performance tuning of data pipelines are essential to minimize downtime and maintain system efficiency.
Data Engineer vs. Data Scientist
- Output: Data engineers deliver data pipelines, databases, and scalable data infrastructure. Data scientists produce reports, dashboards, and machine learning models.
- Collaboration: Data engineers and scientists collaborate closely; engineers provide clean data, and scientists provide insights that may influence pipeline requirements.
- Goal: Data engineers focus on building robust data ecosystems, while data scientists aim to solve business problems using data-driven insights and predictive analytics.
- Primary Focus: Data engineers build and maintain the infrastructure and pipelines needed to collect, store, and process data. Data scientists analyze this data to extract insights and build predictive models, making it essential to Learn Data Science.
- Skill Sets: Data engineers typically specialize in programming (Python, Java, Scala), database management, ETL tools, and cloud platforms. Data scientists focus more on statistics, machine learning, data visualization, and programming languages like Python or R.
- Data Handling: Data engineers work with raw, unprocessed data, ensuring it is clean, reliable, and accessible. Data scientists use this prepared data to perform exploratory analysis and modeling.
- Tools Used: Engineers commonly use Hadoop, Spark, Airflow, and SQL databases, while scientists use tools like Jupyter notebooks, TensorFlow, scikit-learn, and visualization libraries.
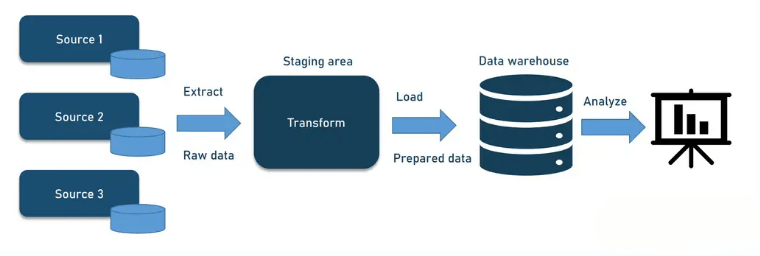
- Definition: ETL (Extract, Transform, Load) is the process of extracting data from various sources, transforming it into a usable format, and loading it into a destination like a data warehouse. Data pipelines automate this flow of data from source to destination.
- Extraction: The first step involves collecting data from diverse sources such as databases, APIs, flat files, or streaming platforms, often in different formats and structures.
- Transformation: Raw data is cleaned, filtered, and transformed to ensure consistency and usability. This may include data validation, removing duplicates, handling missing values, and converting data types skills commonly emphasized in Data Science Training.
- Loading: After transformation, data is loaded into storage systems like data warehouses, data lakes, or databases, optimized for query performance and analytics.
- Automation: Data pipelines automate the ETL process, enabling continuous or scheduled data flow without manual intervention, improving efficiency and reliability.
- Scalability and Resilience: Effective pipelines are designed to handle increasing data volumes and recover gracefully from failures, ensuring uninterrupted data availability.
- Monitoring and Maintenance: Regular monitoring, logging, and error handling are essential to detect issues early, maintain pipeline health, and optimize performance over time.
- Indexing: Creating indexes on key columns speeds up query performance by allowing faster data lookups, especially in large datasets.
- Database Design: Effective database management starts with designing appropriate schemas that organize data logically to support efficient storage and retrieval while minimizing redundancy.
- Data Storage: Data engineers ensure databases can handle large volumes of data, selecting suitable storage engines (e.g., relational or NoSQL) based on the type and scale of data.
- Query Optimization: Data engineers analyze and optimize SQL queries to reduce execution time by rewriting queries, using joins efficiently, and avoiding unnecessary data scans, which is crucial for leveraging Data Science in Retail Industry applications.
- Backup and Recovery: Regular backups and disaster recovery plans safeguard data integrity, enabling quick restoration in case of failures or data loss.
- Security and Access Control: Managing user permissions and encrypting sensitive data protects databases from unauthorized access and ensures compliance with regulations.
- Performance Monitoring: Continuous monitoring of database performance metrics (like response time, CPU, and memory usage) helps identify bottlenecks, allowing timely tuning and resource adjustments.
Would You Like to Know More About Data Science? Sign Up For Our Data Science Course Training Now!
ETL and Data Pipeline Development

Data Modeling and Warehousing Duties
Data modeling and warehousing are core responsibilities of data engineers that enable organizations to organize, store, and analyze large volumes of data effectively. Data engineers design data models that define how data is structured, related, and stored, ensuring that it supports the organization’s analytical and business needs. This involves creating conceptual, logical, and physical models that optimize data accessibility and performance. Effective data modeling helps reduce redundancy, improve data integrity, and streamline query performance. In addition to modeling, data engineers build and maintain data warehouses, central repositories that consolidate data from various sources into a unified platform, which is key to Understanding Data Science and Data Analytics. They work with popular warehousing technologies like Amazon Redshift, Google BigQuery, Snowflake, and Microsoft Azure Synapse. Data engineers design efficient ETL (Extract, Transform, Load) processes to populate these warehouses with clean, consistent, and timely data, facilitating faster business intelligence and reporting. They also ensure data warehouses are scalable to accommodate growing data volumes while optimizing storage and query performance. Regular maintenance, including indexing, partitioning, and backup, is crucial to keep the warehouse efficient and reliable. By combining strong data modeling with robust warehousing solutions, data engineers empower data scientists and analysts to derive meaningful insights, make data-driven decisions, and support strategic initiatives across the organization.
Looking to Master Data Science? Discover the Data Science Masters Course Available at ACTE Now!
Database Management and Optimization
Cloud Infrastructure Management
Cloud infrastructure management is a vital responsibility for data engineers, involving the design, deployment, and maintenance of data systems hosted on cloud platforms like AWS, Microsoft Azure, and Google Cloud. Data engineers leverage cloud services to build scalable, flexible, and cost-effective data storage and processing environments that can handle vast volumes of data efficiently. They configure and optimize cloud resources such as virtual machines, data lakes, databases, and analytics tools to meet organizational needs. Effective cloud management ensures high availability, fault tolerance, and security of data infrastructure. Data engineers implement automation using infrastructure-as-code (IaC) tools like Terraform or AWS CloudFormation to streamline provisioning and updates, reducing manual errors and accelerating deployment, which is essential in understanding What is Data and how it flows through systems. Monitoring and cost management are crucial aspects of cloud infrastructure management; engineers track resource usage, optimize workloads, and manage budgets to prevent overspending. Security is another major focus data engineers enforce access controls, encryption, and compliance policies to protect sensitive information and meet regulatory requirements. They also collaborate with DevOps and security teams to establish best practices for cloud governance. By managing cloud infrastructure effectively, data engineers enable organizations to leverage the power of cloud computing for advanced analytics, real-time processing, and machine learning, driving innovation and agility in today’s data-driven business environment.
Preparing for Data Science Job? Have a Look at Our Blog on Data Science Interview Questions & Answer To Ace Your Interview!
Troubleshooting and Performance Tuning
Troubleshooting and performance tuning are critical duties of data engineers to ensure the smooth functioning of data systems and pipelines. When issues such as data delays, pipeline failures, or system errors occur, data engineers quickly diagnose the root causes using monitoring tools, logs, and alerts. They troubleshoot problems related to data quality, connectivity, storage, and processing to minimize downtime and maintain uninterrupted data flow. Performance tuning involves optimizing the efficiency of data pipelines, databases, and queries to handle large-scale data volumes effectively. Data engineers analyze bottlenecks, such as slow-running queries or resource constraints, and apply solutions like indexing, query optimization, or parallel processing techniques often covered in Data Science Training. They also fine-tune system configurations, resource allocation, and batch sizes to enhance throughput and reduce latency. Continuous monitoring plays a vital role in identifying potential issues before they impact users, allowing proactive maintenance and timely adjustments. Collaboration with cross-functional teams helps data engineers address complex challenges involving infrastructure, software, and data architecture. By ensuring data pipelines run efficiently and reliably, data engineers support timely analytics and reporting, enabling data scientists and business users to make informed decisions. Effective troubleshooting and performance tuning ultimately contribute to the robustness and scalability of the data ecosystem, making it a foundational aspect of a data engineer’s role.




