
Last updated on 19th Apr 2025| 9488
- What is the KNN Algorithm?
- Recognizing the KNN Algorithm’s Need
- KNN Distance Metrics
- Choosing the Ideal “K” Value
- KNN Operational Mechanism
- Benefits and Drawbacks of KNN
- KNN is a lazy algorithm; why is that?
- In conclusion
The K-Nearest Neighbors (KNN) algorithm is a supervised machine learning method used for classification and regression. Data Science Course Training known for its simplicity and effectiveness, especially with small datasets. KNN is a lazy learner, meaning it stores the training data and defers computation until prediction. Predictions are based on the majority class or average value of the K closest data points. It relies heavily on distance metrics and works best with normalized data. KNN doesn’t make assumptions about data distribution, making it a non-parametric method. Choosing the right value of K is critical to avoid overfitting or underfitting. It can be computationally expensive for large datasets due to real-time distance calculations. KNN is sensitive to irrelevant or redundant features, so feature selection is important. Common use cases include handwriting recognition, recommendation systems, and fraud detection.
What is the KNN Algorithm?
The K-Nearest Neighbors (KNN) algorithm is a simple, intuitive, and powerful supervised machine learning technique used for both classification and regression tasks. It works by comparing a new, unknown data point to the existing data points in the training set. The algorithm identifies the ‘K’ closest neighbors to the new point, based on a chosen distance metric (like Euclidean distance), and makes predictions by analyzing those neighbors. In classification, it assigns the most common class among the neighbors, while in regression, Big Data vs Data Science averages their values. KNN is called a lazy learner because it doesn’t build a model during training but instead stores the data and performs computation only when making predictions. Its simplicity makes it easy to implement, but it can become slow with large datasets and is sensitive to irrelevant features or unscaled data.
Master Data Science skills by enrolling in this Data Science Online Course today.
Recognizing the KNN Algorithm’s Need
In machine learning, the demand for efficient classification and regression methods has increased significantly due to data-driven insights in various applications. The K-Nearest Neighbors (KNN) algorithm is one such approach that has shown itself to be very practical and easy to understand in machine learning tasks. The KNN algorithm is widely appreciated for its simplicity, ease of understanding, and versatility in solving classification and regression problems. KNN is a supervised learning method for tasks involving regression and classification. A new data point is classified according to the feature space’s ‘K’ nearest neighbors’ majority class. K&N’s advantage is that it is non-parametric, which means it assumes very little about the distribution of the underlying data and can be applied to various applications. Like all algorithms, the effectiveness of the KNN algorithm depends heavily on the proper implementation and parameter selection. In this article, we shall examine the various facets of the Top Reasons to Learn Python , including distance metrics, choosing the optimal ‘K’ value, its Operational Mechanism , machine learning applications, and its benefits and drawbacks.
KNN Distance Metrics
One of the core components of the KNN algorithm is the distance metric, which determines how “closeness” is measured between data points. KNN Application works by finding the K-nearest data points to a given test point, and these nearest points are used to predict the class or value of the test point. There are several distance metrics available, but the most commonly used ones are:
Enhance your knowledge in Data Science. Join this Data Science Online Course now.
- Euclidean Distance: The Euclidean distance is the most commonly used distance metric derived from the Pythagorean theorem. It calculates the straight-line distance between two points in the feature space, which is defined by the following formula,
- Manhattan Distance: Also known as L1 distance or taxicab distance, Manhattan distance calculates the sum of the absolute differences between corresponding coordinates in the feature space, d=∣x2−x1∣+∣y2−y1∣d = |x_2 – x_1| + |y_2 – y_1| . This metric is useful when the movement between two points can only happen in a grid-like structure, such as in urban environments where streets are arranged in a grid pattern.
- Minkowski Distance: Minkowski distance is a generalized distance metric that generalizes both the Euclidean and Manhattan distance measures. It is defined as,
- Cosine Similarity: Cosine similarity measures the cosine of the angle between two vectors in the feature space. Logistic Regression is widely used in text mining and natural language processing (NLP). The formula is, Cosine
- Hamming Distance: For categorical or binary data, Hamming distance calculates the number of positions at which two strings of equal length differ. It is ideal for discrete data and binary vectors.

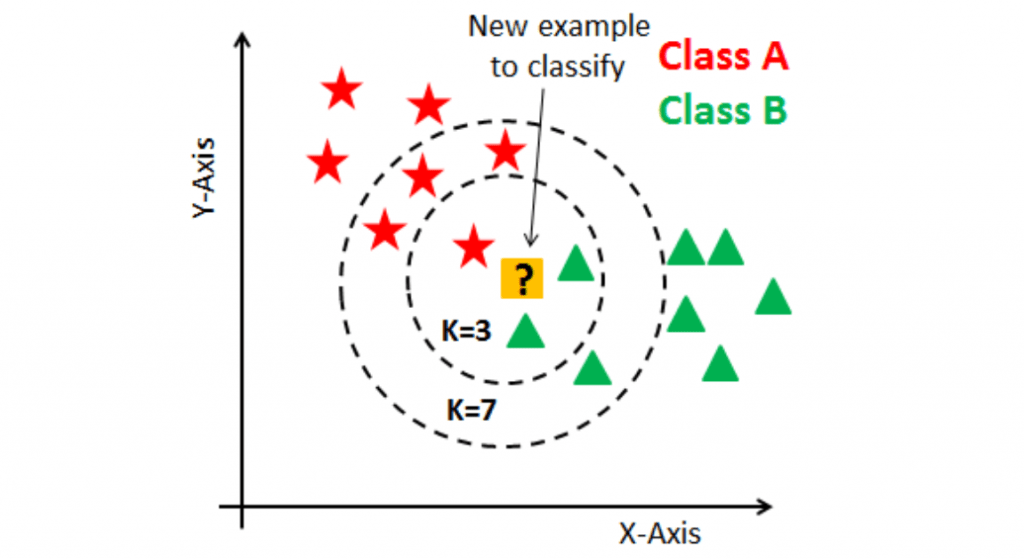
Choosing the Ideal “K” Value
The K in KNN refers to the number of nearest neighbors the algorithm considers when classifying or predicting a data point. Choosing the correct value of K is one of the most critical steps in effectively applying the KNN algorithm. Impact of a Small “K” Value, When K is small, the KNN model becomes very sensitive to noise in the data. For example, if you choose K = 1, the model will classify a data point based on the closest neighbor, which can lead to overfitting. Data Science Course Training means the model becomes too complex and may fail to generalize to unseen data. Impact of a Large “K” Value, On the other hand, if K is too large, the model may become too simplistic and ignore important local patterns in the data. A large K value can smooth out decision boundaries and bias the classifier towards the majority class, resulting in underfitting. Optimal K Selection, To determine the optimal K, one can use methods such as cross-validation. This technique involves splitting the data into training and validation sets multiple times and evaluating the model’s performance for different K values. Typically, K values between 3 and 10 work well for many datasets, but this can vary depending on the problem and data distribution.
Ready to excel in Data Science? Enroll in ACTE’s Data Science Master Program Training Course and begin your journey today!
KNN Operational Mechanism
The KNN algorithm operates in two simple phases: training and prediction. Training Phase, KNN is a lazy learning algorithm, which means it doesn’t learn any model during the training phase. Instead, it simply stores the training data. The algorithm doesn’t try to make assumptions or fit a model to the data, which makes it “lazy”—it only computes during the prediction phase. Prediction Phase, When a new data point arrives in the prediction phase, lazy algorithm computes the distance between the test point and all the training data points using the chosen distance metric. After computing the distances, the K nearest neighbors are selected based on their proximity. Operational Mechanism K neighbors’ class label (for classification) or average (for regression) assigns a label or value to the new data point.
Benefits and Drawbacks of KNN
Like any machine learning algorithm, KNN has its advantages and limitations. Understanding these can help you decide when to use KNN Application over other algorithms.
Benefits of KNN: Simple and Intuitive: KNN is easy to understand and implement, making it a great choice for Data Mining vs Machine Learning beginners.
- No Training Phase: Since KNN is a lazy learning algorithm, there is no need for an explicit training phase or a model to be learned. Operational Mechanism makes it quick to set up for small to medium datasets.
- Non-Parametric: KNN makes a few assumptions about the data, making it useful when the data distribution is unknown.
- Works Well with Multi-Class Data: KNN effectively deals with problems involving multiple classes.
Drawbacks of KNN: Computational Complexity: As the dataset grows, the time complexity of finding the nearest neighbors increases, making KNN unsuitable for large datasets or real-time applications.
- Sensitive to Irrelevant Features: K&N’s performance can degrade significantly if irrelevant or redundant features are present in the data.
- Curse of Dimensionality: As the number of dimensions (features) increases, the distance between points becomes less distinguishable, which can hurt the performance of KNN in high-dimensional spaces.
KNN is a Lazy Algorithm. Why is That?
KNN is considered a lazy algorithm because it does not perform any generalization during the training phase. The Importance of Machine Learning for Data Scientists does not build an explicit model from the training data or try to extract any features from the data. Instead, KNN memorizes the training data and performs computations only when a prediction is needed. This characteristic makes KNN a non-parametric model because it doesn’t assume any underlying functional form for the data. While this gives KNN the flexibility to handle various data types and distributions, it can also be inefficient when dealing with large datasets or real-time predictions.
Want to ace your Data Science interview? Read our blog on Data Science Interview Questions and Answers now!
In Conclusion
One straightforward yet effective tool in the machine learning toolbox is the K-Nearest Neighbors (KNN) method. It is a well-liked option for many classification and regression problems because of its user-friendly design and simplicity. KNN Application can be modified to effectively address real-world issues by using the proper distance metric and the optimal K value. KNN does have certain drawbacks, though, mainly when working with extensive or high-dimensional data. Due to its lazy learning algorithm, it is simple to use and adaptable, but in more complicated situations, Data Science Course Training may cause performance problems. Like with any lazy algorithm, comprehending the issue and trying out several models and strategies is crucial to identifying the best solution.




