
Last updated on 24th Apr 2025| 9750
- Introduction to Data Cleaning
- Importance of Data Cleaning in Data Science
- Common Data Quality Issues
- Steps in Data Cleaning Process
- Handling Missing Data
- Removing Duplicates in Datasets
- Data Transformation and Standardization
- Data Cleaning Tools and Technologies
- Challenges in Data Cleaning
- Best Practices for Effective Data Cleaning
- Conclusion
Introduction to Data Cleaning
Data cleaning is a vital part of the data preparation process that involves identifying, correcting, or removing inaccurate, incomplete, or irrelevant data from datasets. AI data cleaning is central to analytics, machine learning, and C, so ensuring its quality is critical for generating meaningful insights. Poor-quality data can lead to flawed conclusions, inaccurate models, and wasted resources, making data cleaning an indispensable step in any Data Science Course Training workflow. By removing inconsistencies, addressing missing values, and ensuring data accuracy, data cleaning helps improve the reliability of analyses and enhances the performance of machine learning models. Properly cleaned data is essential for making informed decisions and drawing valid conclusions. Data cleaning services are the foundation of any successful data-driven initiative, as high-quality data directly contributes to better outcomes in analytics and AI applications.
Importance of Data Cleaning in Data Science
- Accuracy: Clean data ensures the accuracy of insights derived from analysis.
- Model Performance: Data quality directly impacts the performance of machine learning models, making data cleaning a critical step for effective predictive modeling.
- Efficiency: Clean datasets help avoid wasting time on irrelevant or erroneous data and streamline analysis.
- Decision Making: Accurate, high-quality data supports informed decision-making by providing reliable foundations for predictions, trends, and insights. Proper AI data cleaning is indispensable for any data science project, as even sophisticated algorithms can produce unreliable results without it.
Unlock your potential in Data Science with this Data Science Online Course .
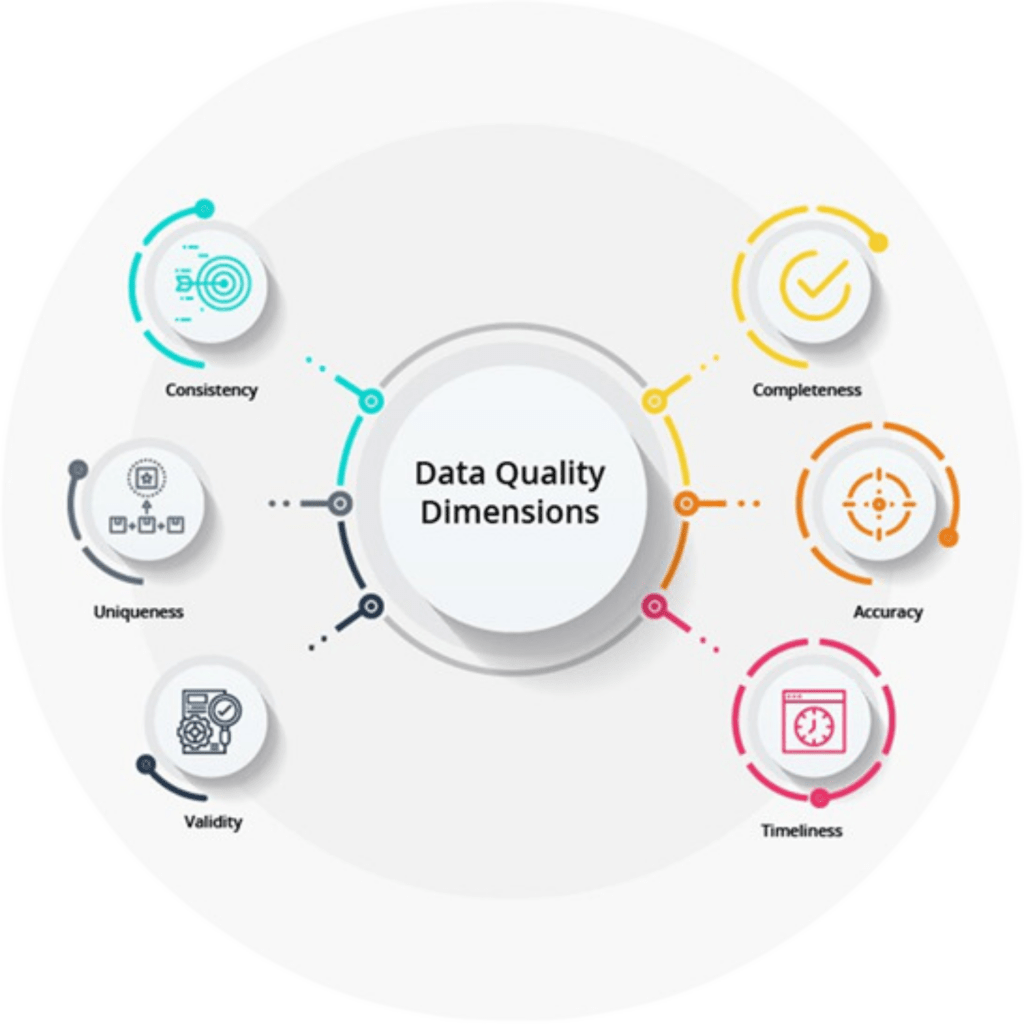
Common Data Quality Issues
- Missing Data: Gaps in the dataset where specific values are not recorded or available.
- Duplicates: Repeated entries of the same data point, leading to redundancy and potential bias in analysis.
- Inconsistent Data: Inconsistencies in data formats, units of measurement, or spelling errors that can lead to confusion or misinterpretation.
- Outliers: Top Deep Learning Projects are data points that are significantly different from the rest of the dataset, which may indicate errors or rare but valid events.
- Incorrect Data: Data that is erroneous due to human or machine input errors, such as impossible dates or misspelled categories.
- Irrelevant Data: Data that doesn’t contribute to the analysis or model, such as unnecessary columns or unrelated features.
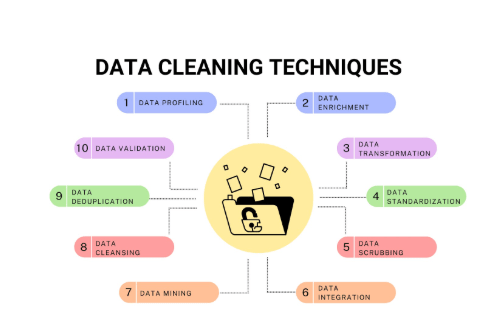
Steps in the Data Cleaning Process
- Data Inspection: Understand the dataset and identify missing values, duplicates, or inconsistencies.
- Data Cleaning: Rectify problems identified during the inspection, such as filling in missing values, correcting inconsistencies, and Build and Annotate An NLP Corpus Easily irrelevant features.
- Data Transformation: Transform variables to an appropriate format, scale, or unit of measurement (e.g., normalizing or standardizing data).
- Data Integration: If data is collected from multiple sources, integrate datasets into a unified structure.
- Data Validation: Ensure the cleaned data is consistent, accurate, and reliable for further analysis or modeling.
- Deletion: Removing rows or columns with missing AI Checker Tool (which may lead to the loss of important information if too much data is missing).
- Imputation: Filling in missing values with estimated values based on other data. Common techniques include
- Mean/Median Imputation: Replacing missing values with the mean or median of the respective feature.
- Regression Imputation: Using a regression model to predict missing values based on other variables.
- KNN Imputation: Filling in missing values using the nearest neighbors approach.
- Flagging: A new feature indicates whether a value is missing, which can be helpful in some modeling situations.
- Pandas: A powerful library for data manipulation and analysis, with built-in functions for detecting and handling missing data, duplicates, and transformations.
- NumPy: Useful for numerical operations and handling arrays, often used alongside Pandas.
- Scikit-learn: Provides utilities for data preprocessing and transformations, such as imputation, encoding, and scaling.
- dplyr and tidyr: Popular packages for data manipulation and cleaning in R.
- Data.table: A fast and efficient package for Uncertainty in Artificial Intelligence with large datasets.
- Talend and Apache Nifi: Platforms for extracting, transforming, and loading data also include powerful AI data cleaning capabilities.
- Trifacta: An intuitive data-cleaning tool that uses machine learning to suggest transformations and corrections.
- OpenRefine: An open-source tool for cleaning messy data and exploring large datasets.
- Large Datasets: When dealing with big data, cleaning becomes more complex and time-consuming due to the sheer volume of information.
- Inconsistent Data Formats: Hypothesis Testing in Data Science from various sources may have different formats, making it challenging to integrate and standardize.
- Missing Data: Deciding how to handle missing data (impute or delete) can significantly affect analysis and outcomes.
- Domain Knowledge: Data cleaning services require knowledge about the domain to identify anomalies or inconsistencies that may not be immediately apparent.
- Automation vs. Manual Cleaning: Automating the data cleaning process using tools and scripts is challenging due to the variety and complexity of data quality issues. Manual inspection is often required but is time-consuming.
- Data Privacy and Security: Cleaning sensitive or personal data can raise privacy concerns, especially when dealing with regulations like GDPR.
- Create a Data Cleaning Plan: Develop a systematic approach to identify and resolve common data quality issues, including missing values, duplicates, and outliers.
- Use Consistent Formats: Standardize data formats (e.g., date formats, unit measurements) across the dataset to avoid inconsistencies.
- Automate Repetitive Tasks: Use libraries and tools to automate common data cleaning tasks like handling Natural Language Processing values, duplicates, or scaling.
- Document the Process: Record the data cleaning steps taken, especially if the process involves transforming or imputing data.
- Validate and Verify: After cleaning, verify the data to ensure it is accurate, complete, and ready for analysis or modeling.
Learn how to manage and deploy cloud services by joining this Data Science Online Course today.
Handling Missing Data
Missing data is one of the most common issues in datasets. The chosen method depends on the nature of the missing data and its impact on the overall analysis.There are several ways to handle it:

Removing Duplicates in Datasets
Duplicated data occurs when the same information is entered multiple times, which can skew results or affect model training. Removing duplicates involves, Identifying Duplicate Rows: Check for rows with identical Data Science Course Training all or specific columns. Removing Exact Duplicates Remove duplicate rows based on predefined criteria (such as keeping only one row of identical data). Handling Near-Duplicates Sometimes, duplicate entries are not identical but represent the same information with slight variations (e.g., slight spelling differences). Identifying and handling near-duplicates is more complex and may involve text-matching or fuzzy-matching algorithms.
Data Transformation and Standardization
After cleaning, data often requires transformation and standardization to make it suitable for analysis or machine learning, Scaling Rescaling numerical features to a specific range (e.g., normalization to [0,1] or standardization to mean zero and standard deviation 1). Encoding Converting categorical variables into numerical representations (e.g., one-hot encoding, label encoding). Feature Engineering Creating new features from existing data to better represent underlying patterns or relationships (e.g., extracting a year from a date). Handling Categorical Variables Transforming text-based categories into numerical values or binary columns. Data transformation ensures that features are in a consistent format, and appropriate scaling makes it easier for machine learning algorithms to process and learn from the data.
Looking to master Data Science? Sign up for ACTE’s Data Science Master Program Training Course and begin your journey today!
Data Cleaning Tools and Technologies
Python Libraries:
R Libraries:
ETL Tools:
Data Cleaning Platforms:
Challenges in Data Cleaning
Boost your chances in Data Science interviews by checking out our blog on Data Science Interview Questions and Answers!
Best Practices for Effective Data Cleaning
Understand Your Data: Conduct an initial exploratory analysis to understand the dataset’s structure, types, and potential issues.
Conclusion
Data cleaning services is an ongoing and evolving process crucial in data science and machine learning. As the volume and complexity of data continue to increase, the techniques and tools used for data cleaning are also advancing. The process is becoming faster and more efficient with the integration of artificial intelligence, machine learning, and automation. Data cleaning services advancements streamline data cleaning, reduce the time and effort needed, and allow for better scalability in handling large datasets. As a result, Data Science Course Training is becoming less of a bottleneck in the AI data cleaning workflow and more of an automated step that seamlessly integrates with machine learning processes. However, despite these advancements, data cleaning remains critical for ensuring high-quality data. Clean data is essential for accurate analysis, the creation of reliable predictive models, and making informed, data-driven decisions. As the field continues to grow, data cleaning will remain central to the success of any data-driven initiative.




