
Last updated on 25th Apr 2025| 9701
- Overview of Data Mining
- Feature Selection and Engineering
- Clustering Algorithms
- ETL in Data Mining
- Classification Techniques in Data Mining
- Association Rule Mining
- Data Mining Tools
- Scalability Challenges in Data Mining
Overview of Data Mining
Data mining is the process of discovering hidden patterns, trends, and insights from large datasets, enabling businesses to make informed decisions. It combines various techniques from statistics, machine learning, and database management to extract valuable information that may not be immediately apparent. The process begins with collecting and preparing data, which often involves cleaning and transforming raw data into a usable format. Statistical methods, such as regression analysis and clustering, help identify relationships and groupings within the data, making them essential tools in Data Science Training for uncovering patterns and driving data-driven decisions. Machine learning algorithms like decision trees, neural networks, and support vector machines are used to detect complex patterns and predict future trends. Database techniques, including association rule mining and anomaly detection, uncover relationships between variables and identify outliers. The goal of data mining is to turn raw, unstructured data into actionable knowledge that can drive business strategies, improve operations, or enhance customer experiences. This process is particularly valuable in fields such as marketing, finance, healthcare, and e-commerce, where organizations need to analyze vast amounts of data to uncover insights that lead to better decision-making and improved outcomes.
To Explore Data Science in Depth, Check Out Our Comprehensive Data Science Course Training To Gain Insights From Our Experts!
Feature Selection and Engineering
Feature selection and engineering are critical steps in the data preprocessing phase of machine learning, playing a major role in building accurate and efficient models. Feature selection involves identifying the most relevant variables from a dataset that contribute meaningfully to the target outcome. By eliminating irrelevant, redundant, or noisy features, it helps reduce model complexity, improve performance, and decrease overfitting principles that align with Mastering Informed Search in Artificial Intelligence to enhance search efficiency and model accuracy. Common techniques for feature selection include correlation analysis, mutual information, recursive feature elimination, and using model-based importance scores. On the other hand, feature engineering focuses on creating new features or transforming existing ones to better represent the underlying patterns in the data. This may include techniques like normalization, encoding categorical variables, extracting date/time elements, binning, or combining features to uncover deeper relationships.
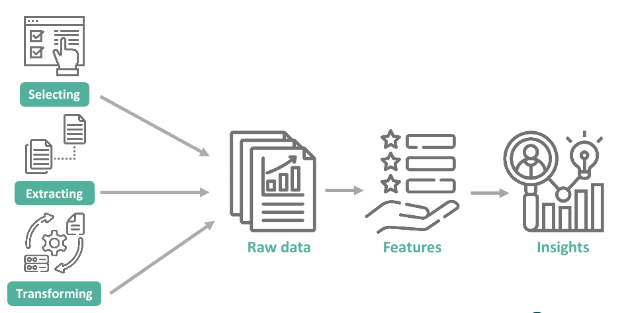
Thoughtfully engineered features often enhance a model’s predictive power far more than simply relying on raw data. Together, these processes help ensure that the machine learning algorithm has the most informative and clean set of inputs, leading to better generalization and more interpretable models. Proper feature selection and engineering not only improve accuracy but also make the modeling process more efficient, especially when dealing with high-dimensional datasets.
Clustering Algorithms
- Definition: Clustering algorithms group similar data points together based on feature similarity, without using labeled outputs.
- K-Means Clustering: One of the most popular algorithms, it partitions data into k predefined clusters by minimizing intra-cluster variance.
- Hierarchical Clustering: Builds nested clusters by either merging (agglomerative) or splitting (divisive) data points, often visualized with a dendrogram.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Forms clusters based on dense regions, effectively identifying outliers and irregularly shaped clusters, a technique often used in Master Data Wrangling Steps, Tools & Techniques to clean and organize data before analysis.
- Mean Shift: A centroid-based algorithm that does not require specifying the number of clusters in advance, using a sliding window approach.
- Gaussian Mixture Models (GMM): Uses probabilistic models to represent data as a mixture of multiple Gaussian distributions, allowing soft clustering.
- Applications: Clustering is widely used in market segmentation, image analysis, anomaly detection, and recommendation systems.
- Evaluation Metrics: Metrics like silhouette score, Davies–Bouldin index, and elbow method help assess clustering quality and determine the optimal number of clusters.
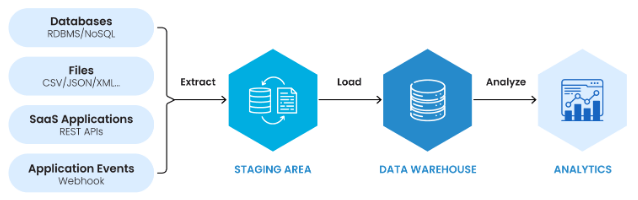
- Extract: The first step in ETL (Extract, Transform, Load) involves gathering raw data from various sources such as databases, APIs, files, or cloud services.
- Transform: In this phase, the raw data is cleaned, formatted, and converted into a consistent structure suitable for analysis. This includes handling missing values, normalizing, and applying business rules.
- Load: The transformed data is then loaded into a target data warehouse, data lake, or analytical system for mining and reporting purposes, which is a fundamental step covered in Data Science Training for building effective data pipelines.
- Data Integration: ETL combines data from multiple heterogeneous sources, ensuring a unified view that supports comprehensive analysis.
- Quality Improvement: The transformation stage enhances data quality by correcting errors, removing duplicates, and standardizing formats.
- Automation: ETL processes can be automated, making them efficient for handling large volumes of data regularly.
- Scalability: Modern ETL tools support scalability, allowing them to handle growing data requirements in real-time or batch processing.
- Foundation for Data Mining: ETL prepares and organizes data, making it ready for mining techniques like classification, clustering, and pattern recognition.
- KNIME (Konstanz Information Miner): An open-source platform that provides a graphical interface to create data pipelines for data mining, machine learning, and data analysis with easy integration of R and Python.
- Orange: A user-friendly, open-source tool that supports visual programming and interactive data analysis, widely used in educational and research settings.
- SAS Enterprise Miner: A commercial tool that offers advanced analytics, including predictive modeling, data mining, and machine learning, mainly used in enterprise environments.
- IBM SPSS Modeler: A powerful statistical analysis and data mining tool designed for business users to build predictive models without deep programming skills.
- R and Python: Both offer rich ecosystems of libraries (like scikit-learn, caret, and mlr) for custom, flexible data mining workflows essential tools for Top Deep Learning Projects, where customization and flexibility are key to building sophisticated models.
- Tableau: While primarily a data visualization tool, Tableau can integrate with mining tools and handle large datasets for pattern discovery and analysis.
- RapidMiner: A popular open-source data science platform offering a visual workflow designer. It supports data preparation, machine learning, deep learning, and model deployment, making it ideal for users with minimal coding experience.
- WEKA (Waikato Environment for Knowledge Analysis): A Java-based tool with a user-friendly interface that includes a collection of machine learning algorithms for data mining tasks such as classification, clustering, and association.
Interested in Obtaining Your Data Science Certificate? View The Data Science Course Training Offered By ACTE Right Now!
ETL in Data Mining

Classification Techniques in Data Mining
Classification is a fundamental technique in data mining used to assign predefined labels or categories to data based on input features. It is a supervised learning method, meaning the model is trained on a labeled dataset where the outcome variable is already known. The goal is to learn a mapping from input variables to target labels, enabling the model to predict the class of new, unseen instances accurately. Several popular classification algorithms are widely used depending on the data and problem type. Decision Trees are intuitive models that split data based on feature values, creating a tree-like structure for decision-making, a concept covered under Subjects in Data Science for their simplicity and effectiveness in predictive modeling. Naïve Bayes is a probabilistic classifier based on Bayes’ Theorem, assuming feature independence, and is effective for text classification. K-Nearest Neighbors (KNN) assigns a class to a data point based on the majority class among its nearest neighbors. Support Vector Machines (SVM) work well for high-dimensional data and aim to find the optimal boundary between classes. Random Forest is an ensemble method combining multiple decision trees for more accurate and robust predictions. Classification techniques are widely applied in spam detection, medical diagnosis, fraud detection, and sentiment analysis, making them essential tools in data mining.
Are You Considering Pursuing a Master’s Degree in Data Science? Enroll in the Data Science Masters Course Today!
Association Rule Mining
Association rule mining is a key technique in data mining used to uncover interesting relationships, patterns, or associations among items in large datasets. It is particularly useful in market basket analysis, where it identifies products frequently bought together, helping businesses optimize cross-selling and recommendation strategies. The technique works by discovering rules in the form of “If A, then B,” where A and B are itemsets. These rules are evaluated using metrics such as support, confidence, and lift. Support measures how frequently the itemset appears in the dataset, confidence indicates how often the rule has been found to be true, and lift evaluates how much more likely the consequent is to occur with the antecedent than without it concepts often explored in Data Science Course Fees, where understanding these metrics is crucial for effective data mining and association rule learning. Algorithms like Apriori, Eclat, and FP-Growth are commonly used for association rule mining. These algorithms efficiently prune the search space and identify the most meaningful rules. Association rule mining is not limited to retail; it’s also used in bioinformatics, web usage mining, and healthcare to uncover hidden correlations. By revealing actionable insights, it empowers data-driven decision-making and enhances strategic planning in various industries.
Data Mining Tools
Preparing for a Data Science Job Interview? Check Out Our Blog on Data Science Interview Questions & Answer
Scalability Challenges in Data Mining
Scalability is a significant challenge in data mining, particularly as organizations generate and collect massive volumes of data from various sources. As datasets grow in size, complexity, and dimensionality, traditional data mining algorithms often struggle to maintain performance and efficiency. One key challenge is the computational complexity of mining large-scale data, which can result in slower processing times and increased memory usage. Many algorithms that work well on small datasets become inefficient or even unusable when applied to big data. Another issue is data heterogeneity, where data comes in different formats, structures, and from various sources, making it difficult to integrate and process uniformly a challenge often addressed in Data Science Training through techniques for data wrangling and standardization. Real-time data processing poses an additional challenge, as systems must analyze and derive insights from streaming data without delays. Furthermore, distributed environments require algorithms that can efficiently work across multiple nodes while maintaining consistency and accuracy. To address these scalability challenges, techniques such as parallel processing, sampling, incremental learning, and distributed computing frameworks like Hadoop and Spark are employed. Optimizing algorithms for scalability is essential for extracting timely, actionable insights and ensuring that data mining remains effective as data volumes continue to expand across industries.




